Wydajność jest niezwykle ważna w wielu produktach konsumenckich, takich jak handel elektroniczny, systemy płatności, gry, aplikacje transportowe i tak dalej. Chociaż bazy danych są wewnętrznie zoptymalizowane za pomocą wielu mechanizmów, aby spełnić ich wymagania dotyczące wydajności we współczesnym świecie, wiele zależy również od programisty aplikacji — w końcu tylko programista wie, jakie zapytania ma wykonać aplikacja.
Deweloperzy zajmujący się relacyjnymi bazami danych używali lub przynajmniej słyszeli o indeksowaniu i jest to bardzo powszechna koncepcja w świecie baz danych. Jednak najważniejszą częścią jest zrozumienie, co indeksować i w jaki sposób indeksowanie zwiększy czas odpowiedzi na zapytanie. Aby to zrobić, musisz zrozumieć, w jaki sposób zamierzasz wysyłać zapytania do tabel bazy danych. Właściwy indeks można utworzyć tylko wtedy, gdy dokładnie wiesz, jak wyglądają wzorce zapytań i dostępu do danych.
W prostej terminologii indeks mapuje klucze wyszukiwania do odpowiednich danych na dysku, używając różnych struktur danych w pamięci i na dysku. Indeks służy do przyspieszenia wyszukiwania poprzez zmniejszenie liczby rekordów do wyszukania.
Najczęściej indeks jest tworzony na kolumnach określonych w WHERE klauzula zapytania, ponieważ baza danych pobiera i filtruje dane z tabel na podstawie tych kolumn. Jeśli nie utworzysz indeksu, baza danych przeskanuje wszystkie wiersze, odfiltruje pasujące wiersze i zwróci wynik. Przy milionach rekordów ta operacja skanowania może zająć wiele sekund, a ten długi czas odpowiedzi sprawia, że interfejsy API i aplikacje są wolniejsze i bezużyteczne. Zobaczmy przykład —
Będziemy używać MySQL z domyślnym silnikiem bazy danych InnoDB, chociaż koncepcje wyjaśnione w tym artykule są mniej więcej takie same w innych serwerach baz danych, takich jak Oracle, MSSQL itp.
Utwórz tabelę o nazwie index_demo o następującym schemacie:
CREATE TABLE index_demo (
name VARCHAR(20) NOT NULL,
age INT,
pan_no VARCHAR(20),
phone_no VARCHAR(20)
);Jak możemy sprawdzić, czy używamy silnika InnoDB?
Uruchom poniższe polecenie:
SHOW TABLE STATUS WHERE name = 'index_demo' \G;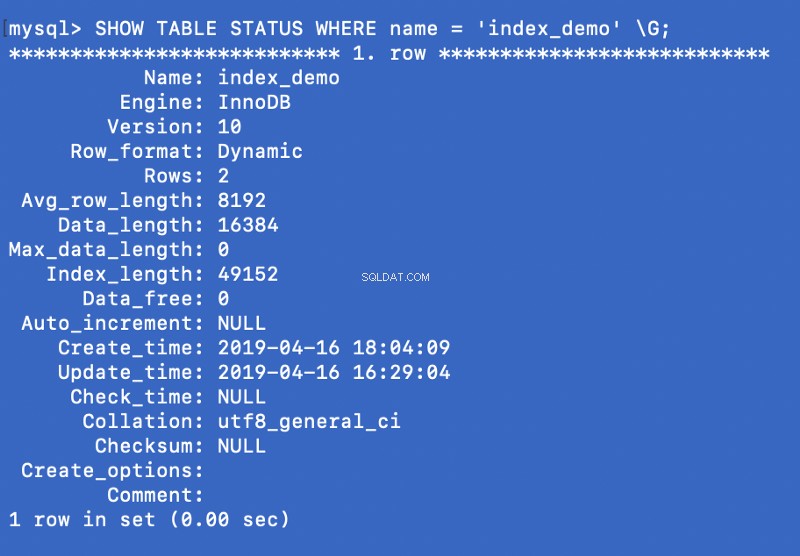
Engine Kolumna na powyższym zrzucie ekranu reprezentuje silnik, który jest używany do tworzenia tabeli. Tutaj InnoDB jest używany.
