To jest druga część tej serii blogów. Możesz przeczytać część 1, tutaj: Cyfrowa transformacja to podróż danych od krawędzi do wglądu
Ta seria blogów śledzi dane produkcyjne, operacyjne i sprzedażowe dla połączonego producenta pojazdów, gdy dane przechodzą przez etapy i transformacje, które zwykle występują w dużej firmie produkcyjnej, która jest liderem obecnej technologii. Pierwszy blog przedstawił pozorowaną firmę produkującą pojazdy połączone, The Electric Car Company (ECC), w celu zilustrowania ścieżki danych produkcyjnych w cyklu życia danych. Aby to osiągnąć, ECC wykorzystuje Cloudera Data Platform (CDP) do przewidywania zdarzeń i uzyskiwania z góry widoku procesu produkcyjnego samochodu w swoich fabrykach zlokalizowanych na całym świecie.
Po zakończeniu etapu zbierania danych w poprzednim blogu, kolejnym krokiem ECC w cyklu życia danych jest Wzbogacanie danych. ECC wzbogaci zebrane dane i udostępni je do wykorzystania w analizie i tworzeniu modeli w dalszej części cyklu życia danych. Poniżej znajduje się cały zestaw kroków w cyklu życia danych, a każdy krok w cyklu życia będzie wspierany przez dedykowany post na blogu (patrz rys. 1):
- Zbieranie danych – pozyskiwanie i monitorowanie danych na brzegu (czy to z czujnikami przemysłowymi, czy z ludźmi w salonie samochodowym)
- Wzbogacanie danych – przetwarzanie, agregacja i zarządzanie potoku danych w celu przygotowania danych do dalszej analizy
- Raportowanie – dostarczanie wglądu biznesowego (analiza i prognozowanie sprzedaży, budżetowanie jako przykłady)
- Podawanie – kontrolowanie i prowadzenie niezbędnych operacji biznesowych (operacje dealerskie, monitorowanie produkcji)
- Analiza predykcyjna – analityka predykcyjna oparta na sztucznej inteligencji i uczeniu maszynowym (konserwacja predykcyjna, optymalizacja zapasów w oparciu o zapotrzebowanie jako przykłady)
- Bezpieczeństwo i zarządzanie – zintegrowany zestaw technologii bezpieczeństwa, zarządzania i nadzoru w całym cyklu życia danych

Rys. 1 Cykl życia danych korporacyjnych
Wyzwanie wzbogacania danych
ECC potrzebuje kompleksowego wglądu i solidnego zrozumienia wszystkich danych związanych z produkcją, operacjami dealera i wysyłką ich pojazdów. Będą również musieli szybko zidentyfikować problemy z danymi, takie jak czujniki operacyjne generujące dane, które mogą obejmować fałszywe skoki temperatury spowodowane nieplanowanymi przestojami maszyn lub nagłymi rozruchami. Dane, które nie mają związku z procesem, gdy pracownicy utrzymania ruchu wyjmują czujnik ze zbiornika zanurzeniowego, na przykład podczas rutynowych kontroli, nie powinny być brane pod uwagę w analizie.
Ponadto ECC stoi przed następującymi wyzwaniami związanymi z danymi, którymi należy się zająć, aby z powodzeniem przenieść produkcję silników przez łańcuch dostaw. Te wyzwania dotyczące danych obejmują:
- Pobieranie danych w różnych formatach z różnych źródeł: Potoki inżynierii danych wymagają, aby dane były pobierane z różnych źródeł i w wielu różnych formatach. Niezależnie od tego, czy dane pochodzą z czujników umieszczonych na linii produkcyjnej, wspierających operacje produkcyjne, czy danych ERP kontrolujących łańcuch dostaw, wszystkie muszą zostać zebrane w celu dalszej analizy.
- Filtrowanie zbędnych lub nieistotnych danych: Usunięcie zduplikowanych lub nieprawidłowych danych i zapewnienie dokładności pozostałych danych to kluczowy krok w przygotowaniu danych do dalszego wykorzystania w zaawansowanej analityce predykcyjnej.
- Zdolność do identyfikacji nieefektywnych procesów: ECC wymaga możliwości zobaczenia, które procesy danych zajmują najwięcej czasu i zasobów, co ułatwia kierowanie słabszych części potoku w celu przyspieszenia całego procesu.
- Możliwość monitorowania wszystkich procesów z jednego okienka: ECC wymaga scentralizowanego systemu, który umożliwia monitorowanie wszystkich bieżących procesów danych, a także możliwości rozbudowy obecnej infrastruktury przy zachowaniu przejrzystości.
