W ostatnich czterech postach z serii blogów omówiliśmy wdrażanie klastrów/replikacji (MySQL/Galera, MySQL Replication, MongoDB i PostgreSQL), zarządzanie i monitorowanie istniejących baz danych i klastrów, monitorowanie wydajności i kondycji oraz w ostatnim poście, jak sprawić, by konfiguracja była wysoce dostępna poprzez HAProxy i ProxySQL.
Więc teraz, gdy masz już uruchomione i wysoce dostępne bazy danych, w jaki sposób możesz zapewnić sobie kopie zapasowe swoich danych?
Kopii zapasowych można używać do wielu celów:odzyskiwania po awarii, dostarczania danych produkcyjnych do testowania przed rozwojem, a nawet udostępniania węzła podrzędnego. Ten ostatni przypadek jest już objęty ClusterControl. Po dodaniu nowego węzła (repliki) do konfiguracji replikacji, ClusterControl utworzy kopię zapasową/migawkę węzła głównego i użyje go do zbudowania repliki. Może również użyć istniejącej kopii zapasowej do przygotowania repliki, na wypadek gdybyś chciał uniknąć dodatkowego obciążenia mastera. Po rozpakowaniu i przygotowaniu kopii zapasowej oraz uruchomieniu i uruchomieniu bazy danych, ClusterControl automatycznie skonfiguruje replikację.
Tworzenie natychmiastowej kopii zapasowej
Zasadniczo tworzenie kopii zapasowej jest takie samo dla Galera, replikacji MySQL, PostgreSQL i MongoDB. Sekcja kopii zapasowej znajduje się w sekcji ClusterControl> Kopia zapasowa i domyślnie zobaczysz listę utworzonych kopii zapasowych klastra (jeśli istnieje). W przeciwnym razie zobaczysz symbol zastępczy do utworzenia kopii zapasowej:
Tutaj możesz kliknąć przycisk „Utwórz kopię zapasową”, aby wykonać natychmiastową kopię zapasową lub zaplanować nową kopię zapasową:
Wszystkie utworzone kopie zapasowe można również przesłać do chmury, przełączając opcję „Prześlij kopię zapasową do chmury”, pod warunkiem, że podasz działające poświadczenia chmury. Domyślnie wszystkie kopie zapasowe starsze niż 31 dni zostaną usunięte (można je skonfigurować za pomocą ustawień przechowywania kopii zapasowych) lub możesz zachować je na zawsze lub zdefiniować niestandardowy okres.
„Utwórz kopię zapasową” i „Zaplanuj kopię zapasową” mają podobne opcje, z wyjątkiem części dotyczącej harmonogramu i opcji tworzenia przyrostowej kopii zapasowej dla tych ostatnich. Dlatego przyjrzymy się dokładniej funkcji Utwórz kopię zapasową (tzw. natychmiastowa kopia zapasowa).
Ponieważ wszystkie te różne bazy danych mają różne narzędzia do tworzenia kopii zapasowych, istnieje oczywiście pewna różnica w opcjach, które możesz wybrać. Na przykład z MySQL możesz wybierać między mysqldump i xtrabackup (pełny i przyrostowy). W przypadku MongoDB ClusterControl obsługuje mongodump i mongodb-consistent-backup (beta), podczas gdy obsługiwane są PostgreSQL, pg_dump i pg_basebackup. Jeśli masz wątpliwości, który z nich wybrać dla MySQL, sprawdź ten blog o różnicach i przypadkach użycia mysqldump i xtrabackup.
Tworzenie kopii zapasowych MySQL i Galera
Jak wspomniano w poprzednim akapicie, możesz tworzyć kopie zapasowe MySQL za pomocą mysqldump lub xtrabackup (pełne lub przyrostowe). W kreatorze „Utwórz kopię zapasową” możesz wybrać host, na którym chcesz uruchomić kopię zapasową, lokalizację, w której chcesz przechowywać pliki kopii zapasowej, a także jego katalog i określone schematy (xtrabackup) lub schematy i tabele (mysqldump).
