W naszym poprzednim Hadoop blogi, które badaliśmy, każdy składnik Hadoop Szczegółowy proces MapReduce. W tym miejscu omówimy bardzo interesujący temat, tj. Praca tylko z mapą w Hadoop.
Najpierw omówimy krótkie wprowadzenie Mapy i Zmniejsz w Hadoop Mapreduce, a następnie omówimy, czym jest zadanie Map only w Hadoop MapReduce.
Na koniec w tym samouczku omówimy również zalety i wady zadania Hadoop Tylko mapa.
Co to jest zadanie Tylko mapa Hadoop?
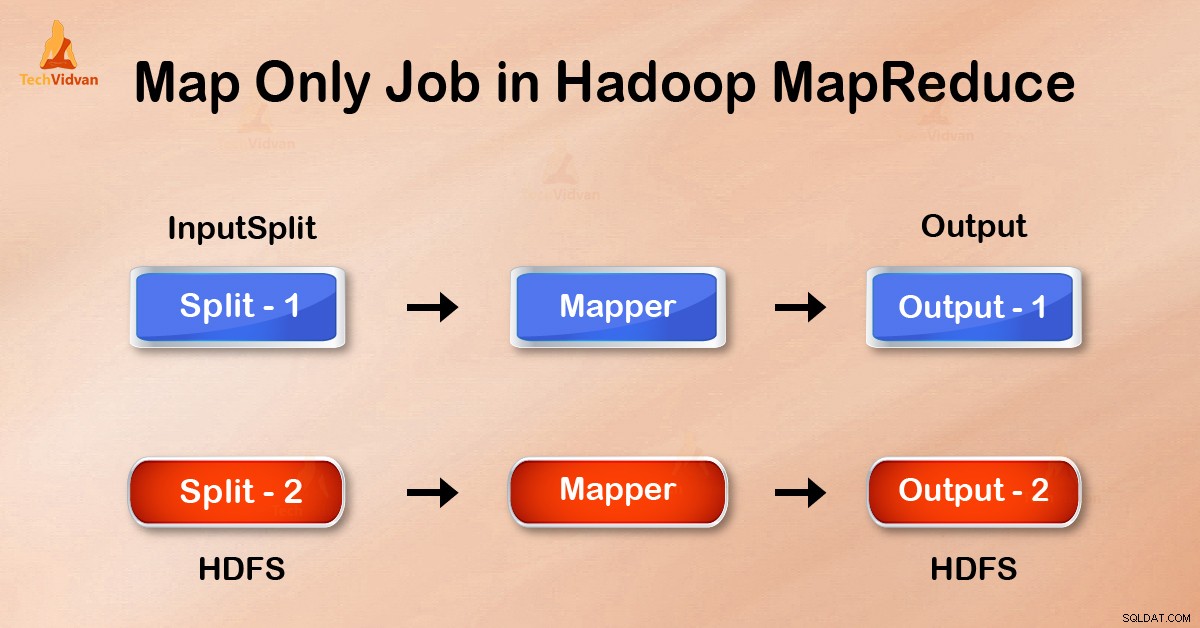
Zadanie tylko z mapą w Hadoop to proces, w którym mapper wykonuje wszystkie zadania. Żadne zadanie nie jest wykonywane przez reduktor . Dane wyjściowe Mappera są ostatecznymi danymi wyjściowymi.
MapReduce to warstwa przetwarzania danych platformy Hadoop. Przetwarza duże ustrukturyzowane i nieustrukturyzowane dane przechowywane w HDFS . MapReduce przetwarza również równolegle ogromne ilości danych.
Dokonuje tego poprzez podzielenie zadania (przesłanej pracy) na zestaw niezależnych zadań (pod-praca). W Hadoop MapReduce działa, dzieląc przetwarzanie na fazy:Mapa i Zmniejsz .
- Mapa: Jest to pierwsza faza przetwarzania, w której określamy cały złożony kod logiczny. Pobiera zestaw danych i konwertuje na inny zestaw danych. Dzieli każdy element na krotki (pary klucz-wartość ).
