ClusterControl 1.6 zapewnia ściślejszą integrację z AWS, Azure i Google Cloud, dzięki czemu można teraz uruchamiać nowe instancje i wdrażać MySQL, MariaDB, MongoDB i PostgreSQL bezpośrednio z interfejsu użytkownika ClusterControl. W tym blogu pokażemy, jak wdrożyć klaster w Amazon Web Services.
Pamiętaj, że ta nowa funkcja wymaga dwóch modułów o nazwie clustercontrol-cloud i clustercontrol-clud . Pierwszy z nich jest demonem pomocniczym, który rozszerza możliwości komunikacji w chmurze CMON, podczas gdy drugi jest klientem menedżera plików do przesyłania i pobierania plików w instancjach w chmurze. Oba pakiety są zależnościami pakietu interfejsu użytkownika klastracontrol, który zostanie zainstalowany automatycznie, jeśli nie istnieją. Zobacz stronę dokumentacji komponentów, aby uzyskać szczegółowe informacje.
Poświadczenia chmury
ClusterControl umożliwia przechowywanie i zarządzanie danymi uwierzytelniającymi w chmurze w obszarze Integracje (menu boczne) -> Dostawcy usług w chmurze:
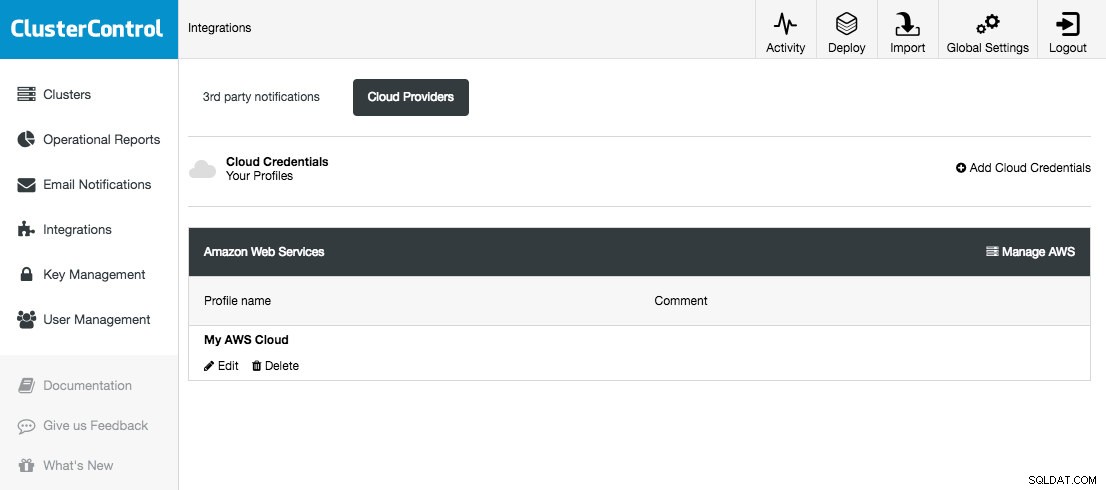
Obsługiwane platformy chmurowe w tej wersji to Amazon Web Services, Google Cloud Platform i Microsoft Azure. Na tej stronie możesz dodać nowe dane uwierzytelniające do chmury, zarządzać istniejącymi, a także połączyć się z platformą w chmurze, aby zarządzać zasobami.