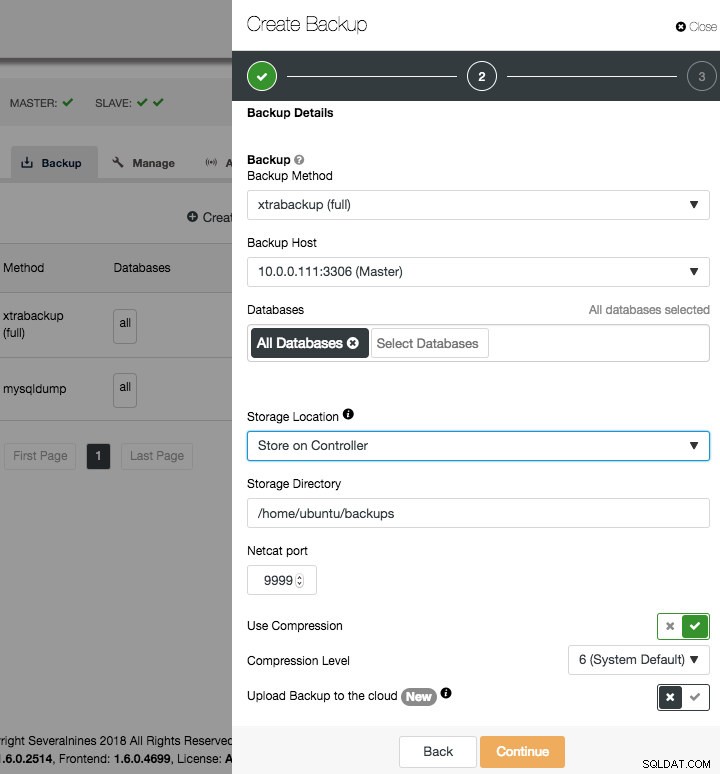
Jeśli węzeł, którego kopię zapasową tworzysz, odbiera ruch (produkcyjny) i obawiasz się, że dodatkowe zapisy na dysku staną się uciążliwe, zaleca się wysłanie kopii zapasowych do hosta ClusterControl, wybierając opcję „Zapisz na kontrolerze”. Spowoduje to, że kopia zapasowa będzie przesyłać strumieniowo pliki przez sieć do hosta ClusterControl i musisz upewnić się, że w tym węźle jest wystarczająca ilość miejsca, a port przesyłania strumieniowego jest otwarty na hoście ClusterControl.
Istnieje również kilka innych opcji, czy chcesz użyć kompresji i poziomu kompresji. Im wyższy poziom kompresji, tym mniejszy będzie rozmiar kopii zapasowej. Wymaga to jednak większego wykorzystania procesora w procesie kompresji i dekompresji.
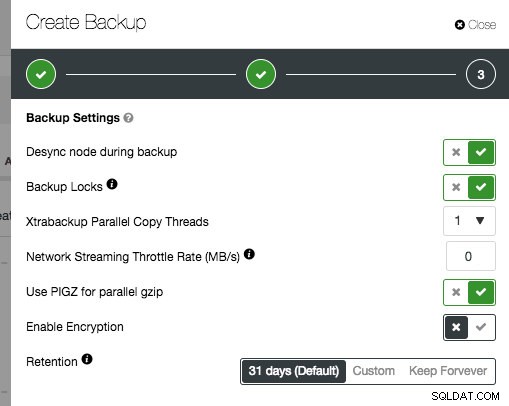
Jeśli wybierzesz xtrabackup jako metodę tworzenia kopii zapasowej, otworzy to dodatkowe opcje:desynchronizacja, blokady kopii zapasowych, kompresja i równoległe wątki xtrabackup/gzip. Opcja desynchronizacji ma zastosowanie tylko do desynchronizacji węzła z klastra Galera. Blokady kopii zapasowych wykorzystują nowy typ blokady MDL do blokowania aktualizacji tabel nietransakcyjnych i instrukcji DDL dla wszystkich tabel, co jest bardziej wydajne w przypadku obciążenia specyficznego dla InnoDB. Jeśli korzystasz z Galera Cluster, włączenie tej opcji jest zalecane.
