ClusterControl 1.7.1 wprowadził nową funkcję, która umożliwia tworzenie kopii zapasowych serwera ClusterControl i przywracanie go (wraz z metadanymi dotyczącymi zarządzanych baz danych) na innym serwerze. Tworzy kopię zapasową aplikacji ClusterControl oraz wszystkich jej danych konfiguracyjnych. Migracja ClusterControl do nowego serwera była kiedyś uciążliwa, ale już nie.
Ten post na blogu przedstawia tę nową funkcję.
Przeniesiemy ClusterControl z jednego serwera na drugi, zachowując wszystkie konfiguracje i ustawienia.
Pokażemy Ci również, jak przenieść zarządzanie klastrem z jednej instancji ClusterControl do innej.
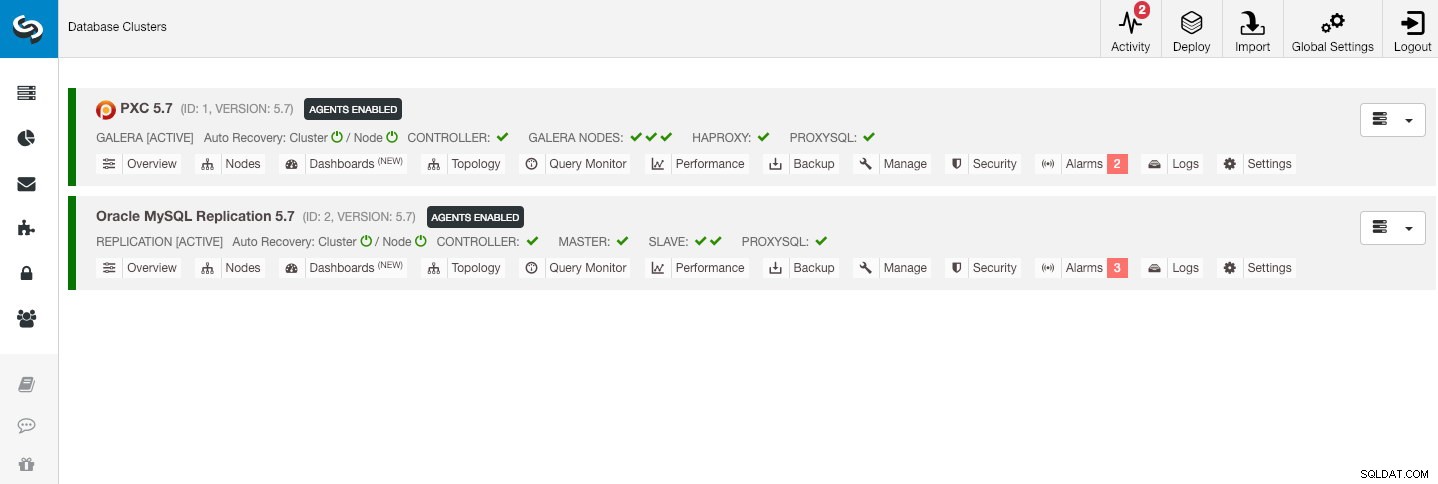
Nasza przykładowa architektura rozpoczęła się od dwóch klastrów produkcyjnych (pokazanych na poniższym zrzucie ekranu):
- Identyfikator klastra 1:3 węzły Galera (PXC) + 1 HAProxy + 1 ProxySQL (5 węzłów)
- Identyfikator klastra 2:1 główny MySQL + 2 podrzędne MySQL + 1 ProxySQL (4 węzły)
Wprowadzenie
ClusterControl CLI (s9s) to narzędzie interfejsu wiersza poleceń do interakcji, kontroli i zarządzania klastrami baz danych przy użyciu platformy ClusterControl. Począwszy od wersji 1.4.1, skrypt instalacyjny automatycznie zainstaluje ten pakiet w węźle ClusterControl.
Istnieją zasadniczo 4 nowe opcje wprowadzone w poleceniu „kopia zapasowa s9s”, które można wykorzystać do osiągnięcia naszego celu:
| Flaga | Opis |
|---|---|
| --zapisz-kontroler | Zapisuje stan kontrolera w archiwum tar. |
| --przywróć-kontroler | Przywraca cały kontroler z wcześniej utworzonego archiwum tar (utworzonego za pomocą --save-controller |
| --save-cluster-info | Zapisuje informacje kontrolera o jednym klastrze. |
| --przywracanie-informacje o klastrze | Przywraca informacje, które kontroler posiada o klastrze z wcześniej utworzonego pliku archiwum. |
W tym poście na blogu zostaną omówione przykłady użycia tych opcji. W tej chwili znajdują się na etapie kandydata do wydania i są dostępne tylko za pośrednictwem narzędzia ClusterControl CLI.