Wyselekcjonowane, wysokiej jakości zestawy danych są podstawą każdej zaawansowanej inicjatywy analitycznej. Aby to osiągnąć, należy zastosować ramy inżynierii danych, aby umożliwić budowę wszystkich rurociągów i wodociągów potrzebnych do przemieszczania, manipulowania i zarządzania danymi różnych części pojazdu w cyklu życia danych.
Budowanie potoku przy użyciu inżynierii danych Cloudera
Zanim dane zostaną wzbogacone i omówione na pierwszym blogu, strumienie danych IT i OT zebrane z fabryki zostaną oczyszczone, zmanipulowane i zmodyfikowane. Identyfikator fabryczny, identyfikator maszyny, znacznik czasu, numer części i numer seryjny można pobrać z kodu QR nadrukowanego na silniku elektrycznym. Gdy silnik jest montowany w podłączonym pojeździe, zbierane są dane, takie jak typ modelu, VIN i podstawowy koszt pojazdu.
Po sprzedaży pojazdu informacje o sprzedaży, takie jak nazwa klienta, dane kontaktowe, ostateczna cena sprzedaży i lokalizacja klienta, są rejestrowane osobno. Dane te będą miały kluczowe znaczenie dla kontaktu z klientem w przypadku ewentualnych wycofań lub ukierunkowanej konserwacji zapobiegawczej. Przechowywane są również dane geolokalizacyjne, co pomoże mapować lokalizacje klientów na szerokości i długości geograficzne, aby lepiej zrozumieć, gdzie znajdują się te silniki po sprzedaży w pojeździe.
ECC użyje Cloudera Data Engineering (CDE), aby sprostać powyższym wyzwaniom związanym z danymi (patrz rys. 2). CDE udostępni następnie dane do Cloudera Data Warehouse (CDW), gdzie zostaną udostępnione do zaawansowanych analiz i raportów Business Intelligence. Kroki CDE są opisane poniżej.
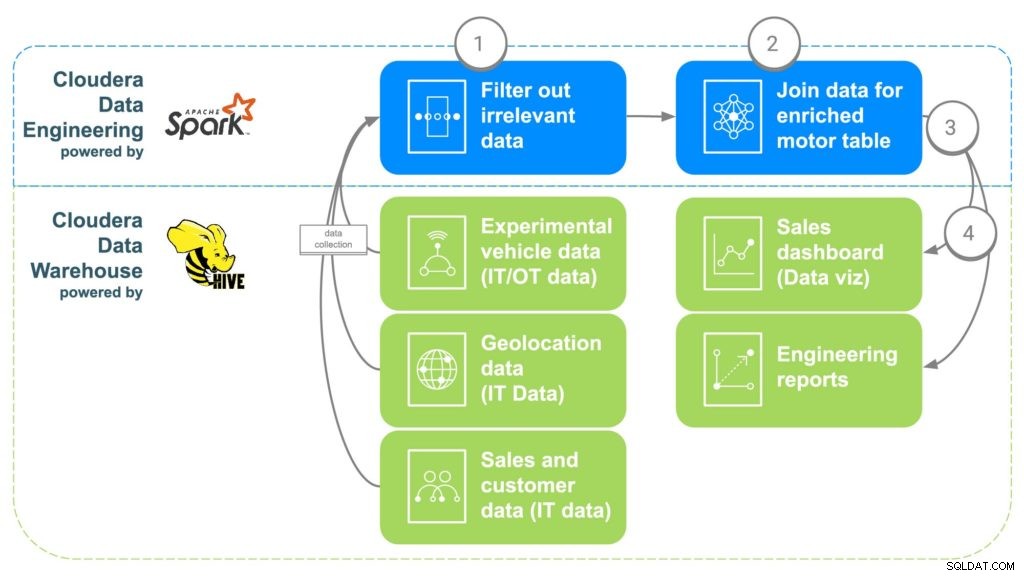
Rys. 2 Potok wzbogacania danych ECC
KROK 1:Filtruj i oddzielaj dane
Pierwszym krokiem w korzystaniu z CDE jest utworzenie zadania PySpark, które pobiera dane z różnych „surowych” źródeł z kroku 1. Jest to okazja do filtrowania wszelkich nieistotnych danych, takich jak klienci poniżej 16 roku życia, na przykład, ponieważ to to zazwyczaj minimalny wiek prowadzenia pojazdu. Zduplikowane dane i inne nieistotne dane można również odfiltrować lub oddzielić.