Po zaplanowaniu natychmiastowej kopii zapasowej możesz śledzić postęp zadania kopii zapasowej w Aktywność> Zadania :
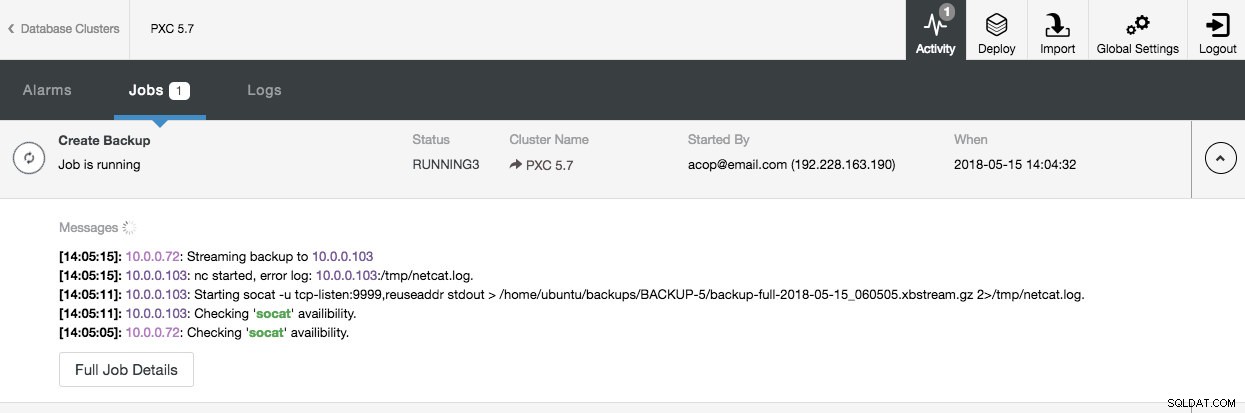
Po zakończeniu powinieneś być w stanie zobaczyć nowy wpis na liście kopii zapasowych.
Tworzenie kopii zapasowej PostgreSQL
Podobnie jak w przypadku natychmiastowych kopii zapasowych MySQL, możesz uruchomić kopię zapasową w bazie danych Postgres. W przypadku kopii zapasowych Postgres obsługiwane są dwie metody tworzenia kopii zapasowych - pg_dumpall lub pg_basebackup. Zwróć uwagę, że ClusterControl zawsze wykona pełną kopię zapasową, niezależnie od wybranej metody tworzenia kopii zapasowej.
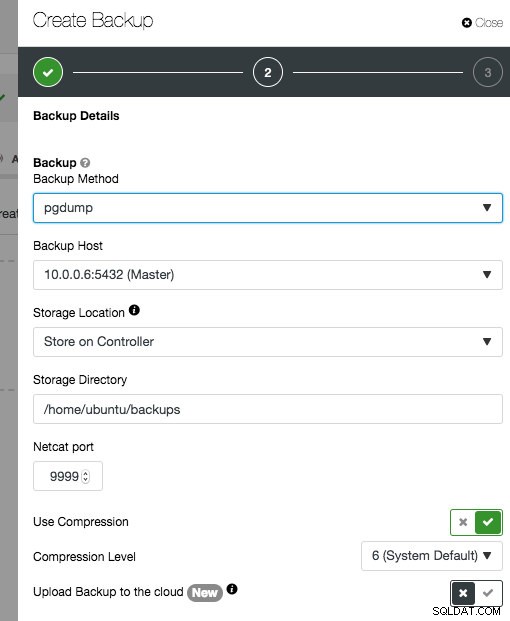
Omówiliśmy ten aspekt w szczegółach w sekcji Zostań DBA PostgreSQL - Logiczne i fizyczne kopie zapasowe PostgreSQL.
Tworzenie kopii zapasowej MongoDB
W przypadku MongoDB ClusterControl obsługuje standardowe mongodump i mongodb-consistent-backup opracowane przez firmę Percona. Ta ostatnia jest nadal w wersji beta, która zapewnia spójne dla klastra kopie zapasowe MongoDB w określonym punkcie czasu, odpowiednie dla konfiguracji klastrów sharded. Ponieważ podzielony na fragmenty klaster MongoDB składa się z wielu zestawów replik, zestawu replik konfiguracji i serwerów fragmentów, bardzo trudno jest wykonać spójną kopię zapasową przy użyciu tylko mongodump.