Poświadczenia, które zostały tutaj ustawione, mogą być użyte do:
- Zarządzaj zasobami w chmurze
- Wdrażaj bazy danych w chmurze
- Prześlij kopię zapasową do pamięci w chmurze
Oto, co zobaczysz po kliknięciu przycisku „Zarządzaj AWS”:
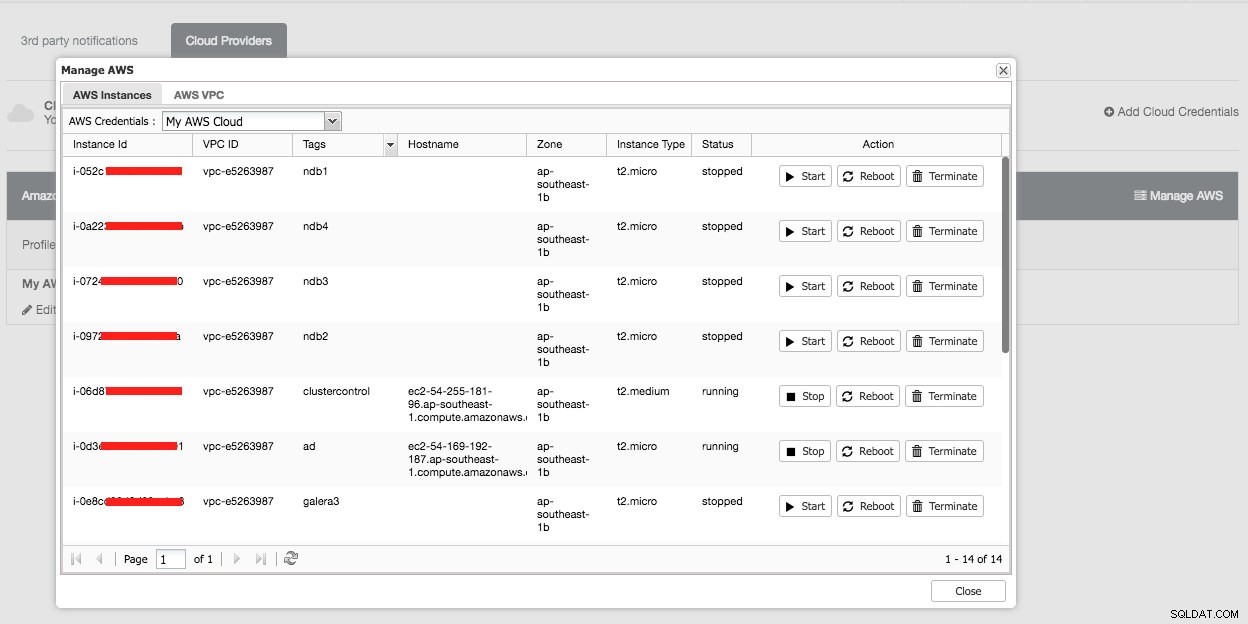
Możesz wykonywać proste zadania zarządzania na swoich instancjach w chmurze. Możesz również sprawdzić ustawienia VPC w zakładce „AWS VPC”, jak pokazano na poniższym zrzucie ekranu:
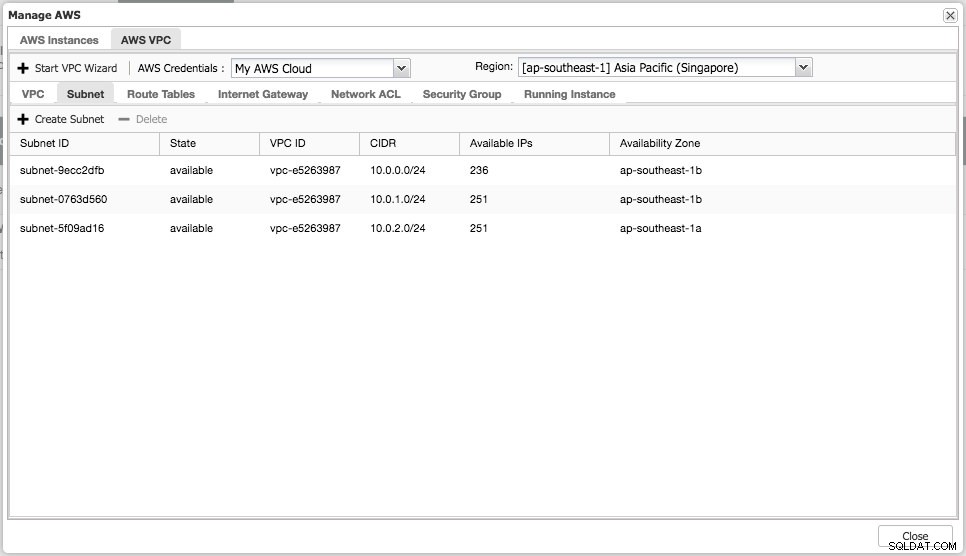
Powyższe funkcje są przydatne jako odniesienie, zwłaszcza podczas przygotowywania instancji w chmurze przed rozpoczęciem wdrożeń bazy danych.
