ClusterControl jest zaprogramowany z wieloma algorytmami odzyskiwania, aby automatycznie reagować na różne typy typowych awarii mających wpływ na systemy baz danych. Rozumie różne typy topologii baz danych i zarządzania procesami związanymi z bazą danych, aby pomóc w określeniu najlepszego sposobu odzyskania klastra. W pewnym sensie ClusterControl poprawia dostępność bazy danych.
Niektórzy menedżerowie topologii obejmują tylko odzyskiwanie klastrów, takie jak MHA, Orchestrator i mysqlfailover, ale odzyskiwaniem węzłów musisz zająć się samodzielnie. ClusterControl obsługuje odzyskiwanie zarówno na poziomie klastra, jak i węzła.
Opcje konfiguracji
ClusterControl obsługuje dwa składniki odzyskiwania, a mianowicie:
- Klaster — próba przywrócenia klastra do stanu operacyjnego
- Węzeł — próba przywrócenia węzła do stanu operacyjnego
Te dwa elementy są najważniejsze, aby zapewnić jak najwyższą dostępność usługi. Jeśli masz już menedżera topologii nad ClusterControl, możesz wyłączyć funkcję automatycznego odzyskiwania i pozwolić, aby inny menedżer topologii zajął się tym za Ciebie. ClusterControl oferuje wszystkie możliwości.
Funkcja automatycznego odzyskiwania może być włączana i wyłączana za pomocą prostego przełącznika ON/OFF i działa ona w przypadku odzyskiwania klastra lub węzła. Zielone ikony oznaczają włączone, a czerwone ikony wyłączone. Poniższy zrzut ekranu pokazuje, gdzie można go znaleźć na liście klastrów bazy danych:
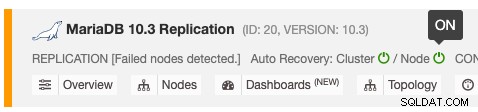
Istnieją 3 parametry ClusterControl, których można użyć do sterowania zachowaniem odzyskiwania. Wszystkie parametry mają domyślnie wartość true (ustawiane logiczną liczbą całkowitą 0 lub 1):
- enable_autorecovery — Włącz odzyskiwanie klastra i węzła. Ten parametr jest nadzbiorem enable_cluster_recovery i enable_node_recovery. Jeśli jest ustawiony na 0, parametry podzbioru zostaną wyłączone.
- enable_cluster_recovery — ClusterControl wykona odzyskiwanie klastra, jeśli jest włączone.
- enable_node_recovery — ClusterControl wykona odzyskiwanie węzła, jeśli jest włączone.
Odzyskiwanie klastra obejmuje próbę przywrócenia całej topologii klastra. Na przykład, replikacja master-slave musi mieć przynajmniej jednego mastera aktywnego w danym momencie, niezależnie od liczby dostępnych slave(ów). ClusterControl próbuje skorygować topologię przynajmniej raz dla klastrów replikacji, ale bez końca dla replikacji z wieloma wzorcami, takiej jak klaster NDB i klaster Galera.
Odzyskiwanie węzła obejmuje problem z odzyskiwaniem węzła, na przykład w przypadku zatrzymania węzła bez wiedzy ClusterControl, np. za pomocą polecenia zatrzymania systemu z konsoli SSH lub zabicia przez proces OOM.
Odzyskiwanie węzłów
ClusterControl może odzyskać węzeł bazy danych w przypadku sporadycznych awarii, monitorując proces i łączność z węzłami bazy danych. W przypadku tego procesu działa podobnie do systemd, gdzie upewni się, że usługa MySQL jest uruchomiona i działa, chyba że celowo zatrzymałeś ją za pomocą interfejsu użytkownika ClusterControl.
Jeśli węzeł wróci do trybu online, ClusterControl nawiąże połączenie z powrotem do węzła bazy danych i wykona niezbędne działania. Oto, co zrobiłby ClusterControl, aby odzyskać węzeł:
- Poczeka na uruchomienie monitorowanych usług/procesów przez systemd/chkconfig/init przez 30 sekund
- Jeśli monitorowane usługi/procesy nadal nie działają, ClusterControl spróbuje automatycznie uruchomić usługę bazy danych.