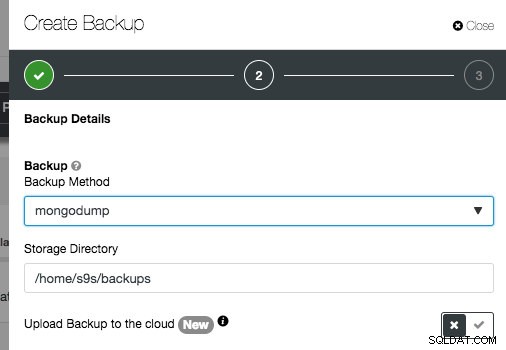
Zauważ, że w kreatorze nie musisz wybierać węzła bazy danych, którego kopia zapasowa ma zostać utworzona. ClusterControl automatycznie wybierze najzdrowszą replikę pomocniczą jako węzeł zapasowy. W przeciwnym razie zostanie wybrany podstawowy. Gdy kopia zapasowa jest uruchomiona, wybrany węzeł kopii zapasowej zostanie zablokowany do czasu zakończenia procesu tworzenia kopii zapasowej.
Planowanie kopii zapasowych
Teraz, gdy bawiliśmy się tworzeniem natychmiastowych kopii zapasowych, możemy to rozszerzyć, planując tworzenie kopii zapasowych.
Harmonogramowanie jest bardzo proste:możesz wybrać, w które dni ma być wykonana kopia zapasowa io której godzinie ma ona zostać uruchomiona.
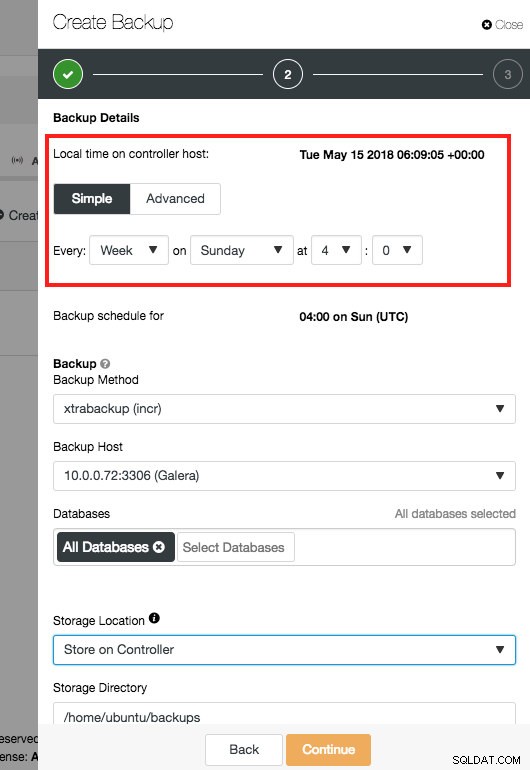
W przypadku xtrabackup dostępna jest dodatkowa funkcja:przyrostowe kopie zapasowe. Przyrostowa kopia zapasowa utworzy kopię zapasową tylko tych danych, które zmieniły się od ostatniej kopii zapasowej. Oczywiście przyrostowe kopie zapasowe są bezużyteczne, jeśli nie ma pełnej kopii zapasowej jako punktu wyjścia. Między dwiema pełnymi kopiami zapasowymi możesz mieć dowolną liczbę kopii przyrostowych. Ale przywrócenie ich potrwa dłużej.
Po zaplanowaniu zadania powinny być widoczne w zakładce „Zaplanowana kopia zapasowa” i można je edytować, klikając przycisk „Edytuj”. Podobnie jak w przypadku natychmiastowych kopii zapasowych, zadania te zaplanują tworzenie kopii zapasowej, a postęp można śledzić na karcie Aktywność.
