Python i SQL to dwa najważniejsze języki dla analityków danych.
W tym artykule przeprowadzę Cię przez wszystko, co musisz wiedzieć, aby połączyć Python i SQL.
Dowiesz się, jak pobierać dane z relacyjnych baz danych bezpośrednio do potoków uczenia maszynowego, przechowywać dane z aplikacji Pythona we własnej bazie danych lub w jakimkolwiek innym przypadku użycia, jaki możesz wymyślić.
Wspólnie omówimy:
- Po co uczyć się używania Pythona i SQL razem?
- Jak skonfigurować środowisko Pythona i serwer MySQL
- Łączenie z serwerem MySQL w Pythonie
- Tworzenie nowej bazy danych
- Tworzenie tabel i relacji między tabelami
- Wypełnianie tabel danymi
- Odczyt danych
- Aktualizowanie rekordów
- Usuwanie rekordów
- Tworzenie rekordów z list Pythona
- Tworzenie funkcji wielokrotnego użytku, aby robić to wszystko za nas w przyszłości
To dużo bardzo przydatnych i bardzo fajnych rzeczy. Przejdźmy do tego!
Krótka uwaga, zanim zaczniemy:w tym repozytorium GitHub jest dostępny Notatnik Jupyter zawierający cały kod użyty w tym samouczku. Kodowanie razem jest wysoce zalecane!
Użyta tutaj baza danych i kod SQL pochodzą z mojej poprzedniej serii Wprowadzenie do SQL opublikowanej na Towards Data Science (skontaktuj się ze mną, jeśli masz problemy z przeglądaniem artykułów, a mogę wysłać Ci link, aby zobaczyć je za darmo).
Jeśli nie jesteś zaznajomiony z SQL i koncepcjami relacyjnych baz danych, wskażę Ci tę serię (dodatkowo na freeCodeCamp jest oczywiście ogromna ilość świetnych rzeczy dostępnych!)
Dlaczego Python z SQL?
Dla analityków danych i naukowców zajmujących się danymi Python ma wiele zalet. Ogromna gama bibliotek typu open source sprawia, że jest to niezwykle przydatne narzędzie dla każdego analityka danych.
Mamy pandy, NumPy i Vaex do analizy danych, Matplotlib, seaborn i Bokeh do wizualizacji oraz TensorFlow, scikit-learn i PyTorch do zastosowań uczenia maszynowego (oraz wiele, wiele innych).
Dzięki (stosunkowo) łatwej krzywej uczenia się i wszechstronności nic dziwnego, że Python jest jednym z najszybciej rozwijających się języków programowania.
Jeśli więc używamy Pythona do analizy danych, warto zapytać – skąd te wszystkie dane pochodzą?
Chociaż istnieje ogromna różnorodność źródeł zbiorów danych, w wielu przypadkach – szczególnie w przedsiębiorstwach – dane będą przechowywane w relacyjnej bazie danych. Relacyjne bazy danych to niezwykle wydajny, wydajny i szeroko stosowany sposób tworzenia, odczytywania, aktualizowania i usuwania wszelkiego rodzaju danych.
Najczęściej używane systemy zarządzania relacyjnymi bazami danych (RDBMS) — Oracle, MySQL, Microsoft SQL Server, PostgreSQL, IBM DB2 — używają języka Structured Query Language (SQL) do uzyskiwania dostępu do danych i wprowadzania w nich zmian.
Zauważ, że każdy RDBMS używa nieco innego smaku SQL, więc kod SQL napisany dla jednego zwykle nie będzie działał w innym bez (zwykle dość drobnych) modyfikacji. Ale koncepcje, struktury i operacje są w dużej mierze identyczne.
Oznacza to, że dla pracującego analityka danych niezmiernie ważne jest dobre zrozumienie języka SQL. Umiejętność korzystania z Pythona i SQL razem daje jeszcze większe korzyści, jeśli chodzi o pracę z danymi.
Pozostała część tego artykułu zostanie poświęcona pokazaniu dokładnie, jak możemy to zrobić.
Pierwsze kroki
Wymagania i instalacja
Aby kodować wraz z tym samouczkiem, będziesz potrzebować własnego skonfigurowanego środowiska Python.
Używam Anacondy, ale jest na to wiele sposobów. Po prostu wygoogluj „jak zainstalować Pythona”, jeśli potrzebujesz dalszej pomocy. Możesz także użyć Bindera do kodowania wraz z powiązanym notatnikiem Jupyter.
Będziemy używać MySQL Community Server, ponieważ jest on darmowy i szeroko stosowany w branży. Jeśli korzystasz z systemu Windows, ten przewodnik pomoże Ci skonfigurować. Oto przewodniki dla użytkowników komputerów Mac i Linux (chociaż mogą się różnić w zależności od dystrybucji Linuksa).
Po ich skonfigurowaniu będziemy musieli skłonić je do komunikowania się ze sobą.
W tym celu musimy zainstalować bibliotekę MySQL Connector Python. Aby to zrobić, postępuj zgodnie z instrukcjami lub po prostu użyj pip:
pip install mysql-connector-pythonBędziemy również używać pand, więc upewnij się, że masz je również zainstalowane.
pip install pandasImportowanie bibliotek
Jak w przypadku każdego projektu w Pythonie, pierwszą rzeczą, którą chcemy zrobić, jest zaimportowanie naszych bibliotek.
Najlepszą praktyką jest zaimportowanie wszystkich bibliotek, z których będziemy korzystać na początku projektu, aby osoby czytające lub przeglądające nasz kod wiedziały z grubsza, co nadchodzi, więc nie ma niespodzianek.
W tym samouczku użyjemy tylko dwóch bibliotek - MySQL Connector i pand.
import mysql.connector
from mysql.connector import Error
import pandas as pdFunkcję Error importujemy osobno, dzięki czemu mamy do niej łatwy dostęp dla naszych funkcji.
Łączenie z serwerem MySQL
W tym momencie powinniśmy mieć już zainstalowany MySQL Community Server w naszym systemie. Teraz musimy napisać kod w Pythonie, który pozwoli nam nawiązać połączenie z tym serwerem.
def create_server_connection(host_name, user_name, user_password):
connection = None
try:
connection = mysql.connector.connect(
host=host_name,
user=user_name,
passwd=user_password
)
print("MySQL Database connection successful")
except Error as err:
print(f"Error: '{err}'")
return connectionTworzenie funkcji wielokrotnego użytku dla kodu takiego jak ten jest najlepszą praktyką, abyśmy mogli używać jej wielokrotnie przy minimalnym wysiłku. Gdy to zostanie napisane, możesz użyć go ponownie we wszystkich swoich projektach w przyszłości, więc w przyszłości będziesz wdzięczny!
