Chociaż ten silnik pamięci masowej był przestarzały już w MongoDB w wersji 4.0, zawiera kilka ważnych funkcji. MMAPv1 to oryginalny silnik przechowywania w MongoDB i jest oparty na zmapowanych plikach. Tylko 64-bitowa architektura Intel (x86_64) obsługuje ten silnik pamięci masowej.
MMAPv1 zapewnia doskonałą wydajność przy obciążeniach dzięki...
- Duże aktualizacje
- Wysokie odczyty
- Wkładki o dużej objętości
- Wysokie wykorzystanie pamięci systemowej
Architektura MMAPv1
MMAPv1 to system oparty na drzewie B, który obsługuje wiele funkcji, takich jak interakcja pamięci masowej i zarządzanie pamięcią, w systemie operacyjnym.
Była to domyślna baza danych dla MongoDB dla wersji wcześniejszych niż 3.2, do czasu wprowadzenia silnika pamięci masowej WiredTiger. Jego nazwa wzięła się stąd, że do uzyskiwania dostępu do danych wykorzystuje pliki mapowane w pamięci. Czyni to poprzez bezpośrednie ładowanie i modyfikowanie zawartości plików, które znajdują się w pamięci wirtualnej za pomocą metodologii mmap() syscall.
Wszystkie rekordy znajdują się na dysku w sposób ciągły iw przypadku, gdy dokument staje się większy niż przydzielony rozmiar rekordu, MongoDB przydziela nowy rekord. W przypadku MMAPv1 jest to korzystne dla sekwencyjnego dostępu do danych, ale jednocześnie jest to ograniczenie, ponieważ wiąże się z kosztami czasu, ponieważ wszystkie indeksy dokumentów wymagają aktualizacji, co może skutkować fragmentacją pamięci.
Podstawowa architektura silnika pamięci masowej MMAPv1 jest pokazana poniżej.
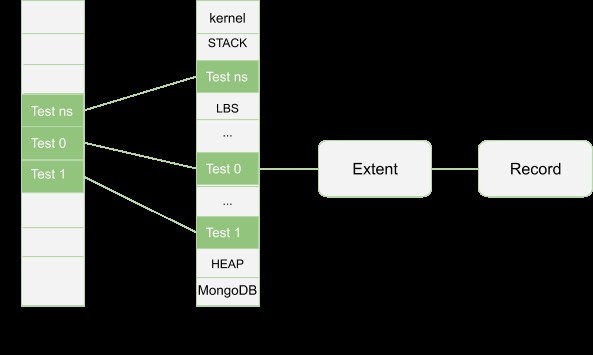
Jak wspomniano powyżej, jeśli rozmiar dokumentu przekracza przydzielony rozmiar rekordu, spowoduje to realokację, co nie jest dobrą rzeczą. Aby tego uniknąć, silnik MMAPv1 wykorzystuje alokację mocy 2 wielkości, dzięki czemu każdy dokument jest przechowywany w rekordzie, który zawiera sam dokument (w tym dodatkową przestrzeń znaną jako dopełnienie). Dopełnienie jest następnie używane, aby umożliwić wzrost dokumentu, który może wynikać z aktualizacji, jednocześnie zmniejszając szanse na realokację. W przeciwnym razie, jeśli nastąpi realokacja, może dojść do fragmentacji pamięci. Wyściółka zapewnia dodatkową przestrzeń w celu poprawy wydajności, a tym samym zmniejszenia fragmentacji. W przypadku obciążeń z dużą liczbą operacji wstawiania, aktualizacji lub usuwania, moc alokacji 2 powinna być najbardziej preferowana, podczas gdy alokacja dokładnego dopasowania jest idealna w przypadku kolekcji, które nie obejmują żadnych obciążeń związanych z aktualizacją ani usuwaniem.
