
Co to jest Couchbase
Couchbase Server to rozproszona baza danych dokumentów JSON typu open source. Udostępnia skalowalny magazyn wartości klucza z zarządzaną pamięcią podręczną dla operacji na danych poniżej milisekundy, specjalnie skonstruowane indeksatory do wydajnych zapytań oraz potężny silnik zapytań do wykonywania zapytań podobnych do SQL. W przypadku środowisk mobilnych i Internetu rzeczy Couchbase działa również natywnie na urządzeniu i zarządza synchronizacją z serwerem.
Dlaczego Couchbase?
Couchbase Server to rozproszona baza danych dokumentów JSON typu open source. Udostępnia skalowalny magazyn wartości klucza z zarządzaną pamięcią podręczną dla operacji na danych poniżej milisekundy, specjalnie skonstruowane indeksatory do wydajnych zapytań oraz potężny silnik zapytań do wykonywania zapytań podobnych do SQL. W przypadku środowisk mobilnych i Internetu rzeczy Couchbase działa również natywnie na urządzeniu i zarządza synchronizacją z serwerem.
Couchbase Server specjalizuje się w zapewnianiu zarządzania danymi o niskich opóźnieniach w interaktywnych aplikacjach internetowych, mobilnych i IoT na dużą skalę. Typowe wymagania, które Couchbase Server ma spełnić, obejmują:
- Ujednolicony interfejs programowania
- Zapytanie
- Szukaj
- Urządzenia mobilne i IoT
- Analityka
- Podstawowy silnik bazy danych
- Architektura skalowalna
- Architektura oparta na pamięci
- Integracje Big Data i SQL
- Bezpieczeństwo pełnego stosu
- Wdrożenia kontenerów i chmury
- Wysoka dostępność
Wiele baz danych jest w stanie spełnić jedno lub więcej z tych wymagań, ale wymagają kompromisów podczas pracy produkcyjnej z aplikacjami o znaczeniu krytycznym w skali internetowej. Na przykład jedno rozwiązanie może zapewnić elastyczność modelu danych, ale może brakować możliwości dodawania lub usuwania węzłów bez wpływu na czas pracy lub wydajność. Inne rozwiązanie może wykazać dobrą skalowalność zapisu bez możliwości indeksowania lub zmiany modelu danych w locie. Couchbase Server został zaprojektowany, aby zapewnić produktywne środowisko programistyczne i administracyjne, zapewniając jednocześnie wydajność na dużą skalę, czy to w chmurze, w kontenerze, lokalnie lub na urządzeniu brzegowym.
Wzorzec wydajności Nosql
Nowy test porównawczy porównujący MongoDB, DataStax i Couchbase Server pokazuje, że Couchbase jest najbardziej skalowalną i wydajną bazą danych NoSQL.
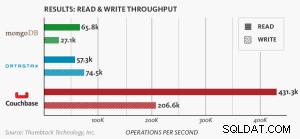
Test oparty na węzłach.
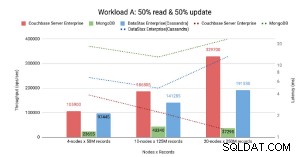
Zgodnie z twierdzeniem CAP Couchbase.
Twierdzenie o ograniczeniu