Przejdźmy przez ten wiersz po wierszu, abyśmy zrozumieli, co się tutaj dzieje:
Pierwsza linia to nazwanie funkcji (create_server_connection) i argumentów, które ta funkcja przyjmie (nazwa_hosta, nazwa_użytkownika i hasło_użytkownika).
Następna linia zamyka wszystkie istniejące połączenia, aby serwer nie został pomylony z wieloma otwartymi połączeniami.
Następnie używamy bloku try-except w Pythonie, aby obsłużyć wszelkie potencjalne błędy. Pierwsza część próbuje utworzyć połączenie z serwerem za pomocą metody mysql.connector.connect() przy użyciu szczegółów określonych przez użytkownika w argumentach. Jeśli to zadziała, funkcja wypisze szczęśliwy komunikat o powodzeniu.
Część wyjątku bloku wyświetla błąd, który zwraca MySQL Server, w niefortunnym przypadku wystąpienia błędu.
Wreszcie, jeśli połączenie się powiedzie, funkcja zwraca obiekt połączenia.
Wykorzystujemy to w praktyce, przypisując wyjście funkcji do zmiennej, która następnie staje się naszym obiektem połączenia. Następnie możemy zastosować do niego inne metody (takie jak kursor) i stworzyć inne przydatne obiekty.
connection = create_server_connection("localhost", "root", pw)Powinno to dać komunikat o sukcesie:

Tworzenie nowej bazy danych
Teraz, gdy nawiązaliśmy połączenie, następnym krokiem jest utworzenie nowej bazy danych na naszym serwerze.
W tym samouczku zrobimy to tylko raz, ale ponownie napiszemy to jako funkcję wielokrotnego użytku, więc mamy przyjemną przydatną funkcję, którą możemy ponownie wykorzystać w przyszłych projektach.
def create_database(connection, query):
cursor = connection.cursor()
try:
cursor.execute(query)
print("Database created successfully")
except Error as err:
print(f"Error: '{err}'")Ta funkcja przyjmuje dwa argumenty, połączenie (nasz obiekt połączenia) i zapytanie (zapytanie SQL, które napiszemy w następnym kroku). Wykonuje zapytanie na serwerze za pośrednictwem połączenia.
Używamy metody kursora na naszym obiekcie połączenia, aby utworzyć obiekt kursora (MySQL Connector używa paradygmatu programowania obiektowego, więc istnieje wiele obiektów dziedziczących właściwości z obiektów nadrzędnych).
Ten obiekt kursora ma metody, takie jak execute, executemany (których użyjemy w tym samouczku) wraz z kilkoma innymi przydatnymi metodami.
Jeśli to pomoże, możemy myśleć o obiekcie kursora jako zapewniającym nam dostęp do migającego kursora w oknie terminala MySQL Server.
Następnie definiujemy zapytanie do utworzenia bazy danych i wywołujemy funkcję:

Wszystkie zapytania SQL użyte w tym samouczku są wyjaśnione w mojej serii samouczków Wprowadzenie do SQL, a pełny kod można znaleźć w powiązanym Notatniku Jupyter w tym repozytorium GitHub, więc nie będę wyjaśniał, co robi kod SQL w tym samouczek.
Jest to jednak prawdopodobnie najprostsze możliwe zapytanie SQL. Jeśli umiesz czytać po angielsku, prawdopodobnie zrozumiesz, co on robi!
Uruchomienie funkcji create_database z argumentami jak powyżej spowoduje utworzenie na naszym serwerze bazy danych o nazwie „school”.
Dlaczego nasza baza danych nazywa się „szkoła”? Być może teraz byłby dobry moment, aby dokładniej przyjrzeć się temu, co zamierzamy zaimplementować w tym samouczku.
Nasza baza danych
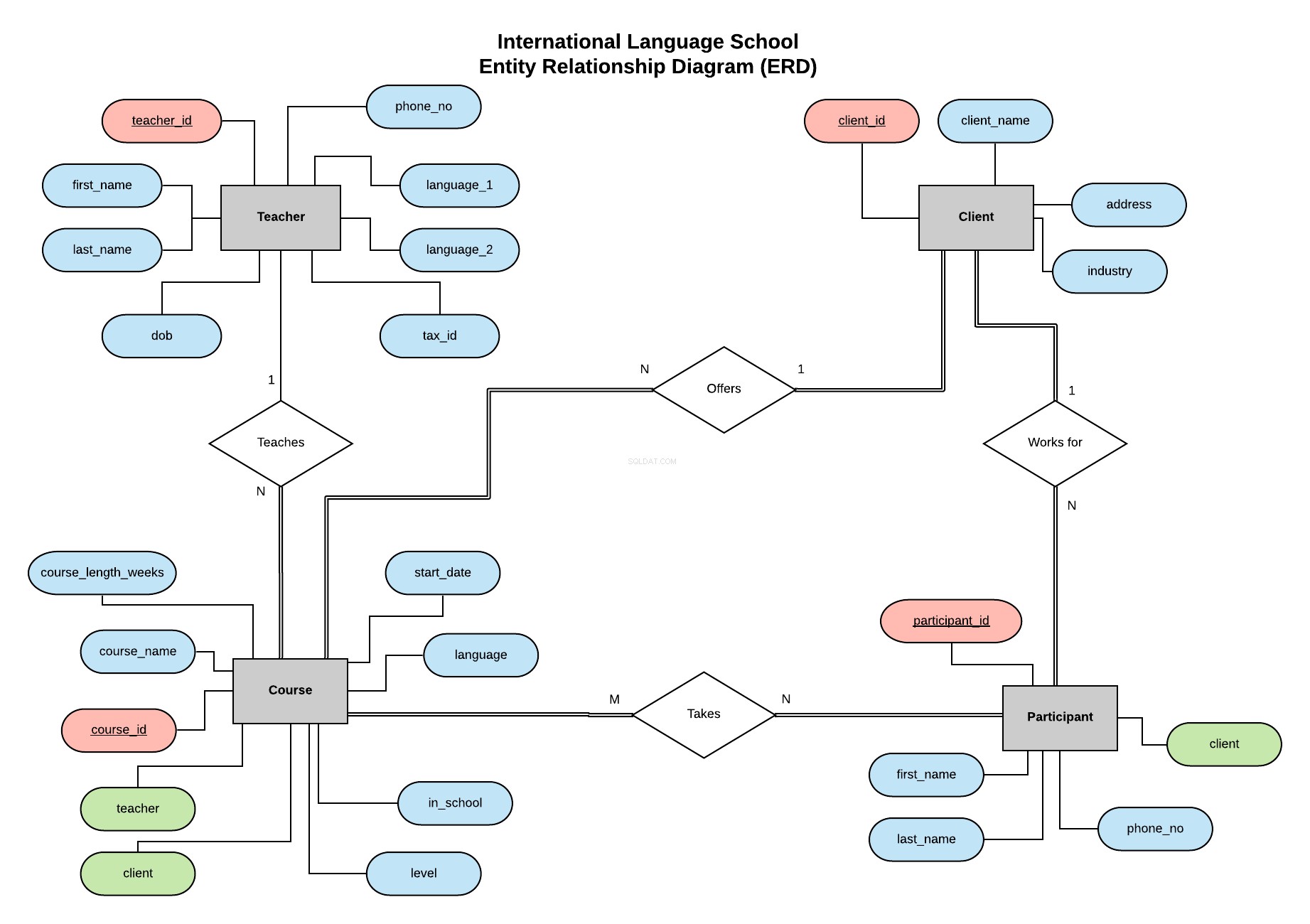
Idąc za przykładem z mojej poprzedniej serii, będziemy wdrażać bazę danych dla Międzynarodowej Szkoły Językowej - fikcyjnej szkoły językowej, która zapewnia profesjonalne lekcje językowe klientom korporacyjnym.
Ten diagram relacji z podmiotami (ERD) przedstawia nasze jednostki (nauczyciel, klient, kurs i uczestnik) i definiuje relacje między nimi.
