Co to jest indeksowanie?
Indeksowanie jest ważną koncepcją w świecie baz danych. Główną zaletą tworzenia indeksu na dowolnym polu jest szybszy dostęp do danych. Optymalizuje proces przeszukiwania i dostępu do bazy danych. Rozważ ten przykład, aby to zrozumieć.
Gdy jakikolwiek użytkownik poprosi o konkretny wiersz z bazy danych, co zrobi system DB? Zacznie od pierwszego wiersza i sprawdzi, czy to jest ten, którego chce użytkownik? Jeśli tak, zwróć ten wiersz, w przeciwnym razie kontynuuj wyszukiwanie do końca.
Ogólnie rzecz biorąc, kiedy definiujesz indeks w określonym polu, system DB utworzy uporządkowaną listę wartości tego pola i zapisze ją w innej tabeli. Każdy wpis w tej tabeli będzie wskazywał odpowiednie wartości w oryginalnej tabeli. Tak więc, gdy użytkownik próbuje wyszukać dowolny wiersz, najpierw wyszuka wartość w tabeli indeksów za pomocą algorytmu wyszukiwania binarnego i zwróci odpowiednią wartość z oryginalnej tabeli. Ten proces zajmie mniej czasu, ponieważ używamy wyszukiwania binarnego zamiast wyszukiwania liniowego.
W tym artykule skupimy się na indeksowaniu MongoDB i zrozumiemy, jak tworzyć i używać indeksów w MongoDB.
Jak utworzyć indeks w kolekcji MongoDB?
Aby utworzyć indeks za pomocą powłoki Mongo, możesz użyć następującej składni:
db.collection.createIndex( <key and index type specification>, <options> )Przykład:
Aby utworzyć indeks w polu nazwy w kolekcji myColl:
db.myColl.createIndex( { name: -1 } )Typy indeksów MongoDB
-
Domyślny indeks _id
Jest to domyślny indeks, który zostanie utworzony przez MongoDB podczas tworzenia nowej kolekcji. Jeśli nie określisz żadnej wartości dla tego pola, _id będzie domyślnie kluczem podstawowym dla Twojej kolekcji, aby użytkownik nie mógł wstawić dwóch dokumentów z tymi samymi wartościami pól _id. Nie możesz usunąć tego indeksu z pola _id.
-
Indeks pojedynczego pola
Możesz użyć tego typu indeksu, jeśli chcesz utworzyć nowy indeks w dowolnym polu innym niż pole _id.
Przykład:
db.myColl.createIndex( { name: 1 } )Spowoduje to utworzenie pojedynczego klucza rosnącego indeksu w polu nazwy w kolekcji myColl
-
Indeks złożony
Możesz również utworzyć indeks na wielu polach za pomocą indeksów złożonych. Dla tego indeksu liczy się kolejność pól, w których są one zdefiniowane w indeksie. Rozważ ten przykład:
db.myColl.createIndex({ name: 1, score: -1 })Ten indeks najpierw posortuje kolekcję według nazwy w porządku rosnącym, a następnie dla każdej wartości nazwy posortuje według wartości punktacji w porządku malejącym.
-
Indeks wielokluczowy
Ten indeks może służyć do indeksowania danych tablicy. Jeśli dowolne pole w kolekcji ma jako wartość tablicę, możesz użyć tego indeksu, który utworzy osobne wpisy indeksu dla każdego elementu tablicy. Jeśli indeksowane pole jest tablicą, MongoDB automatycznie utworzy na nim indeks Multikey.
Rozważ ten przykład:
{ ‘userid’: 1, ‘name’: ‘mongo’, ‘addr’: [ {zip: 12345, ...}, {zip: 34567, ...} ] }Możesz utworzyć indeks Multikey w polu addr, wydając to polecenie w powłoce Mongo.
db.myColl.createIndex({ addr.zip: 1 }) -
Indeks geoprzestrzenny
Załóżmy, że zapisałeś niektóre współrzędne w kolekcji MongoDB. Aby utworzyć indeks dla tego typu pól (które zawierają dane geoprzestrzenne), możesz użyć indeksu geoprzestrzennego. MongoDB obsługuje dwa typy indeksów geoprzestrzennych.
-
Indeks 2D:Możesz użyć tego indeksu dla danych, które są przechowywane jako punkty na płaszczyźnie 2D.
db.collection.createIndex( { <location field> : "2d" } ) -
Indeks 2dsphere:użyj tego indeksu, gdy dane są przechowywane w formacie GeoJson lub w parach współrzędnych (długość, szerokość geograficzna)
db.collection.createIndex( { <location field> : "2dsphere" } ) -
-
Indeks tekstowy
Aby obsługiwać zapytania, które obejmują wyszukiwanie jakiegoś tekstu w kolekcji, możesz użyć indeksu tekstu.
Przykład:
db.myColl.createIndex( { address: "text" } ) -
Indeks haszowany
MongoDB obsługuje sharding na podstawie skrótu. Indeks haszowany oblicza skrót wartości indeksowanego pola. Indeks zaszyfrowany obsługuje fragmentowanie przy użyciu zaszyfrowanych kluczy podzielonych na fragmenty. Fragmentacja haszowana używa tego indeksu jako klucza fragmentu do partycjonowania danych w klastrze.
Przykład:
db.myColl.createIndex( { _id: "hashed" } )
-
Unikalny indeks
Ta właściwość zapewnia, że w indeksowanym polu nie ma zduplikowanych wartości. Jeśli podczas tworzenia indeksu zostaną znalezione jakiekolwiek duplikaty, odrzuci on te wpisy.
