Równowaga obciążenia bazy danych umożliwia dystrybucję równoczesnych żądań klientów do wielu serwerów baz danych w celu zmniejszenia obciążenia pojedynczego serwera. Może to znacznie poprawić wydajność bazy danych. Na szczęście MongoDB domyślnie może obsłużyć wiele żądań klientów dotyczących jednoczesnego odczytu i zapisu tych samych danych. Wykorzystuje pewne mechanizmy kontroli współbieżności i protokoły blokowania, aby zapewnić spójność danych przez cały czas.
W ten sposób MongoDB zapewnia również, że wszyscy klienci otrzymują spójny widok danych w dowolnym momencie. Dzięki tej wbudowanej funkcji obsługi żądań od wielu klientów nie musisz się martwić o dodanie zewnętrznego modułu równoważenia obciążenia na serwerach MongoDB. Chociaż, jeśli nadal chcesz poprawić wydajność swojej bazy danych za pomocą równoważenia obciążenia, oto kilka sposobów, aby to osiągnąć.
Skalowanie w pionie MongoDB
W uproszczeniu skalowanie w pionie oznacza dodawanie do serwera większej ilości zasobów do obsługi w celu załadowania. Podobnie jak wszystkie systemy baz danych, MongoDB preferuje większą pojemność pamięci RAM i IO. Jest to najprostszy sposób na zwiększenie wydajności MongoDB bez rozkładania obciążenia na wiele serwerów. Skalowanie w pionie bazy danych MongoDB zazwyczaj obejmuje zwiększenie pojemności procesora lub pojemności dysku oraz zwiększenie przepustowości (operacje we/wy). Dodając więcej zasobów, twój serwer mongo staje się bardziej zdolny do obsługi wielu żądań klientów. W ten sposób lepsze równoważenie obciążenia Twojej bazy danych.
Wadą korzystania z tego podejścia jest techniczne ograniczenie dodawania zasobów do dowolnego pojedynczego systemu. Ponadto wszyscy dostawcy usług w chmurze mają ograniczenia dotyczące dodawania nowych konfiguracji sprzętowych. Inną wadą tego podejścia jest pojedynczy punkt awarii. W tym podejściu wszystkie Twoje dane są przechowywane w jednym systemie, co może prowadzić do trwałej utraty danych.
Skalowanie poziome MongoDB
Skalowanie w poziomie odnosi się do dzielenia bazy danych na części i przechowywania ich na wielu serwerach. Główną zaletą tego podejścia jest możliwość dodawania dodatkowych serwerów w locie, aby zwiększyć wydajność bazy danych bez przestojów. MongoDB zapewnia skalowanie w poziomie poprzez sharding. Fragmentacja MongoDB zapewnia dodatkową zdolność do rozłożenia obciążenia zapisu na wiele serwerów (odłamków). Tutaj każdy fragment może być postrzegany jako jedna niezależna baza danych, a kolekcja wszystkich fragmentów może być postrzegana jako jedna duża logiczna baza danych. Sharding umożliwia Twojej bazie danych MongoDB dystrybucję danych na wielu serwerach w celu wydajnej obsługi jednoczesnych żądań klientów. W związku z tym zwiększa przepustowość odczytu i zapisu Twojej bazy danych.
Sharding MongoDB
Shard może być pojedynczą instancją mongod lub zestawem replik, który przechowuje podzbiór podzielonej bazy danych mongo. Możesz przekonwertować fragment w zestawie replik, aby zapewnić wysoką dostępność danych i nadmiarowość.
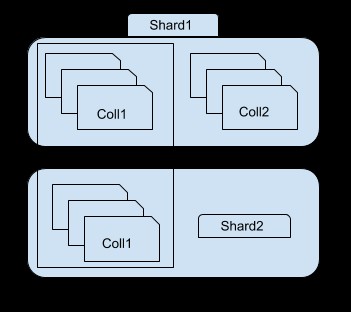
Jak widać na powyższym obrazku, fragment 1 zawiera podzbiór kolekcja 1 i cała kolekcja2, podczas gdy fragment 2 zawiera tylko inny podzbiór kolekcji1. Możesz uzyskać dostęp do każdego odłamka za pomocą instancji mongos. Na przykład, jeśli połączysz się z instancją shard1, będziesz mógł zobaczyć/uzyskać dostęp tylko do podzbioru kolekcji 1.
Mongo
Mongos to router zapytań, który zapewnia dostęp do klastra podzielonego na fragmenty dla aplikacji klienckich. Możesz mieć wiele instancji Mongos dla lepszego równoważenia obciążenia. Na przykład w klastrze produkcyjnym możesz mieć jedną instancję Mongos dla każdego serwera aplikacji. Teraz możesz użyć zewnętrznego load balancera, który przekieruje żądanie twojego serwera aplikacji do odpowiedniej instancji mongos. Dodając takie konfiguracje do serwera produkcyjnego, upewnij się, że połączenie z dowolnego klienta zawsze łączy się z tą samą instancją mongos za każdym razem, ponieważ niektóre zasoby mongo, takie jak kursory, są specyficzne dla instancji mongos.