Wszystkie informacje na temat tego, czym jest ERD i co należy wziąć pod uwagę przy jego tworzeniu i projektowaniu bazy danych, można znaleźć w tym artykule.
Surowy kod SQL, wymagania dotyczące bazy danych i dane, które mają trafić do bazy danych, są zawarte w tym repozytorium GitHub, ale zobaczysz to wszystko, gdy będziemy również przechodzić przez ten samouczek.
Łączenie z bazą danych
Teraz, gdy stworzyliśmy bazę danych w MySQL Server, możemy zmodyfikować naszą funkcję create_server_connection, aby połączyć się bezpośrednio z tą bazą danych.
Zwróć uwagę, że możliwe jest - w rzeczywistości powszechne - posiadanie wielu baz danych na jednym serwerze MySQL, więc chcemy zawsze i automatycznie łączyć się z bazą danych, która nas interesuje.
Możemy to zrobić w ten sposób:
def create_db_connection(host_name, user_name, user_password, db_name):
connection = None
try:
connection = mysql.connector.connect(
host=host_name,
user=user_name,
passwd=user_password,
database=db_name
)
print("MySQL Database connection successful")
except Error as err:
print(f"Error: '{err}'")
return connectionTo jest dokładnie ta sama funkcja, ale teraz bierzemy jeszcze jeden argument — nazwę bazy danych — i przekazujemy go jako argument do metody connect().
Tworzenie funkcji wykonywania zapytania
Ostatnia funkcja, którą zamierzamy stworzyć (na razie) jest niezwykle istotna - funkcja wykonywania zapytań. Spowoduje to pobranie naszych zapytań SQL, przechowywanych w Pythonie jako ciągi znaków, i przekazanie ich do metody cursor.execute() w celu wykonania ich na serwerze.
def execute_query(connection, query):
cursor = connection.cursor()
try:
cursor.execute(query)
connection.commit()
print("Query successful")
except Error as err:
print(f"Error: '{err}'")Ta funkcja jest dokładnie taka sama, jak nasza wcześniejsza funkcja create_database, z wyjątkiem tego, że używa metody connection.commit(), aby upewnić się, że polecenia wyszczególnione w naszych zapytaniach SQL są zaimplementowane.
To będzie nasza funkcja konia roboczego, której użyjemy (obok create_db_connection) do tworzenia tabel, ustanawiania relacji między tymi tabelami, wypełniania tabel danymi oraz aktualizowania i usuwania rekordów w naszej bazie danych.
Jeśli jesteś ekspertem od SQL, ta funkcja pozwoli Ci wykonać dowolne złożone polecenia i zapytania, które możesz mieć w pobliżu, bezpośrednio ze skryptu Pythona. Może to być bardzo potężne narzędzie do zarządzania danymi.
Tworzenie tabel
Teraz wszyscy jesteśmy gotowi do uruchomienia poleceń SQL na naszym serwerze i rozpoczęcia budowania naszej bazy danych. Pierwszą rzeczą, którą chcemy zrobić, to stworzyć niezbędne tabele.
Zacznijmy od naszego stołu Nauczyciel:
create_teacher_table = """
CREATE TABLE teacher (
teacher_id INT PRIMARY KEY,
first_name VARCHAR(40) NOT NULL,
last_name VARCHAR(40) NOT NULL,
language_1 VARCHAR(3) NOT NULL,
language_2 VARCHAR(3),
dob DATE,
tax_id INT UNIQUE,
phone_no VARCHAR(20)
);
"""
connection = create_db_connection("localhost", "root", pw, db) # Connect to the Database
execute_query(connection, create_teacher_table) # Execute our defined queryPrzede wszystkim przypisujemy nasze polecenie SQL (szczegółowo wyjaśnione tutaj) do zmiennej o odpowiedniej nazwie.
W tym przypadku używamy notacji potrójnego cudzysłowu Pythona dla wielowierszowych łańcuchów do przechowywania naszego zapytania SQL, a następnie wprowadzamy je do naszej funkcji execute_query, aby ją zaimplementować.
Zwróć uwagę, że to wieloliniowe formatowanie jest wyłącznie z korzyścią dla ludzi czytających nasz kod. Ani SQL, ani Python "nie przejmują się", jeśli polecenie SQL jest rozłożone w ten sposób. Dopóki składnia jest poprawna, oba języki ją zaakceptują.
