Zapewnienie płynnego działania baz danych produkcyjnych nie jest trywialnym zadaniem, a istnieje wiele narzędzi i narzędzi, które mogą w tym pomóc. Dostępne są narzędzia do monitorowania kondycji, wydajności serwera, analizowania zapytań, wdrożeń, zarządzania przełączaniem awaryjnym, uaktualnień, a lista jest długa. ClusterControl jako platforma do zarządzania i monitorowania infrastruktury bazy danych wyróżnia się możliwością zarządzania całym cyklem życia, od wdrożenia do monitorowania, ciągłego zarządzania i skalowania.
Chociaż ClusterControl oferuje ważne funkcje, takie jak automatyczne przełączanie awaryjne bazy danych, szyfrowanie podczas przesyłania/w spoczynku, zarządzanie kopiami zapasowymi, odzyskiwanie do określonego punktu w czasie, integracja z Prometheus, skalowanie bazy danych, można je znaleźć w innych dostępnych na rynku narzędziach do zarządzania/monitorowania przedsiębiorstw. Istnieją jednak pewne funkcje, których nie znajdziesz tak łatwo. W tym poście na blogu przedstawimy 9 funkcji, których nie znajdziesz w żadnych innych narzędziach do zarządzania i monitorowania dostępnych na rynku (w momencie pisania tego tekstu).
Weryfikacja kopii zapasowej
Każda kopia zapasowa dosłownie nie jest kopią zapasową, dopóki nie wiadomo, że można ją odzyskać — przez rzeczywiste sprawdzenie, czy można ją odzyskać. ClusterControl umożliwia weryfikację kopii zapasowej po utworzeniu kopii zapasowej poprzez uruchomienie nowego serwera i przetestowanie przywracania. Weryfikacja kopii zapasowej to kluczowy proces, który zapewnia spełnienie zasad dotyczących punktu odzyskiwania (RPO) w przypadku odzyskiwania po awarii. Proces weryfikacji przeprowadzi przywrócenie na nowym samodzielnym hoście (gdzie ClusterControl zainstaluje niezbędne pakiety bazy danych przed przywróceniem) lub na serwerze przeznaczonym do weryfikacji kopii zapasowej.
Aby skonfigurować weryfikację kopii zapasowej, po prostu wybierz istniejącą kopię zapasową i kliknij Przywróć. Pojawi się opcja przywracania i weryfikacji:
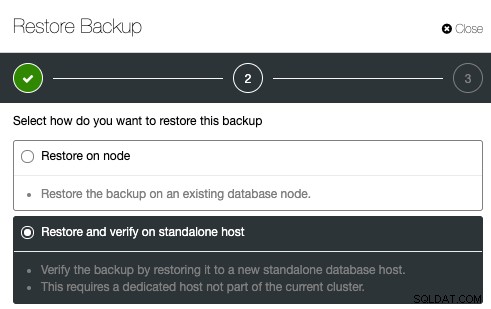
Następnie podaj adres IP serwera, który chcesz przywróć i zweryfikuj:
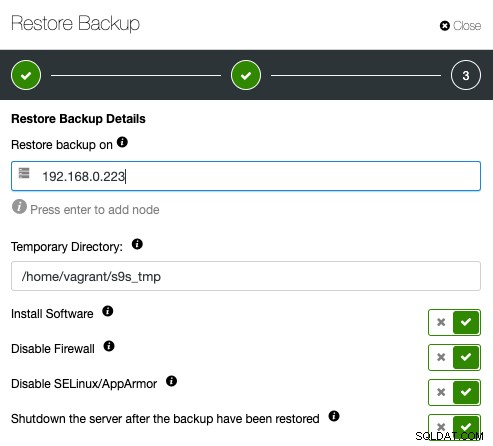
Upewnij się, że określony host jest dostępny za pośrednictwem protokołu SSH bez hasła. Masz również kilka opcji poniżej procesu aprowizacji. Możesz także wyłączyć serwer weryfikacji po przywróceniu, aby zaoszczędzić koszty i zasoby po zweryfikowaniu kopii zapasowej. ClusterControl wyszuka kod zakończenia procesu przywracania i będzie obserwować dziennik przywracania, aby sprawdzić, czy weryfikacja się nie powiodła lub zakończyła się powodzeniem.
