Kiedy pracujesz nad projektem, który składa się z wielu mikrousług, prawdopodobnie będzie również zawierał wiele baz danych.
Na przykład możesz mieć bazę danych MySQL i bazę danych PostgreSQL, które działają na osobnych serwerach.
Zwykle, aby połączyć dane z dwóch baz danych, należałoby wprowadzić nową mikrousługę, która łączyłaby dane razem. Ale to zwiększyłoby złożoność systemu.
W tym samouczku użyjemy Materialize, aby połączyć MySQL i Postgres w zmaterializowanym widoku na żywo. Dzięki temu będziemy mogli wysyłać zapytania bezpośrednio i uzyskiwać wyniki z obu baz danych w czasie rzeczywistym przy użyciu standardowego SQL.
Materialise to dostępna w źródle strumieniowa baza danych napisana w języku Rust, która przechowuje w pamięci wyniki zapytania SQL (widok zmaterializowany) w miarę zmian danych.
Samouczek zawiera projekt demonstracyjny, który możesz rozpocząć za pomocą docker-compose .
Projekt demonstracyjny, z którego będziemy korzystać, będzie monitorował zamówienia na naszej próbnej stronie internetowej. Wygeneruje zdarzenia, które później mogą zostać wykorzystane do wysyłania powiadomień, gdy koszyk został porzucony przez długi czas.
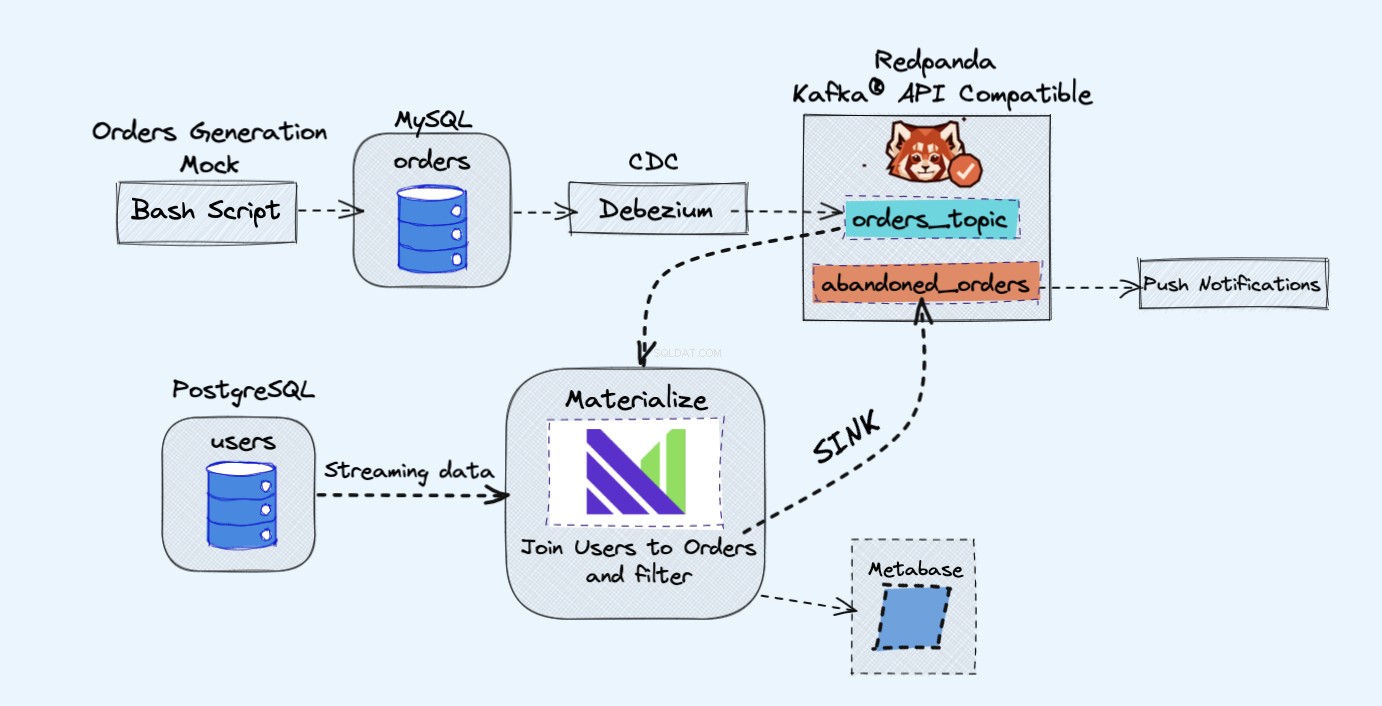
Architektura projektu demonstracyjnego jest następująca:
Wymagania wstępne
Wszystkie usługi, z których będziemy korzystać w demie, będą działały w kontenerach Dockera, dzięki czemu nie będziesz musiał instalować żadnych dodatkowych usług na swoim laptopie lub serwerze zamiast Docker i Docker Compose.