Tworzenie kopii zapasowej ClusterControl
W tym celu serwer ClusterControl musi być w wersji co najmniej 1.7.1 lub nowszej. Aby wykonać kopię zapasową kontrolera ClusterControl, po prostu uruchom następujące polecenie w węźle ClusterControl jako użytkownik root (lub za pomocą sudo):
$ s9s backup \
--save-controller \
--backup-directory=$HOME/ccbackup \
--output-file=controller.tar.gz \
--log--output-file musi być nazwą pliku lub ścieżką fizyczną (jeśli chcesz pominąć flagę --backup-directory), a plik nie może wcześniej istnieć. ClusterControl nie zastąpi pliku wyjściowego, jeśli już istnieje. Określając --log, poczeka aż zadanie zostanie wykonane, a logi zadania zostaną wyświetlone w terminalu. Dostęp do tych samych dzienników można uzyskać za pośrednictwem interfejsu użytkownika ClusterControl w sekcji Aktywność -> Zadania -> Zapisz kontroler :
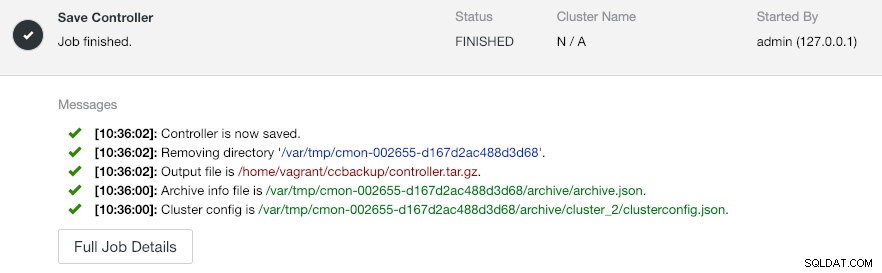
Zadanie „Zapisz kontroler” zasadniczo wykonuje następujące procedury:
- Pobierz konfigurację kontrolera i wyeksportuj ją do JSON
- Eksportuj bazę danych CMON jako plik zrzutu MySQL
- Dla każdego klastra bazy danych:
- Pobierz konfigurację klastra i wyeksportuj ją do JSON
W wyniku możesz zauważyć, że znalezione zadanie to N + 1 klaster, na przykład „Znaleziono 3 klastry do zapisania”, mimo że mamy tylko dwa klastry bazy danych. Obejmuje to identyfikator klastra 0, który ma szczególne znaczenie w ClusterControl jako globalnie zainicjowanym klastrze. Jednak nie należy do komponentu CmonCluster, który jest klastrem bazy danych zarządzanym przez ClusterControl.
Przywracanie ClusterControl do nowego serwera ClusterControl
Jeśli ClusterControl jest już zainstalowany na nowym serwerze, chcielibyśmy przeprowadzić migrację klastrów baz danych, które mają być zarządzane przez nowy serwer. Poniższy diagram ilustruje nasze ćwiczenie migracji:
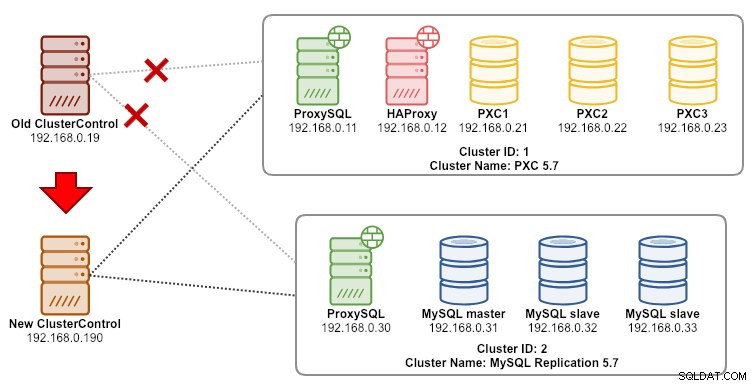
Najpierw przenieś kopię zapasową ze starego serwera na nowy serwer:
$ scp $HOME/ccbackup/controller.tar.gz 192.168.0.190:~Zanim wykonamy przywracanie, musimy skonfigurować bezhasłowe SSH do wszystkich węzłów z nowego serwera ClusterControl:
$ ssh-copy-id 192.168.0.11 #proxysql cluster 1
$ ssh-copy-id 192.168.0.12 #proxysql cluster 1
$ ssh-copy-id 192.168.0.21 #pxc cluster 1
$ ssh-copy-id 192.168.0.22 #pxc cluster 1
$ ssh-copy-id 192.168.0.23 #pxc cluster 1
$ ssh-copy-id 192.168.0.30 #proxysql cluster 2
$ ssh-copy-id 192.168.0.31 #mysql cluster 2
$ ssh-copy-id 192.168.0.32 #mysql cluster 2
$ ssh-copy-id 192.168.0.33 #mysql cluster 2Następnie na nowym serwerze wykonaj przywracanie:
$ s9s backup \
--restore-controller \
--input-file=$HOME/controller.tar.gz \
--debug \
--logNastępnie musimy zsynchronizować klaster w interfejsie użytkownika, przechodząc do Ustawienia globalne -> Rejestracje klastra -> Synchronizuj klaster . Następnie, jeśli wrócisz do głównego pulpitu nawigacyjnego ClusterControl, zobaczysz następujące informacje:
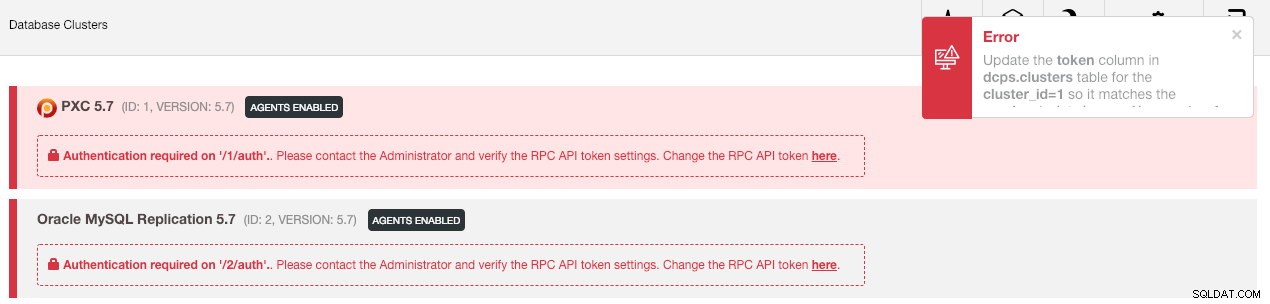
Nie panikować. Nowy interfejs użytkownika ClusterControl nie może pobrać danych monitorowania i zarządzania z powodu nieprawidłowego tokenu interfejsu API RPC. Musimy tylko odpowiednio go zaktualizować. Najpierw pobierz wartość rpc_key dla odpowiednich klastrów:
$ cat /etc/cmon.d/cmon_*.cnf | egrep 'cluster_id|rpc_key'
cluster_id=1
rpc_key=8fgkzdW8gAm2pL4L
cluster_id=2
rpc_key=tAnvKME53N1n8vCCW interfejsie użytkownika kliknij link „tutaj” w wierszu „Zmień token interfejsu API RPC tutaj”. Pojawi się następujące okno dialogowe:
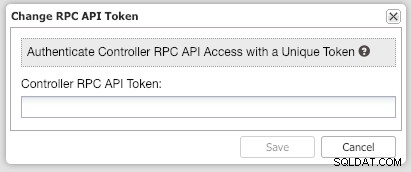
Wklej odpowiednią wartość rpc_key w polu tekstowym i kliknij Zapisz. Powtórz dla następnego klastra. Poczekaj chwilę, a lista klastrów powinna zostać automatycznie odświeżona.
