Jeśli chodzi o tworzenie kopii zapasowych i archiwizację danych, działy IT znajdują się pod presją przestrzegania bardziej rygorystycznych umów dotyczących poziomu usług, dostarczania większej liczby niestandardowych raportów i przestrzegania rozszerzających się wymagań dotyczących zgodności, przy jednoczesnym dalszym zarządzaniu codziennymi zadaniami archiwizacji i tworzenia kopii zapasowych. Bez wątpienia serwer bazy danych przechowuje niektóre z najcenniejszych informacji przedsiębiorstwa. Gwarantowanie niezawodnych kopii zapasowych baz danych, aby zapobiec utracie danych w razie wypadku lub awarii sprzętu, jest kluczowym polem wyboru.
Ale jak zrobić to naprawdę DR, gdy wszystkie dane znajdują się w jednym centrum danych lub nawet w centrach danych, które znajdują się w bliskiej geolokalizacji? Co więcej, niezależnie od tego, czy jest to mocno obciążony serwer 24x7, czy środowisko o niskim wolumenie transakcji, będziesz potrzebować tworzenia kopii zapasowych bezproblemową procedurą bez zakłócania wydajności serwera w środowisku produkcyjnym.
W tym blogu przyjrzymy się kopii zapasowej MongoDB w chmurze. Chmura zmieniła branżę tworzenia kopii zapasowych danych. Ze względu na przystępną cenę mniejsze firmy mają rozwiązanie poza siedzibą firmy, które tworzy kopie zapasowe wszystkich ich danych.
Pokażemy Ci, jak wykonywać bezpieczne kopie zapasowe MongoDB przy użyciu usług mongo, a także innych metod, których możesz użyć, aby rozszerzyć opcje odzyskiwania po awarii bazy danych.
Jeśli serwer lub miejsce docelowe kopii zapasowej znajduje się w odsłoniętej infrastrukturze, takiej jak chmura publiczna, dostawca usług hostingowych lub jest połączone przez niezaufaną sieć WAN, należy pomyśleć o dodatkowych działaniach w zasadach tworzenia kopii zapasowych. Istnieje kilka różnych sposobów wykonywania kopii zapasowych bazy danych dla MongoDB, a w zależności od typu kopii zapasowej, czas odzyskiwania, rozmiar i opcje infrastruktury będą się różnić. Ponieważ wiele rozwiązań do przechowywania w chmurze to po prostu pamięć masowa z różnymi interfejsami API, każde rozwiązanie do tworzenia kopii zapasowych można wykonać za pomocą odrobiny skryptów. Więc jakie mamy opcje, aby proces był płynny i bezpieczny?
Szyfrowanie kopii zapasowych MongoDB
Bezpieczeństwo powinno być w centrum wszystkich działań podejmowanych przez zespoły IT. Zawsze dobrze jest wymusić szyfrowanie w celu zwiększenia bezpieczeństwa danych kopii zapasowej. Prostym przypadkiem użycia szyfrowania jest sytuacja, w której chcesz przenieść kopię zapasową do zewnętrznej pamięci masowej znajdującej się w chmurze publicznej.
Podczas tworzenia zaszyfrowanej kopii zapasowej należy pamiętać, że jej odzyskanie zwykle zajmuje więcej czasu. Kopia zapasowa musi zostać odszyfrowana przed podjęciem jakichkolwiek działań związanych z odzyskiwaniem. W przypadku dużego zestawu danych może to spowodować pewne opóźnienia w RTO.
Z drugiej strony, jeśli używasz kluczy prywatnych do szyfrowania, upewnij się, że przechowujesz klucz w bezpiecznym miejscu. Jeśli brakuje klucza prywatnego, kopia zapasowa będzie bezużyteczna i niemożliwa do odzyskania. Jeśli klucz zostanie skradziony, wszystkie utworzone kopie zapasowe używające tego samego klucza zostaną naruszone, ponieważ nie będą już zabezpieczone. Możesz użyć popularnego GnuPG lub OpenSSL do wygenerowania kluczy prywatnych lub publicznych.