- Jeśli ClusterControl nie może odzyskać monitorowanych usług/procesów, zostanie podniesiony alarm.
Pamiętaj, że jeśli zamknięcie bazy danych zostanie zainicjowane przez użytkownika, ClusterControl nie będzie próbował odzyskać konkretnego węzła. Oczekuje, że użytkownik uruchomi go z powrotem za pośrednictwem interfejsu użytkownika ClusterControl, przechodząc do Węzeł -> Akcje węzła -> Uruchom węzeł lub jawnie użyj polecenia systemu operacyjnego.
Odzyskiwanie obejmuje wszystkie usługi związane z bazami danych, takie jak ProxySQL, HAProxy, MaxScale, Keepalived, eksportery Prometheus i garbd. Szczególną uwagę poświęcamy eksporterom Prometheusa, w których ClusterControl używa programu o nazwie „demon” do demonizowania procesu eksportera. ClusterControl spróbuje połączyć się z portem nasłuchiwania eksportera w celu sprawdzenia kondycji i weryfikacji. Dlatego zaleca się otwarcie portów eksportera z serwera ClusterControl i Prometheus, aby upewnić się, że podczas odzyskiwania nie wystąpi fałszywy alarm.
Odzyskiwanie klastra
ClusterControl rozumie topologię bazy danych i postępuje zgodnie z najlepszymi praktykami podczas odzyskiwania. W przypadku klastra bazy danych z wbudowaną odpornością na awarie, takiego jak Galera Cluster, NDB Cluster i MongoDB Replicaset, proces przełączania awaryjnego zostanie wykonany automatycznie przez serwer bazy danych za pomocą obliczenia kworum, pulsu i przełączania ról (jeśli istnieje). ClusterControl monitoruje proces i wprowadza niezbędne zmiany w wizualizacji, takie jak odzwierciedlenie zmian w widoku topologii i dostosowanie komponentu monitorowania i zarządzania do nowej roli, np. nowy węzeł główny w zestawie replik.
W przypadku technologii baz danych, które nie mają wbudowanej odporności na błędy z automatycznym odzyskiwaniem, takich jak MySQL/MariaDB Replication i PostgreSQL/TimescaleDB Streaming Replication, ClusterControl wykona procedury odzyskiwania, postępując zgodnie z najlepszymi praktykami dostarczonymi przez dostawca bazy danych. Jeśli odzyskiwanie nie powiedzie się, wymagana jest interwencja użytkownika i oczywiście otrzymasz powiadomienie alarmowe dotyczące tego.
W topologii mieszanej/hybrydowej, na przykład asynchronicznego urządzenia podrzędnego podłączonego do klastra Galera lub klastra NDB, węzeł zostanie odzyskany przez ClusterControl, jeśli włączone jest odzyskiwanie klastra.
Odzyskiwanie klastra nie dotyczy samodzielnego serwera MySQL. Jednak zaleca się włączenie odzyskiwania zarówno węzła, jak i klastra dla tego typu klastra w interfejsie użytkownika ClusterControl.
Replikacja MySQL/MariaDB
ClusterControl obsługuje odzyskiwanie następującej konfiguracji replikacji MySQL/MariaDB:
- Master-slave z MySQL GTID
- Master-slave z MariaDB GTID
- Master-slave z bez GTID (zarówno MySQL, jak i MariaDB)
- Master-master z MySQL GTID
- Master-master z identyfikatorem GTID MariaDB
- Asynchroniczne urządzenie podrzędne podłączone do klastra Galera
ClusterControl uwzględnia następujące parametry podczas odzyskiwania klastra:
- enable_cluster_autorecovery
- auto_manage_readonly
- repl_password
- repl_user
- replication_auto_rebuild_slave
- replication_check_binlog_filtration_bf_failover
- replication_check_external_bf_failover
- replication_failed_reslave_failover_script
- replication_failover_blacklist
- replication_failover_events
- replication_failover_wait_to_apply_timeout
- replication_failover_whitelist
- replication_onfail_failover_script
- replication_post_failover_script
- replication_post_switchover_script
- replication_post_unsuccessful_failover_script
- replication_pre_failover_script
- replication_pre_switchover_script
- replication_skip_apply_missing_txs
- replication_stop_on_error
Więcej informacji na temat każdego parametru można znaleźć na stronie dokumentacji.