Wdrażanie bazy danych w chmurze
W poprzednich wersjach ClusterControl wdrażanie bazy danych w chmurze było traktowane podobnie do wdrażania na standardowych hostach, gdzie trzeba było wcześniej utworzyć instancje w chmurze, a następnie podać szczegóły instancji i poświadczenia w kreatorze „Wdrażanie klastra bazy danych”. Procedura wdrażania nie była świadoma żadnych dodatkowych funkcji i elastyczności w środowisku chmury, takich jak dynamiczne przydzielanie adresów IP i nazw hostów, publiczny adres IP z translacją NAT, elastyczność przechowywania, konfiguracja sieci wirtualnej chmury prywatnej i tak dalej.
W wersji 1.6 wystarczy podać poświadczenia chmury, którymi można zarządzać za pomocą interfejsu „Dostawcy chmury” i postępować zgodnie z kreatorem wdrażania „Wdrażanie w chmurze”. W interfejsie użytkownika ClusterControl kliknij Wdróż, a zostaną wyświetlone następujące opcje:
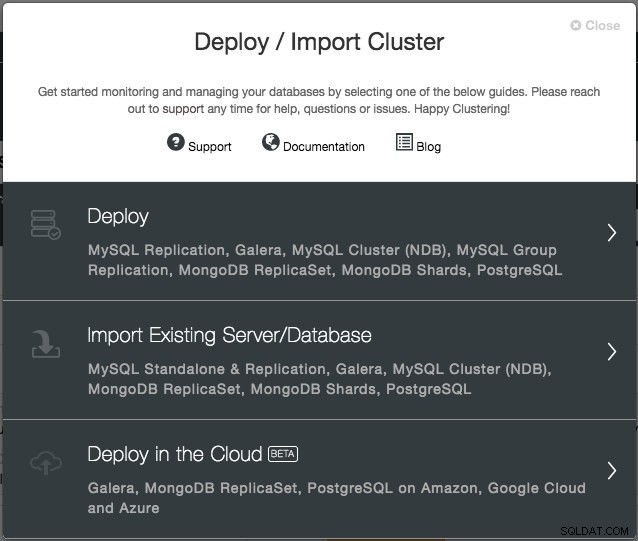
Obecnie wspieranymi dostawcami chmury są trzej najwięksi gracze – Amazon Web Service (AWS), Google Cloud i Microsoft Azure. W przyszłej wersji zamierzamy zintegrować więcej dostawców.
Na pierwszej stronie zostaną wyświetlone opcje szczegółów klastra:
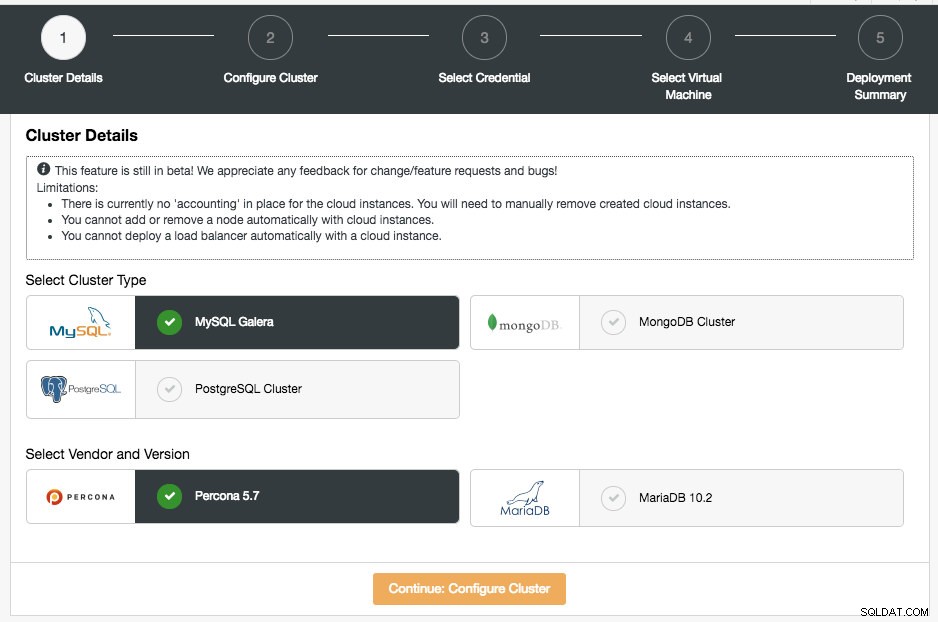
W tej sekcji należy wybrać obsługiwany typ klastra, MySQL Galera Cluster, MongoDB Replica Set lub PostgreSQL Streaming Replication. Następnym krokiem jest wybór obsługiwanego dostawcy dla wybranego typu klastra. Obecnie obsługiwani są następujący dostawcy i wersje:
- Klaster MySQL Galera — klaster Percona XtraDB 5.7, MariaDB 10.2
- Klaster MongoDB — MongoDB 3.4 firmy MongoDB, Inc i Percona Server dla MongoDB 3.4 firmy Percona (tylko zestaw replik).
- Klaster PostgreSQL — PostgreSQL 10.0 (tylko replikacja strumieniowa).
W następnym kroku zostanie wyświetlone następujące okno dialogowe:
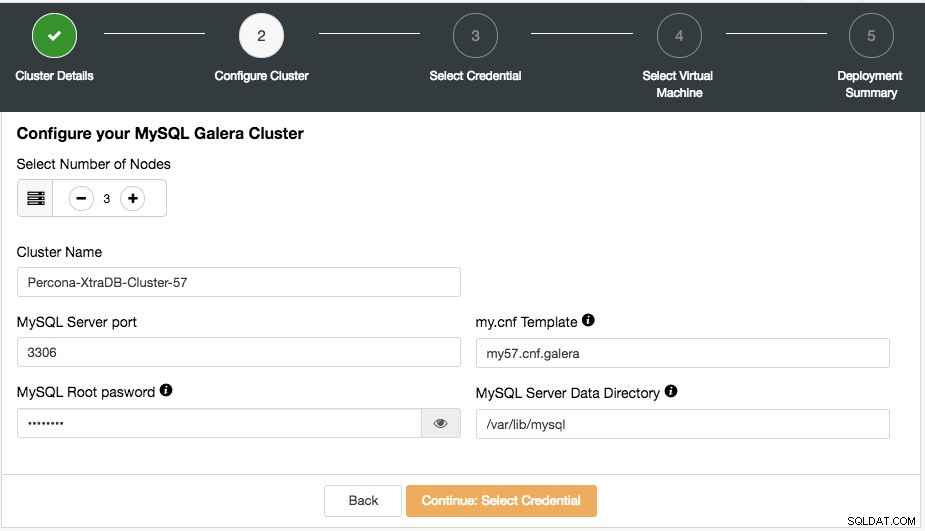
Tutaj możesz odpowiednio skonfigurować wybrany typ klastra. Wybierz liczbę węzłów. Nazwa klastra będzie używana jako tag wystąpienia, dzięki czemu można łatwo rozpoznać to wdrożenie na pulpicie nawigacyjnym dostawcy chmury. W nazwie klastra nie jest dozwolone spacja. Szablon My.cnf to plik konfiguracyjny szablonu, którego ClusterControl użyje do wdrożenia klastra. Musi znajdować się w katalogu /usr/share/cmon/templates na hoście ClusterControl. Pozostałe pola są dość oczywiste.