Aby wykonać szyfrowanie MongoDBdump przy użyciu GnuPG, wygeneruj klucz prywatny i postępuj zgodnie z instrukcjami kreatora:
$ gpg --gen-keyUtwórz zwykłą kopię zapasową MongoDBdump jak zwykle:
$ mongodump –db db1 –gzip –archive=/tmp/db1.tar.gz$ gpg --encrypt -r ‘example@sqldat.com’ db1.tar.gz
$ rm -f db1.tar.gzpo prostu uruchom polecenie gpg z flagą --decrypt:
$ gpg --output db1.tar.gz --decrypt db1.tar.gz.gpgOpenSSL req -x509 -nodes -newkey rsa:2048 -keyout dump.priv.pem -out dump.pub.pemTen klucz prywatny (dump.priv.pem) musi być przechowywany w bezpiecznym miejscu do późniejszego odszyfrowania. W przypadku Mongodump można utworzyć zaszyfrowaną kopię zapasową, na przykład przesyłając zawartość do openssl
mongodump –db db1 –gzip –archive=/tmp/db1.tar.gz | openssl smime -encrypt -binary -text -aes256
-out database.sql.enc -outform DER dump.pub.pemopenssl smime -decrypt -in database.sql.enc -binary -inform
DEM -inkey dump.priv.pem -out db1.tar.gzKompresja kopii zapasowej MongoDB
W świecie tworzenia kopii zapasowych baz danych w chmurze kompresja jest jednym z Twoich najlepszych przyjaciół. Może nie tylko zaoszczędzić miejsce na dysku, ale może również znacznie skrócić czas wymagany do pobierania/przesyłania danych.
Oprócz archiwizacji dodaliśmy również obsługę kompresji za pomocą gzip. Zostało to ujawnione przez wprowadzenie nowej opcji wiersza poleceń „--gzip” zarówno w mongodump, jak i mongorestore. Kompresja działa zarówno w przypadku kopii zapasowych utworzonych przy użyciu katalogu, jak i w trybie archiwum oraz zmniejsza użycie miejsca na dysku.
Normalnie zrzut MongoDB może mieć najlepsze współczynniki kompresji, ponieważ jest to płaski plik tekstowy. W zależności od narzędzia i współczynnika kompresji skompresowany MongoDBdump może być do 6 razy mniejszy niż oryginalny rozmiar kopii zapasowej. Aby skompresować kopię zapasową, możesz przesłać dane wyjściowe MongoDBdump do narzędzia do kompresji i przekierować je do pliku docelowego
Skompresowana kopia zapasowa może zaoszczędzić do 50% oryginalnego rozmiaru kopii zapasowej, w zależności od zestawu danych.
mongodump --db country --gzip --archive=country.archiveOgraniczanie przepustowości sieci
Doskonałą opcją dla kopii zapasowych w chmurze jest ograniczenie przepustowości sieci (Mb/s) podczas tworzenia kopii zapasowej. Możesz to osiągnąć za pomocą narzędzia pv. Narzędzie pv jest dostarczane z opcjami modyfikatorów danych -L RATE, --rate-limit RATE, które ograniczają transfer do maksymalnie RATE bajtów na sekundę. Poniższy przykład ograniczy to do 2MB/s.
$ pv -q -L 2mPrzenoszenie kopii zapasowych MongoDB do chmury
Teraz, gdy kopia zapasowa jest skompresowana i zabezpieczona (zaszyfrowana), jest gotowa do transferu.
Google Cloud
Narzędzie wiersza poleceń gsutil służy do zarządzania, monitorowania i używania zasobników na dane w Google Cloud Storage. Jeśli już zainstalowałeś narzędzie gcloud, masz już zainstalowany gsutil. W przeciwnym razie postępuj zgodnie z instrukcjami dla swojej dystrybucji Linuksa tutaj.
