W poprzednich dwóch wpisach na blogu omówiliśmy zarówno wdrażanie czterech typów klastrowania/replikacji (MySQL/Galera, MySQL Replication, MongoDB i PostgreSQL), jak i zarządzanie/monitorowanie istniejących baz danych i klastrów. Tak więc po przeczytaniu tych dwóch pierwszych wpisów na blogu można było dodać 20 istniejących konfiguracji replikacji do ClusterControl, rozszerzyć je i dodatkowo wdrożyć dwa nowe klastry Galera, jednocześnie wykonując mnóstwo innych rzeczy. A może wdrożyłeś systemy MongoDB i/lub PostgreSQL. Więc teraz, jak dbasz o ich zdrowie?
Dokładnie o tym jest ten wpis na blogu:jak wykorzystać funkcje monitorowania wydajności i doradców ClusterControl, aby utrzymać w dobrym stanie bazy danych i klastry MySQL, MongoDB i/lub PostgreSQL. Jak to się robi w ClusterControl?
Lista klastrów bazy danych
Najważniejsze informacje można znaleźć już na liście klastrów:dopóki nie ma alarmów i żaden host nie jest wyłączony, wszystko działa poprawnie. Alarm jest uruchamiany, gdy spełniony jest określony warunek, np. host wymienia się i zwraca uwagę na problem, który należy zbadać. Oznacza to, że alarmy nie tylko są podnoszone podczas awarii, ale także umożliwiają proaktywne zarządzanie bazami danych.
Załóżmy, że zalogujesz się do ClusterControl i zobaczysz listę klastrów taką jak ta, na pewno będziesz miał coś do zbadania:na przykład jeden węzeł jest wyłączony w klastrze Galera, a każdy klaster ma różne alarmy:
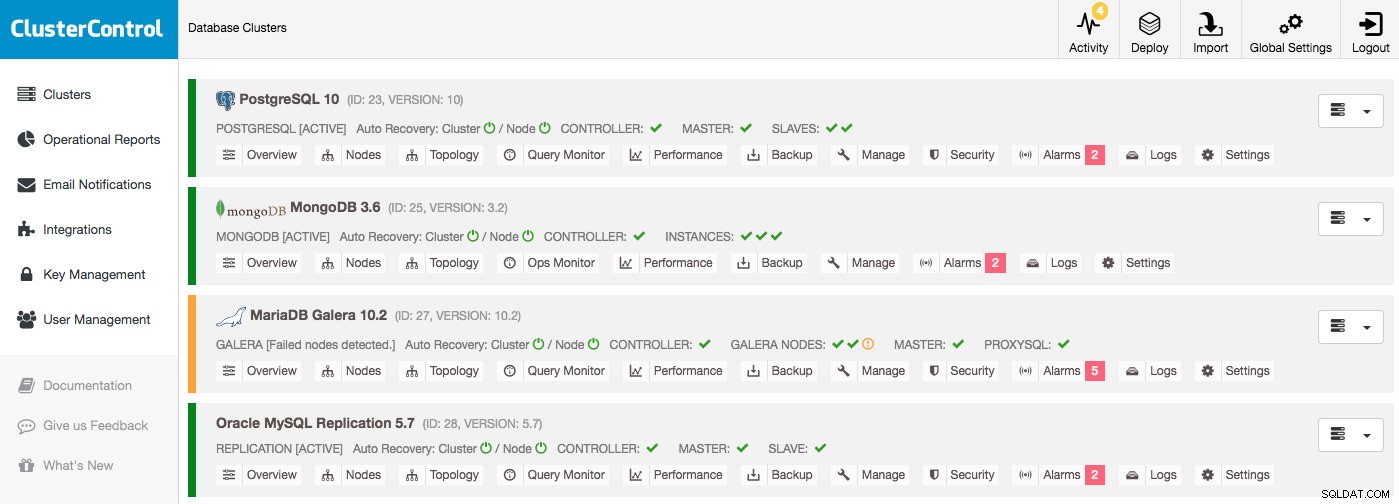
Po kliknięciu jednego z alarmów przejdziesz do szczegółowej strony ze wszystkimi alarmami klastra. Szczegóły alarmu wyjaśnią problem, a w większości przypadków również zalecą działania mające na celu rozwiązanie problemu.
Możesz skonfigurować własne alarmy, tworząc niestandardowe wyrażenia, ale zostało to przestarzałe na rzecz naszego nowego Developer Studio, które umożliwia pisanie niestandardowych skryptów JavaScript i wykonywanie ich jako Doradców. Wrócimy do tego tematu w dalszej części tego postu.