Jednak z korzyścią dla ludzi, którzy będą czytać Twój kod (nawet jeśli będzie to tylko przyszłość Ty!) jest to bardzo przydatne, aby uczynić kod bardziej czytelnym i zrozumiałym.
To samo dotyczy pisania wielkimi literami operatorów w SQL. Jest to powszechnie stosowana konwencja, która jest zdecydowanie zalecana, ale rzeczywiste oprogramowanie, które uruchamia kod, nie rozróżnia wielkości liter i traktuje polecenia „CREATE TABLE teacher” i „create table teacher” jako identyczne polecenia.

Uruchomienie tego kodu daje nam wiadomości o sukcesie. Możemy to również zweryfikować w kliencie wiersza poleceń MySQL Server:
Świetny! Teraz utwórzmy pozostałe tabele.
create_client_table = """
CREATE TABLE client (
client_id INT PRIMARY KEY,
client_name VARCHAR(40) NOT NULL,
address VARCHAR(60) NOT NULL,
industry VARCHAR(20)
);
"""
create_participant_table = """
CREATE TABLE participant (
participant_id INT PRIMARY KEY,
first_name VARCHAR(40) NOT NULL,
last_name VARCHAR(40) NOT NULL,
phone_no VARCHAR(20),
client INT
);
"""
create_course_table = """
CREATE TABLE course (
course_id INT PRIMARY KEY,
course_name VARCHAR(40) NOT NULL,
language VARCHAR(3) NOT NULL,
level VARCHAR(2),
course_length_weeks INT,
start_date DATE,
in_school BOOLEAN,
teacher INT,
client INT
);
"""
connection = create_db_connection("localhost", "root", pw, db)
execute_query(connection, create_client_table)
execute_query(connection, create_participant_table)
execute_query(connection, create_course_table)Tworzy to cztery tabele niezbędne dla naszych czterech podmiotów.
Teraz chcemy zdefiniować relacje między nimi i utworzyć jeszcze jedną tabelę, aby obsłużyć relację wiele-do-wielu między uczestnikiem a tabelami kursu (więcej szczegółów znajdziesz tutaj).
Robimy to dokładnie w ten sam sposób:
alter_participant = """
ALTER TABLE participant
ADD FOREIGN KEY(client)
REFERENCES client(client_id)
ON DELETE SET NULL;
"""
alter_course = """
ALTER TABLE course
ADD FOREIGN KEY(teacher)
REFERENCES teacher(teacher_id)
ON DELETE SET NULL;
"""
alter_course_again = """
ALTER TABLE course
ADD FOREIGN KEY(client)
REFERENCES client(client_id)
ON DELETE SET NULL;
"""
create_takescourse_table = """
CREATE TABLE takes_course (
participant_id INT,
course_id INT,
PRIMARY KEY(participant_id, course_id),
FOREIGN KEY(participant_id) REFERENCES participant(participant_id) ON DELETE CASCADE,
FOREIGN KEY(course_id) REFERENCES course(course_id) ON DELETE CASCADE
);
"""
connection = create_db_connection("localhost", "root", pw, db)
execute_query(connection, alter_participant)
execute_query(connection, alter_course)
execute_query(connection, alter_course_again)
execute_query(connection, create_takescourse_table)Teraz tworzone są nasze tabele wraz z odpowiednimi ograniczeniami, kluczem podstawowym i relacjami klucza obcego.
Wypełnianie tabel
Następnym krokiem jest dodanie kilku rekordów do tabel. Ponownie używamy execute_query, aby wprowadzić nasze istniejące polecenia SQL do serwera. Zacznijmy ponownie od stołu Nauczyciela.
pop_teacher = """
INSERT INTO teacher VALUES
(1, 'James', 'Smith', 'ENG', NULL, '1985-04-20', 12345, '+491774553676'),
(2, 'Stefanie', 'Martin', 'FRA', NULL, '1970-02-17', 23456, '+491234567890'),
(3, 'Steve', 'Wang', 'MAN', 'ENG', '1990-11-12', 34567, '+447840921333'),
(4, 'Friederike', 'Müller-Rossi', 'DEU', 'ITA', '1987-07-07', 45678, '+492345678901'),
(5, 'Isobel', 'Ivanova', 'RUS', 'ENG', '1963-05-30', 56789, '+491772635467'),
(6, 'Niamh', 'Murphy', 'ENG', 'IRI', '1995-09-08', 67890, '+491231231232');
"""
connection = create_db_connection("localhost", "root", pw, db)
execute_query(connection, pop_teacher)czy to działa? Możemy to sprawdzić ponownie w naszym kliencie wiersza poleceń MySQL:
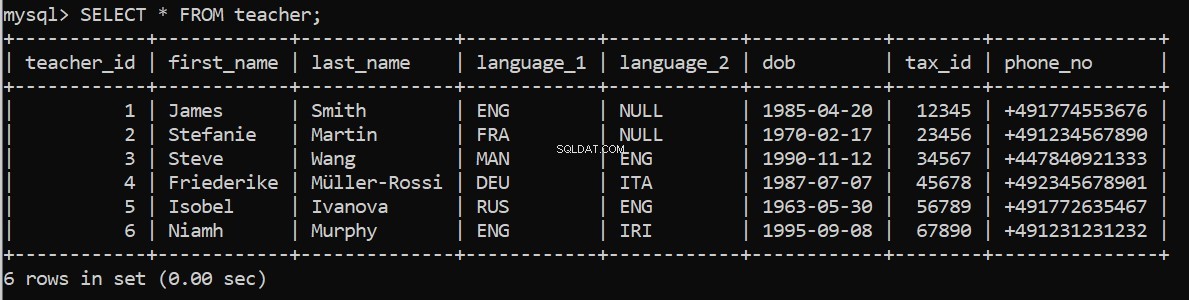
Teraz wypełnij pozostałe tabele.