Następne okno dialogowe to wybór danych logowania do chmury:
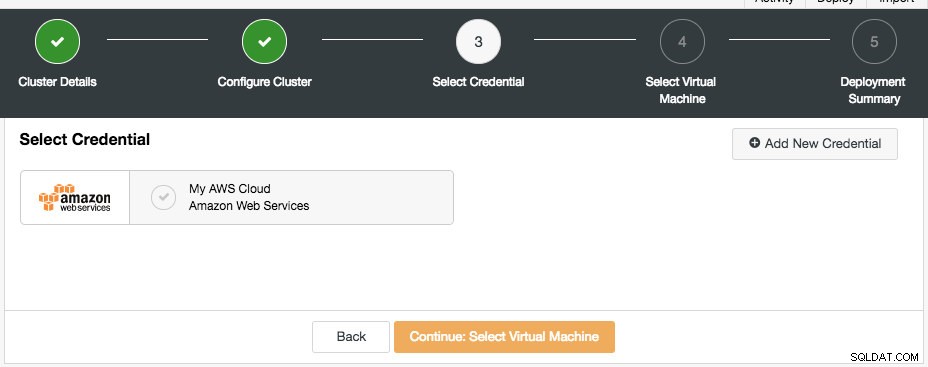
Możesz wybrać istniejące poświadczenia chmury lub utworzyć nowe, klikając przycisk „Dodaj nowe poświadczenia”. Następnym krokiem jest wybór konfiguracji maszyny wirtualnej:
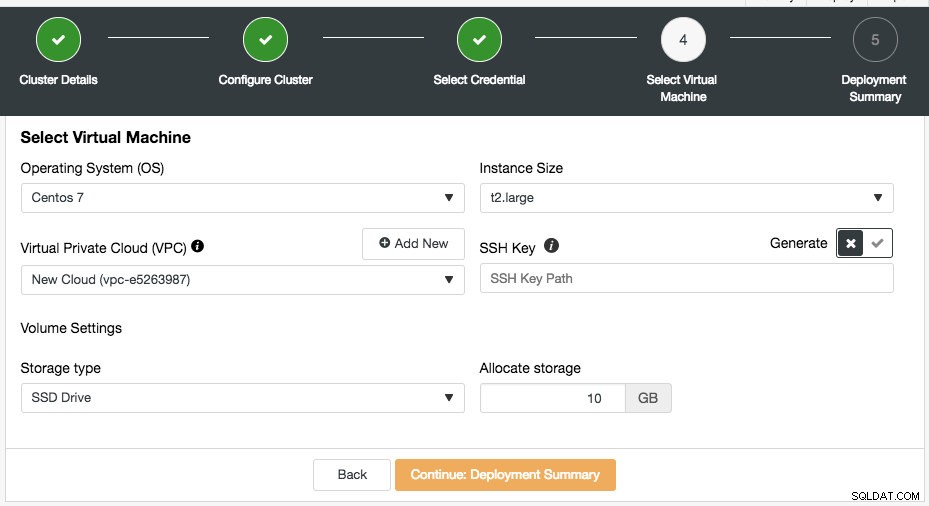
Większość ustawień w tym kroku jest dynamicznie wypełniana przez dostawcę chmury przez wybrane poświadczenia. Możesz skonfigurować system operacyjny, rozmiar instancji, ustawienia VPC, typ i rozmiar pamięci, a także określić lokalizację klucza SSH na hoście ClusterControl. Możesz także pozwolić ClusterControl wygenerować nowy klucz specjalnie dla tych instancji. Po kliknięciu przycisku „Dodaj nowy” obok wirtualnej chmury prywatnej zostanie wyświetlony formularz do utworzenia nowego VPC:
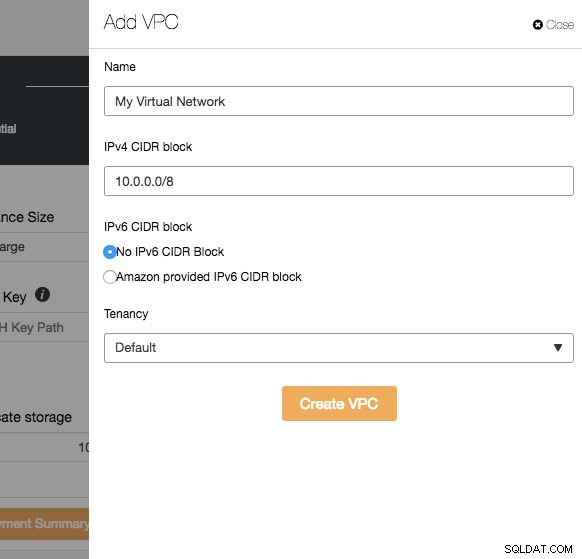
VPC to logiczna infrastruktura sieciowa, którą masz na swojej platformie chmurowej. Możesz skonfigurować swoją VPC, modyfikując jej zakres adresów IP, tworząc podsieci, konfigurując tabele tras, bramy sieciowe i ustawienia zabezpieczeń. Zaleca się wdrożenie infrastruktury bazy danych w tej sieci w celu izolacji, bezpieczeństwa i kontroli routingu.