ClusterControl będzie przestrzegać następujących reguł podczas monitorowania i zarządzania replikacją master-slave:
- Wszystkie węzły będą uruchamiane z read_only=ON i super_read_only=ON (niezależnie od roli).
- Tylko jeden master (read_only=OFF) może działać w danym momencie.
- Polegaj na zmiennej MySQL report_host do mapowania topologii.
- Jeśli są dwa lub więcej węzłów, które mają read_only=OFF na raz, ClusterControl automatycznie ustawi read_only=ON na obu masterach, aby chronić je przed przypadkowym zapisem. Wymagana jest interwencja użytkownika, aby wybrać rzeczywisty master poprzez wyłączenie trybu tylko do odczytu. Przejdź do Węzły -> Akcje węzła -> Wyłącz tylko do odczytu.
W przypadku awarii aktywnego mastera, ClusterControl spróbuje wykonać przełączanie awaryjne mastera w następującej kolejności:
- Po 3 sekundach nieosiągalności urządzenia głównego, ClusterControl podniesie alarm.
- Sprawdź dostępność urządzenia podrzędnego, co najmniej jedno urządzenie podrzędne musi być osiągalne przez ClusterControl.
- Wybierz niewolnika jako kandydata na mistrza.
- ClusterControl obliczy prawdopodobieństwo błędnych transakcji, jeśli GTID jest włączony.
- Jeśli nie zostanie wykryta żadna błędna transakcja, wybrany zostanie promowany jako nowy główny.
- Utwórz i przyznaj użytkownikowi replikacji do użytku przez urządzenia podrzędne.
- Zmień master dla wszystkich slave'ów, które wskazywały starego mastera na nowo promowanego mastera.
- Uruchom urządzenie podrzędne i włącz tylko do odczytu.
- Opróżnij dzienniki we wszystkich węzłach.
- Jeśli promocja urządzenia podrzędnego nie powiedzie się, ClusterControl przerwie zadanie odzyskiwania. Aby ponownie uruchomić zadanie odzyskiwania, wymagana jest interwencja użytkownika lub ponowne uruchomienie usługi cmon.
- Kiedy stary wzorzec będzie ponownie dostępny, zostanie uruchomiony w trybie tylko do odczytu i nie będzie częścią replikacji. Wymagana jest interwencja użytkownika.
W tym samym czasie zostaną wywołane następujące alarmy:
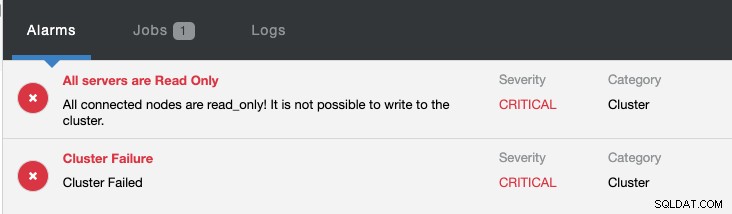
Zapoznaj się z wprowadzeniem do przełączania awaryjnego replikacji MySQL — blog 101 i automatycznym przełączaniem awaryjnym replikacji MySQL — nowością w ClusterControl 1.4, aby uzyskać więcej informacji na temat konfigurowania i zarządzania przełączaniem awaryjnym replikacji MySQL za pomocą ClusterControl.
Replikacja strumieniowa PostgreSQL/TimescaleDB
ClusterControl obsługuje odzyskiwanie następującej konfiguracji replikacji PostgreSQL:
- Replikacja strumieniowa PostgreSQL
- Replikacja przesyłania strumieniowego TimescaleDB
ClusterControl uwzględnia następujące parametry podczas odzyskiwania klastra:
- enable_cluster_autorecovery
- repl_password
- repl_user
- replication_auto_rebuild_slave
- replication_failover_whitelist
- replication_failover_blacklist
Więcej informacji na temat każdego parametru można znaleźć na stronie dokumentacji.