Couchbase jest na diagramie CP i AP.
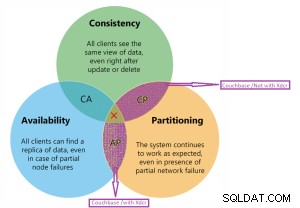
Szczegóły diagramu Couchbase CP i AP.
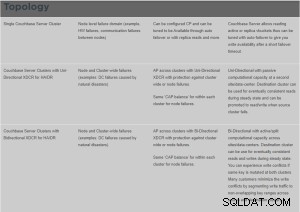
Co to jest XDCR?
Cross Data Center Replication (XDCR) replikuje dane między klastrami:zapewnia to ochronę przed awarią centrum danych, a także zapewnia dostęp do danych o wysokiej wydajności dla globalnie rozproszonych aplikacji o znaczeniu krytycznym.
XDCR replikuje dane z określonego zasobnika w klastrze źródłowym do określonego zasobnika w klastrze docelowym. Dane z zasobnika źródłowego są wypychane do zasobnika docelowego za pomocą agenta XDCR działającego w klastrze źródłowym przy użyciu protokołu zmiany bazy danych. Dowolny zasobnik (Couchbase lub Ephemeral) w dowolnym klastrze można określić jako źródło lub cel dla jednej lub więcej definicji XDCR.
Pełny opis architektury XDCR jest dostępny w usłudze Cross Data Center Replication (XDCR). Przed wykonaniem procedur opisanych w tej sekcji możesz zapoznać się z podanymi tam informacjami.
Podstawowa struktura Xdcr;
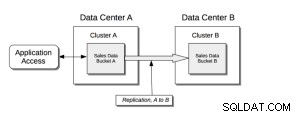
Wymagania wstępne;
- Potwierdź, że klaster ma odpowiedni rozmiar i może obsługiwać nowe strumienie XDCR. Na przykład XDCR potrzebuje 1-2 dodatkowych rdzeni procesora na strumień, a w niektórych przypadkach będzie wymagało również więcej pamięci RAM i zasobów sieciowych. Jeśli klaster nie ma odpowiedniego rozmiaru dla istniejącego obciążenia oraz nowych strumieni XDCR, XDCR może konkurować o zasoby serwera i mieć negatywny wpływ na ogólną wydajność.
- Couchbase Server używa portu TCP/IP 8091 do wymiany informacji o konfiguracji klastra. Jeśli komunikujesz się z klastrem docelowym przez dedykowane połączenie lub Internet, upewnij się, że wszystkie węzły w klastrze docelowym i źródłowym mogą komunikować się ze sobą przez porty 8091 i 8092.
Porty wymienione według ścieżki komunikacji
| XDCR (od klastra do klastra) |
|
Couchbase przechowuje dane zarówno na dysku, jak iw pamięci RAM. Domyślnym zachowaniem jest zapisanie dokumentu na dysku w dowolnym czasie (zwykle szybko) po zapisaniu w pamięci RAM. Pozostawia to krótkie okno, w którym awaria węzła może spowodować utratę danych.
W każdym razie po zapisaniu do pamięci RAM dokument zostanie ostatecznie zapisany na dysku. Couchbase utrzymuje kolejkę zapisu na dysku, którą możesz sprawdzić na stronie raportu metryk w konsoli zarządzania. Teraz CB synchronizuje zapisy w klastrze i uważam, że zapis zostanie zsynchronizowany w całym klastrze, zanim Couchbase potwierdzi, że nastąpiło zapisanie (np. zanim metoda zapisu powróci do wywołującego).
Jeśli masz więcej dokumentów niż dostępna pamięć RAM, tylko te, z których korzystasz najczęściej, będą przechowywane w pamięci RAM w celu szybkiego odzyskania, a wszystkie inne zostaną „wyeksmitowane” na dysk.
Porada;
Gdy rozmiar zasobnika zmniejszono z 200 GB do 10 GB w źródle, replikacja stała się wystarczająco szybsza. Innymi słowy, jeśli rozmiar wiadra jest duży i chociaż wszystkie dane są w pamięci RAM, zauważyłem, że replikacja miała 10 sekund przerwy.
Źródło i cel mają te same ustawienia linuxowe i te same zasoby. To tylko rada.
Wartość rezydentna zasobnika produktu musi wynosić %100. Ponieważ szybkość replikacji jest ważna.
Bucket replication best settings ; XDCR Source Nozzles per Node: 2 --> 8 XDCR Target Nozzles per Node: 2 --> 24 (Nozzles=Channel=parallel , as cpu core) XDCR Checkpoint Interval (sn): 1800 --> 60 Control frequency is low, but not as much as waiting in the queue. The higher this value, the longer it takes for XDCR queues to grow. XDCR Batch Count: 500 --> 2000 It is beneficial to increase by 2.3 times. It also sends so many data groups at the same time. XDCR Batch Size (kB): 2048 --> 8192 It is beneficial to increase by 2.3 times. At the same time, it sends such a large amount of data. XDCR Failure Retry Interval: 10 --> 10 It is used for retry attempts in network errors. XDCR Optimistic Replication Threshold: 256 --> 1024 --> 256 --> 128 Increasing or decreasing this value appropriately can speed up replication, collect data above 1 mb and send it in bulk. But collection can be a waste of time and waiting in the queue. This is the compressed document size in bytes. 0 - 2097152 Bytes (20MB). Default is 256 Bytes. XDCR retrieves metadata for documents larger than this size at once before copying the uncompressed document to a destination set. This option improves XDCR latency. XDCR Statistics Collection Interval (ms): 1000 --> 1000 XDCR Logging Level: info --> info
Porada;
Zalecam, aby źródło i cel miały takie same ustawienia i miały te same zasoby.
Są to ustawienia zasobnika , ustawienia klastra , procesor , pamięć , jakość dysku itp.
Replikacja Xdcr to po prostu replikacja danych. Przed replikacją musisz utworzyć metadane zasobnika.
Jeśli chcesz, możesz utworzyć użytkownika, indeks, widok, zdarzenie itp.
Jako dodatkowe informacje;
Możesz wykonać replikację xdcr w wersji społecznościowej.
Możesz wykonać replikację xdcr w wersji Enterprise. To wymaga dodatkowej licencji. Jeśli nie używasz trybu czuwania jako produktu, nie jest to wysoka opłata.
Inne złącza Couchbase dla XDCR; Elasticsearch, Hadoop, Kafka, Spark, Talend, SQL (ODBC / JDBC)
Zarządzanie couchbase może odbywać się poprzez WEB UI, REST API i CLI. W szczególności internetowy interfejs użytkownika jest bardzo prosty i łatwy w użyciu. Za pomocą interfejsu użytkownika możesz wykonać wiele transakcji operacyjnych i zapytań.
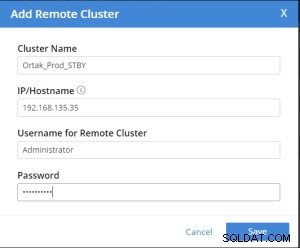
Replication Summary; Stby=Xdcr=Target=Remote same term. A different name xdcr cluster is established with the same features. The buckets with the same name with the same features are created in the xdcr cluster. In Prod, add remote server and xdcr information are entered in the xdcr tab. Prod in xdcr tab with add remote cluster; Cluster Name= Xdcr couchbase name IP/Hostname= Xdcr ip / hostname Username=Xdcr Admin username Password=Xdcr Admin user password Prod in xdcr tab with add bucket replication; Replicate From Bucket = Bucket name in the prod Remote Cluster = Added Xdcr name Remote Bucket = Bucket name added in Xdcr
Ustawienia pamięci dla ustawień klastra Xdcr są podane zgodnie z wartością pamięci serwera.
Powinien być wolny rozmiar pamięci serwera.
Xdcr wymaga dodatkowej pamięci w klastrze prod.
Możliwa jest wielokrotna replikacja wiadra couchbase.
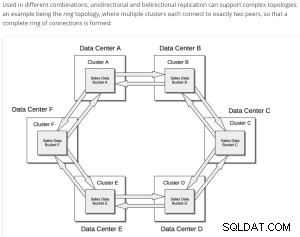
Przykładowa prosta operacja replikacji XDCR;
Karta Xdcr wybrana na stronie głównej couchbase.