Jeśli nie masz jeszcze zainstalowanych programów Docker i Docker Compose, możesz postępować zgodnie z oficjalnymi instrukcjami, jak to zrobić tutaj:
- Zainstaluj Docker
- Zainstaluj Docker Compose
Przegląd
Jak pokazano na powyższym schemacie, będziemy mieć następujące komponenty:
- Pozorna usługa do ciągłego generowania zamówień.
- Zamówienia będą przechowywane w bazie danych MySQL .
- Gdy nastąpi zapis bazy danych, Debezium przesyła zmiany z MySQL do Redpandy temat.
- Będziemy również mieć Postgres baza danych, w której możemy uzyskać naszych użytkowników.
- Następnie przetworzymy ten temat Redpanda w Materialize bezpośrednio wraz z użytkownikami z bazy danych Postgres.
- W Materialize połączymy nasze zamówienia i użytkowników, wykonamy filtrowanie i utworzymy zmaterializowany widok, który pokazuje informacje o porzuconym koszyku.
- Następnie utworzymy zlew, aby wysłać dane porzuconego koszyka do nowego tematu Redpanda.
- Na koniec użyjemy Metabazy do wizualizacji danych.
- Możesz później wykorzystać informacje z tego nowego tematu do wysyłania powiadomień do użytkowników i przypominania im, że mają porzucony koszyk.
Na marginesie, byłoby dobrze, gdyby używał Kafki zamiast Redpanda. Po prostu podoba mi się prostota, jaką Redpanda wnosi do stołu, ponieważ możesz uruchomić pojedynczą instancję Redpanda zamiast wszystkich komponentów Kafki.
Jak uruchomić demo
Najpierw zacznij od sklonowania repozytorium:
git clone https://github.com/bobbyiliev/materialize-tutorials.git
Następnie możesz uzyskać dostęp do katalogu:
cd materialize-tutorials/mz-join-mysql-and-postgresql
Zacznijmy od uruchomienia kontenera Redpanda:
docker-compose up -d redpanda
Zbuduj obrazy:
docker-compose build
Na koniec uruchom wszystkie usługi:
docker-compose up -d
Aby uruchomić Materialize CLI, możesz uruchomić następujące polecenie:
docker-compose run mzcli
To tylko skrót do kontenera Dockera z postgres-client wstępnie zainstalowany. Jeśli masz już psql możesz uruchomić psql -U materialize -h localhost -p 6875 materialize zamiast tego.
Jak utworzyć zmaterializować źródło Kafki
Teraz, gdy jesteś w Materialize CLI, zdefiniujmy orders tabele w mysql.shop baza danych jako źródła Redpanda:
CREATE SOURCE orders
FROM KAFKA BROKER 'redpanda:9092' TOPIC 'mysql.shop.orders'
FORMAT AVRO USING CONFLUENT SCHEMA REGISTRY 'https://redpanda:8081'
ENVELOPE DEBEZIUM;
Gdybyś miał sprawdzić dostępne kolumny z orders źródło, uruchamiając następującą instrukcję:
SHOW COLUMNS FROM orders;
Byłbyś w stanie zobaczyć, że ponieważ Materialize pobiera dane schematu wiadomości z rejestru Redpanda, zna typy kolumn, których należy użyć dla każdego atrybutu:
name | nullable | type
--------------+----------+-----------
id | f | bigint
user_id | t | bigint
order_status | t | integer
price | t | numeric
created_at | f | text
updated_at | t | timestamp
Jak tworzyć zmaterializowane widoki
Następnie utworzymy nasz pierwszy widok zmaterializowany, aby pobrać wszystkie dane z orders Źródło Redpanda:
CREATE MATERIALIZED VIEW orders_view AS
SELECT * FROM orders;
CREATE MATERIALIZED VIEW abandoned_orders AS
SELECT
user_id,
order_status,
SUM(price) as revenue,
COUNT(id) AS total
FROM orders_view
WHERE order_status=0
GROUP BY 1,2;
Możesz teraz użyć SELECT * FROM abandoned_orders; aby zobaczyć wyniki:
SELECT * FROM abandoned_orders;
Aby uzyskać więcej informacji na temat tworzenia widoków zmaterializowanych, zapoznaj się z sekcją Widoki zmaterializowane w dokumentacji Materializacji.
Jak utworzyć źródło Postgresa
Istnieją dwa sposoby tworzenia źródła Postgres w Materialize:
- Korzystając z Debezium, tak jak robiliśmy to ze źródłem MySQL.
- Korzystanie ze źródła Materialize Postgres, które umożliwia bezpośrednie połączenie Materialise z Postgresem, dzięki czemu nie musisz używać Debezium.
W tym demo użyjemy źródła Postgres Materialise tylko jako demonstracji, jak z niego korzystać, ale zamiast tego możesz użyć Debezium.
Aby utworzyć źródło Postgres Materialise, uruchom następującą instrukcję:
CREATE MATERIALIZED SOURCE "mz_source" FROM POSTGRES
CONNECTION 'user=postgres port=5432 host=postgres dbname=postgres password=postgres'
PUBLICATION 'mz_source';
Krótkie podsumowanie powyższego stwierdzenia:
MATERIALIZED:Materializuje dane źródła PostgreSQL. Wszystkie dane są przechowywane w pamięci i umożliwiają bezpośredni wybór źródeł.mz_source:Nazwa źródła PostgreSQL.CONNECTION:Parametry połączenia PostgreSQL.PUBLICATION:Publikacja PostgreSQL zawierająca tabele, które mają być przesyłane strumieniowo do Materialize.
