Przerwy w produkcji są prawie gwarantowane w pewnym momencie. Zaakceptowanie tego faktu i przeanalizowanie harmonogramu i scenariusza awarii bazy danych może pomóc w lepszym przygotowaniu, zdiagnozowaniu i odzyskaniu sprawności po następnym awarii. Aby złagodzić wpływ przestojów, organizacje potrzebują odpowiedniego planu odzyskiwania po awarii (DR). Planowanie DR jest krytycznym zadaniem dla wielu SysOps/DevOps, ale nawet jeśli jest przewidziane; często nie istnieje.
W tym poście na blogu przeanalizujemy różne scenariusze tworzenia kopii zapasowych i awarii w systemach baz danych MongoDB. Przeprowadzimy Cię również przez procedury odzyskiwania i przełączania awaryjnego dla każdego odpowiedniego scenariusza. Te przypadki użycia będą się różnić od przywracania pojedynczego węzła, przywracania węzła w istniejącym zestawie replik i umieszczania nowego węzła w zestawie replik. Mamy nadzieję, że pozwoli to dobrze zrozumieć ryzyko, z którym możesz się zmierzyć, i co należy wziąć pod uwagę podczas projektowania infrastruktury.
Zanim zaczniemy omawiać możliwe scenariusze awarii, przyjrzyjmy się, jak MongoDB przechowuje dane i jakie typy kopii zapasowych są dostępne.
Jak MongoDB przechowuje dane
MongoDB to baza danych zorientowana na dokumenty. Zamiast przechowywać dane w tabelach utworzonych z pojedynczych wierszy (jak to robi relacyjna baza danych), przechowuje dane w kolekcjach utworzonych z pojedynczych dokumentów. W MongoDB dokument jest dużym obiektem blob JSON bez określonego formatu ani schematu. Ponadto dane mogą być rozłożone na różne węzły klastra z udostępnianiem lub replikacją na serwery podrzędne za pomocą zestawu repliki.
MongoDB domyślnie umożliwia bardzo szybkie zapisy i aktualizacje. Kompromis polega na tym, że często nie jesteś wyraźnie powiadamiany o awariach. Domyślnie większość sterowników wykonuje asynchroniczne, niebezpieczne zapisy. Oznacza to, że sterownik nie zwraca bezpośrednio błędu, podobnie jak w przypadku INSERT DELAYED w MySQL. Jeśli chcesz wiedzieć, czy coś się udało, musisz ręcznie sprawdzić błędy za pomocą getLastError.
W celu uzyskania optymalnej wydajności lepiej jest używać dysku SSD zamiast dysku twardego do przechowywania. Należy zadbać o to, czy pamięć ma charakter lokalny czy zdalny i podjąć odpowiednie środki. Lepiej jest używać RAID do ochrony defektów sprzętu i schematów odzyskiwania, ale nie polegaj na nim całkowicie, ponieważ nie zapewnia ochrony przed niepożądanymi awariami. Właściwy sprzęt jest elementem składowym Twojej aplikacji, aby zoptymalizować wydajność i uniknąć poważnej porażki.
Uszkodzenie danych na poziomie dysku lub brakujące pliki danych mogą uniemożliwić uruchomienie instancji mongod, a pliki dziennika mogą być niewystarczające do automatycznego odzyskania.
Jeśli pracujesz z włączonym dziennikiem, prawie nigdy nie ma potrzeby uruchamiania naprawy, ponieważ serwer może użyć plików dziennika do automatycznego przywrócenia plików danych do czystego stanu. Jednak nadal może być konieczne uruchomienie naprawy w przypadkach, gdy konieczne jest odzyskanie danych po uszkodzeniu danych na poziomie dysku.
Jeśli kronikowanie nie jest włączone, jedyną opcją może być uruchomienie polecenia naprawy. mongod --repair powinno być używane tylko wtedy, gdy nie masz innych opcji, ponieważ operacja usuwa (i nie zapisuje) wszelkich uszkodzonych danych podczas procesu naprawy. Tego typu operację należy zawsze poprzedzić backupem.
Scenariusz odzyskiwania po awarii MongoDB
W planie odzyskiwania po awarii, Twój Cel Punktu Odzyskiwania (RPO) jest kluczowym parametrem odzyskiwania, który określa, ile danych możesz utracić. RPO jest podany w czasie, od milisekund do dni i jest bezpośrednio zależny od systemu tworzenia kopii zapasowych. Uwzględnia wiek danych kopii zapasowej, które musisz odzyskać, aby wznowić normalne działanie.