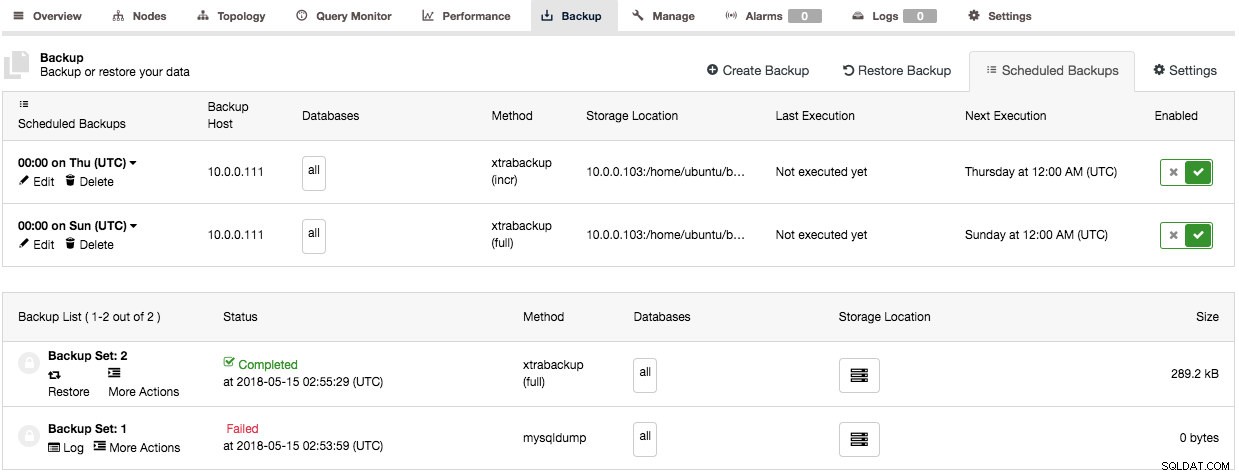
Lista kopii zapasowych
Listę kopii zapasowych znajdziesz w ClusterControl> Kopia zapasowa a to da ci przegląd wszystkich wykonanych kopii zapasowych na poziomie klastra. Kliknięcie każdego wpisu spowoduje rozwinięcie wiersza i udostępnienie dodatkowych informacji o kopii zapasowej:
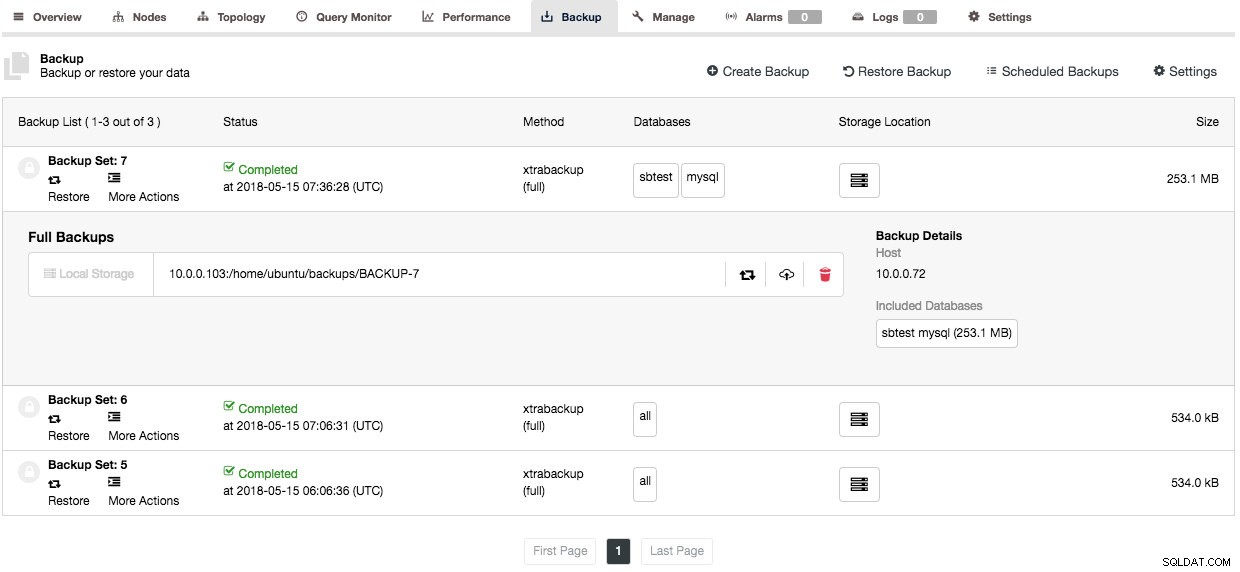
Każdej kopii zapasowej towarzyszy dziennik kopii zapasowej, gdy ClusterControl wykonał zadanie, który jest dostępny pod przyciskiem „Więcej działań”.
Zewnętrzna kopia zapasowa w chmurze
Ponieważ mamy teraz wiele kopii zapasowych przechowywanych na hostach bazy danych lub na hoście ClusterControl, chcemy również mieć pewność, że nie zgubią się one w przypadku całkowitej awarii infrastruktury. (np. DC w przypadku pożaru lub zalania) Dlatego ClusterControl umożliwia przechowywanie lub kopiowanie kopii zapasowych poza siedzibą firmy w chmurze. Obsługiwane platformy chmurowe to Amazon S3, Google Cloud Storage i Azure Cloud Storage.