pop_client = """
INSERT INTO client VALUES
(101, 'Big Business Federation', '123 Falschungstraße, 10999 Berlin', 'NGO'),
(102, 'eCommerce GmbH', '27 Ersatz Allee, 10317 Berlin', 'Retail'),
(103, 'AutoMaker AG', '20 Künstlichstraße, 10023 Berlin', 'Auto'),
(104, 'Banko Bank', '12 Betrugstraße, 12345 Berlin', 'Banking'),
(105, 'WeMoveIt GmbH', '138 Arglistweg, 10065 Berlin', 'Logistics');
"""
pop_participant = """
INSERT INTO participant VALUES
(101, 'Marina', 'Berg','491635558182', 101),
(102, 'Andrea', 'Duerr', '49159555740', 101),
(103, 'Philipp', 'Probst', '49155555692', 102),
(104, 'René', 'Brandt', '4916355546', 102),
(105, 'Susanne', 'Shuster', '49155555779', 102),
(106, 'Christian', 'Schreiner', '49162555375', 101),
(107, 'Harry', 'Kim', '49177555633', 101),
(108, 'Jan', 'Nowak', '49151555824', 101),
(109, 'Pablo', 'Garcia', '49162555176', 101),
(110, 'Melanie', 'Dreschler', '49151555527', 103),
(111, 'Dieter', 'Durr', '49178555311', 103),
(112, 'Max', 'Mustermann', '49152555195', 104),
(113, 'Maxine', 'Mustermann', '49177555355', 104),
(114, 'Heiko', 'Fleischer', '49155555581', 105);
"""
pop_course = """
INSERT INTO course VALUES
(12, 'English for Logistics', 'ENG', 'A1', 10, '2020-02-01', TRUE, 1, 105),
(13, 'Beginner English', 'ENG', 'A2', 40, '2019-11-12', FALSE, 6, 101),
(14, 'Intermediate English', 'ENG', 'B2', 40, '2019-11-12', FALSE, 6, 101),
(15, 'Advanced English', 'ENG', 'C1', 40, '2019-11-12', FALSE, 6, 101),
(16, 'Mandarin für Autoindustrie', 'MAN', 'B1', 15, '2020-01-15', TRUE, 3, 103),
(17, 'Français intermédiaire', 'FRA', 'B1', 18, '2020-04-03', FALSE, 2, 101),
(18, 'Deutsch für Anfänger', 'DEU', 'A2', 8, '2020-02-14', TRUE, 4, 102),
(19, 'Intermediate English', 'ENG', 'B2', 10, '2020-03-29', FALSE, 1, 104),
(20, 'Fortgeschrittenes Russisch', 'RUS', 'C1', 4, '2020-04-08', FALSE, 5, 103);
"""
pop_takescourse = """
INSERT INTO takes_course VALUES
(101, 15),
(101, 17),
(102, 17),
(103, 18),
(104, 18),
(105, 18),
(106, 13),
(107, 13),
(108, 13),
(109, 14),
(109, 15),
(110, 16),
(110, 20),
(111, 16),
(114, 12),
(112, 19),
(113, 19);
"""
connection = create_db_connection("localhost", "root", pw, db)
execute_query(connection, pop_client)
execute_query(connection, pop_participant)
execute_query(connection, pop_course)
execute_query(connection, pop_takescourse)Zdumiewający! Teraz stworzyliśmy bazę danych z relacjami, ograniczeniami i rekordami w MySQL, używając wyłącznie poleceń Pythona.
Przeszliśmy przez to krok po kroku, aby było to zrozumiałe. Ale w tym momencie możesz zobaczyć, że wszystko to można bardzo łatwo zapisać w jednym skrypcie Pythona i wykonać w jednym poleceniu w terminalu. Potężne rzeczy.
Czytanie danych
Teraz mamy funkcjonalną bazę danych do pracy. Jako analityk danych prawdopodobnie zetkniesz się z istniejącymi bazami danych w organizacjach, w których pracujesz. Bardzo przydatna będzie wiedza, jak wyciągnąć dane z tych baz danych, aby można je było następnie wprowadzić do potoku danych Pythona. Nad tym będziemy pracować w następnej kolejności.