Na wybranej karcie xdcr wybrano kartę Dodaj zdalny klaster.

Dodaj zdalne działanie klastra odbywa się w następujący sposób.
Na wybranej karcie xdcr wybrano kartę Dodaj replikację.
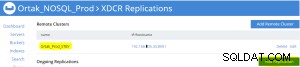
Operacja dodawania replikacji zasobnika jest wykonywana po .
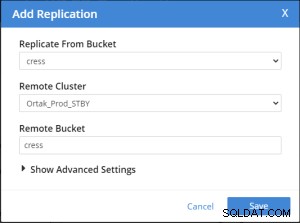
Najlepsze parametry wydajności xdcr . Ale można to ustawić ponownie dla swojego systemu.

Stan replikacji na karcie xdcr źródła (prod)
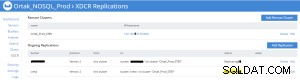
Statystyki replikacji zasobników
Wydajność replikacji docelowa;

Wydajność replikacji w źródle;

Referencje;
1-) https://resources.couchbase.com/nosql_comparison_web/altoros-nosql-performance-benchmark
2-) https://docs.couchbase.com/
3-) https://www.businesswire.com/news/home/20140625005778/en/Couchbase-Blows-Past-Competition-in-NoSQL-Performance-Benchmark
4-) https://www.quora.com/What-is-the-relation-między-SQL-NoSQL-theorem-CAP-and-ACID
Fatih Gençali – Certyfikaty Couchbase