Aby oszacować RPO, musisz zadać sobie kilka pytań. Kiedy tworzona jest kopia zapasowa moich danych? Jaka jest umowa SLA związana z pobieraniem danych? Czy można przywrócić kopię zapasową danych, czy też dane muszą być dostępne online i gotowe do przeszukiwania w dowolnym momencie?
Odpowiedzi na te pytania pomogą określić rodzaj potrzebnego rozwiązania do tworzenia kopii zapasowych.
Rozwiązania do tworzenia kopii zapasowych MongoDB
Techniki tworzenia kopii zapasowych mają różny wpływ na wydajność działającej bazy danych. Niektóre rozwiązania do tworzenia kopii zapasowych obniżają wydajność bazy danych na tyle, że może być konieczne zaplanowanie tworzenia kopii zapasowych w celu uniknięcia okresów szczytowego użytkowania lub konserwacji. Możesz zdecydować się na wdrożenie nowych serwerów pomocniczych tylko w celu obsługi kopii zapasowych.
Trzy najpopularniejsze rozwiązania do tworzenia kopii zapasowych serwera/klastra MongoDB to...
- Mongodump/Mongorestore — logiczna kopia zapasowa.
- Mongo Management System (Cloud) — produkcyjne bazy danych można tworzyć za pomocą MongoDB Ops Manager lub w przypadku korzystania z usługi MongoDB Atlas, można skorzystać z w pełni zarządzanego rozwiązania do tworzenia kopii zapasowych.
- Migawki bazy danych (kopia zapasowa na poziomie dysku)
Mongodump/Mongorestore
Podczas wykonywania mongodump wszystkie kolekcje w wyznaczonych bazach danych zostaną zrzucone jako dane wyjściowe BSON. Jeśli nie określono bazy danych, MongoDB zrzuci wszystkie bazy danych z wyjątkiem bazy danych administratora, testowej i lokalnej, ponieważ są one zarezerwowane do użytku wewnętrznego.
Domyślnie mongodump utworzy katalog o nazwie dump, z katalogiem dla każdej bazy danych zawierającej plik BSON na kolekcję w tej bazie danych. Alternatywnie możesz nakazać mongodumpowi przechowywanie kopii zapasowej w jednym pliku archiwum. Parametr archiwum połączy dane wyjściowe ze wszystkich baz danych i kolekcji w jeden strumień danych binarnych. Dodatkowo parametr gzip może naturalnie skompresować to archiwum za pomocą gzip. W ClusterControl przesyłamy strumieniowo wszystkie nasze kopie zapasowe, więc włączamy zarówno parametry archiwum, jak i gzip.
Podobnie do mysqldump z MySQL, jeśli utworzysz kopię zapasową w MongoDB, kolekcje zostaną zamrożone podczas zrzucania zawartości do pliku kopii zapasowej. Ponieważ MongoDB nie obsługuje transakcji (zmieniono w 4.2), nie można wykonać w pełni spójnej kopii zapasowej, chyba że utworzysz kopię zapasową z parametrem oplog. Włączenie tej opcji w kopii zapasowej obejmuje transakcje z oploga, które były wykonywane podczas tworzenia kopii zapasowej.
Dla lepszej automatyzacji i MongoDB można uruchomić z wiersza poleceń lub użyć zewnętrznych narzędzi, takich jak ClusterControl. ClusterControl jest zalecaną opcją do zarządzania kopiami zapasowymi i automatyzacji tworzenia kopii zapasowych, ponieważ umożliwia tworzenie zaawansowanych strategii tworzenia kopii zapasowych dla różnych systemów baz danych typu open source.
ClusterControl umożliwia przesłanie kopii zapasowej do chmury. Obsługuje pełną kopię zapasową i przywraca szyfrowanie mongodump. Jeśli chcesz zobaczyć, jak to działa, na naszej stronie internetowej znajduje się wersja demonstracyjna.
Przywracanie MongoDB z kopii zapasowej
Istnieją zasadniczo dwa sposoby wykorzystania zrzutu w formacie BSON:
- Uruchom mongod bezpośrednio z katalogu kopii zapasowej
- Uruchom mongorestore i przywróć kopię zapasową
Uruchom mongod bezpośrednio z kopii zapasowej
Warunkiem uruchomienia mongoda bezpośrednio z kopii zapasowej jest to, że miejscem docelowym kopii zapasowej jest standardowy zrzut i nie jest skompresowany gzipem.
Demon MongoDB sprawdzi następnie integralność katalogu danych, doda bazę danych administratora, czasopisma, katalogi kolekcji i indeksu oraz kilka innych plików niezbędnych do uruchomienia MongoDB. Jeśli wcześniej uruchomiłeś WiredTiger jako silnik magazynu, teraz będzie on uruchamiał istniejące kolekcje jako MMAP. W przypadku prostych zrzutów danych lub sprawdzania integralności działa to dobrze.