Podczas tworzenia nowej sieci VPC określ nazwę VPC i blok adresów IPv4 z podsiecią. Następnie wybierz, czy IPv6 ma być częścią sieci i opcję dzierżawy. Następnie możesz użyć tej sieci wirtualnej do infrastruktury bazy danych.
Ostatnim krokiem jest podsumowanie wdrożenia:
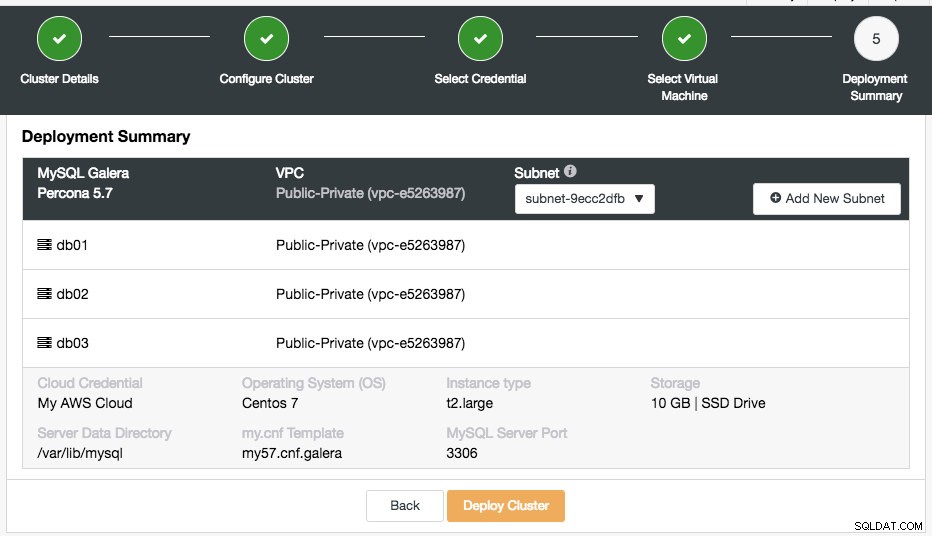
Na tym etapie musisz wybrać podsieć w wybranej sieci wirtualnej, w której ma działać baza danych. Zwróć uwagę, że wybrana podsieć MUSI mieć włączone automatyczne przypisywanie publicznego adresu IPv4. Możesz również utworzyć nową podsieć w ramach tej VPC, klikając przycisk „Dodaj nową podsieć”. Sprawdź, czy wszystko jest w porządku i kliknij przycisk „Wdróż klaster”, aby rozpocząć wdrażanie.