Aby zainstalować gcloud CLI, wykonaj poniższą procedurę:
curl https://sdk.cloud.google.com | bashexec -l $SHELLgcloud initgsutil mb -c regional -l europe-west1 gs://severalnines-storage/
Creating gs://MongoDB-backups-storage/Amazon S3
Jeśli nie używasz RDS do hostowania swoich baz danych, jest bardzo prawdopodobne, że tworzysz własne kopie zapasowe. Platforma AWS firmy Amazon, S3 (Amazon Simple Storage Service) to usługa przechowywania danych, której można używać do przechowywania kopii zapasowych baz danych lub innych plików o znaczeniu krytycznym dla firmy. Niezależnie od tego, czy jest to instancja Amazon EC2, czy środowisko lokalne, możesz użyć tej usługi do zabezpieczenia swoich danych.
Podczas gdy kopie zapasowe można przesyłać za pośrednictwem interfejsu internetowego, dedykowany interfejs wiersza poleceń s3 może być używany do robienia tego z wiersza poleceń i za pomocą skryptów automatyzacji tworzenia kopii zapasowych. Jeśli kopie zapasowe mają być przechowywane przez bardzo długi czas, a czas odzyskiwania nie stanowi problemu, kopie zapasowe można przenieść do usługi Amazon Glacier, która zapewnia znacznie tańsze długoterminowe przechowywanie. Pliki (obiekty amazon) są logicznie przechowywane w ogromnym płaskim kontenerze o nazwie bucket. S3 przedstawia interfejs REST swoim wnętrzom. Możesz użyć tego interfejsu API do wykonywania operacji CRUD na zasobnikach i obiektach, a także do zmiany uprawnień i konfiguracji w obu.
Podstawową metodą dystrybucji AWS CLI w systemach Linux, Windows i macOS jest pip, menedżer pakietów dla Pythona. Instrukcje znajdziesz tutaj.
aws s3 cp severalnines.sql s3://severalnine-sbucket/MongoDB_backupsMicrosoft Azure Storage
Platforma chmury publicznej firmy Microsoft, Azure, oferuje opcje przechowywania z interfejsem linii kontrolnej. Informacje można znaleźć tutaj. Wieloplatformowy interfejs wiersza polecenia platformy Azure typu open source udostępnia zestaw poleceń do pracy z platformą Azure. Zapewnia wiele funkcji widocznych w portalu Azure, w tym bogaty dostęp do danych.
Instalacja interfejsu wiersza polecenia platformy Azure jest dość prosta, instrukcje można znaleźć tutaj. Poniżej możesz dowiedzieć się, jak przenieść kopię zapasową do pamięci Microsoft.
az storage blob upload --container-name severalnines --file severalnines.gz.tar --name severalnines_backupHybrydowa pamięć masowa dla kopii zapasowych MongoDB
Wraz z rosnącą branżą pamięci masowej w chmurze publicznej i prywatnej, mamy nową kategorię o nazwie pamięci masowej hybrydowej. Typowym podejściem jest przechowywanie danych na dyskach lokalnych przez krótszy czas, podczas gdy przechowywanie kopii zapasowych w chmurze byłoby przechowywane przez dłuższy czas. Wielokrotnie wymóg dłuższego przechowywania kopii zapasowych wynika z zobowiązań prawnych dla różnych branż (np. Telekomy muszą przechowywać metadane połączeń). Ta technologia umożliwia przechowywanie plików lokalnie, a zmiany są automatycznie synchronizowane ze zdalnym dostępem w chmurze. Takie podejście wynika z potrzeby posiadania najnowszych kopii zapasowych przechowywanych lokalnie w celu szybkiego przywracania (niższe RTO), a także celów ciągłości biznesowej.
Ważnym aspektem efektywnego wykorzystania zasobów jest posiadanie oddzielnych retencji kopii zapasowych. Dane przechowywane lokalnie, na nadmiarowych dyskach twardych byłyby przechowywane krócej, podczas gdy przechowywanie kopii zapasowych w chmurze byłoby przechowywane przez dłuższy czas. Wielokrotnie wymóg dłuższego przechowywania kopii zapasowych wynika z zobowiązań prawnych dla różnych branż (takich jak telekomunikacja, która musi przechowywać metadane połączeń).