Omówienie klastra – pulpity nawigacyjne
Po otwarciu przeglądu klastra możemy od razu zobaczyć najważniejsze metryki wydajności dla klastra na kartach. Ten przegląd może się różnić w zależności od typu klastra, ponieważ na przykład Galera ma inne metryki wydajności do oglądania niż tradycyjne MySQL, PostgreSQL lub MongoDB.
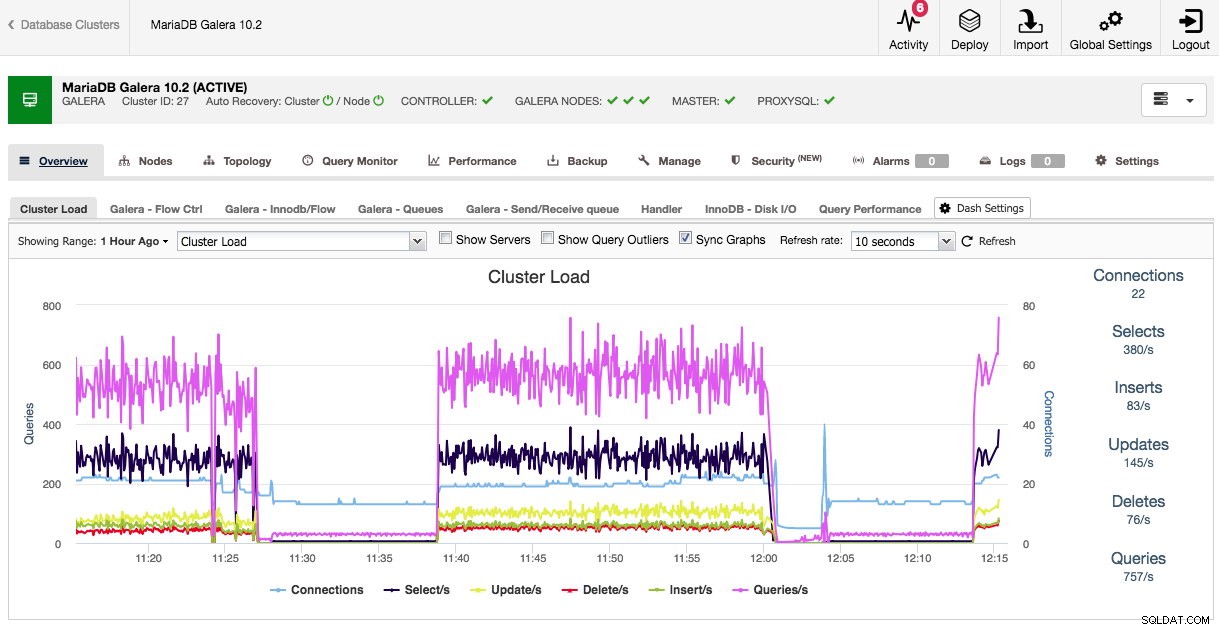
Można dostosować zarówno domyślny przegląd, jak i wstępnie wybrane karty. Klikając Przegląd -> Ustawienia Dash pojawi się okno dialogowe umożliwiające zdefiniowanie pulpitu nawigacyjnego:
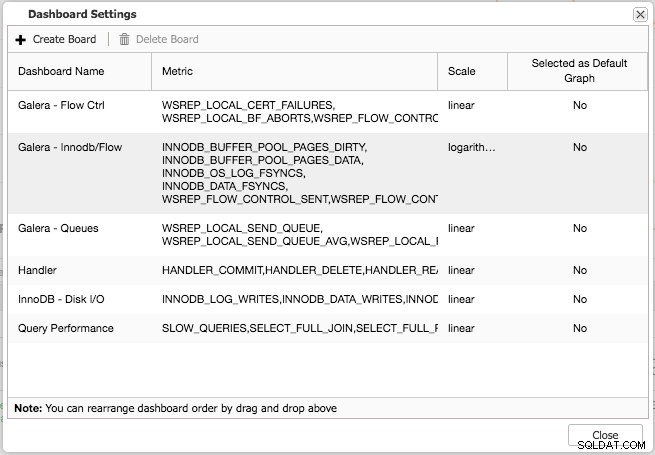
Naciskając znak plus, możesz dodawać i definiować własne metryki do wykresu dashboardu. W naszym przypadku zdefiniujemy nowy pulpit nawigacyjny zawierający średnią kolejki wysyłania i odbierania dla Galery:
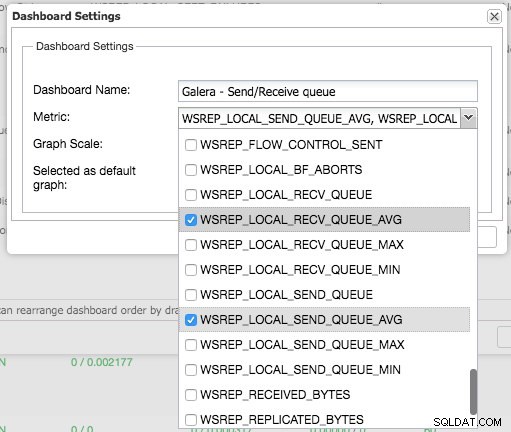
Ten nowy panel powinien dać nam dobry wgląd w średnią długość kolejki w naszym klastrze Galera.