Teraz wstaw losowe dane do tabeli, moja tabela z 5 wierszami wygląda następująco:
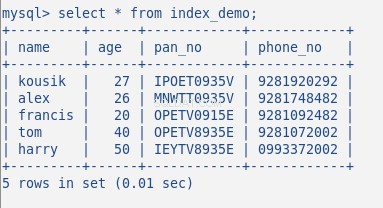
Do tej pory nie stworzyłem żadnego indeksu w tej tabeli. Zweryfikujmy to poleceniem:SHOW INDEX . Zwraca 0 wyników.

W tym momencie, jeśli uruchomimy prosty SELECT zapytanie, ponieważ nie ma indeksu zdefiniowanego przez użytkownika, zapytanie przeskanuje całą tabelę, aby znaleźć wynik:
EXPLAIN SELECT * FROM index_demo WHERE name = 'alex';
EXPLAIN pokazuje, jak aparat zapytań planuje wykonać zapytanie. Na powyższym zrzucie ekranu widać, że rows kolumna zwraca 5 &possible_keys zwraca null . possible_keys reprezentuje wszystkie dostępne indeksy, których można użyć w tym zapytaniu. key kolumna przedstawia, który indeks będzie faktycznie używany spośród wszystkich możliwych indeksów w tym zapytaniu.
Klucz główny:
Powyższe zapytanie jest bardzo nieefektywne. Zoptymalizujmy to zapytanie. Zrobimy phone_no kolumna a PRIMARY KEY zakładając, że w naszym systemie nie może istnieć dwóch użytkowników o tym samym numerze telefonu. Podczas tworzenia klucza podstawowego należy wziąć pod uwagę następujące kwestie:
- Klucz podstawowy powinien być częścią wielu ważnych zapytań w Twojej aplikacji.
- Klucz podstawowy to ograniczenie, które jednoznacznie identyfikuje każdy wiersz w tabeli. Jeśli kluczem podstawowym jest wiele kolumn, ta kombinacja powinna być unikalna dla każdego wiersza.
- Klucz podstawowy nie powinien mieć wartości Null. Nigdy nie traktuj pól dopuszczających wartość null jako klucza podstawowego. Według standardów ANSI SQL klucze podstawowe powinny być ze sobą porównywalne i zdecydowanie powinieneś być w stanie stwierdzić, czy wartość kolumny klucza podstawowego dla danego wiersza jest większa, mniejsza lub równa wartości z innego wiersza. Od
NULLoznacza niezdefiniowaną wartość w standardach SQL, nie można deterministycznie porównaćNULLz dowolną inną wartością, więc logicznieNULLnie jest dozwolone. - Idealnym typem klucza głównego powinna być liczba, taka jak
INTlubBIGINTponieważ porównania liczb całkowitych są szybsze, więc przechodzenie przez indeks będzie bardzo szybkie.
Często definiujemy id pole jako AUTO INCREMENT w tabelach i używaj go jako klucza podstawowego, ale wybór klucza podstawowego zależy od programistów.
Co, jeśli sam nie utworzysz żadnego klucza podstawowego?
Samodzielne tworzenie klucza podstawowego nie jest obowiązkowe. Jeśli nie zdefiniowałeś żadnego klucza podstawowego, InnoDB utworzy go niejawnie, ponieważ InnoDB z założenia musi mieć klucz podstawowy w każdej tabeli. Więc kiedy później utworzysz klucz podstawowy dla tej tabeli, InnoDB usunie wcześniej zdefiniowany automatycznie klucz podstawowy.
Ponieważ na razie nie mamy zdefiniowanego klucza podstawowego, zobaczmy, co domyślnie stworzył dla nas InnoDB:
SHOW EXTENDED INDEX FROM index_demo;
EXTENDED pokazuje wszystkie indeksy, które nie są używane przez użytkownika, ale są całkowicie zarządzane przez MySQL.
Tutaj widzimy, że MySQL zdefiniował indeks złożony (indeksy złożone omówimy później) na DB_ROW_ID , DB_TRX_ID , DB_ROLL_PTR i wszystkie kolumny zdefiniowane w tabeli. W przypadku braku klucza podstawowego zdefiniowanego przez użytkownika, ten indeks jest używany do unikatowego wyszukiwania rekordów.
Jaka jest różnica między kluczem a indeksem?