KROK 2:Połącz dane
Aby połączyć wszystkie dane, CDE skoreluje ze sobą wspólne łącza. Po pierwsze, dane dotyczące sprzedaży samochodu zostaną powiązane z klientem, który kupił samochód, aby uzyskać metadane klienta, takie jak dane kontaktowe, wiek, wynagrodzenie itp. Dane geolokalizacyjne zostaną następnie wykorzystane do uzyskania dokładniejszych informacji o lokalizacji dla klienta , co pomoże później w mapowaniu silników. Dane dotyczące montażu części zostaną wykorzystane do identyfikacji numerów seryjnych każdego silnika, który został zainstalowany w samochodzie klienta. Na koniec dane fabryczne zostaną dopasowane do numeru seryjnego silnika, co pozwoli określić, która fabryka, maszyna i kiedy został utworzony każdy konkretny silnik.
KROK 3:Wyślij dane do Cloudera Data Warehouse
Gdy wszystkie dane zostaną zebrane w wzbogaconą tabelę, proste polecenie Apache Spark zapisze dane w nowej tabeli w Cloudera Data Warehouse. Dzięki temu dane będą dostępne dla wszystkich analityków danych, którzy mogą chcieć uzyskać do nich dostęp w celu przeprowadzenia dodatkowej analizy.
KROK 4:Wygeneruj pulpity nawigacyjne i raporty wizualizacji danych
Mając wszystkie dane w jednym miejscu, można teraz tworzyć raporty, które pozwolą pracownikom podejmować bardziej świadome decyzje i otworzyć możliwości, które nie istniały. Mapy cieplne mogą być tworzone w celu śledzenia lokalizacji silnika i skorelowania wszelkich problemów z potencjalnymi lokalizacjami geograficznymi, takich jak awarie spowodowane ekstremalnym zimnem lub upałem. Dane te mogą być również wykorzystane do dokładnego śledzenia klientów, których może dotyczyć problem w przypadku wystąpienia problemu w określonej fabryce w określonym przedziale czasu, co ułatwia śledzenie klientów, którzy mogą potrzebować wycofania lub konserwacji zapobiegawczej.
Wniosek
Cloudera Data Engineering umożliwia ECC zbudowanie potoku, który może skorelować dane dotyczące produkcji i części, typ użytkowania klienta, warunki środowiskowe, informacje o sprzedaży i inne w celu poprawy zadowolenia klienta i niezawodności pojazdu. Firma ECC osiągnęła swoje cele i sprostała wyzwaniom, śledząc dane związane z produkcją silników i czerpiąc korzyści w następujący sposób:
- ECC skróciło czas do wartości, organizując i automatyzując potoki danych w celu bezpiecznego i przejrzystego dostarczania wyselekcjonowanych, wysokiej jakości zestawów danych z różnych źródeł danych.
- ECC było w stanie zidentyfikować odpowiednie dane i odfiltrować wszelkie zbędne i zduplikowane dane.
- ECC było w stanie monitorować potok danych z jednego okienka, będąc jednocześnie w stanie być powiadamianym o problemach wcześnie poprzez wizualne rozwiązywanie problemów, aby szybko rozwiązać problemy, zanim wpłynie to na biznes.
Poszukaj następnego bloga, który zagłębi się w Raportowanie, który pokaże, jak inżynierowie ECC wykonują zapytania ad hoc w CDW w odniesieniu do tych wyselekcjonowanych danych, a także łączą dane z innymi odpowiednimi źródłami w hurtowni danych przedsiębiorstwa. CDW ułatwia łączenie wszystkich danych i zapewnia wbudowane narzędzie do wizualizacji danych, umożliwiające przejście od zapytanych wyników do pulpitów nawigacyjnych. Czekajcie na następny!
Więcej zasobów gromadzenia danych
Aby zobaczyć to wszystko w akcji, kliknij powiązane linki poniżej, aby dowiedzieć się więcej o wzbogacaniu danych:
- Wideo – jeśli chcesz zobaczyć i usłyszeć, jak to zostało zbudowane, obejrzyj wideo pod linkiem.
- Samouczki – jeśli chcesz to zrobić we własnym tempie, zapoznaj się ze szczegółowym przewodnikiem ze zrzutami ekranu i instrukcjami linia po linii, jak to skonfigurować i wykonać.
- Meetup – Jeśli chcesz porozmawiać bezpośrednio z ekspertami z Cloudera, dołącz do wirtualnego spotkania, aby zobaczyć prezentację na żywo. Na końcu będzie czas na bezpośrednie pytania i odpowiedzi.
- Użytkownicy – aby zobaczyć bardziej techniczne treści przeznaczone dla użytkowników, kliknij link.