Do tego będziemy potrzebować jeszcze jednej funkcji, tym razem używającej kursora.fetchall() zamiast kursora.commit(). Dzięki tej funkcji odczytujemy dane z bazy danych i nie będziemy wprowadzać żadnych zmian.
def read_query(connection, query):
cursor = connection.cursor()
result = None
try:
cursor.execute(query)
result = cursor.fetchall()
return result
except Error as err:
print(f"Error: '{err}'")Ponownie, zaimplementujemy to w bardzo podobny sposób do execute_query. Wypróbujmy to za pomocą prostego zapytania, aby zobaczyć, jak to działa.
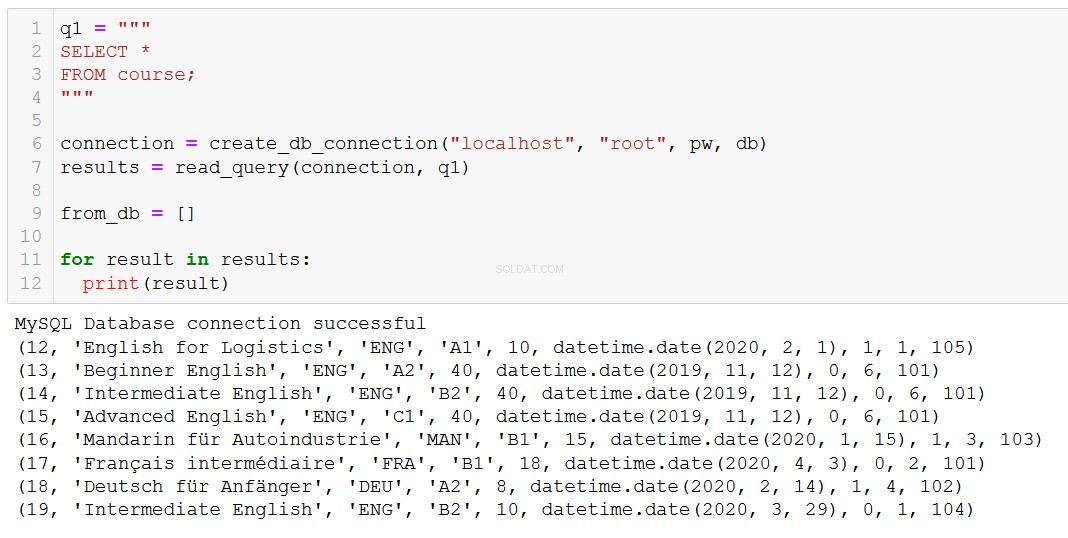
q1 = """
SELECT *
FROM teacher;
"""
connection = create_db_connection("localhost", "root", pw, db)
results = read_query(connection, q1)
for result in results:
print(result)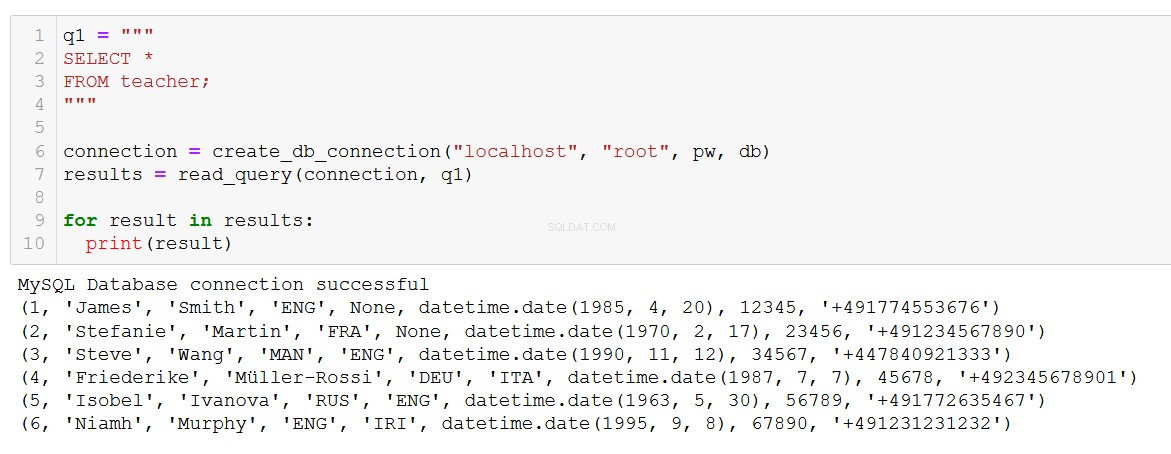
Dokładnie to, czego oczekujemy. Funkcja działa również z bardziej złożonymi zapytaniami, takimi jak to, które obejmuje JOIN w tabelach kursu i klienta.
q5 = """
SELECT course.course_id, course.course_name, course.language, client.client_name, client.address
FROM course
JOIN client
ON course.client = client.client_id
WHERE course.in_school = FALSE;
"""
connection = create_db_connection("localhost", "root", pw, db)
results = read_query(connection, q5)
for result in results:
print(result)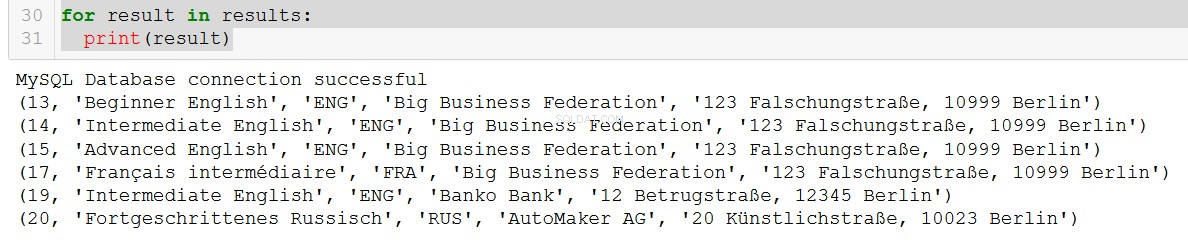
Bardzo dobrze.
W przypadku naszych potoków danych i przepływów pracy w Pythonie możemy chcieć uzyskać te wyniki w różnych formatach, aby były bardziej przydatne lub gotowe do manipulacji.
Przeanalizujmy kilka przykładów, aby zobaczyć, jak możemy to zrobić.
Formatowanie wyjścia na listę
#Initialise empty list
from_db = []
# Loop over the results and append them into our list
# Returns a list of tuples
for result in results:
result = result
from_db.append(result)
Formatowanie wyjścia na listę list
# Returns a list of lists
from_db = []
for result in results:
result = list(result)
from_db.append(result)
Formatowanie danych wyjściowych do pandy DataFrame
Dla analityków danych używających Pythona pandy są naszym pięknym i zaufanym starym przyjacielem. Bardzo łatwo jest przekonwertować dane wyjściowe z naszej bazy danych do ramki DataFrame, a stamtąd możliwości są nieograniczone!
# Returns a list of lists and then creates a pandas DataFrame
from_db = []
for result in results:
result = list(result)
from_db.append(result)
columns = ["course_id", "course_name", "language", "client_name", "address"]
df = pd.DataFrame(from_db, columns=columns)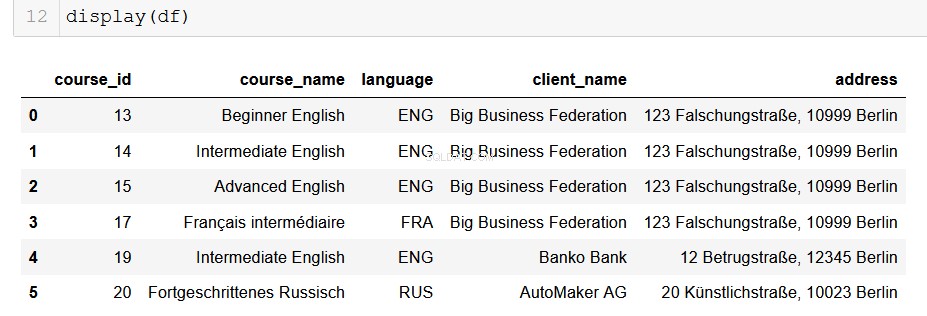
Mam nadzieję, że widzisz tutaj możliwości, które się przed tobą otwierają. Za pomocą zaledwie kilku linijek kodu możemy łatwo wyodrębnić wszystkie dane, które możemy obsłużyć z relacyjnych baz danych, w których się znajdują, i przeciągnąć je do naszych najnowocześniejszych potoków analizy danych. To naprawdę przydatne rzeczy.
Aktualizowanie rekordów
Kiedy prowadzimy bazę danych, czasami będziemy musieli wprowadzić zmiany w istniejących rekordach. W tej sekcji przyjrzymy się, jak to zrobić.