Proces przesyłania odbywa się zaraz po pomyślnym utworzeniu kopii zapasowej (jeśli przełączysz opcję „Prześlij kopię zapasową do chmury”) lub możesz ręcznie kliknąć przycisk ikony chmury na liście kopii zapasowych:
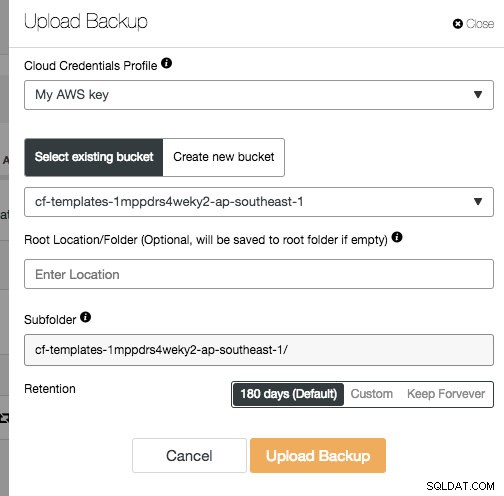
Wybierz dane uwierzytelniające chmury i odpowiednio określ lokalizację kopii zapasowej:
Przywróć i/lub zweryfikuj kopię zapasową
Z interfejsu listy kopii zapasowych możesz bezpośrednio przywrócić kopię zapasową na hoście w klastrze, klikając przycisk „Przywróć” dla określonej kopii zapasowej lub klikając przycisk „Przywróć kopię zapasową”:
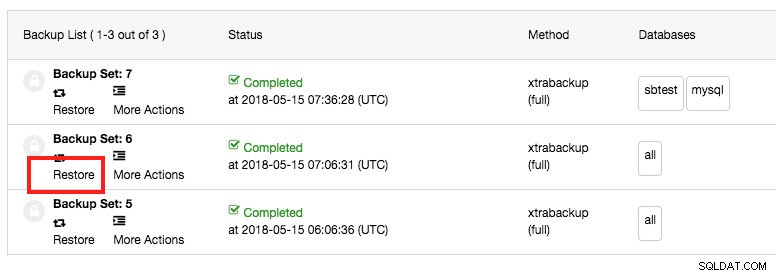
Jedną z fajnych funkcji jest to, że jest w stanie przywrócić węzeł lub klaster przy użyciu pełnych i przyrostowych kopii zapasowych, ponieważ śledzi ostatnią pełną kopię zapasową i rozpoczyna tworzenie przyrostowej kopii zapasowej. Następnie zgrupuje pełną kopię zapasową wraz ze wszystkimi kopiami przyrostowymi aż do następnej pełnej kopii zapasowej. Pozwala to na przywracanie, zaczynając od pełnej kopii zapasowej i stosując na niej przyrostowe kopie zapasowe.
ClusterControl obsługuje przywracanie na istniejącym węźle bazy danych lub przywracanie i weryfikację na nowym samodzielnym hoście:
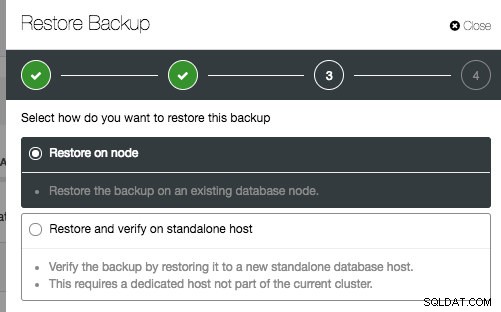
Te dwie opcje są dość podobne, z wyjątkiem tego, że weryfikacja ma dodatkowe opcje dla informacji o nowym hoście. Jeśli będziesz postępować zgodnie z kreatorem przywracania, będziesz musiał określić nowego hosta. Jeśli opcja „Zainstaluj oprogramowanie bazy danych” jest włączona, ClusterControl usunie wszelkie istniejące instalacje MySQL na docelowym hoście i ponownie zainstaluje oprogramowanie bazy danych w tej samej wersji, co istniejący serwer MySQL.