Uproszczenie zarządzania ProxySQL za pomocą graficznego interfejsu użytkownika
Wielu zgodzi się, że posiadanie graficznego interfejsu użytkownika jest bardziej wydajne i mniej podatne na błędy ludzkie podczas konfigurowania systemu. ProxySQL jest częścią krytycznej warstwy bazy danych (chociaż znajduje się na niej) i musi być wystarczająco widoczny dla oczu DBA, aby wykryć typowe problemy i problemy. ClusterControl zapewnia wszechstronny graficzny interfejs użytkownika dla ProxySQL.
Instancje ProxySQL można wdrożyć na nowych hostach lub zaimportować istniejące do ClusterControl. ClusterControl może skonfigurować ProxySQL tak, aby był zintegrowany z wirtualnym adresem IP (dostarczanym przez Keepalived) w celu uzyskania dostępu do serwerów baz danych z jednego punktu końcowego. Zapewnia również wgląd w monitorowanie kluczowych komponentów ProxySQL, takich jak Zaplecze zapytań, Powolne zapytania, Najpopularniejsze zapytania, Trafienia zapytań i wiele innych statystyk monitorowania. Poniżej znajduje się zrzut ekranu pokazujący, jak dodać nową regułę zapytania:
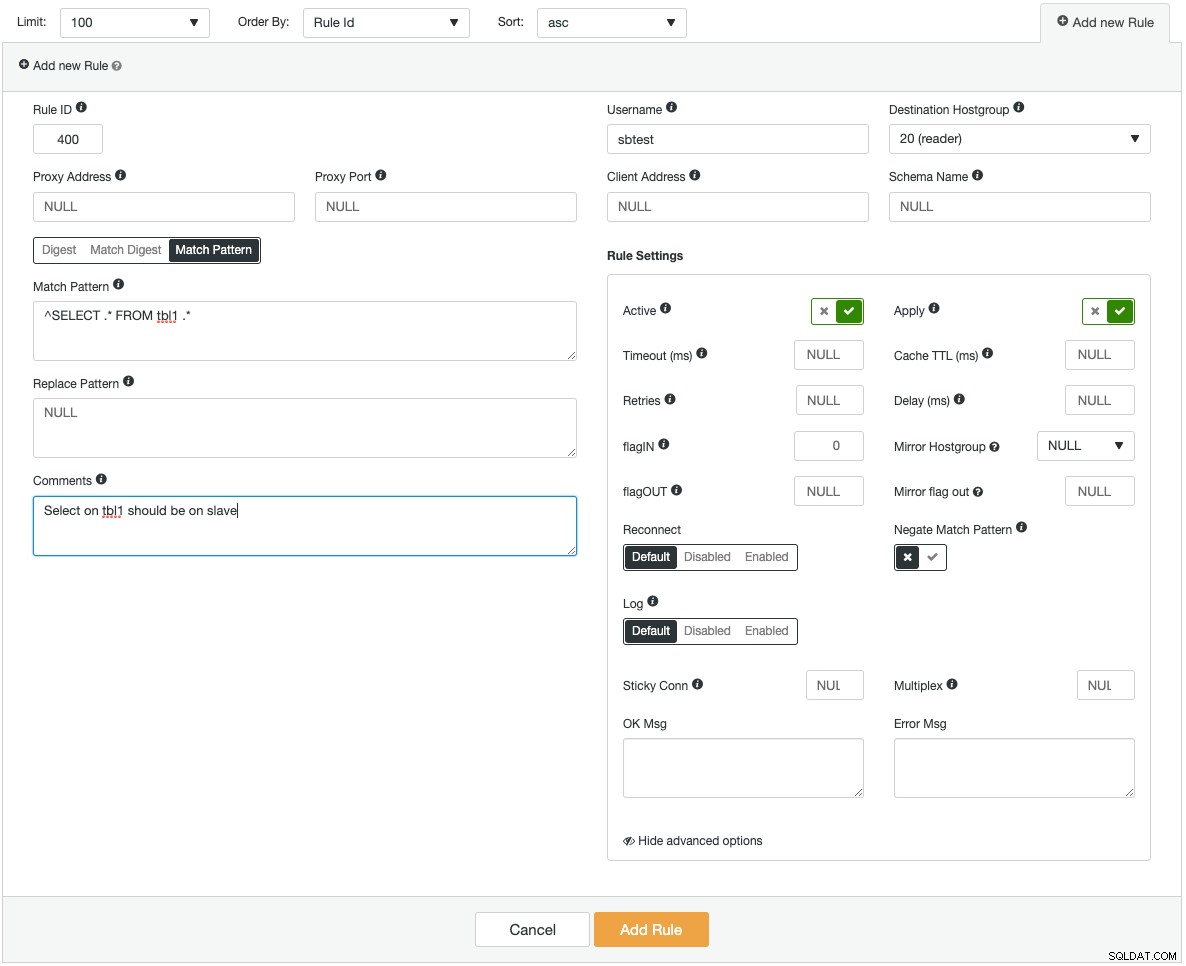