Serwery konfiguracyjne
Serwery konfiguracyjne przechowują ustawienia konfiguracyjne i metadane dotyczące Twojego klastra. Od wersji MongoDB 3.4 musisz wdrożyć serwery konfiguracyjne jako zestaw replik. Jeśli włączasz sharding w środowisku produkcyjnym, obowiązkowe jest użycie trzech oddzielnych serwerów konfiguracyjnych, każdy na różnych maszynach.
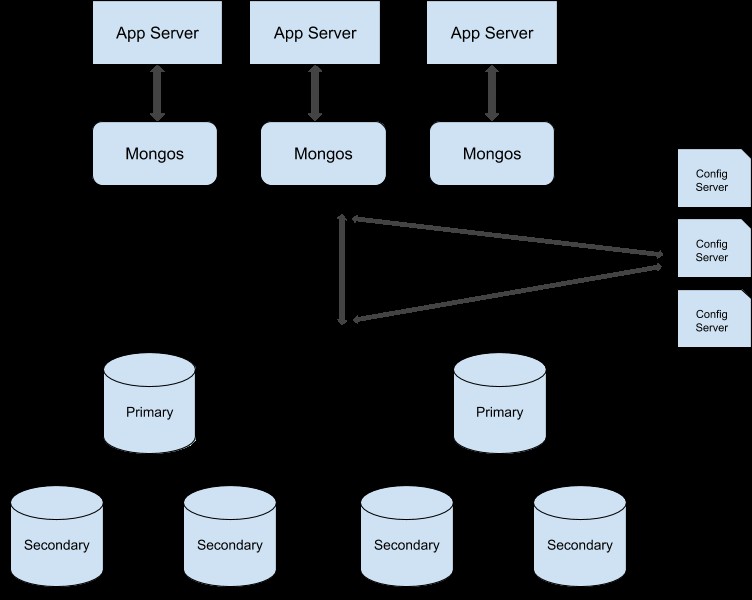
Możesz postępować zgodnie z tym przewodnikiem, aby przekonwertować klaster zestawu replik na klaster podzielony na fragmenty. Oto przykładowa ilustracja klastra produkcyjnego podzielonego na fragmenty:
Równoważenie obciążenia MongoDB przy użyciu replikacji
Czasami replikacji MongoDB można użyć do obsługi większego ruchu od klientów i zmniejszenia obciążenia serwera podstawowego. W tym celu można poinstruować klientów, aby odczytywali z serwerów pomocniczych zamiast z serwera głównego. Może to zmniejszyć obciążenie serwera głównego, ponieważ wszystkie żądania odczytu pochodzące od klientów będą obsługiwane przez serwery pomocnicze, a serwer główny zajmie się tylko żądaniami zapisu.
Następuje polecenie do ustawienia preferencji odczytu na drugorzędne:
db.getMongo().setReadPref('secondary')Możesz także określić niektóre tagi, aby kierować określone elementy pomocnicze podczas obsługi zapytań odczytu.
db.getMongo().setReadPref(
"secondary", [
{ "datacenter": "APAC" },
{ "region": "East"},
{}
])Tutaj MongoDB spróbuje znaleźć węzeł pomocniczy z wartością tagu centrum danych jako APAC. Jeśli zostanie znaleziony, Mongo obsłuży żądania odczytu ze wszystkich urządzeń pomocniczych z centrum danych tagów:„APAC”. Jeśli nie zostanie znaleziony, Mongo spróbuje znaleźć wtórne z regionem tagu:„Wschód”. Jeśli nadal nie znaleziono plików pomocniczych, {} będzie działać jako przypadek domyślny, a Mongo będzie obsługiwać żądania wszystkich kwalifikujących się plików pomocniczych.
Jednak to podejście do równoważenia obciążenia nie jest zalecane do zwiększania przepustowości odczytu. Ponieważ każdy tryb preferencji odczytu inny niż podstawowy może zwracać stare dane w przypadku ostatnich aktualizacji zapisu na serwerze podstawowym. Zwykle serwer główny zajmuje trochę czasu, aby obsłużyć żądania zapisu i propaguje zmiany na serwerach pomocniczych. W tym czasie, jeśli ktoś zażąda operacji odczytu na tych samych danych, serwer pomocniczy zwróci przestarzałe dane, ponieważ nie jest zsynchronizowany z serwerem głównym. Możesz użyć tego podejścia, jeśli twoja aplikacja ma dużo operacji odczytu w porównaniu z operacjami zapisu.
Wnioski
Ponieważ MongoDB może samodzielnie obsługiwać współbieżne żądania, nie ma potrzeby dodawania modułu równoważenia obciążenia w klastrze MongoDB. W przypadku równoważenia obciążenia żądań klienta można wybrać skalowanie pionowe lub poziome, ponieważ nie zaleca się używania elementów pomocniczych do skalowania operacji odczytu i zapisu. Jak omówiono powyżej, skalowanie w pionie może przekroczyć granice techniczne. Dlatego nadaje się do zastosowań na małą skalę. W przypadku dużych aplikacji skalowanie poziome poprzez sharding jest najlepszym podejściem do równoważenia obciążenia operacji odczytu i zapisu.



