Wraz ze wzrostem rozmiarów tabel i indeksów bazy danych dane stają się bardziej pofragmentowane, a odpowiedź na zapytania spowalnia. Aby poprawić wydajność działania bazy danych, wymagana jest regularna reorganizacja tabeli. Zapoznaj się z tym artykułem, w którym wyjaśniamy, dlaczego porządki są ważne, oraz z poniższymi materiałami, w których szczegółowo opisano sposób korzystania z kreatora.
Co to jest
IRI Workbench — środowisko IDE i graficzny interfejs użytkownika Eclipse dla wszystkich produktów oprogramowania IRI — zapewnia klasyczne (offline) rozwiązanie reorg za pomocą specjalnie zaprojektowanego kreatora. Kreator Offline Reorg ułatwia specyfikację i wykonywanie wielu reorg na dużą skalę, które przechowują duże tabele w kolejności zapytań (np. dołączania) bez obciążania samej bazy danych.
Do czego służy
Kreator reorganizacji offline tworzy krok po kroku proces „Rozładuj, zamów i ponownie załaduj” dla jednej lub kilku tabel jednocześnie, korzystając z produktów wchodzących w skład pakietu IRI Data Manager. W przypadku reorgów na dużą skalę określa konfigurację:
- IRI FACT dla zbiorczego wyładowania tabeli
- IRI CoSort do zmiany kolejności
- narzędzie ładowania docelowej bazy danych dla wstępnie posortowanych, masowych ładunków
Opcje wyboru i wstawiania ODBC są również dostępne w przypadku operacji na mniejszą skalę lub bardziej precyzyjnych operacji.
Na końcu kreatora tworzone są skrypty zadań potrzebne do ponownego uporządkowania wybranych tabel. Zadania można uruchamiać w dowolnym miejscu, w którym wybrane narzędzia są objęte licencją, i można je wywoływać z interfejsu GUI, wiersza poleceń lub skryptu wsadowego (który również tworzy kreator). Na użytkowników bazy danych nie ma wpływu metoda reorganizacji offline, chociaż przeładowania lub aktualizacje ODBC mogą zmienić używane tabele.
Jak to działa
Aby uruchomić kreatora reorganizacji offline w IRI Workbench, przejdź do listy rozwijanej w menu FACT i wybierz „Nowe zadanie reorganizacji offline…”.

W pierwszym oknie dialogowym wybierz folder projektu i nazwij podfolder, w którym będą przechowywane metadane reorg i posortowane wyniki, a następnie określ metodę pozyskiwania (rozładowania) i ponownego zapełniania (wczytywania) tabeli.

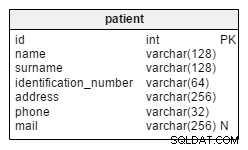
Następny jest etap wyodrębniania (rozładowywania) danych. Dostępne profile bazy danych mogą zależeć od tego, co wybrałeś na poprzedniej stronie w polu Wyodrębnianie. Wybierz bazę danych z pliku połączenia oraz tabele, które chcesz uporządkować, spośród tych dostępnych w oknie wyboru:

Dalej jest etap ładowania danych, na którym określasz szczegóły tabeli docelowej. Wybierz profil połączenia, nazwy schematów i odpowiednie opcje ponownego zapełniania (w tym przypadku za pomocą Oracle SQL*Loader). Kliknij Zakończ, aby automatycznie zbudować wszystkie skrypty potrzebne do uruchomienia reorg.

W wyniku tego procesu powstały pliki niezbędne do automatycznej reorganizacji tylko tabeli JOB_TYPES w trybie offline. Skrypty rozładowywania (FACT .ini), sortowania (CoSort .scl) i ponownego ładowania (Oracle .ctl) oraz pliki pomocnicze są tworzone wraz ze skryptem wsadowym niezbędnym do uruchomienia tego wszystkiego. Pliki .sql zachowują ograniczenia, a plik .flow obsługuje wizualną reprezentację przepływu pracy w osobnym widoku.

Po uruchomieniu skryptu wsadowego (FlowBatch.bat) tworzona jest tabela zawierająca ponownie posortowane dane do załadowania. Poniżej znajduje się widok tabeli przed i po reorganizacji:

Liczba elementów jest taka sama, ale kreator reorganizacji domyślnie sortował tabelę według klucza podstawowego. Możesz zmienić klucze sortowania w zadaniu .scl (ręcznie lub za pomocą GUI), jeśli chcesz zmienić kolejność tabeli w innej kolumnie (wyszukiwania).
Skontaktuj się z info@iri.com, jeśli masz jakiekolwiek pytania dotyczące działania tego kreatora lub jeśli potrzebujesz dostępu do wersji demonstracyjnej lub tych składników IRI Data Manager apartament.