Jeśli dodajesz bardzo złożoną regułę zapytania, wygodniej byłoby zrobić to za pomocą graficznego interfejsu użytkownika. Każde pole ma etykietkę pomocną podczas wypełniania formularza reguły zapytania. Podczas dodawania lub modyfikowania dowolnej konfiguracji ProxySQL, ClusterControl upewni się, że zmiany są wprowadzane w czasie wykonywania i zapisywane na dysku w celu zachowania trwałości.
ClusterControl 1.7.4 obsługuje teraz zarówno ProxySQL 1.x, jak i ProxySQL 2.x.
Raporty operacyjne
Raporty operacyjne to zestaw raportów podsumowujących infrastrukturę bazy danych, które można generować w locie lub zaplanować do wysłania do różnych odbiorców. Raporty te składają się z różnych kontroli i dotyczą różnych codziennych zadań DBA. Ideą raportowania operacyjnego ClusterControl jest umieszczenie wszystkich najbardziej istotnych danych w jednym dokumencie, który można szybko przeanalizować w celu uzyskania jasnego zrozumienia stanu baz danych i ich procesów.
Dzięki ClusterControl możesz planować raporty środowiskowe między klastrami, takie jak dzienny raport systemowy, raport aktualizacji pakietu, raport zmiany schematu, a także kopie zapasowe i dostępność. Raporty te pomogą Ci zapewnić bezpieczeństwo i sprawność środowiska. Zobaczysz również zalecenia, jak naprawić luki. Raporty mogą być adresowane do SysOps, DevOps, a nawet menedżerów, którzy chcieliby otrzymywać regularne aktualizacje statusu o kondycji danego systemu.