Moc alokacji 2 wielkości
Aby zapewnić płynny wzrost dokumentów, strategia ta jest stosowana w aparacie pamięci masowej MMAPv1. Każdy rekord ma rozmiar w bajtach, który jest potęgą 2, czyli (32, 64, 128, 256, 512...2MB). 2MB jest domyślnym większym limitem każdego dokumentu, który go przekracza, jego pamięć jest zaokrąglana do najbliższej wielokrotności 2MB. Na przykład, jeśli dokument ma 200 MB, ten rozmiar zostanie zaokrąglony do 256 MB, a wymiana przestrzeni o 56 MB będzie dostępna dla każdego dodatkowego wzrostu. Dzięki temu dokumenty będą się powiększać, zamiast wyzwalać ponowne przypisanie, które system będzie musiał wykonać, gdy dokumenty dotrą do ich ograniczenia dostępnej przestrzeni.
Zasługi alokacji wielkości mocy 2
- Ponowne wykorzystanie uwolnionych rekordów w celu zmniejszenia fragmentacji: Zgodnie z tą koncepcją, rekordy są kwantyzowane w pamięci, aby mieć stały rozmiar, który jest wystarczająco duży, aby pomieścić nowe dokumenty, które pasowałyby do przydzielonej przestrzeni utworzonej przez wcześniejsze usunięcie lub przeniesienie dokumentu.
- Ogranicza przenoszenie dokumentów: Jak wspomniano wcześniej, domyślnie wstawki i aktualizacje MongoDB, które powodują, że rozmiar dokumentu jest większy niż ustawiony rozmiar rekordu, spowoduje również aktualizację indeksów. Oznacza to po prostu, że dokumenty zostały przeniesione. Jednak gdy w dokumencie jest wystarczająco dużo miejsca na wzrost, dokument nie zostanie przeniesiony, stąd mniej aktualizacji indeksów.
Wykorzystanie pamięci
Cała wolna pamięć na komputerze w aparacie pamięci masowej MMAPv1 jest używana jako pamięć podręczna. Odpowiednio zwymiarowane zestawy robocze i optymalną wydajność osiąga się dzięki zestawowi roboczemu, który mieści się w pamięci. Poza tym co 60 sekund MMAPv1 opróżnia zmiany danych na dysk, zapisując je w pamięci podręcznej. Wartość tę można zmienić tak, aby płukanie mogło być wykonywane często. Ponieważ cała wolna pamięć jest używana jako pamięć podręczna, nie bądź zszokowany, że narzędzia do monitorowania zasobów systemowych wskażą, że MongoDB zużywa dużo pamięci, ponieważ to użycie jest dynamiczne.
Zalety silnika pamięci masowej MMAPv1
- Zmniejszona fragmentacja na dysku podczas korzystania ze strategii wstępnej alokacji.
- Bardzo wydajne odczyty, gdy zestaw roboczy został skonfigurowany tak, aby mieścił się w pamięci.
- Aktualizacje na miejscu, tj. aktualizacje poszczególnych pól mogą skutkować przechowywaniem większej ilości danych, a tym samym poprawiają aktualizację dużych dokumentów przy minimalnej liczbie współbieżnych autorów.
- Przy małej liczbie współbieżnych programów zapisujących wydajność zapisu można poprawić dzięki koncepcji częstego przesyłania danych na dysk.
- Blokowanie na poziomie kolekcji ułatwia operacje zapisu. Schemat blokowania jest jednym z najważniejszych czynników wpływających na wydajność bazy danych. W takim przypadku tylko 1 klient może jednocześnie uzyskać dostęp do bazy danych. Stwarza to scenariusz, w którym operacje przebiegają szybciej niż w przypadku przedstawiania w sposób szeregowy przez aparat pamięci masowej.
Ograniczenia mechanizmu pamięci masowej MMAPv1
- Wysokie wykorzystanie przestrzeni podczas iteracji. MMAPv1 nie ma strategii kompresji dla systemu plików, stąd nadmierna alokacja przestrzeni rekordów.