Załóżmy, że ILS został powiadomiony, że jeden z jej obecnych klientów, Federacja Wielkiego Biznesu, przenosi swoje biura do 23 Fingiertweg, 14534 Berlin. W takim przypadku administrator bazy danych (czyli my!) będzie musiał dokonać pewnych zmian.
Na szczęście możemy to zrobić za pomocą naszej funkcji execute_query wraz z instrukcją SQL UPDATE.
update = """
UPDATE client
SET address = '23 Fingiertweg, 14534 Berlin'
WHERE client_id = 101;
"""
connection = create_db_connection("localhost", "root", pw, db)
execute_query(connection, update)Zauważ, że klauzula WHERE jest tutaj bardzo ważna. Jeśli uruchomimy to zapytanie bez klauzuli WHERE, to wszystkie adresy dla wszystkich rekordów w naszej tabeli Client zostaną zaktualizowane do 23 Fingiertweg. To nie jest to, czego chcemy.
Należy również zauważyć, że w zapytaniu UPDATE użyliśmy „WHERE client_id =101”. Możliwe byłoby również użycie „WHERE nazwa_klienta ='Federacja Big Business'” lub „WHERE adres ='123 Falschungstraße, 10999 Berlin'” lub nawet „WHERE adres LIKE '%Falschung%'”.
Ważną rzeczą jest to, że klauzula WHERE pozwala nam jednoznacznie zidentyfikować rekord (lub rekordy), które chcemy zaktualizować.
Usuwanie rekordów
Możliwe jest również użycie naszej funkcji execute_query do usuwania rekordów za pomocą polecenia DELETE.
Używając SQL z relacyjnymi bazami danych, musimy być ostrożni przy korzystaniu z operatora DELETE. To nie jest Windows, nie ma opcji „Czy na pewno chcesz to usunąć?” wyskakujące okienko z ostrzeżeniem i brak kosza na surowce wtórne. Gdy coś usuniemy, to naprawdę zniknie.
Mając to na uwadze, czasami naprawdę musimy coś usuwać. Przyjrzyjmy się temu, usuwając kurs z naszej tabeli Kursy.
Przede wszystkim przypomnijmy sobie, jakie mamy kursy.
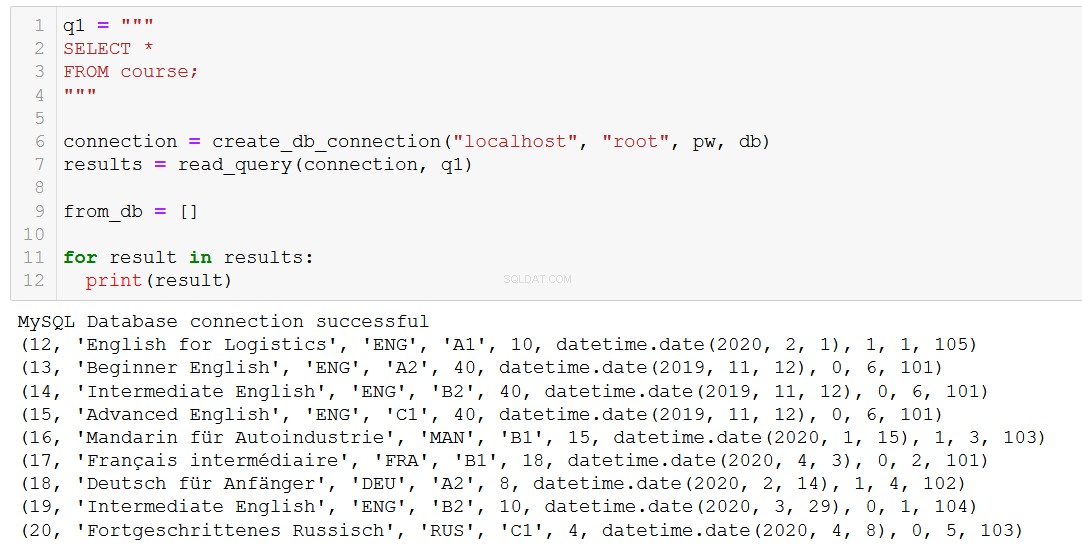
Załóżmy, że kurs 20 „Fortgeschrittenes Russisch” (dla ciebie i dla mnie to „zaawansowany rosyjski”) dobiega końca, więc musimy go usunąć z naszej bazy danych.
Na tym etapie nie będziesz zaskoczony tym, jak to robimy — zapisz polecenie SQL jako ciąg, a następnie wrzuć je do naszego konia roboczego funkcji execute_query.
delete_course = """
DELETE FROM course
WHERE course_id = 20;
"""
connection = create_db_connection("localhost", "root", pw, db)
execute_query(connection, delete_course)Sprawdźmy, czy przyniosło to zamierzony efekt:
„Zaawansowany rosyjski” zniknął, tak jak się spodziewaliśmy.
Działa to również z usuwaniem całych kolumn za pomocą DROP COLUMN i całych tabel za pomocą poleceń DROP TABLE, ale nie będziemy ich omawiać w tym samouczku.
Śmiało i poeksperymentuj z nimi — nie ma znaczenia, czy usuniesz kolumnę lub tabelę z bazy danych fikcyjnej szkoły, a dobrym pomysłem jest zapoznanie się z tymi poleceniami przed przejściem do środowiska produkcyjnego.
Och CRUD
W tym momencie jesteśmy w stanie wykonać cztery główne operacje trwałego przechowywania danych.
Nauczyliśmy się:
- Utwórz - całkowicie nowe bazy danych, tabele i rekordy
- Odczyt - wyodrębnij dane z bazy danych i przechowuj je w wielu formatach
- Aktualizacja - wprowadź zmiany w istniejących rekordach w bazie danych
- Usuń - usuń rekordy, które nie są już potrzebne
Są to fantastycznie przydatne rzeczy, które można zrobić.
Zanim skończymy, musimy się nauczyć jeszcze jednej bardzo przydatnej umiejętności.
Tworzenie rekordów z list
Podczas wypełniania naszych tabel widzieliśmy, że możemy użyć polecenia SQL INSERT w naszej funkcji execute_query, aby wstawić rekordy do naszej bazy danych.
Biorąc pod uwagę, że używamy Pythona do manipulowania naszą bazą danych SQL, przydatna byłaby możliwość pobrania struktury danych Pythona (takiej jak lista) i wstawienia jej bezpośrednio do naszej bazy danych.