Poniżej znajduje się próbka codziennego raportu operacyjnego wysyłanego na Twoją skrzynkę pocztową w odniesieniu do dostępności:
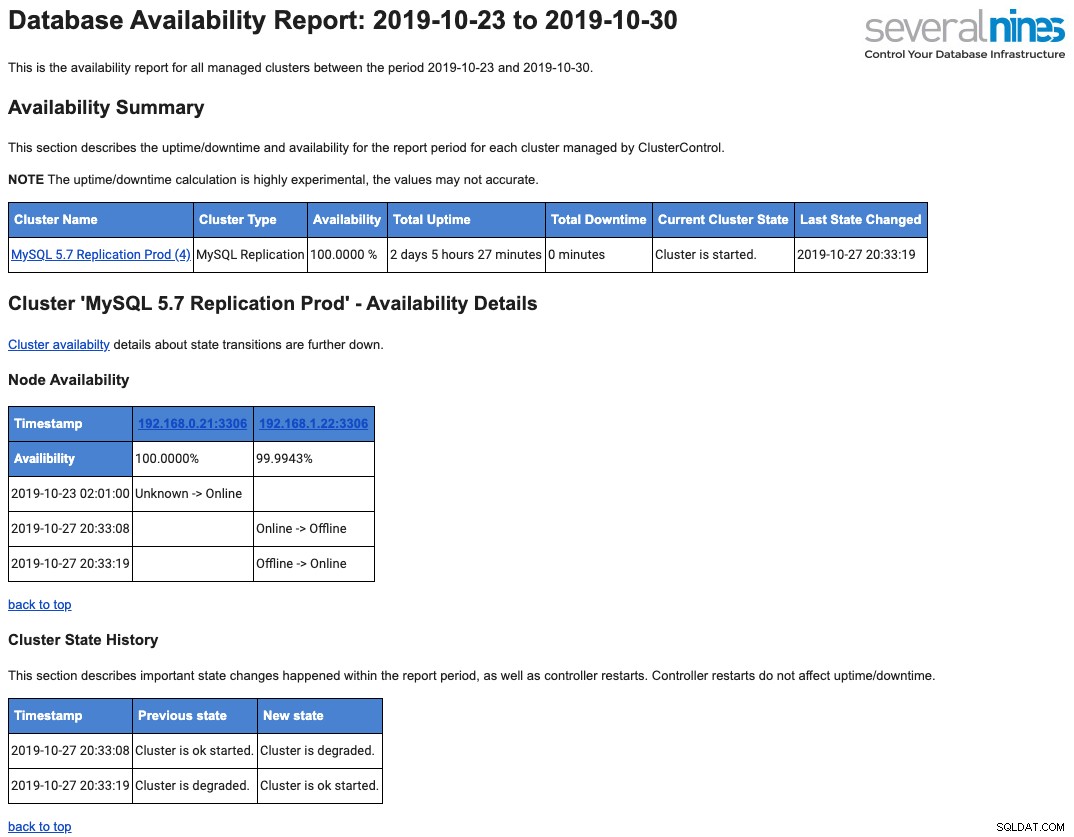
Omówiliśmy to szczegółowo w tym poście na blogu, Przegląd raportowania operacyjnego bazy danych w ClusterControl.
Ponowna synchronizacja urządzenia podrzędnego przez kopię zapasową
ClusterControl umożliwia postawienie urządzenia podrzędnego (nowego lub uszkodzonego) za pomocą najnowszej pełnej lub przyrostowej kopii zapasowej. Nie brzmi to zbyt ekscytująco, ale ta funkcja jest ogromna, jeśli masz duże zestawy danych o wielkości 100 GB i więcej. Powszechną praktyką podczas ponownej synchronizacji urządzenia podrzędnego jest przesyłanie strumieniowe kopii zapasowej bieżącego urządzenia głównego, co może zająć trochę czasu w zależności od rozmiaru bazy danych. Doda to dodatkowe obciążenie masterowi, co może zagrozić jego wydajności.