ClusterControl będzie przestrzegać następujących zasad zarządzania i monitorowania konfiguracji replikacji strumieniowej PostgreSQL:
- wal_level jest ustawiony na "replikę" (lub "hot_standby" w zależności od wersji PostgreSQL).
- Archiwum zmiennej jest ustawiony na WŁĄCZONY na urządzeniu głównym.
- Ustaw plik recovery.conf na węzłach podrzędnych, który zamienia węzeł w stan gotowości z włączoną opcją tylko do odczytu.
W przypadku awarii aktywnego mastera, ClusterControl spróbuje przeprowadzić odzyskiwanie klastra w następującej kolejności:
- Po 10 sekundach nieosiągalności urządzenia głównego, ClusterControl podniesie alarm.
- Po 10 sekundach czasu oczekiwania, ClusterControl zainicjuje główne zadanie przełączania awaryjnego.
- Spróbuj lokalizację powtórzenia i lokalizację odbioru we wszystkich dostępnych węzłach, aby określić najbardziej zaawansowany węzeł.
- Promuj najbardziej zaawansowany węzeł jako nowego głównego.
- Zatrzymaj niewolników.
- Zweryfikuj stan synchronizacji za pomocą pg_rewind.
- Restartowanie slave'ów z nowym masterem.
- Jeśli promocja urządzenia podrzędnego nie powiedzie się, ClusterControl przerwie zadanie odzyskiwania. Aby ponownie uruchomić zadanie odzyskiwania, wymagana jest interwencja użytkownika lub ponowne uruchomienie usługi cmon.
- Kiedy stary master będzie ponownie dostępny, zostanie zmuszony do zamknięcia i nie będzie częścią replikacji. Wymagana jest interwencja użytkownika. Zobacz niżej.
Gdy stary master wróci do trybu online, jeśli usługa PostgreSQL jest uruchomiona, ClusterControl wymusi zamknięcie usługi PostgreSQL. Ma to na celu ochronę serwera przed przypadkowymi zapisami, ponieważ zostałby uruchomiony bez pliku odzyskiwania (recovery.conf), co oznacza, że byłby zapisywalny. Należy się spodziewać, że w postgresql-{day}.log pojawią się następujące wiersze:
2019-11-27 05:06:10.091 UTC [2392] LOG: database system is ready to accept connections
2019-11-27 05:06:27.696 UTC [2392] LOG: received fast shutdown request
2019-11-27 05:06:27.700 UTC [2392] LOG: aborting any active transactions
2019-11-27 05:06:27.703 UTC [2766] FATAL: terminating connection due to administrator command
2019-11-27 05:06:27.704 UTC [2758] FATAL: terminating connection due to administrator command
2019-11-27 05:06:27.709 UTC [2392] LOG: background worker "logical replication launcher" (PID 2419) exited with exit code 1
2019-11-27 05:06:27.709 UTC [2414] LOG: shutting down
2019-11-27 05:06:27.735 UTC [2392] LOG: database system is shut downPostgreSQL został uruchomiony po tym, jak serwer wrócił do trybu online około 05:06:10, ale ClusterControl wykonuje szybkie zamknięcie 17 sekund później około 05:06:27. Jeśli jest to coś, czego nie chcesz, możesz na chwilę wyłączyć odzyskiwanie węzłów dla tego klastra.
Wypróbuj automatyczne przełączanie awaryjne replikacji Postgres i przełączanie awaryjne dla replikacji PostgreSQL 101, aby uzyskać więcej informacji na temat konfigurowania i zarządzania przełączaniem awaryjnym replikacji PostgreSQL za pomocą ClusterControl.
Wnioski
Automatyczne odzyskiwanie ClusterControl rozumie topologię klastra bazy danych i jest w stanie odzyskać niedziałający lub zdegradowany klaster do w pełni działającego klastra, co znacznie poprawi czas działania usług bazy danych. Wypróbuj ClusterControl już teraz i osiągnij swoje dziewiątki pod względem dostępności SLA i bazy danych. Nie znasz swoich dziewiątek? Sprawdź ten fajny kalkulator dziewiątek.