- Ograniczenie dostępu do kolekcji dla wielu klientów podczas wykonywania operacji zapisu. MMAPv1 używa strategii blokowania na poziomie kolekcji, co oznacza, że 2 lub więcej klientów nie może uzyskać dostępu do tej samej kolekcji w tym samym czasie, dlatego zapis blokuje wszystkie odczyty do tej kolekcji. Prowadzi to do zgrubnej współbieżności, która uniemożliwia skalowanie silnika MMAPv1.
- Awaria systemu może potencjalnie spowodować utratę danych, jeśli opcja kronikowania nie jest włączona. Jednak nawet jeśli tak jest, okno jest zbyt małe, ale przynajmniej może uchronić Cię przed dużym scenariuszem utraty danych.
- Nieefektywne wykorzystanie pamięci. Podczas korzystania ze strategii wstępnej alokacji niektóre dokumenty zajmą więcej miejsca na dysku niż same dane.
- Jeżeli rozmiar zestawu roboczego przekracza przydzieloną pamięć, wydajność w dużym stopniu spada. Poza tym znaczny wzrost liczby dokumentów po początkowym przechowywaniu może wywołać dodatkowe operacje we/wy, a tym samym spowodować problemy z wydajnością.
Porównanie silników pamięci masowej MMAPv1 i WiredTiger
| Kluczowa funkcja | MMAPv1 | WiredTiger |
|---|---|---|
| Wydajność procesora | Dodanie większej liczby rdzeni procesora niestety nie zwiększa wydajności | Wydajność poprawia się dzięki systemom wielordzeniowym |
| Szyfrowanie | Ponieważ używane są pliki mapowane w pamięci, nie obsługuje żadnego szyfrowania | Szyfrowanie zarówno danych przesyłanych, jak i pozostałych jest dostępne zarówno w MongoDB Enterprise, jak i w instalacji Beta |
| Skalowalność | Równoczesne zapisy wynikające z blokowania na poziomie kolekcji uniemożliwiają skalowanie w poziomie. | Wysokie szanse na skalowanie, ponieważ najniższym poziomem blokowania jest sam dokument. |
| Dostrajanie | Bardzo małe szanse na dostrojenie tego silnika pamięci | Wokół zmiennych, takich jak rozmiar pamięci podręcznej, interwały punktów kontrolnych i bilety odczytu/zapisu, można dokonać wielu zmian |
| Kompresja danych | Brak kompresji danych, dlatego można użyć więcej miejsca | Dostępne są metody kompresji Snappy i zlib, dlatego dokumenty mogą zajmować mniej miejsca niż w MMAPv1 |
| Transakcje atomowe | Dotyczy tylko jednego dokumentu | Od wersji 4.0 transakcja atomowa na wielu dokumentach jest obsługiwana. |
| Pamięć | Cała wolna pamięć na komputerze jest używana jako jej pamięć podręczna | Wykorzystywana jest pamięć podręczna systemu plików i wewnętrzna pamięć podręczna |
| Aktualizacje | Obsługuje aktualizacje w miejscu, dzięki czemu doskonale sprawdza się w przypadku obciążeń z dużymi wstawkami, odczytami i aktualizacjami w miejscu | Nie obsługuje aktualizacji na miejscu. Cały dokument musi zostać napisany od nowa. |
Wniosek
Przychodząc do wyboru silnika pamięci masowej dla bazy danych, wiele osób nie wie, który wybrać. Wybór zwykle zależy od obciążenia pracą, któremu zostanie poddany. Ogólnie rzecz biorąc, MMAPv1 byłby złym wyborem i dlatego MongoDB dokonał wielu postępów w opcji WiredTiger. Jednak nadal może przewyższyć niektóre inne silniki pamięci masowej, w zależności od przypadku użycia, na przykład w przypadku, gdy musisz wykonywać tylko obciążenia odczytu lub musisz przechowywać wiele oddzielnych kolekcji z dużymi dokumentami, w których 1 lub 2 pola są często aktualizowane.