Aby ponownie zsynchronizować urządzenie podrzędne za pomocą kopii zapasowej, wybierz węzeł podrzędny na stronie Węzły i przejdź do Akcje węzła -> Odbuduj urządzenie podrzędne replikacji -> Odbuduj z kopii zapasowej. Tylko kopia zapasowa kompatybilna z PITR zostanie wyświetlona na liście rozwijanej:
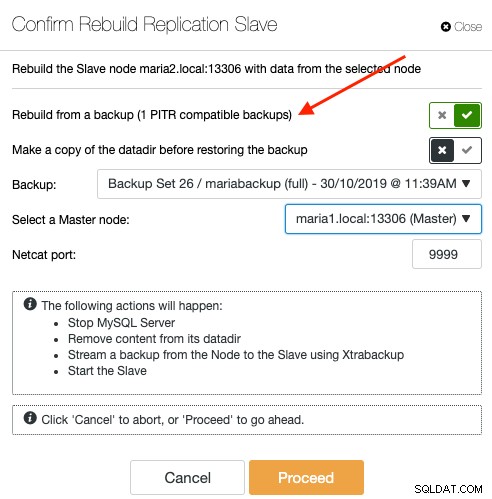
Ponowna synchronizacja urządzenia podrzędnego z kopii zapasowej nie przyniesie żadnych dodatkowych kosztów pracy urządzenia nadrzędnego, ponieważ ClusterControl wyodrębnia i przesyła kopię zapasową z lokalizacji przechowywania kopii zapasowych do urządzenia podrzędnego i ostatecznie konfiguruje łącze replikacji między urządzeniem podrzędnym a urządzeniem nadrzędnym. Slave później dogoni mastera po ustanowieniu łącza replikacji. Master jest nietknięty podczas całego procesu, a cały postęp możesz monitorować w Aktywność -> Zadania.
Bootstrap klastra Galera
Galera Cluster jest bardzo popularny podczas wdrażania wysokiej dostępności dla MySQL lub MariaDB, ale niewłaściwe polecenia zarządzania mogą prowadzić do katastrofalnych konsekwencji. Zajrzyj do tego wpisu na blogu, w którym opisano, jak załadować klaster Galera w różnych warunkach. Pokazuje to, że ładowanie początkowe klastra Galera ma wiele zmiennych i musi być wykonywane z najwyższą ostrożnością. W przeciwnym razie możesz utracić dane lub spowodować rozszczepienie mózgu. ClusterControl rozumie topologię bazy danych i dokładnie wie, co zrobić, aby poprawnie załadować klaster bazy danych. Aby załadować klaster za pomocą ClusterControl, kliknij Cluster Actions -> Bootstrap Cluster:
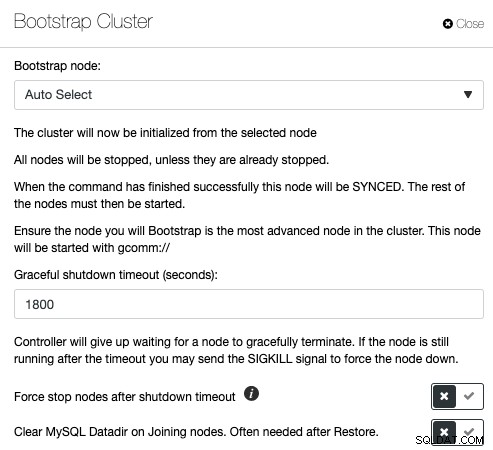
Będziesz mieć możliwość umożliwienia ClusterControl automatycznego wybrania właściwego węzła ładowania początkowego lub wykonania początkowego ładowania początkowego, w którym wybierasz jeden z węzłów bazy danych z listy, aby stać się węzłem referencyjnym i wymazać katalog danych MySQL na węzłach dołączających, aby wymusić SST z ładowany węzeł. Jeśli proces ładowania początkowego się nie powiedzie, ClusterControl pobierze dziennik błędów MySQL.
Jeśli chcesz przeprowadzić ręczny ładowanie początkowe, możesz również użyć funkcji „Znajdź najbardziej zaawansowany węzeł” i wykonać operację ładowania początkowego klastra na najbardziej zaawansowanym węźle zgłoszonym przez ClusterControl.