Ostatnim krokiem jest naprawienie uprawnień użytkownika cmon MySQL dla nowych zmian adresu IP ClusterControl, 192.168.0.190. Zaloguj się do jednego z węzłów PXC i uruchom następujące polecenie:
$ mysql -uroot -p -e 'GRANT ALL PRIVILEGES ON *.* TO example@sqldat.com"192.168.0.190" IDENTIFIED BY "<password>" WITH GRANT OPTION';
** Zastąp
Po skonfigurowaniu uprawnień powinieneś zobaczyć, że lista klastrów jest zielona, podobnie jak stara:
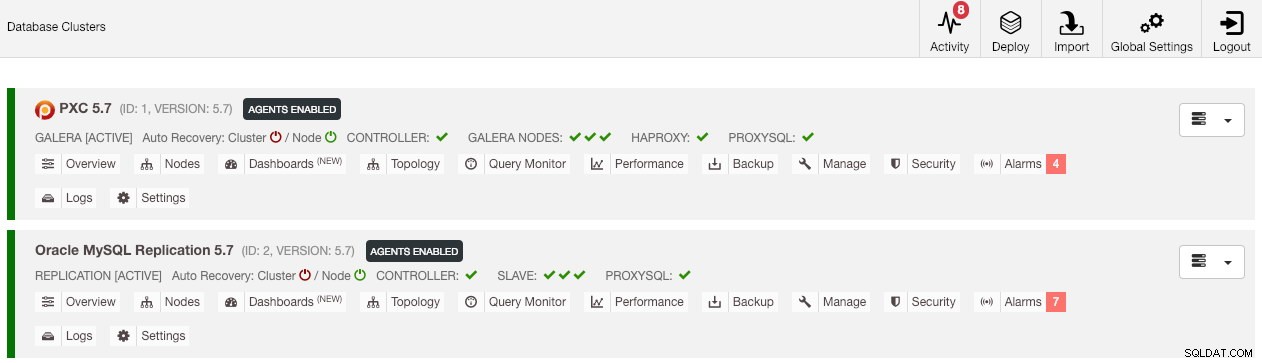
Warto wspomnieć, że domyślnie ClusterControl wyłączy automatyczne odzyskiwanie klastra (jak widać czerwoną ikonę obok słowa „Cluster”), aby uniknąć sytuacji wyścigu z inną instancją ClusterControl. Zaleca się włączenie tej funkcji (klikając ikonę na zieloną) po zamknięciu starego serwera.
Nasza migracja została zakończona. Wszystkie konfiguracje i ustawienia ze starego serwera są zachowywane i przenoszone na nowy serwer.
Migracja zarządzania klastrem do innego serwera ClusterControl
Tworzenie kopii zapasowej informacji o klastrze
Chodzi o tworzenie kopii zapasowych metadanych i informacji klastra, abyśmy mogli przenieść je na inny serwer ClusterControl, znany również jako częściowa kopia zapasowa. W przeciwnym razie musimy wykonać „Importuj istniejący serwer/klaster”, aby ponownie zaimportować je do nowego ClusterControl, co oznacza utratę danych monitorowania ze starego serwera. Jeśli masz moduły równoważenia obciążenia lub asynchroniczne instancje podrzędne, należy je zaimportować po zaimportowaniu klastra, po jednym węźle na raz. Więc jest to trochę kłopotliwe, jeśli masz kompletny zestaw ustawień produkcyjnych.
Ćwiczenie migracji „menedżera” klastra jest przedstawione na poniższym diagramie:
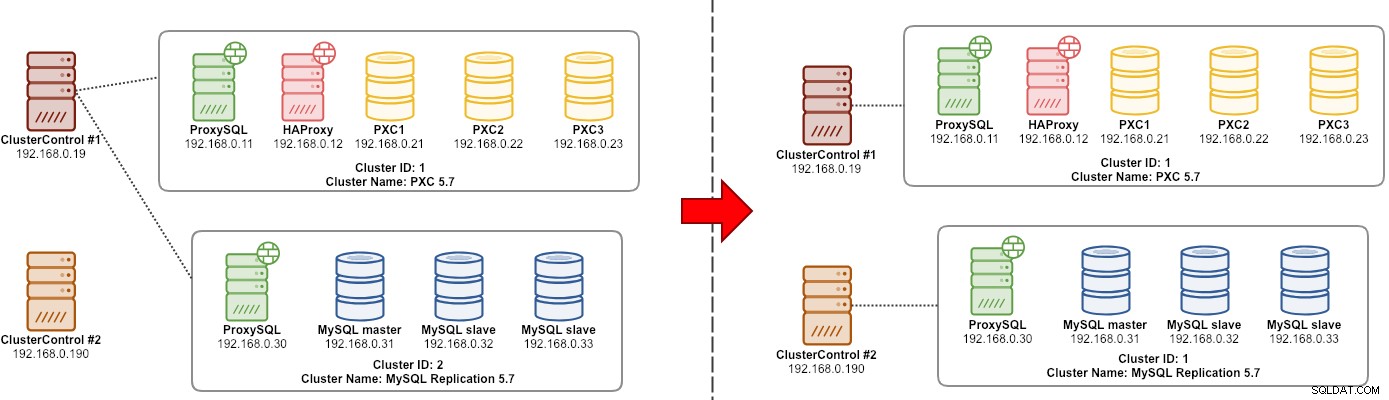
Zasadniczo chcemy przenieść naszą replikację MySQL (identyfikator klastra:2), aby była zarządzana przez inną instancję ClusterControl. W tym przypadku użyjemy opcji --save-cluster-info i --restore-cluster-info. Opcja --save-cluster-info wyeksportuje odpowiednie informacje o klastrze do zapisania w innym miejscu. Wyeksportujmy nasz klaster replikacji MySQL (identyfikator klastra:2). Na bieżącym serwerze ClusterControl wykonaj:
$ s9s backup \
--save-cluster-info \
--cluster-id=2 \
--backup-directory=$HOME/ccbackup \
--output-file=cc-replication-2.tar.gz \
--logZobaczysz kilka nowych wierszy wydrukowanych w terminalu, wskazujących, że zadanie kopii zapasowej jest uruchomione (wyjście jest również dostępne przez ClusterControl -> Aktywność -> Zadania ):
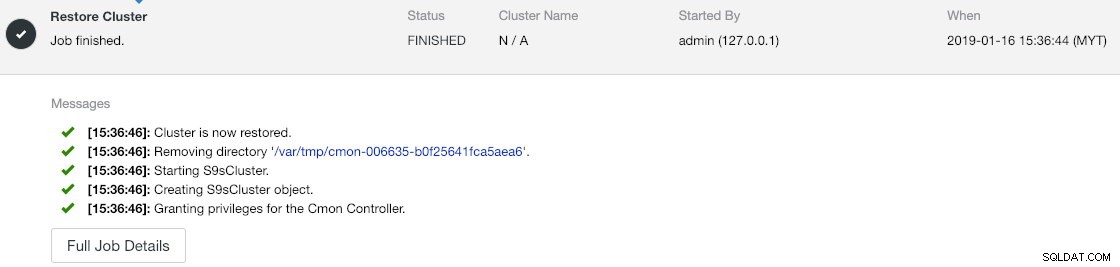
Jeśli przyjrzysz się uważnie dziennikom zadań, zauważysz, że zadanie próbowało wyeksportować wszystkie powiązane informacje i metadane dla klastra o identyfikatorze 2. Dane wyjściowe są przechowywane jako skompresowany plik i znajdują się pod ścieżką, którą określiliśmy za pomocą --backup flaga katalogu. Jeśli ta flaga zostanie zignorowana, ClusterControl zapisze dane wyjściowe w domyślnym katalogu kopii zapasowej, który jest katalogiem domowym użytkownika SSH, pod $HOME/backups.
Przywracanie informacji o klastrze
Opisane tutaj kroki są podobne do kroków przywracania pełnej kopii zapasowej ClusterControl. Przenieś kopię zapasową z bieżącego serwera na inny serwer ClusterControl:
$ scp $HOME/ccbackup/cc-replication-2.tar.gz 192.168.0.190:~Zanim wykonamy przywracanie, musimy skonfigurować bezhasłowe SSH do wszystkich węzłów z nowego serwera ClusterControl:
$ ssh-copy-id 192.168.0.30 #proxysql cluster 2
$ ssh-copy-id 192.168.0.31 #mysql cluster 2
$ ssh-copy-id 192.168.0.32 #mysql cluster 2
$ ssh-copy-id 192.168.0.33 #mysql cluster 2
$ ssh-copy-id 192.168.0.19 #prometheus cluster 2Następnie na nowym serwerze wykonaj przywracanie informacji o klastrze dla naszej replikacji MySQL:
$ s9s backup \
--restore-cluster-info \
--input-file=$HOME/cc-replication-2.tar.gz \
--logPostęp możesz sprawdzić w Aktywność -> Zadania -> Przywróć klaster :
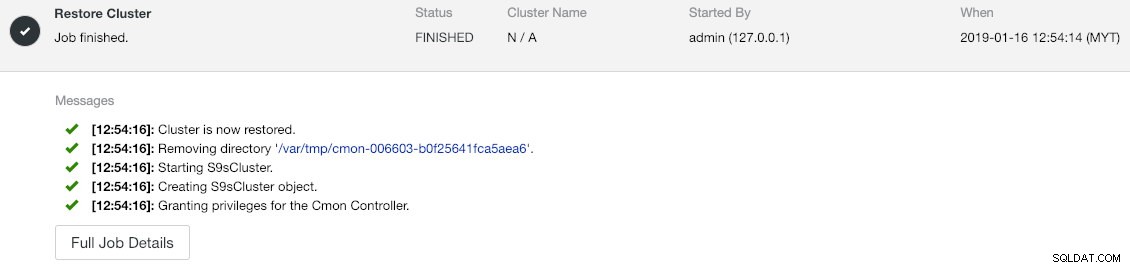
Jeśli przyjrzysz się uważnie komunikatom zadania, zobaczysz, że ClusterControl automatycznie ponownie przypisuje identyfikator klastra do 1 w nowej instancji (w starej instancji był to identyfikator klastra 2).