Następnie możesz monitorować postęp, klikając Aktywność -> Zadania -> Utwórz klaster -> Pełne szczegóły zadania:
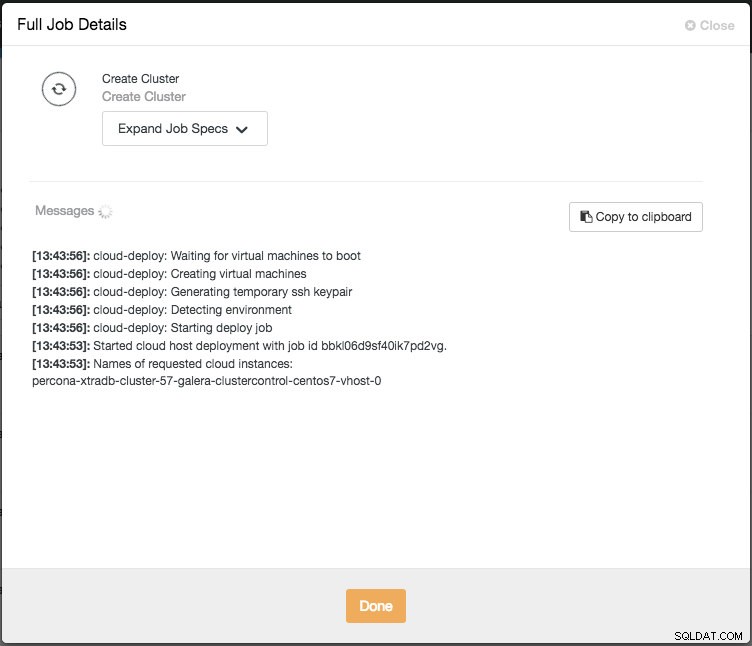
W zależności od połączeń może to zająć od 10 do 20 minut. Po zakończeniu zobaczysz nowy klaster bazy danych na liście w panelu ClusterControl. W przypadku klastra replikacji strumieniowej PostgreSQL może być konieczna znajomość adresów IP mastera i slave'a po zakończeniu wdrożenia. Po prostu przejdź do zakładki Węzły, a zobaczysz publiczne i prywatne adresy IP na liście węzłów po lewej stronie:
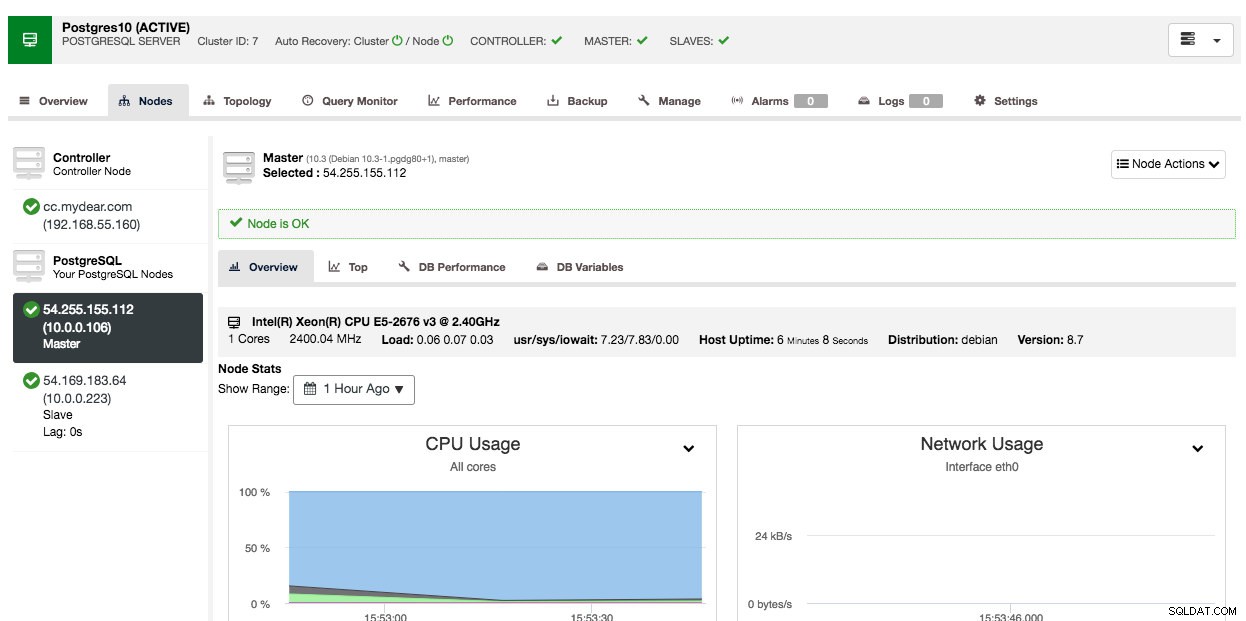
Twój klaster bazy danych jest teraz wdrożony i działa w AWS.