Scentralizowana konfiguracja i rejestrowanie
ClusterControl pobiera wiele ważnych plików konfiguracyjnych i rejestrujących i wyświetla je w strukturze drzewa w ClusterControl. Scentralizowany widok tych plików jest kluczem do skutecznego zrozumienia i rozwiązywania problemów z konfiguracjami rozproszonych baz danych. Tradycyjny sposób śledzenia/grepowania tych plików już dawno zniknął z ClusterControl. Poniższy zrzut ekranu pokazuje menedżera plików konfiguracyjnych ClusterControl, który wylistował wszystkie powiązane pliki konfiguracyjne dla tego klastra w jednym widoku (oczywiście z podświetlaniem składni):
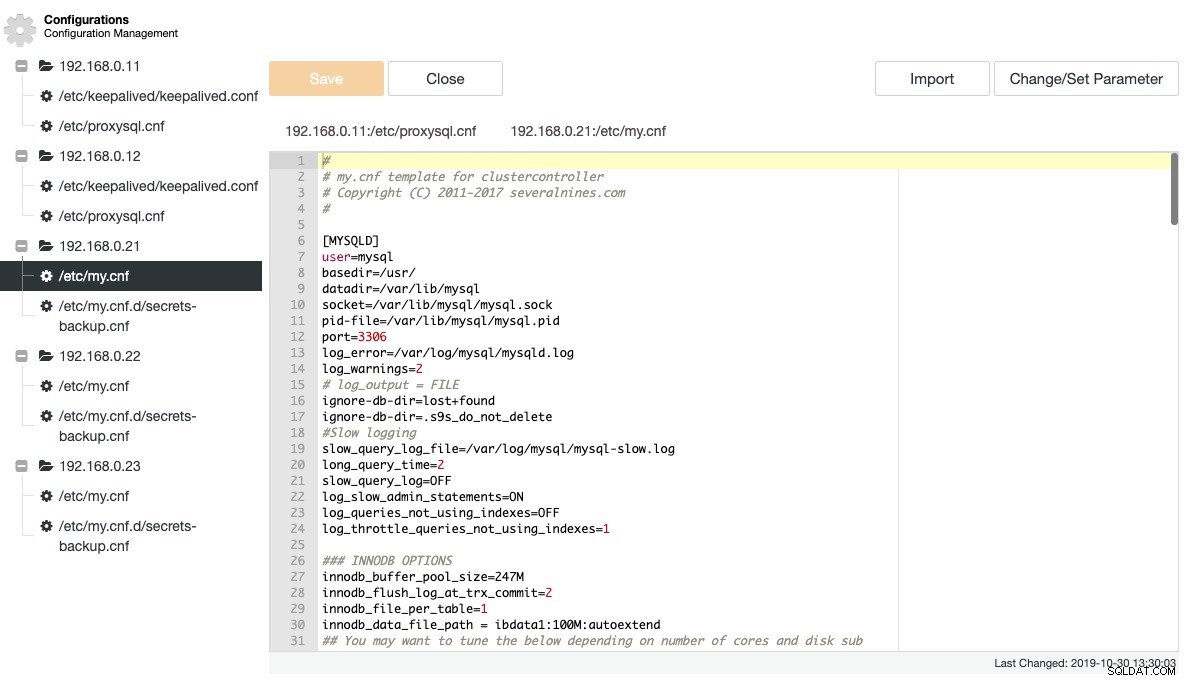
ClusterControl eliminuje powtarzalność podczas zmiany opcji konfiguracyjnej klastra bazy danych. Zmiana opcji konfiguracji na wielu węzłach może być wykonana za pośrednictwem jednego interfejsu i zostanie odpowiednio zastosowana do węzła bazy danych. Po kliknięciu „Zmień/Ustaw parametr” możesz wybrać instancje bazy danych, które chcesz zmienić, i określić grupę konfiguracji, parametr i wartość:
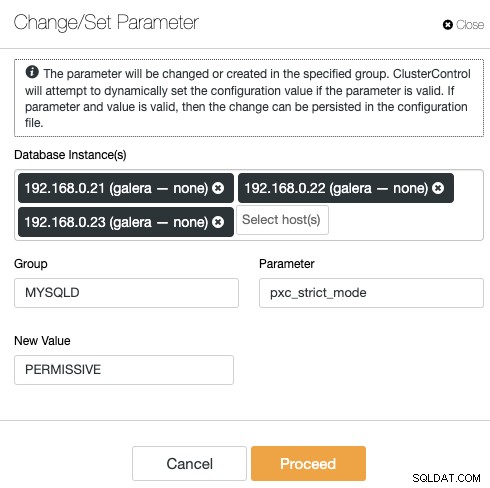
Możesz dodać nowy parametr do pliku konfiguracyjnego lub zmodyfikować istniejący parametr . Parametr zostanie zastosowany do środowiska uruchomieniowego wybranych węzłów bazy danych oraz do pliku konfiguracyjnego, jeśli opcja przejdzie proces walidacji zmiennych. Niektóre zmienne mogą wymagać ponownego uruchomienia serwera, co zostanie następnie zalecone przez ClusterControl.