Następnie zsynchronizuj klaster w interfejsie użytkownika, przechodząc do Ustawienia globalne -> Rejestracje klastra -> Synchronizuj klaster . Jeśli wrócisz do głównego pulpitu ClusterControl, zobaczysz następujące informacje:

Błąd oznacza, że nowy interfejs użytkownika ClusterControl nie może pobrać danych monitorowania i zarządzania z powodu nieprawidłowego tokenu interfejsu API RPC. Musimy tylko odpowiednio go zaktualizować. Najpierw pobierz wartość rpc_key dla naszego klastra o identyfikatorze 1:
$ cat /etc/cmon.d/cmon_1.cnf | egrep 'cluster_id|rpc_key'
cluster_id=1
rpc_key=tAnvKME53N1n8vCCW interfejsie użytkownika kliknij link „tutaj” w wierszu „Zmień token interfejsu API RPC tutaj”. Pojawi się następujące okno dialogowe:
Wklej odpowiednią wartość rpc_key w polu tekstowym i kliknij Zapisz. Poczekaj chwilę, a lista klastrów powinna zostać automatycznie odświeżona.
Ostatnim krokiem jest naprawienie uprawnień użytkownika cmon MySQL dla nowych zmian adresu IP ClusterControl, 192.168.0.190. Zaloguj się do węzła głównego (192.168.0.31) i uruchom następującą instrukcję:
$ mysql -uroot -p -e 'GRANT ALL PRIVILEGES ON *.* TO example@sqldat.com"192.168.0.190" IDENTIFIED BY "<password>" WITH GRANT OPTION';
** Zastąp
Możesz także cofnąć stare uprawnienia użytkownika (odwołanie nie spowoduje usunięcia użytkownika) lub po prostu usunąć starego użytkownika:
$ mysql -uroot -p -e 'DROP USER example@sqldat.com"192.168.0.19"'Po skonfigurowaniu uprawnień powinieneś zobaczyć, że wszystko jest zielone:

W tym momencie nasza architektura wygląda mniej więcej tak:
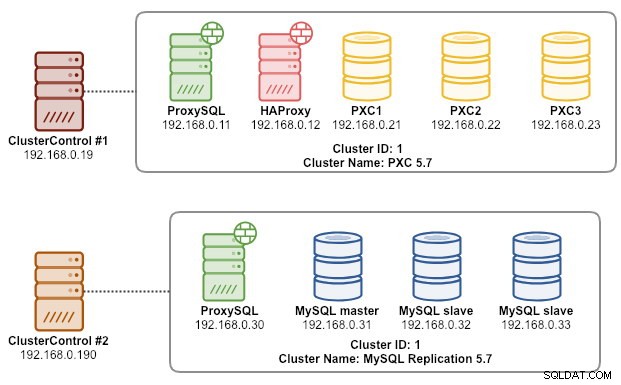
Nasze ćwiczenie migracji zostało zakończone.
Ostateczne myśli
Teraz możliwe jest wykonywanie pełnych i częściowych kopii zapasowych instancji ClusterControl i zarządzanych przez nie klastrów, co pozwala na swobodne przenoszenie ich między hostami przy niewielkim wysiłku. Sugestie i opinie są mile widziane.