Po naciśnięciu przycisku Zapisz nowy panel będzie dostępny dla tego klastra:
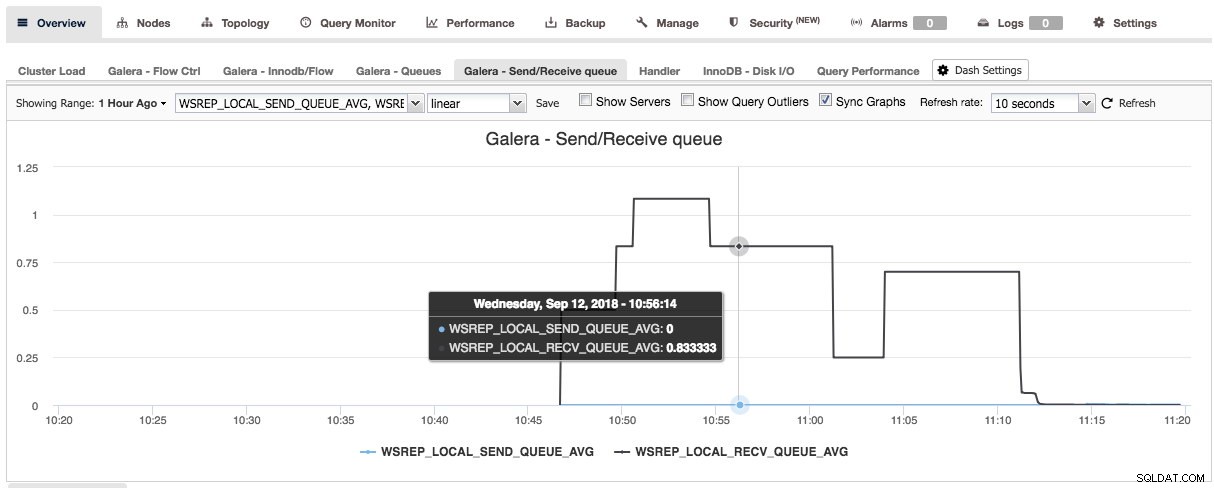
Podobnie możesz to zrobić również dla PostgreSQL, na przykład możemy monitorować trafione bloki współdzielone w porównaniu z blokami odczytanymi:
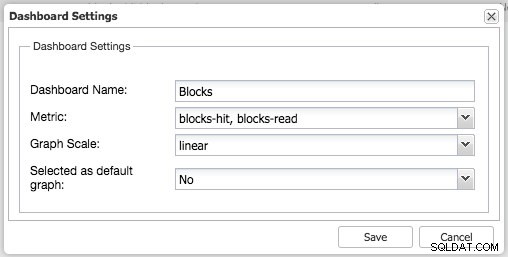
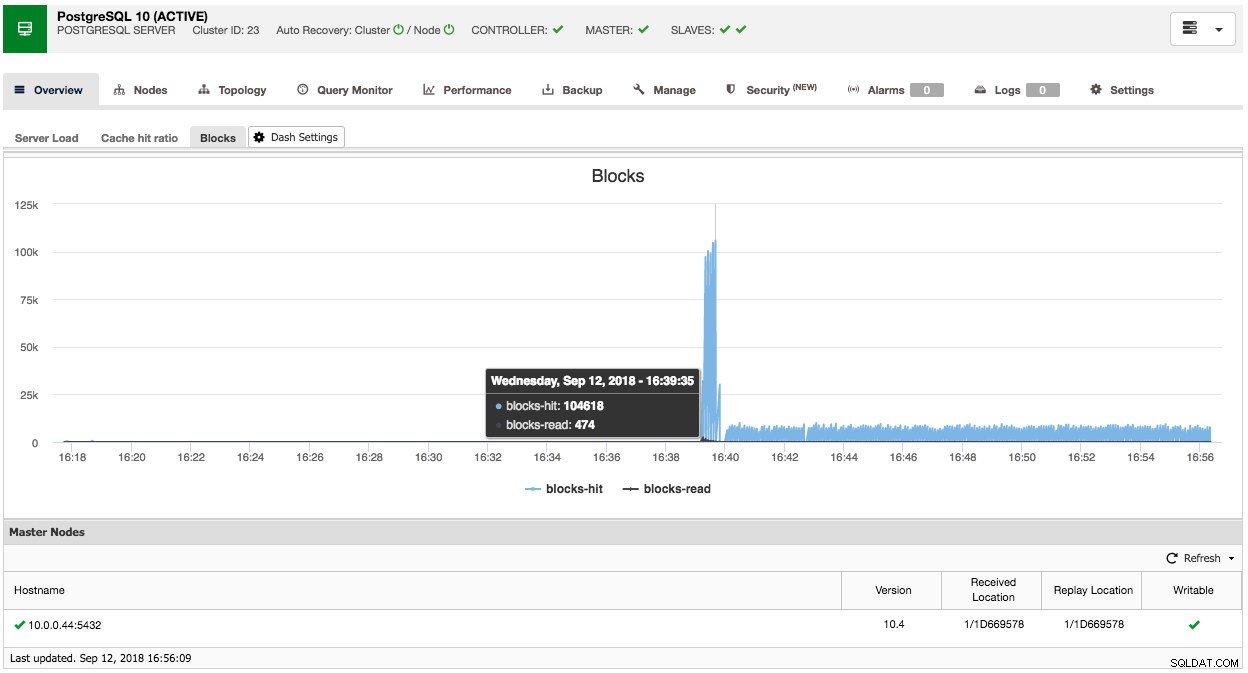
Jak widać, dostosowanie własnego (domyślnego) pulpitu nawigacyjnego jest stosunkowo łatwe.
Omówienie klastra — monitor zapytań
Karta Monitor zapytań jest dostępna zarówno dla konfiguracji opartych na MySQL, jak i PostgreSQL i składa się z trzech pulpitów nawigacyjnych:Najpopularniejsze zapytania, Uruchamianie zapytań i Elementy odstające zapytań.
W panelu Uruchomione zapytania znajdziesz wszystkie aktualnie uruchomione zapytania. Jest to w zasadzie odpowiednik polecenia SHOW FULL PROCESSLIST w bazie danych MySQL.
Najpopularniejsze zapytania i wartości odstające zapytań opierają się na danych wejściowych wolnego dziennika zapytań lub schematu wydajności. Korzystanie ze schematu wydajności jest zawsze zalecane i będzie używane automatycznie, jeśli jest włączone. W przeciwnym razie ClusterControl użyje dziennika powolnych zapytań MySQL do przechwycenia uruchomionych zapytań. Aby zapobiec nadmiernemu ingerowaniu w ClusterControl i zbyt dużemu rozrostowi dziennika powolnych zapytań, ClusterControl będzie próbkować dziennik powolnych zapytań, włączając go i wyłączając. Ta pętla jest domyślnie ustawiona na 1 sekundę przechwytywania i long_query_time jest ustawiony na 0,5 sekundy. Jeśli chcesz zmienić te ustawienia dla swojego klastra, możesz to zmienić w Ustawienia -> Monitor zapytań .