Klonowanie klastra bazy danych
Dzięki ClusterControl możesz szybko sklonować istniejący klaster MySQL Galera, aby uzyskać dokładną kopię zestawu danych w innym klastrze. ClusterControl wykonuje operację klonowania online, bez blokowania lub przestoju istniejącego klastra. Przypomina to operację skalowania klastra w poziomie, z wyjątkiem tego, że oba klastry są niezależne od siebie po zakończeniu synchronizacji. Sklonowany klaster niekoniecznie musi mieć taki sam rozmiar klastra jak istniejący. Moglibyśmy zacząć od „klastra z jednym węzłem” i skalować go z większą liczbą węzłów bazy danych na późniejszym etapie.
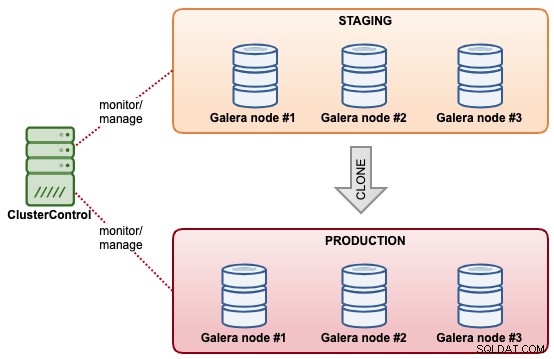
Kolejną podobną funkcją oferowaną przez ClusterControl jest „Utwórz klaster z kopii zapasowej”. Ta funkcja została wprowadzona w ClusterControl 1.7.1, specjalnie dla klastrów Galera Cluster i PostgreSQL, w których można utworzyć nowy klaster z istniejącej kopii zapasowej. W przeciwieństwie do klonowania klastra ta operacja nie powoduje dodatkowego obciążenia klastra źródłowego z kompromisem polegającym na tym, że sklonowany klaster nie będzie w tym samym stanie co klaster źródłowy.
Szczegółowo omówiliśmy ten temat w tym poście na blogu, Jak utworzyć klon swojego klastra bazy danych MySQL lub PostgreSQL.
Przywróć fizyczną kopię zapasową
Większość narzędzi do zarządzania bazami danych umożliwia tworzenie kopii zapasowych bazy danych, a tylko kilka z nich obsługuje tylko przywracanie bazy danych z logicznej kopii zapasowej. ClusterControl obsługuje pełne przywracanie nie tylko logicznych kopii zapasowych, ale także fizycznych kopii zapasowych, niezależnie od tego, czy jest to pełna, czy przyrostowa kopia zapasowa. Przywrócenie fizycznej kopii zapasowej wymaga szeregu krytycznych kroków (zwłaszcza przyrostowych kopii zapasowych), które zasadniczo obejmują przygotowanie kopii zapasowej, skopiowanie przygotowanych danych do katalogu danych, przypisanie odpowiednich uprawnień/własności i uruchomienie węzła w odpowiedniej kolejności w celu zachowania spójności danych w całym wszystkich członków klastra. ClusterControl wykonuje wszystkie te operacje automatycznie.
Fizyczną kopię zapasową można również przywrócić do innego węzła, który nie jest częścią klastra. W ClusterControl opcja ta nazywa się „Utwórz klaster z kopii zapasowej”. Możesz zacząć od „klastra z jednym węzłem”, aby przetestować proces przywracania na innym serwerze lub skopiować klaster bazy danych do innej lokalizacji.