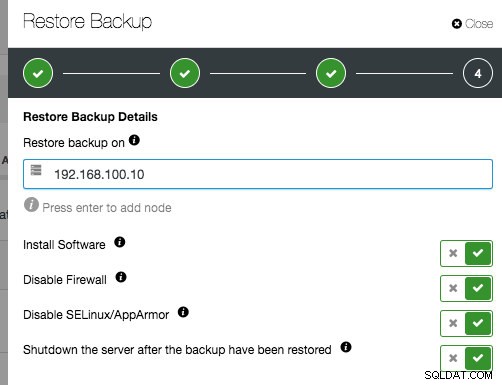
Gdy kopia zapasowa zostanie przywrócona i zweryfikowana, otrzymasz powiadomienie o stanie przywracania, a węzeł zostanie automatycznie wyłączony.
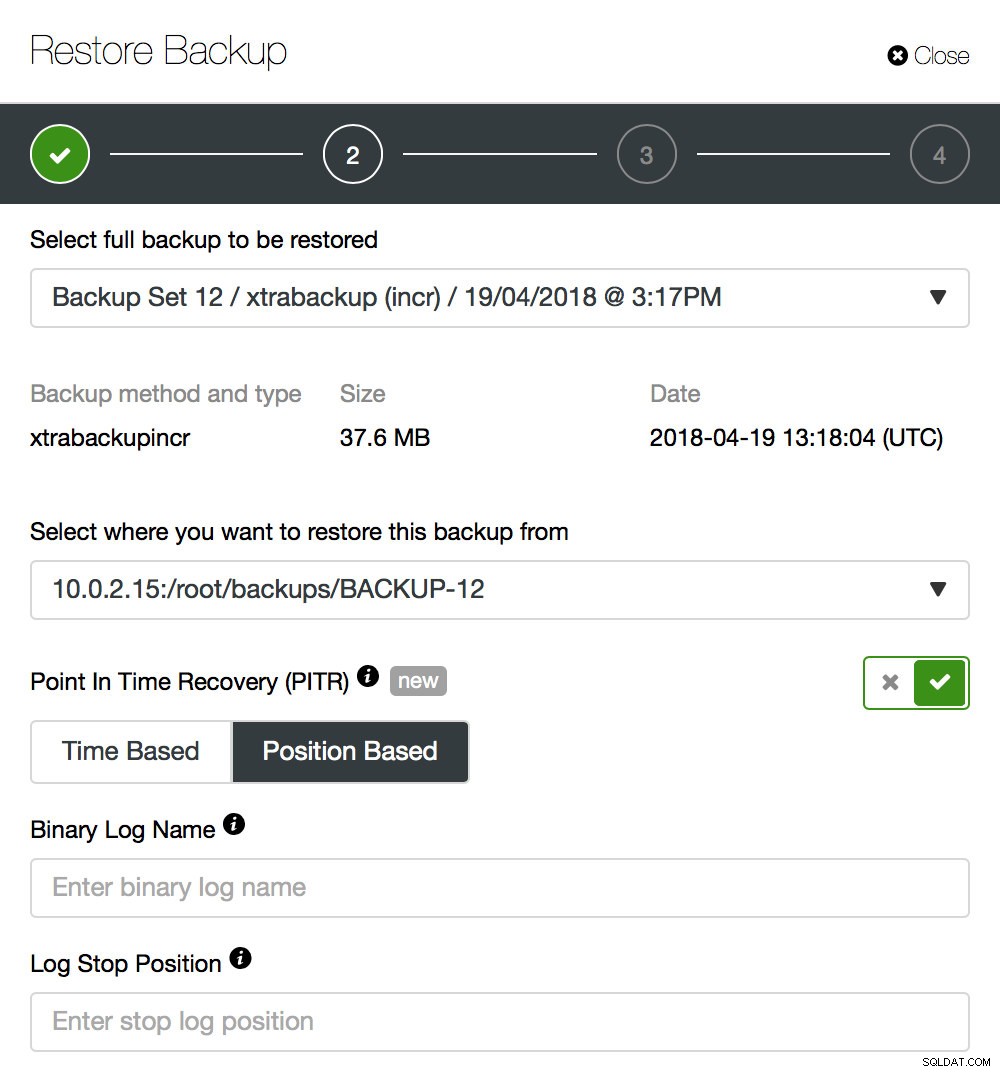
Odzyskiwanie do określonego punktu w czasie
W przypadku MySQL zarówno xtrabackup, jak i mysqldump mogą być używane do wykonywania odzyskiwania do określonego momentu, a także do udostępniania nowego urządzenia podrzędnego replikacji na potrzeby replikacji typu master-slave lub klastra Galera. Kopia zapasowa zgodna z mysqldump PITR zawiera jeden plik zrzutu z informacjami GTID, plikiem binlogu i pozycją. W związku z tym tylko węzeł bazy danych, który generuje dziennik binarny, będzie miał dostępną opcję „zgodność z PITR”:
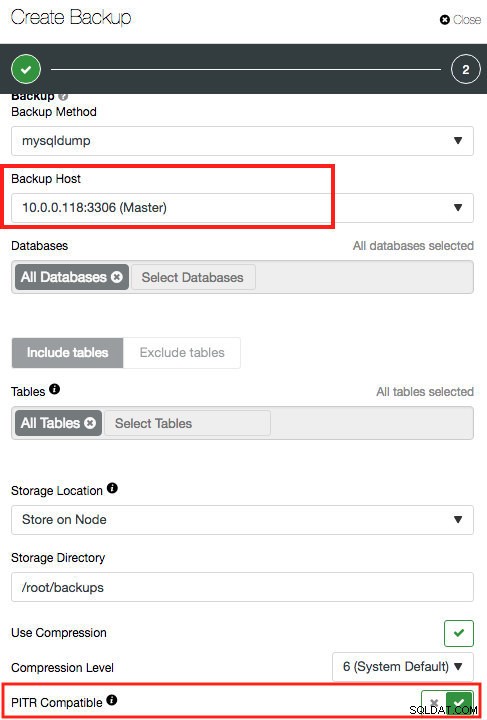
Gdy opcja kompatybilna z PITR jest przełączona, pola bazy danych i tabeli są wyszarzone, ponieważ ClusterControl zawsze wykona pełną kopię zapasową wszystkich baz danych, zdarzeń, wyzwalaczy i procedur docelowego serwera MySQL.
Teraz przywracam kopię zapasową. Jeśli kopia zapasowa jest zgodna z PITR, zostanie wyświetlona opcja wykonania odzyskiwania do określonego punktu w czasie. Będziesz mieć do tego dwie opcje – „Na podstawie czasu” i „Na podstawie pozycji”. W przypadku „opartego na czasie” możesz po prostu podać dzień i godzinę. W przypadku opcji „Na podstawie pozycji” możesz przekazać dokładną pozycję do miejsca, w którym