Po utworzeniu źródła PostgreSQL, aby móc odpytywać tabele PostgreSQL, musielibyśmy utworzyć widoki, które reprezentują oryginalne tabele publikacji nadrzędnej.
W naszym przypadku mamy tylko jedną tabelę o nazwie users więc stwierdzenie, które musielibyśmy uruchomić to:
CREATE VIEWS FROM SOURCE mz_source (users);
Aby zobaczyć dostępne widoki, wykonaj następującą instrukcję:
SHOW FULL VIEWS;
Gdy to zrobisz, możesz bezpośrednio zapytać o nowe widoki:
SELECT * FROM users;
Następnie przejdźmy dalej i utwórzmy jeszcze kilka widoków.
Jak utworzyć zlew Kafka
Zlewy umożliwiają wysyłanie danych z Materialise do zewnętrznego źródła.
W tym demo użyjemy Redpanda.
Redpanda jest kompatybilna z interfejsem API Kafki, a Materialize może przetwarzać z niej dane tak samo, jak przetwarza dane ze źródła Kafki.
Stwórzmy zmaterializowany widok, który będzie zawierał wszystkie nieopłacone zamówienia o dużej liczbie:
CREATE MATERIALIZED VIEW high_value_orders AS
SELECT
users.id,
users.email,
abandoned_orders.revenue,
abandoned_orders.total
FROM users
JOIN abandoned_orders ON abandoned_orders.user_id = users.id
GROUP BY 1,2,3,4
HAVING revenue > 2000;
Jak widać, tutaj faktycznie dołączamy do users widok, który pozyskuje dane bezpośrednio z naszego źródła Postgres, oraz abandond_orders widok, który jednocześnie pobiera dane z tematu Redpanda.
Stwórzmy Sink, do którego wyślemy dane powyższego zmaterializowanego widoku:
CREATE SINK high_value_orders_sink
FROM high_value_orders
INTO KAFKA BROKER 'redpanda:9092' TOPIC 'high-value-orders-sink'
FORMAT AVRO USING
CONFLUENT SCHEMA REGISTRY 'https://redpanda:8081';
Teraz, gdybyś miał połączyć się z kontenerem Redpanda i użyć rpk topic consume polecenie, będziesz mógł odczytać rekordy z tematu.
Jednak na razie nie będziemy mogli wyświetlić podglądu wyników za pomocą rpk ponieważ jest sformatowany w AVRO. Redpanda najprawdopodobniej zaimplementuje to w przyszłości, ale w tej chwili możemy przesłać temat z powrotem do Materialize, aby potwierdzić format.
Najpierw zdobądź nazwę tematu, który został automatycznie wygenerowany:
SELECT topic FROM mz_kafka_sinks;
Wyjście:
topic
-----------------------------------------------------------------
high-volume-orders-sink-u12-1637586945-13670686352905873426
Aby uzyskać więcej informacji na temat generowania nazw tematów, zapoznaj się z dokumentacją tutaj.
Następnie utwórz nowe zmaterializowane źródło z tego tematu Redpanda:
CREATE MATERIALIZED SOURCE high_volume_orders_test
FROM KAFKA BROKER 'redpanda:9092' TOPIC ' high-volume-orders-sink-u12-1637586945-13670686352905873426'
FORMAT AVRO USING CONFLUENT SCHEMA REGISTRY 'https://redpanda:8081';
Pamiętaj, aby odpowiednio zmienić nazwę tematu!
Na koniec prześlij zapytanie do nowego zmaterializowanego widoku:
SELECT * FROM high_volume_orders_test LIMIT 2;
Teraz, gdy masz dane w temacie, możesz połączyć się z innymi usługami i wykorzystać je, a następnie na przykład wywołać e-maile lub alerty.
Jak podłączyć metabazę
Aby uzyskać dostęp do instancji Metabase, odwiedź https://localhost:3030 jeśli uruchamiasz demo lokalnie lub https://your_server_ip:3030 jeśli uruchamiasz demo na serwerze. Następnie postępuj zgodnie z instrukcjami, aby zakończyć konfigurację metabazy.
Upewnij się, że jako źródło danych wybrałeś Materializuj.
Gdy będziesz gotowy, będziesz mógł wizualizować swoje dane tak samo, jak w przypadku standardowej bazy danych PostgreSQL.
Jak zatrzymać demo
Aby zatrzymać wszystkie usługi, uruchom następujące polecenie:
docker-compose down
Wniosek
Jak widać, jest to bardzo prosty przykład korzystania z Materialize. Możesz użyć Materialize, aby pozyskiwać dane z różnych źródeł, a następnie przesyłać je strumieniowo do różnych miejsc docelowych.
Przydatne zasoby:
CREATE SOURCE: PostgreSQLCREATE SOURCECREATE VIEWSSELECT