W tej chwili skalowanie w górę działa podobnie do standardowego hosta, gdzie trzeba wcześniej ręcznie utworzyć instancję chmury i określić hosta w ClusterControl -> wybrać klaster -> Dodaj węzeł.
Pod maską proces wdrażania wygląda następująco:
- Utwórz instancje w chmurze
- Konfiguruj grupy bezpieczeństwa i sieć
- Zweryfikuj połączenie SSH z ClusterControl do wszystkich utworzonych instancji
- Wdróż bazę danych na każdej instancji
- Skonfiguruj łącza do klastrowania lub replikacji
- Zarejestruj wdrożenie w ClusterControl
Pamiętaj, że ta funkcja jest nadal w wersji beta. Niemniej jednak możesz użyć tej funkcji, aby przyspieszyć swoje środowisko programistyczne i testowe, kontrolując i zarządzając klastrem bazy danych u różnych dostawców chmury z jednego interfejsu użytkownika.
Kopia zapasowa bazy danych w chmurze
Ta funkcja istnieje już od ClusterControl 1.5.0, a teraz dodaliśmy obsługę usługi Azure Cloud Storage. Oznacza to, że możesz teraz przesyłać i pobierać utworzoną kopię zapasową na wszystkich trzech głównych dostawcach chmury (AWS, GCP i Azure). Proces przesyłania odbywa się zaraz po pomyślnym utworzeniu kopii zapasowej (jeśli przełączysz opcję „Prześlij kopię zapasową do chmury”) lub możesz ręcznie kliknąć przycisk ikony chmury na liście kopii zapasowych:
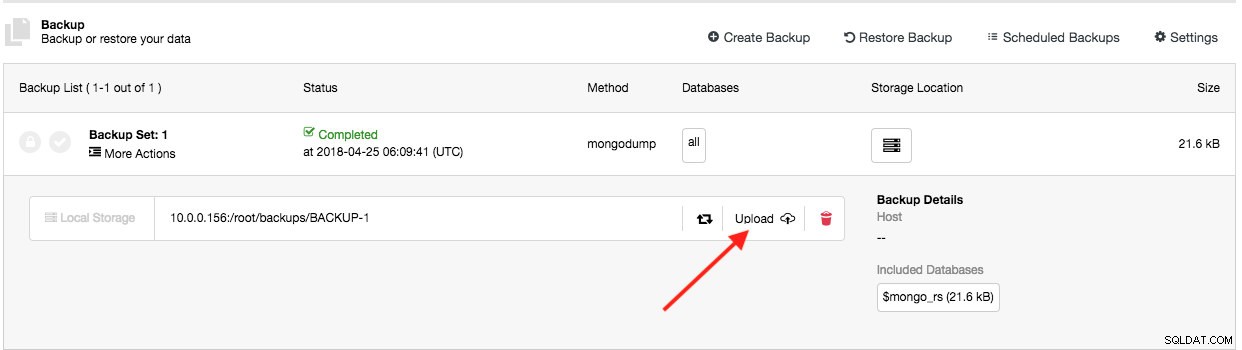
Następnie możesz pobierać i przywracać kopie zapasowe z chmury na wypadek utraty lokalnego magazynu kopii zapasowych lub w przypadku konieczności zmniejszenia wykorzystania miejsca na dysku lokalnym na kopie zapasowe.
Aktualne ograniczenia
Istnieją pewne znane ograniczenia funkcji wdrażania w chmurze, jak podano poniżej:
- Obecnie nie ma „księgowania” dla instancji w chmurze. Jeśli usuniesz klaster bazy danych, musisz ręcznie usunąć instancje w chmurze.
- Nie można automatycznie dodawać ani usuwać węzła za pomocą instancji w chmurze.
- Nie możesz automatycznie wdrożyć systemu równoważenia obciążenia z instancją w chmurze.
Przetestowaliśmy tę funkcję w wielu środowiskach i konfiguracjach, ale zawsze są przypadki, w których mogliśmy przeoczyć. Aby uzyskać więcej informacji, zajrzyj do dziennika zmian.
Miłego klastrowania w chmurze!