Chociaż terminy key &index są używane zamiennie, key oznacza ograniczenie nałożone na zachowanie słupa. W tym przypadku ograniczeniem jest to, że klucz podstawowy jest polem nie dopuszczającym wartości null, które jednoznacznie identyfikuje każdy wiersz. Z drugiej strony index to specjalna struktura danych, która ułatwia wyszukiwanie danych w tabeli.
Utwórzmy teraz główny indeks na phone_no &sprawdź utworzony indeks:
ALTER TABLE index_demo ADD PRIMARY KEY (phone_no);
SHOW INDEXES FROM index_demo;
Zauważ, że CREATE INDEX nie można użyć do utworzenia indeksu podstawowego, ale ALTER TABLE jest używany.

Na powyższym zrzucie ekranu widzimy, że jeden główny indeks jest tworzony w kolumnie phone_no . Kolumny poniższych obrazów są opisane w następujący sposób:
Table :Tabela, na której tworzony jest indeks.
Non_unique :Jeśli wartość wynosi 1, indeks nie jest unikalny, jeśli wartość wynosi 0, indeks jest unikalny.
Key_name :nazwa utworzonego indeksu. Nazwa głównego indeksu to zawsze PRIMARY w MySQL, niezależnie od tego, czy podczas tworzenia indeksu podałeś nazwę indeksu, czy nie.
Seq_in_index :Numer kolejny kolumny w indeksie. Jeśli częścią indeksu jest wiele kolumn, numer kolejny zostanie przydzielony na podstawie kolejności kolumn w czasie tworzenia indeksu. Numer sekwencyjny zaczyna się od 1.
Collation :jak kolumna jest sortowana w indeksie. A oznacza rosnąco, D oznacza malejąco, NULL oznacza nieposortowane.
Cardinality :Szacowana liczba unikalnych wartości w indeksie. Większa kardynalność oznacza większe szanse, że optymalizator zapytań wybierze indeks dla zapytań.
Sub_part :Prefiks indeksu. To jest NULL jeśli indeksowana jest cała kolumna. W przeciwnym razie pokazuje liczbę indeksowanych bajtów w przypadku częściowego indeksowania kolumny. Częściowy indeks zdefiniujemy później.
Packed :wskazuje sposób zapakowania klucza; NULL jeśli nie.
Null :YES jeśli kolumna może zawierać NULL wartości i puste, jeśli nie.
Index_type :wskazuje, która struktura danych indeksowania jest używana dla tego indeksu. Niektórzy potencjalni kandydaci to — BTREE , HASH , RTREE lub FULLTEXT .
Comment :Informacje o indeksie nie opisane w jego własnej kolumnie.
Index_comment :Komentarz do indeksu określonego podczas tworzenia indeksu za pomocą COMMENT atrybut.
Zobaczmy teraz, czy ten indeks zmniejsza liczbę wierszy, które będą przeszukiwane dla danego phone_no w WHERE klauzula zapytania.
EXPLAIN SELECT * FROM index_demo WHERE phone_no = '9281072002';
W tym zrzucie zwróć uwagę, że rows kolumna zwróciła 1 tylko possible_keys &key oba zwracają PRIMARY . Oznacza to więc zasadniczo, że użycie podstawowego indeksu o nazwie PRIMARY (nazwa jest automatycznie przypisywana podczas tworzenia klucza podstawowego), optymalizator zapytań po prostu przechodzi bezpośrednio do rekordu i pobiera go. Jest bardzo wydajny. Właśnie do tego służy indeks — aby zminimalizować zakres wyszukiwania kosztem dodatkowej przestrzeni.
Indeks klastrowy:
clustered index jest skolokowany z danymi w tym samym obszarze tabel lub w tym samym pliku na dysku. Możesz uznać, że indeks klastrowy to B-Tree indeks, którego węzły liści są rzeczywistymi blokami danych na dysku, ponieważ indeks i dane znajdują się razem. Ten rodzaj indeksu fizycznie porządkuje dane na dysku zgodnie z logiczną kolejnością klucza indeksu.
Co oznacza fizyczna organizacja danych?