-
Rzadki indeks
Ta właściwość zapewnia, że wszystkie zapytania przeszukują dokumenty z zaindeksowanym polem. Jeśli jakikolwiek dokument nie ma zindeksowanego pola, zostanie odrzucony z zestawu wyników.
-
Indeks TTL
Ten indeks służy do automatycznego usuwania dokumentów z kolekcji po określonym przedziale czasu (TTL) . Jest to idealne rozwiązanie do usuwania dokumentów z dzienników zdarzeń lub sesji użytkowników.
Analiza wydajności
Rozważ zbiór wyników uczniów. Zawiera dokładnie 3000000 dokumentów. W tej kolekcji nie utworzyliśmy żadnych indeksów. Zobacz ten obraz poniżej, aby zrozumieć schemat.
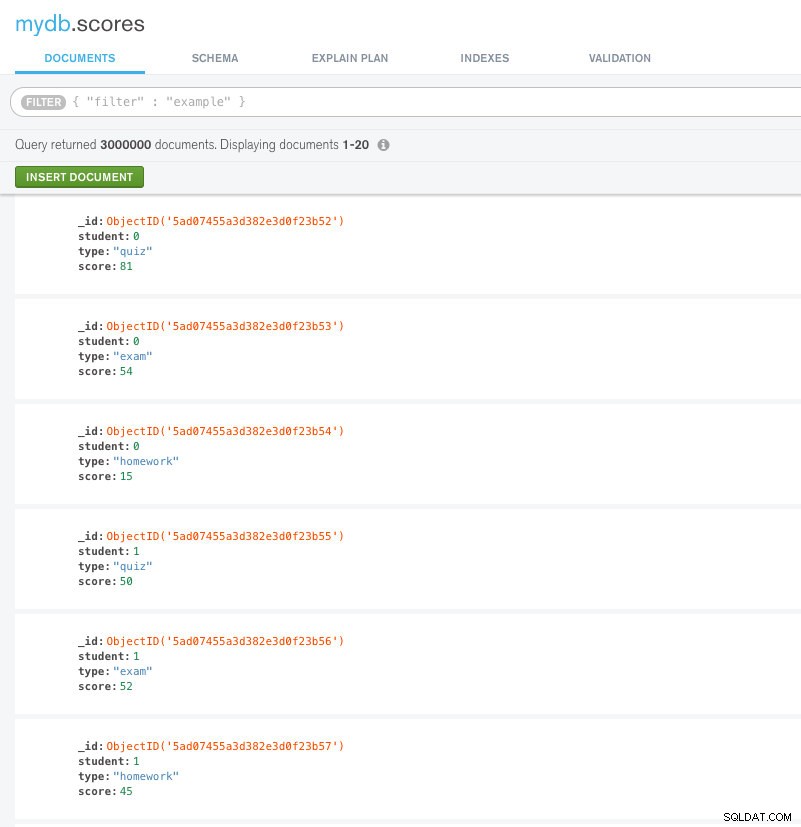 Przykładowe dokumenty w kolekcji partytury
Przykładowe dokumenty w kolekcji partytury Teraz rozważ to zapytanie bez żadnych indeksów:
db.scores.find({ student: 585534 }).explain("executionStats")Wykonanie tego zapytania zajmuje 1155 ms. Oto dane wyjściowe. Wyszukaj wynik w polu ExecutionTimeMillis.
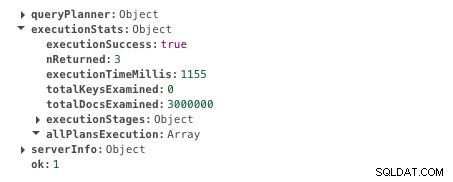 Czas wykonania bez indeksowania
Czas wykonania bez indeksowania Teraz stwórzmy indeks na polu studenta. Aby utworzyć indeks, uruchom to zapytanie.
db.scores.createIndex({ student: 1 })Teraz to samo zapytanie zajmuje 0 ms.
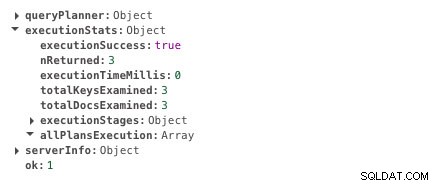 Czas wykonania z indeksowaniem
Czas wykonania z indeksowaniem Widać wyraźnie różnicę w czasie realizacji. To prawie natychmiastowe. Na tym polega siła indeksowania.
Wniosek
Jednym z oczywistych wniosków jest:tworzenie indeksów. Na podstawie zapytań możesz zdefiniować różne typy indeksów w swoich kolekcjach. Jeśli nie tworzysz indeksów, każde zapytanie przeskanuje pełne kolekcje, co zajmuje dużo czasu, przez co Twoja aplikacja działa bardzo wolno i zużywa dużo zasobów Twojego serwera. Z drugiej strony nie twórz zbyt wielu indeksów, ponieważ tworzenie niepotrzebnych indeksów spowoduje dodatkowy czas na wstawianie, usuwanie i aktualizację. Kiedy wykonujesz jakąkolwiek z tych operacji na indeksowanym polu, musisz wykonać tę samą operację na drzewie indeksu, co zajmuje trochę czasu. Indeksy są przechowywane w pamięci RAM, więc tworzenie nieistotnych indeksów może zająć miejsce w pamięci RAM i spowolnić serwer.