Może to być przydatne, gdy chcemy na przykład przechowywać logi aktywności użytkowników w aplikacji społecznościowej, którą napisaliśmy w Pythonie lub dane wejściowe od użytkowników do zbudowanej przez nas Wiki. Jest tyle możliwych zastosowań tego, ile możesz sobie wyobrazić.
Ta metoda jest również bezpieczniejsza, jeśli nasza baza danych jest otwarta dla naszych użytkowników w dowolnym momencie, ponieważ pomaga zapobiegać atakom SQL Injection, które mogą uszkodzić lub nawet zniszczyć całą naszą bazę danych.
Aby to zrobić, napiszemy funkcję za pomocą metody executemany(), zamiast prostszej metody execute(), której używaliśmy do tej pory.
def execute_list_query(connection, sql, val):
cursor = connection.cursor()
try:
cursor.executemany(sql, val)
connection.commit()
print("Query successful")
except Error as err:
print(f"Error: '{err}'")Teraz mamy funkcję, musimy zdefiniować polecenie SQL ('sql') oraz listę zawierającą wartości, które chcemy wprowadzić do bazy danych ('val'). Wartości muszą być przechowywane jako lista krotek, co jest dość powszechnym sposobem przechowywania danych w Pythonie.
Aby dodać dwóch nowych nauczycieli do bazy danych, możemy napisać taki kod:
sql = '''
INSERT INTO teacher (teacher_id, first_name, last_name, language_1, language_2, dob, tax_id, phone_no)
VALUES (%s, %s, %s, %s, %s, %s, %s, %s)
'''
val = [
(7, 'Hank', 'Dodson', 'ENG', None, '1991-12-23', 11111, '+491772345678'),
(8, 'Sue', 'Perkins', 'MAN', 'ENG', '1976-02-02', 22222, '+491443456432')
]Zauważ, że w kodzie 'sql' używamy '%s' jako symbolu zastępczego dla naszej wartości. Podobieństwo do symbolu zastępczego „%s” dla ciągu znaków w pythonie jest po prostu przypadkowe (i szczerze mówiąc, bardzo mylące), chcemy użyć „%s” dla wszystkich typów danych (ciągi, int, daty itp.) z MySQL Python Złącze.
Możesz zobaczyć wiele pytań na Stackoverflow, w których ktoś się zdezorientował i próbował użyć symboli zastępczych „%d” dla liczb całkowitych, ponieważ jest do tego przyzwyczajony w Pythonie. To nie zadziała tutaj — musimy użyć „%s” dla każdej kolumny, do której chcemy dodać wartość.
Następnie funkcja executemany pobiera każdą krotkę z naszej listy 'val' i wstawia odpowiednią wartość dla tej kolumny w miejsce symbolu zastępczego i wykonuje polecenie SQL dla każdej krotki zawartej na liście.
Można to wykonać dla wielu wierszy danych, o ile są one poprawnie sformatowane. W naszym przykładzie po prostu dodamy dwóch nowych nauczycieli, w celach ilustracyjnych, ale w zasadzie możemy dodać tyle, ile chcemy.
Przejdźmy dalej i wykonajmy to zapytanie i dodajmy nauczycieli do naszej bazy danych.
connection = create_db_connection("localhost", "root", pw, db)
execute_list_query(connection, sql, val)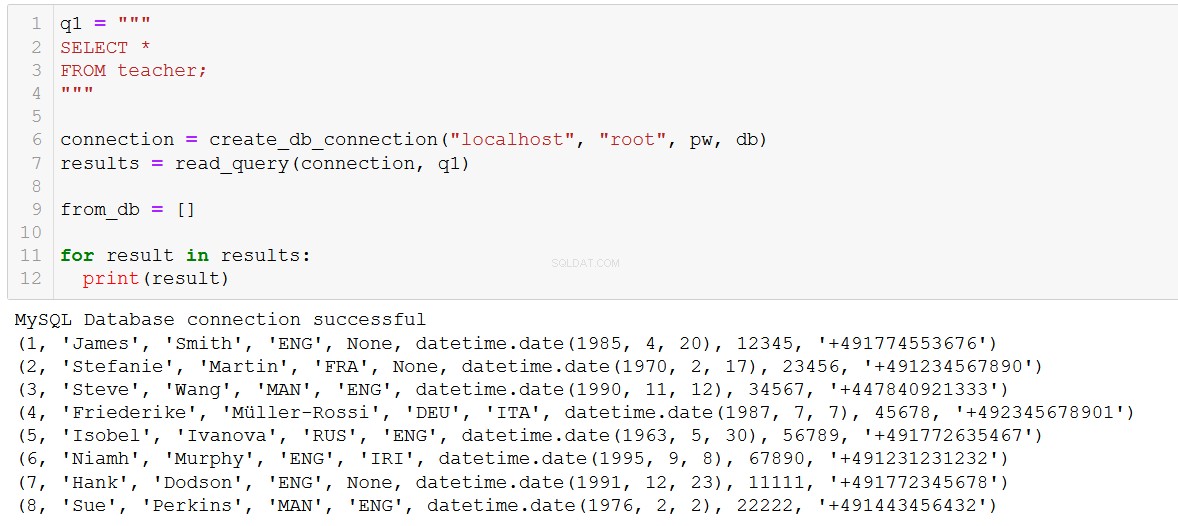
Witamy w ILS, Hank i Sue!
This is yet another deeply useful function, allowing us to take data generated in our Python scripts and applications, and enter them directly into our database.
Wniosek
We have covered a lot of ground in this tutorial.
We have learned how to use Python and MySQL Connector to create an entirely new database in MySQL Server, create tables within that database, define the relationships between those tables, and populate them with data.
We have covered how to Create, Read, Update and Delete data in our database.
We have looked at how to extract data from existing databases and load them into pandas DataFrames, ready for analysis and further work taking advantage of all the possibilities offered by the PyData stack.
Going in the other direction, we have also learned how to take data generated by our Python scripts and applications, and write those into a database where they can be safely stored for later retrieval and manipulation.
I hope this tutorial has helped you to see how we can use Python and SQL together to be able to manipulate data even more effectively!
If you'd like to see more of my projects and work, please visit my website at craigdoesdata.de. If you have any feedback on this tutorial, please contact me directly - all feedback is warmly received!