Uruchomienie sklepu mongorestore
Lepszym sposobem na przywrócenie byłoby oczywiście przywrócenie węzła za pomocą mongorestore.
mongorestore dump/Spowoduje to przywrócenie kopii zapasowej do domyślnych ustawień serwera (localhost, port 27017) i nadpisanie wszelkich baz danych w kopii zapasowej znajdujących się na tym serwerze. Teraz jest mnóstwo parametrów do manipulowania procesem przywracania, a my omówimy niektóre z najważniejszych.
W ClusterControl odbywa się to w opcji przywracania kopii zapasowej. Możesz wybrać maszynę, kiedy kopia zapasowa zostanie przywrócona i przetworzyć, a reszta zajmie się. Obejmuje to zaszyfrowaną kopię zapasową, w której normalnie konieczne byłoby również odszyfrowanie kopii zapasowej.
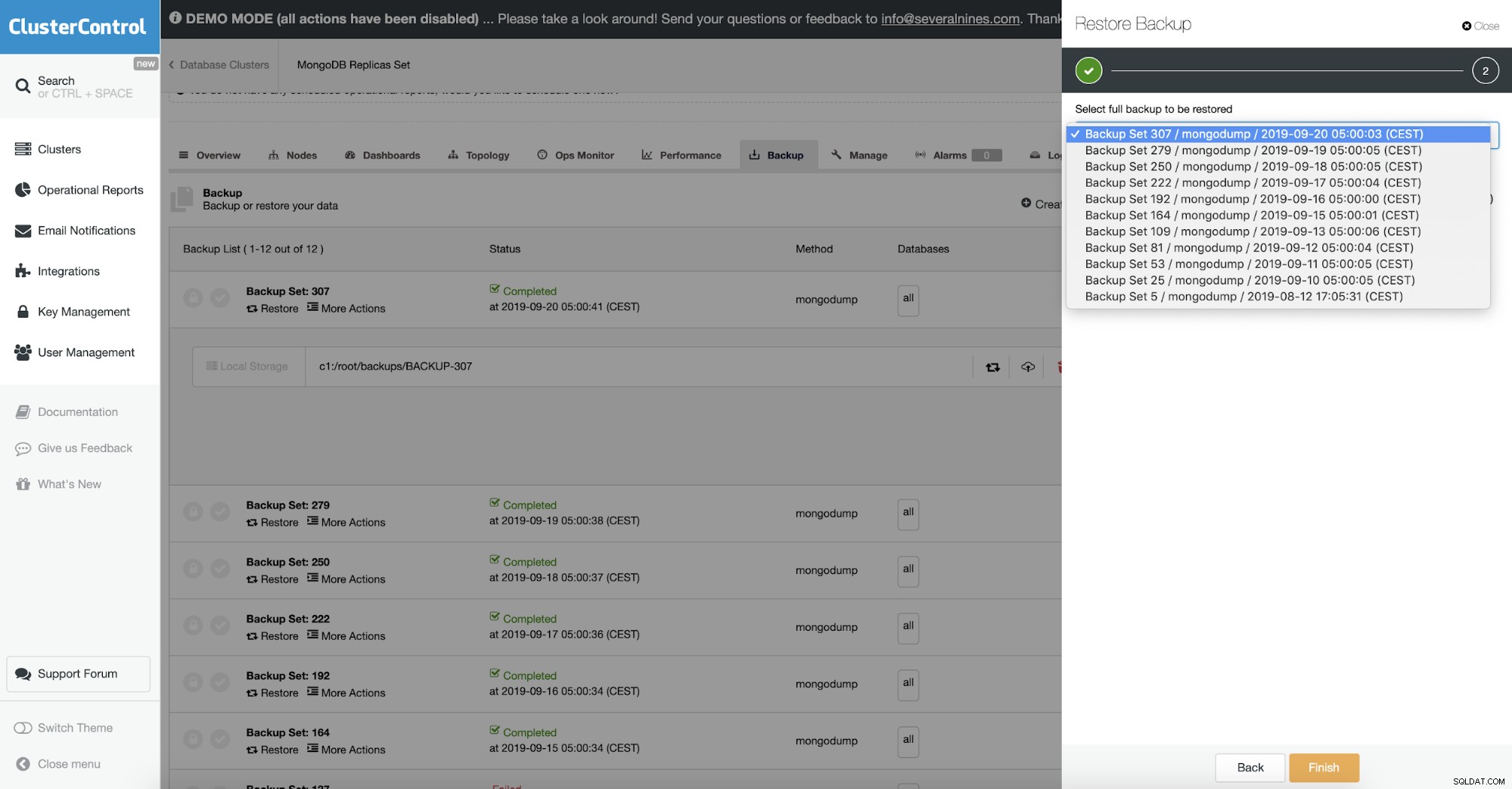
Weryfikacja obiektów
Ponieważ kopia zapasowa zawiera dane BSON, można oczekiwać, że zawartość kopii zapasowej będzie poprawna. Jednak mogło się zdarzyć, że dokument, który został porzucony, był zniekształcony. Mongodump nie sprawdza integralności danych, które zrzuca.