Dostawcy usług w chmurze, tacy jak Google Cloud Services, Microsoft Azure i Amazon S3, oferują praktycznie nieograniczone miejsce na dane, zmniejszając lokalne zapotrzebowanie na przestrzeń. Pozwala to na dłuższe przechowywanie plików kopii zapasowej, tak długo, jak chcesz i nie ma obaw związanych z lokalną przestrzenią dyskową.
Zarządzanie kopiami zapasowymi ClusterControl — pamięć masowa hybrydowa
Podczas planowania tworzenia kopii zapasowej za pomocą ClusterControl, każda z metod tworzenia kopii zapasowych jest konfigurowalna z zestawem opcji dotyczących sposobu wykonywania kopii zapasowej. Najważniejsze dla hybrydowego przechowywania w chmurze to:
- Ograniczanie przepustowości sieci
- Szyfrowanie z wbudowanym zarządzaniem kluczami
- Kompresja
- Okres przechowywania lokalnych kopii zapasowych
- Okres przechowywania kopii zapasowych w chmurze
ClusterControl zaawansowane funkcje tworzenia kopii zapasowych w chmurze, kompresja równoległa, limit przepustowości sieci, szyfrowanie itp. Twoja firma może skorzystać ze skalowalności chmury i opłat zgodnie z rzeczywistym użyciem w przypadku rosnących potrzeb w zakresie pamięci masowej. Możesz zaprojektować strategię tworzenia kopii zapasowych, aby zapewnić zarówno lokalne kopie w centrum danych w celu natychmiastowego przywrócenia, jak i bezproblemową bramę do usług przechowywania w chmurze od AWS, Google i Azure.
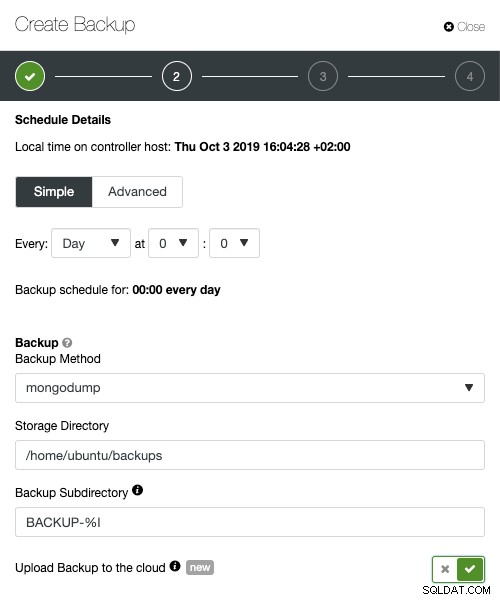
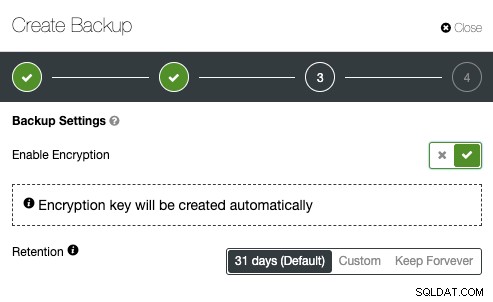
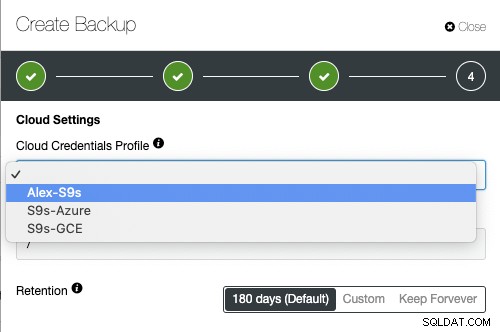
Zaawansowane TLS i AES 256 -bitowe funkcje szyfrowania i kompresji obsługują bezpieczne kopie zapasowe, które zajmują znacznie mniej miejsca w chmurze.