Najpopularniejsze zapytania, jak sama nazwa wskazuje, pokażą najpopularniejsze zapytania, które były próbkowane. Możesz je sortować według różnych kolumn:na przykład częstotliwość, średni czas wykonania, całkowity czas wykonania lub czas odchylenia standardowego:
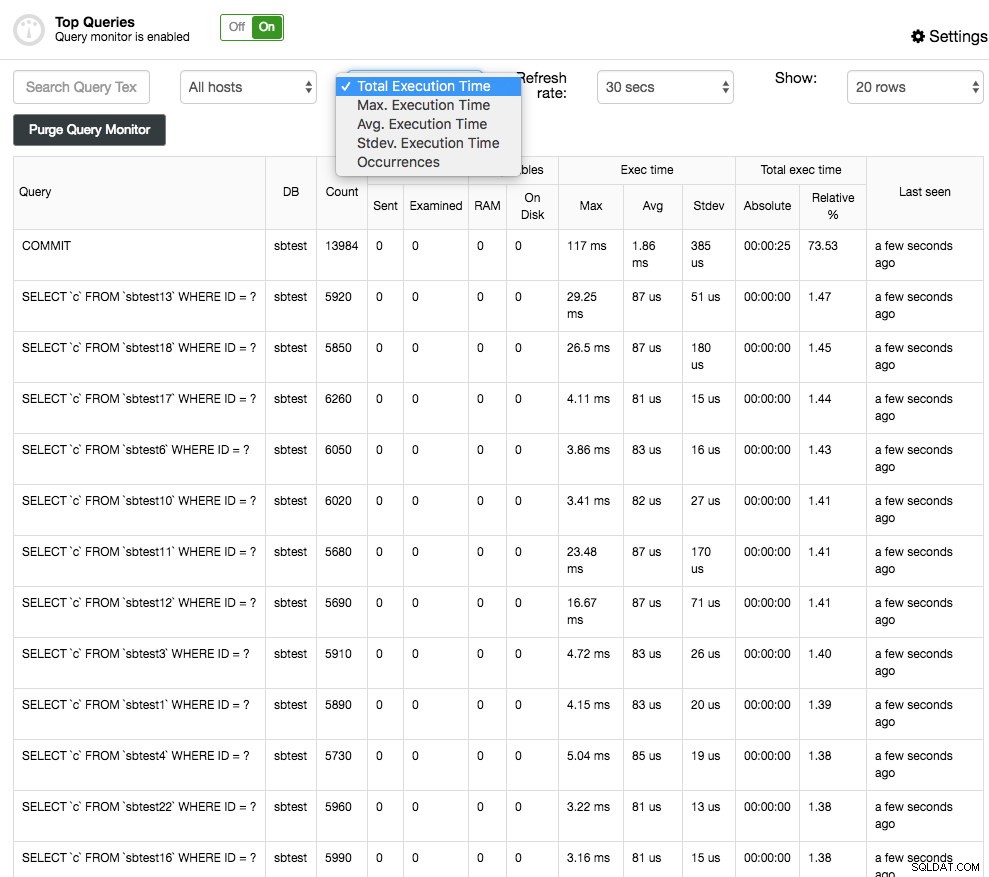
Możesz uzyskać więcej szczegółów na temat zapytania, wybierając je, a to zaprezentuje plan wykonania zapytania (jeśli jest dostępny) oraz wskazówki/wskazówki dotyczące optymalizacji. Wartości odstające zapytań są podobne do Najpopularniejsze zapytania, ale umożliwiają filtrowanie zapytań według hosta i porównywanie ich w czasie.
Omówienie klastra — operacje
Podobnie do systemów PostgreSQL i MySQL, klastry MongoDB mają przegląd operacji i są podobne do uruchomionych zapytań MySQL. Ten przegląd jest podobny do wydawania polecenia db.currentOp() w MongoDB.
Omówienie klastra – wydajność
MySQL/Galera
Karta Wydajność jest prawdopodobnie najlepszym miejscem do znalezienia ogólnej wydajności i kondycji klastrów. W przypadku MySQL i Galera składa się on ze strony Przegląd, Doradców, przeglądów statusu/zmiennych, Analizatora schematu i Dziennika transakcji.