- Zmniejsz: To druga faza przetwarzania. Tutaj określamy lekkie przetwarzanie, takie jak agregacja/sumowanie. Pobiera dane wyjściowe z mapy jako dane wejściowe. Następnie łączy te krotki na podstawie klucza.
Z tego przykładu liczenia słów możemy powiedzieć, że istnieją dwa zestawy procesów równoległych, mapować i zmniejszać. W procesie tworzenia mapy pierwsze dane wejściowe są dzielone, aby rozdzielić pracę między wszystkie węzły mapy, jak pokazano powyżej.
Następnie framework identyfikuje każde słowo i odwzorowuje liczbę 1. W ten sposób tworzy pary zwane krotkami (klucz-wartość).
W pierwszym węźle mapowania mija trzy słowa:lew, tygrys i rzeka. W ten sposób generuje 3 pary klucz-wartość jako dane wyjściowe węzła. Trzy różne klucze i wartość ustawione na 1 oraz ten sam proces powtarzają się dla wszystkich węzłów.
Następnie przekazuje te krotki do węzłów redukcyjnych. Program partycjonujący wykonuje tasowanie aby wszystkie krotki z tym samym kluczem trafiały do tego samego węzła.
W procesie redukcji zasadniczo dzieje się agregacja wartości, a raczej operacja na wartościach, które mają ten sam klucz.
Rozważmy teraz scenariusz, w którym wystarczy wykonać operację. Nie potrzebujemy agregacji, w takim przypadku wolimy „Praca tylko dla mapy „.
W zadaniu Tylko mapa mapa wykonuje wszystkie zadania za pomocą swojego InputSplit . Reduktor nie działa. Dane wyjściowe maperów to ostateczne dane wyjściowe.
Jak uniknąć redukcji fazy w MapReduce?
Ustawiając job.setNumreduceTasks(0) w konfiguracji w sterowniku możemy uniknąć redukcji fazy. Spowoduje to, że liczba reduktorów będzie wynosić 0 . W ten sposób jedyny maper wykona całe zadanie.
Zalety pracy tylko z mapą w Hadoop
W MapReduce wykonanie zadania pomiędzy mapami i fazami redukcji jest faza klucza, sortowania i tasowania. Tasowanie – sortowanie odpowiadają za sortowanie kluczy w kolejności rosnącej. Następnie grupujemy wartości na podstawie tych samych kluczy. Ta faza jest bardzo kosztowna.
Jeżeli faza redukcji nie jest wymagana, należy jej unikać. Ponieważ unikanie fazy redukcji wyeliminowałoby również sortowanie i fazę tasowania. W związku z tym zmniejszy to również przeciążenie sieci.
Powodem jest to, że podczas tasowania dane wyjściowe mapowania przemieszczają się w celu zmniejszenia. A gdy rozmiar danych jest ogromny, duże dane muszą dotrzeć do reduktora.
Dane wyjściowe programu mapującego są zapisywane na dysku lokalnym przed wysłaniem do zmniejszenia. Jednak w zadaniu zawierającym tylko mapę dane wyjściowe są bezpośrednio zapisywane w systemie HDFS. To dodatkowo oszczędza czas i obniża koszty.
Wniosek
W związku z tym widzieliśmy, że zadanie tylko z mapą zmniejsza przeciążenie sieci, unikając tasowania, sortowania i zmniejszania fazy. Sama mapa zajmuje się ogólnym przetwarzaniem i tworzeniem danych wyjściowych. ZA pomocą job.setNumreduceTasks(0) jest to osiągane.
Mam nadzieję, że zrozumiałeś zadanie Tylko mapa Hadoop i jego znaczenie, ponieważ omówiliśmy wszystko na temat zadania Tylko mapa w Hadoop. Ale jeśli masz jakieś pytanie, możesz podzielić się z nami w sekcji komentarzy.