chcesz przywrócić. Jest to bardziej precyzyjny sposób przywracania, chociaż może być konieczne uzyskanie pozycji binloga za pomocą narzędzia mysqlbinlog. Więcej szczegółów na temat odzyskiwania do określonego momentu można znaleźć na tym blogu.
Szyfrowanie kopii zapasowych
ClusterControl ogólnie obsługuje szyfrowanie kopii zapasowych dla MySQL, MongoDB i PostgreSQL. Kopie zapasowe są szyfrowane w spoczynku przy użyciu algorytmu AES-256 CBC. Automatycznie wygenerowany klucz zostanie zapisany w pliku konfiguracyjnym klastra w /etc/cmon.d/cmon_X.cnf (gdzie X to identyfikator klastra):
$ sudo grep backup_encryption_key /etc/cmon.d/cmon_1.cnf
backup_encryption_key='JevKc23MUIsiWLf2gJWq/IQ1BssGSM9wdVLb+gRGUv0='Jeśli miejsce docelowe kopii zapasowej nie jest lokalne, pliki kopii zapasowej są przesyłane w formacie zaszyfrowanym. Ta funkcja uzupełnia kopię zapasową poza siedzibą w chmurze, gdzie nie mamy pełnego dostępu do podstawowego systemu pamięci masowej.
Ostateczne myśli
Pokazaliśmy, jak wykonać kopię zapasową danych i jak je bezpiecznie przechowywać poza witryną. Odzyskiwanie to zawsze inna sprawa. ClusterControl może automatycznie odzyskać Twoje bazy danych z kopii zapasowych wykonanych w przeszłości, które są przechowywane lokalnie lub kopiowane z powrotem z chmury.
Oczywiście chodzi o coś więcej w zabezpieczaniu danych, zwłaszcza po stronie zabezpieczania połączeń. Omówimy to w następnym poście na blogu!