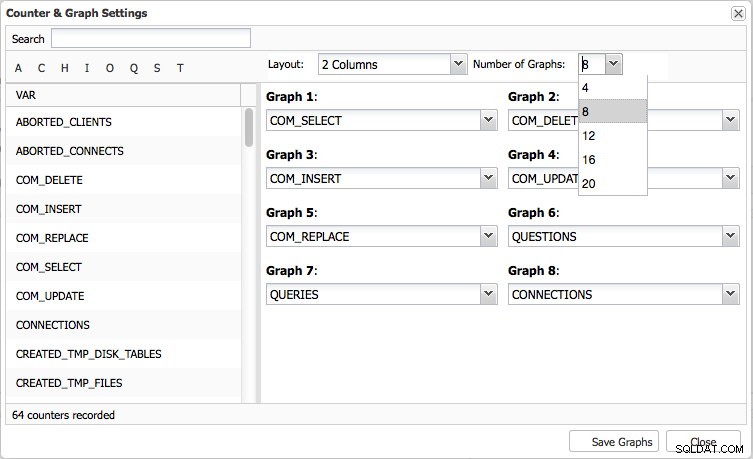
Strona Przegląd zawiera przegląd wykresu najważniejszych metryk w klastrze. To oczywiście różni się w zależności od typu klastra. Osiem wskaźników zostało ustawionych domyślnie, ale możesz łatwo ustawić własne – w razie potrzeby do 20 wykresów:
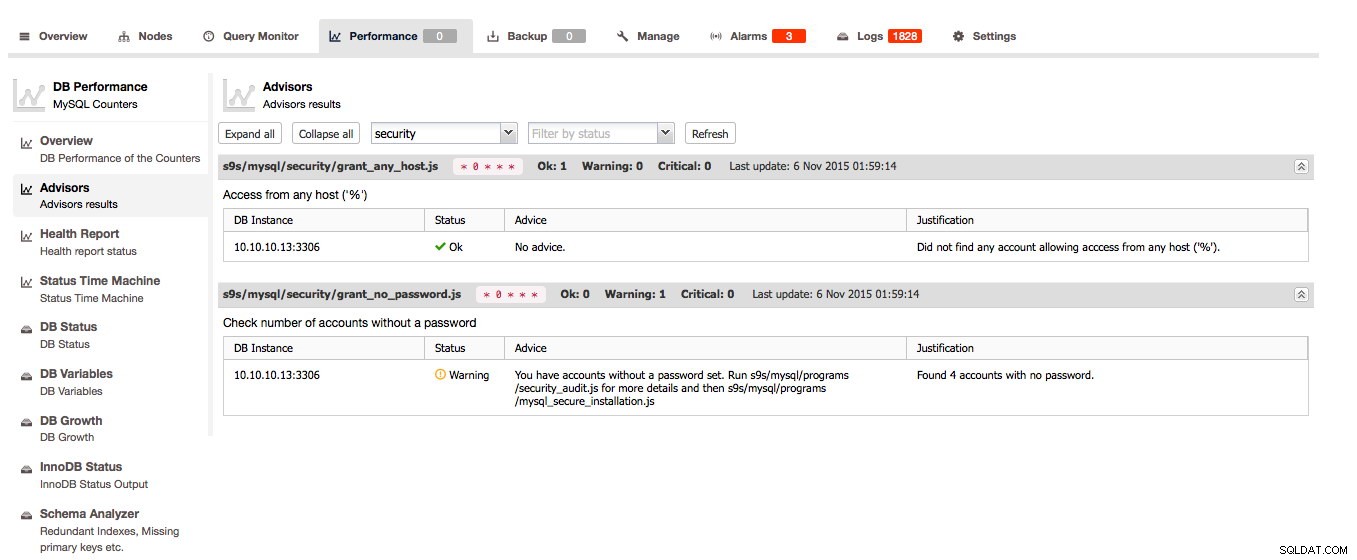
Advisors to jedna z kluczowych funkcji ClusterControl:Advisors to skryptowe kontrole, które można uruchomić na żądanie. Doradcy mogą ocenić prawie każdy znany fakt dotyczący hosta i/lub klastra i wydać opinię na temat stanu hosta i/lub klastra, a nawet mogą udzielić porady, jak rozwiązać problemy lub ulepszyć hosty!
Najlepsza część jeszcze przed nami:możesz tworzyć własne kontrole w Developer Studio (ClusterControl -> Manage -> Developer Studio ), uruchamiaj je w regularnych odstępach czasu i używaj ich ponownie w sekcji Doradcy. Na początku tego roku pisaliśmy o tej nowej funkcji na blogu.
Pominiemy przegląd stanu/zmiennych MySQL i Galera, ponieważ jest to przydatne w celach informacyjnych, ale nie w tym poście na blogu:wystarczy, że wiesz, że jest tutaj.
