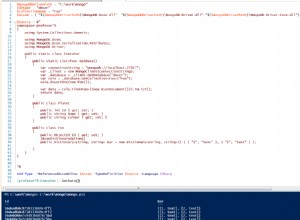
Ta agregacja daje pożądany wynik.
db.posts.aggregate( [
{ $match: { updatedAt: { $gte: 1549786260000 } } },
{ $facet: {
FALSE: [
{ $match: { toggle: false } },
{ $unwind : "$interests" },
{ $group : { _id : { iid: "$interests", pid: "$publisher" }, count: { $sum : 1 } } },
],
TRUE: [
{ $match: { toggle: true, status: "INACTIVE" } },
{ $unwind : "$interests" },
{ $group : { _id : { iid: "$interests", pid: "$publisher" }, count: { $sum : -1 } } },
]
} },
{ $project: { result: { $concatArrays: [ "$FALSE", "$TRUE" ] } } },
{ $unwind: "$result" },
{ $replaceRoot: { newRoot: "$result" } },
{ $group : { _id : "$_id", count: { $sum : "$count" } } },
{ $project:{ _id: 0, iid: "$_id.iid", pid: "$_id.pid", count: 1 } }
] )
[ EDYTUJ DODAJ ]
Wynik zapytania przy użyciu danych wejściowych z postu z pytaniem:
{ "count" : 1, "iid" : "INT123", "pid" : "P789" }
{ "count" : 1, "iid" : "INT123", "pid" : "P123" }
{ "count" : 0, "iid" : "INT789", "pid" : "P789" }
{ "count" : 1, "iid" : "INT456", "pid" : "P789" }
To zapytanie daje ten sam wynik z innym podejściem (kodem):
db.posts.aggregate( [
{
$match: { updatedAt: { $gte: 1549786260000 } }
},
{
$unwind : "$interests"
},
{
$group : {
_id : {
iid: "$interests",
pid: "$publisher"
},
count: {
$sum: {
$switch: {
branches: [
{ case: { $eq: [ "$toggle", false ] },
then: 1 },
{ case: { $and: [ { $eq: [ "$toggle", true] }, { $eq: [ "$status", "INACTIVE" ] } ] },
then: -1 }
]
}
}
}
}
},
{
$project:{
_id: 0,
iid: "$_id.iid",
pid: "$_id.pid",
count: 1
}
}
] )
[ EDYTUJ DODAJ 3 ]
UWAGA:
Kwerenda aspektu uruchamia dwa aspekty (PRAWDA i FAŁSZ) w tym samym zestawie dokumentów; to jest jak dwa zapytania działające równolegle. Istnieje jednak pewna duplikacja kodu, a także dodatkowe etapy kształtowania dokumentów w dół potoku w celu uzyskania pożądanego wyniku.
Drugie zapytanie pozwala uniknąć powielania kodu, a w potoku agregacji występują znacznie mniejsze etapy. Będzie to miało znaczenie, gdy wejściowy zestaw danych zawiera dużą liczbę dokumentów do przetworzenia - pod względem wydajności. Ogólnie rzecz biorąc, mniejsze etapy oznaczają mniejsze iteracje dokumentów (ponieważ etap musi skanować dokumenty, które są wyprowadzane z poprzedniego etapu).