Aby rozwiązać ten problem — objcheck, który zmusza mongorestore do sprawdzania poprawności wszystkich żądań od klientów po ich otrzymaniu, aby upewnić się, że klienci nigdy nie wstawiają nieprawidłowych dokumentów do bazy danych. Może mieć niewielki wpływ na wydajność.
Powtórka Oploga
Oplog do kopii zapasowej umożliwi wykonanie spójnej kopii zapasowej i odzyskanie do określonego momentu. Włącz parametr oplogReplay, aby zastosować oplog podczas procesu przywracania. Aby kontrolować, jak daleko należy odtworzyć oplog, możesz zdefiniować znacznik czasu w parametrze oplogLimit. Tylko transakcje do momentu sygnatury czasowej zostaną zastosowane.
Przywracanie pełnego zestawu replik z kopii zapasowej
Przywracanie zestawu replik nie różni się zbytnio od przywracania pojedynczego węzła. Albo musisz najpierw skonfigurować zestaw repliki i przywrócić bezpośrednio do zestawu repliki. Lub najpierw przywróć pojedynczy węzeł, a następnie użyj tego przywróconego węzła do zbudowania zestawu replik.
Najpierw przywróć węzeł, a następnie utwórz zestaw replik
Teraz drugi i trzeci węzeł będą synchronizować swoje dane z pierwszego węzła. Po zakończeniu synchronizacji nasz zestaw replik został przywrócony.
Najpierw utwórz zestaw replik, a następnie przywróć
W przeciwieństwie do poprzedniego procesu, możesz najpierw utworzyć zestaw replik. Najpierw skonfiguruj wszystkie trzy hosty z włączoną opcją repliceSet, uruchom wszystkie trzy demony i zainicjuj zestaw replik na pierwszym węźle:
Teraz, po utworzeniu zestawu replik, możemy bezpośrednio przywrócić do niego naszą kopię zapasową:
Naszym zdaniem odtworzenie repliki w ten sposób jest o wiele bardziej eleganckie. Jest to bliższe temu, w jaki normalnie tworzysz nowy zestaw replik od podstaw, a następnie wypełniasz go danymi (produkcyjnymi).
Wysyłanie nowego węzła w zestawie replik
Podczas skalowania klastra przez dodanie nowego węzła w MongoDB musi nastąpić początkowa synchronizacja zestawu danych. Dzięki replikacji MySQL i Galerze jesteśmy przyzwyczajeni do używania kopii zapasowej do początkowej synchronizacji. Z MongoDB jest to możliwe, ale tylko poprzez wykonanie binarnej kopii katalogu danych. Jeśli nie masz środków na wykonanie migawki systemu plików, będziesz musiał stawić czoła przestojowi na jednym z istniejących węzłów. Proces z przestojami opisano poniżej.
Wysiew z kopią zapasową
Co by się stało, gdyby zamiast tego przywrócił nowy węzeł z kopii zapasowej mongodump, a następnie dołączył do zestawu replik? Przywracanie z kopii zapasowej powinno teoretycznie dać ten sam zestaw danych. Ponieważ ten nowy węzeł został przywrócony z kopii zapasowej, nie będzie w nim miał replikSetId, co MongoDB to zauważy. Ponieważ MongoDB nie widzi tego węzła jako części zestawu replik, polecenie rs.add() zawsze wyzwoli początkową synchronizację MongoDB. Początkowa synchronizacja zawsze spowoduje usunięcie wszelkich istniejących danych w węźle MongoDB.
ReplikaSetId jest generowany podczas inicjowania zestawu repliki i niestety nie można go ustawić ręcznie. Szkoda, ponieważ odzyskanie z kopii zapasowej (w tym ponowne odtworzenie oploga) teoretycznie dałoby nam 100% identyczny zestaw danych. Byłoby miło, gdyby początkowa synchronizacja była opcjonalna w MongoDB, aby spełnić ten przypadek użycia.