Załóżmy teraz, że Twoja baza danych rośnie, ale chcesz wiedzieć, jak szybko rosła w ciągu ostatniego tygodnia. Możesz śledzić wzrost wielkości danych i indeksów bezpośrednio w ClusterControl:
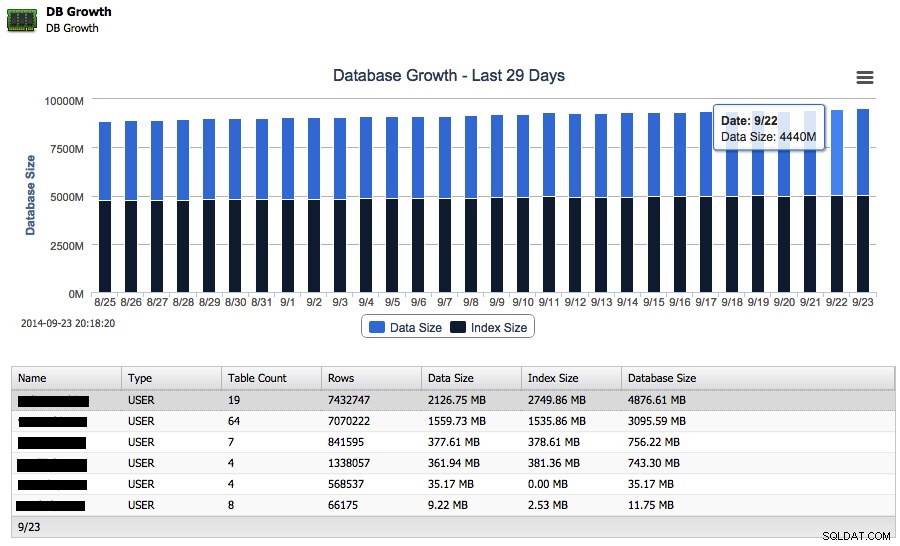
Oprócz całkowitego wzrostu na dysku może również zgłosić 25 największych schematów.
Inną ważną funkcją jest Analizator schematu w ClusterControl:
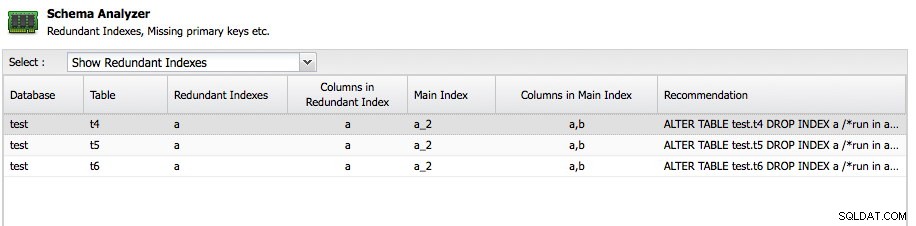
ClusterControl przeanalizuje Twoje schematy i wyszuka nadmiarowe indeksy, tabele MyISAM i tabele bez klucza podstawowego. Oczywiście utrzymanie tabeli bez klucza podstawowego zależy wyłącznie od Ciebie, ponieważ niektóre aplikacje mogły go w ten sposób utworzyć, ale przynajmniej dobrze jest uzyskać poradę za darmo. Analizator schematu zaleca nawet niezbędne oświadczenie ALTER, aby rozwiązać problem.
PostgreSQL
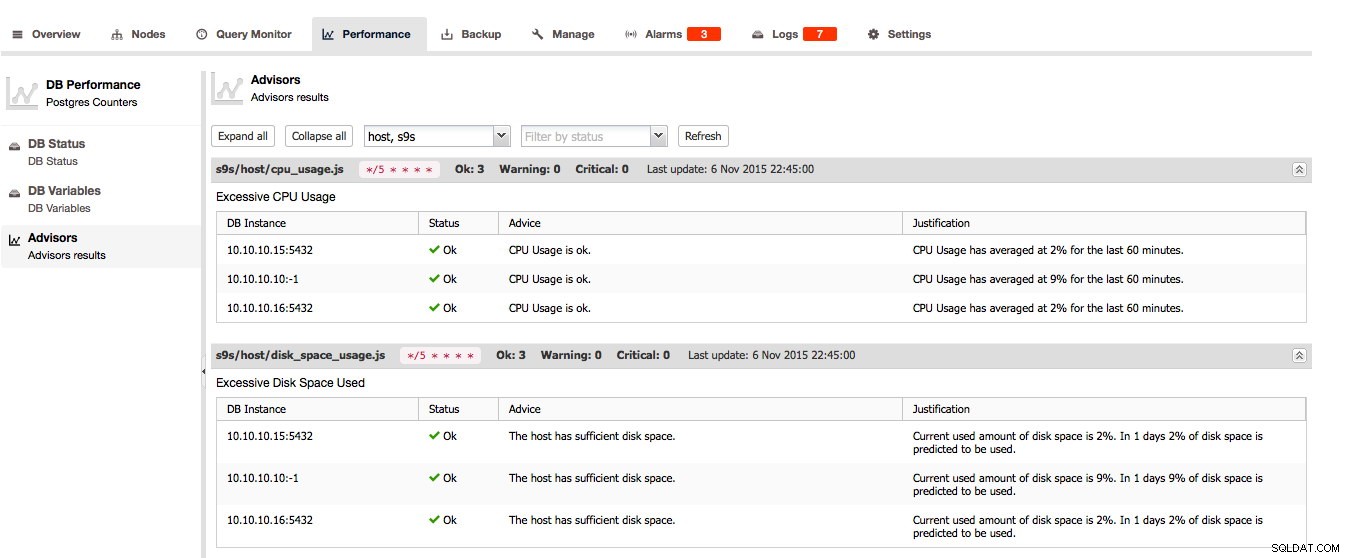
W przypadku PostgreSQL Doradcy, stan bazy danych i zmienne bazy danych można znaleźć tutaj:
MongoDB
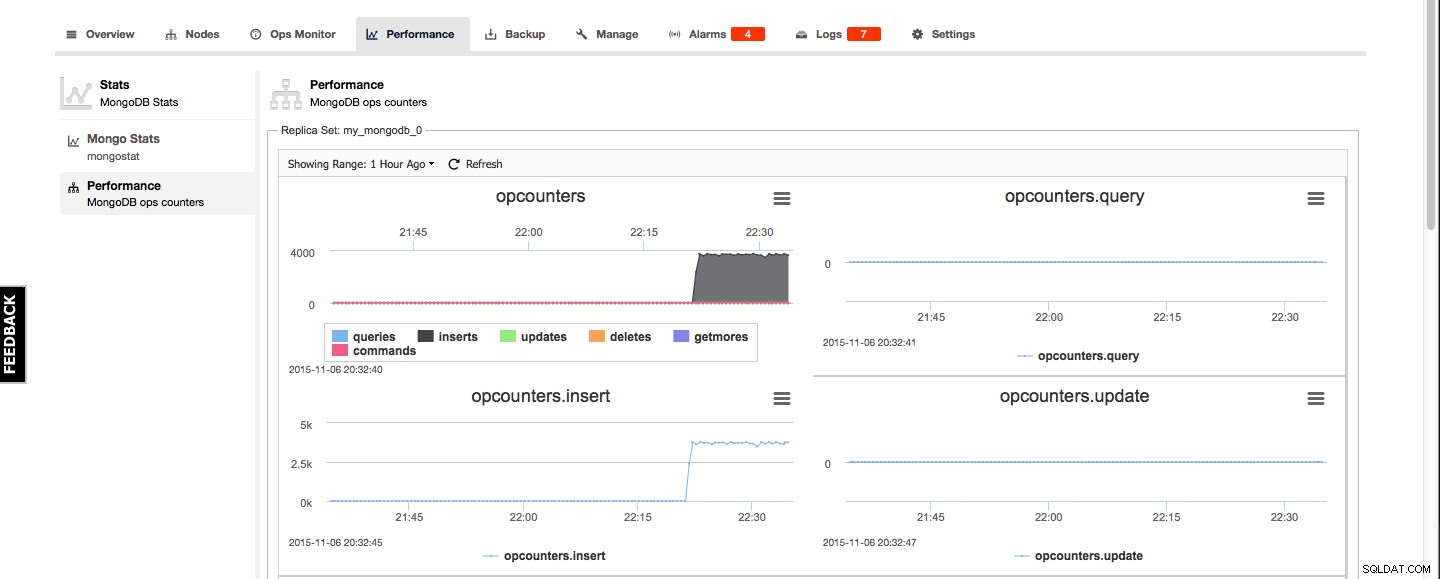
W przypadku MongoDB statystyki Mongo i przegląd wydajności można znaleźć w zakładce Wydajność. Statystyki Mongo to przegląd danych wyjściowych mongostatu, a przegląd wydajności zapewnia dobry graficzny przegląd liczników operacji MongoDB:
Ostateczne myśli
Pokazaliśmy, jak zwracać uwagę na najważniejsze funkcje monitorowania i kontroli stanu ClusterControl. Oczywiście to dopiero początek podróży, ponieważ wkrótce rozpoczniemy kolejną serię blogów o możliwościach Developer Studio i o tym, jak możesz wykonać większość własnych kontroli. Należy również pamiętać, że nasze wsparcie dla MongoDB i PostgreSQL nie jest tak obszerne, jak nasz zestaw narzędzi MySQL, ale stale to ulepszamy.
Możesz zadać sobie pytanie, dlaczego pominęliśmy monitorowanie wydajności i kontrole kondycji HAProxy, ProxySQL i MaxScale. Zrobiliśmy to celowo, ponieważ seria blogów obejmowała tylko dotychczasowe wdrożenia klastrów, a nie wdrażanie komponentów HA. To jest temat, który omówimy następnym razem.