ClusterControl obsługuje również przywracanie zewnętrznej kopii zapasowej, która nie została wykonana przez ClusterControl. Wystarczy przesłać kopię zapasową na serwer ClusterControl i określić fizyczną ścieżkę do pliku kopii zapasowej podczas przywracania. ClusterControl zajmie się resztą.
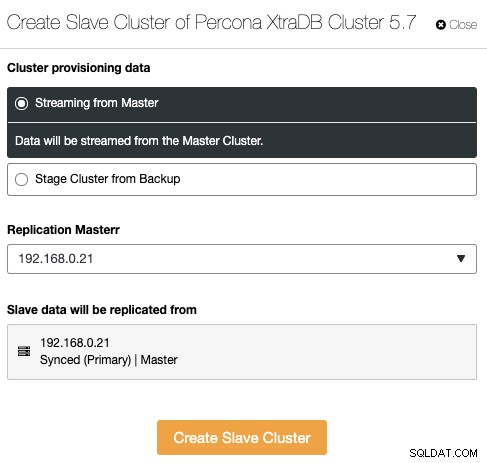
Replikacja między klastrami
To nowa funkcja wprowadzona w ClusterControl 1.7.4. ClusterControl może teraz obsługiwać i monitorować replikację klastrów, co zasadniczo rozszerza asynchroniczną replikację bazy danych między wieloma zestawami klastrów w wielu lokalizacjach geograficznych. Klaster można ustawić jako klaster główny (klaster aktywny, który przetwarza odczyty/zapisy), a klaster podrzędny można ustawić jako klaster tylko do odczytu (klaster w trybie gotowości, który może również przetwarzać odczyty). ClusterControl obsługuje asynchroniczną replikację klastrów dla klastra Galera (musi być włączony dziennik binarny), a także replikację master-slave dla replikacji strumieniowej PostgreSQL.
Aby utworzyć nowy klaster replikowany z innego klastra, przejdź do Akcje klastra -> Utwórz klaster podrzędny:
Wynik powyższego wdrożenia jest wyraźnie przedstawiony na pulpicie nawigacyjnym Database Cluster List :
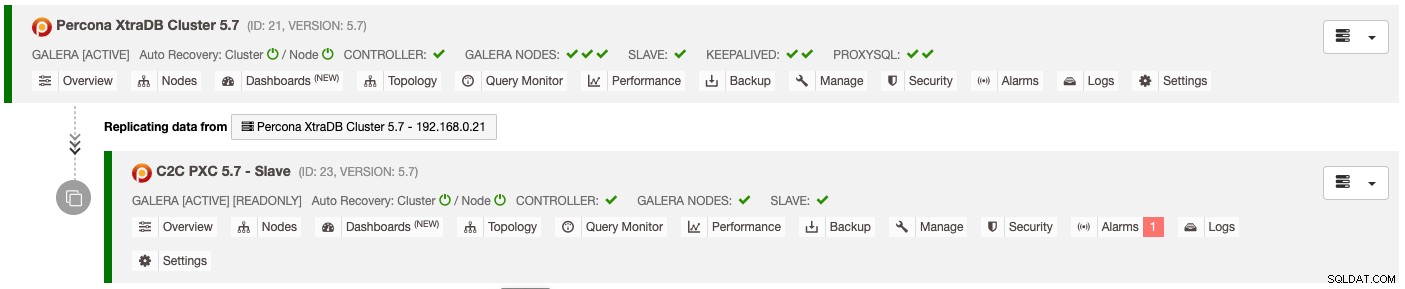
Klaster podrzędny jest automatycznie konfigurowany jako tylko do odczytu, replikujący się z klastra podstawowego i działający jako klaster rezerwowy. Jeśli awaria dotknie klastra podstawowego i chcesz aktywować lokację dodatkową, po prostu wybierz menu „Wyłącz tylko do odczytu” dostępne w menu rozwijanym Węzły -> Akcje węzła, aby promować go jako klaster aktywny.