Fizycznie dane są zorganizowane na dysku na tysiącach lub milionach dysków/bloków danych. W przypadku indeksu klastrowego nie jest wymagane, aby wszystkie bloki dysku były zaraźliwie przechowywane. Fizyczne bloki danych są cały czas przenoszone tu i tam przez system operacyjny, gdy jest to konieczne. System bazy danych nie ma absolutnej kontroli nad sposobem zarządzania fizyczną przestrzenią danych, ale wewnątrz bloku danych rekordy mogą być przechowywane lub zarządzane w logicznej kolejności klucza indeksu. Wyjaśnia to poniższy uproszczony schemat:
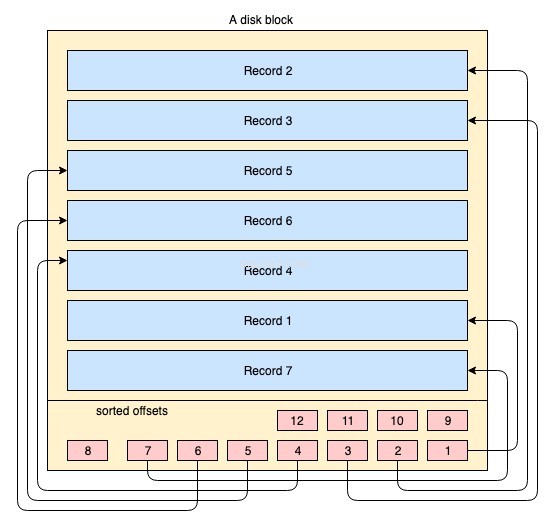
- Duży prostokąt w kolorze żółtym reprezentuje blok dysku/blok danych
- niebieskie prostokąty reprezentują dane przechowywane jako wiersze wewnątrz tego bloku
- Obszar stopki reprezentuje indeks bloku, w którym znajdują się małe prostokąty w kolorze czerwonym, uporządkowane według określonego klucza. Te małe bloki są niczym innym jak wskaźnikami wskazującymi na przesunięcia rekordów.
Rekordy są przechowywane w bloku dyskowym w dowolnej kolejności. Za każdym razem, gdy dodawane są nowe rekordy, są one dodawane w następnym dostępnym miejscu. Za każdym razem, gdy aktualizowany jest istniejący rekord, system operacyjny decyduje, czy ten rekord może nadal pasować do tej samej pozycji, czy też musi zostać przydzielona nowa pozycja dla tego rekordu.
Tak więc pozycja rekordów jest całkowicie obsługiwana przez system operacyjny i nie istnieje żaden określony związek między kolejnością dowolnych dwóch rekordów. Aby pobrać rekordy w logicznej kolejności klucza, strony dysku zawierają w stopce sekcję indeksu, indeks zawiera listę wskaźników przesunięcia w kolejności klucza. Za każdym razem, gdy rekord jest zmieniany lub tworzony, indeks jest dostosowywany.
W ten sposób naprawdę nie musisz przejmować się faktycznym porządkowaniem fizycznego rekordu w określonej kolejności, raczej niewielka sekcja indeksu jest utrzymywana w tej kolejności, a pobieranie lub utrzymywanie rekordów staje się bardzo łatwe.
Zaleta indeksu klastrowego:
Taka kolejność lub kolokacja powiązanych danych w rzeczywistości przyspiesza indeks klastrowy. Kiedy dane są pobierane z dysku, cały blok zawierający dane jest odczytywany przez system, ponieważ nasz dyskowy system IO zapisuje i odczytuje dane w blokach. Tak więc w przypadku zapytań o zakres jest całkiem możliwe, że kolokowane dane są buforowane w pamięci. Załóżmy, że uruchamiasz następujące zapytanie:
SELECT * FROM index_demo WHERE phone_no > '9010000000' AND phone_no < '9020000000'
Blok danych jest pobierany do pamięci podczas wykonywania zapytania. Powiedzmy, że blok danych zawiera phone_no w zakresie od 9010000000 do 9030000000 . Zatem jakikolwiek zakres, o który prosiłeś w zapytaniu, jest tylko podzbiorem danych obecnych w bloku. Jeśli teraz uruchomisz następne zapytanie, aby uzyskać wszystkie numery telefonów z zakresu, powiedz z 9015000000 do 9019000000 , nie musisz pobierać więcej bloków z dysku. Pełne dane można znaleźć w bieżącym bloku danych, dlatego clustered_index zmniejsza liczbę operacji we/wy na dysku, umieszczając powiązane dane w największym możliwym stopniu w tym samym bloku danych. To zredukowane IO na dysku powoduje poprawę wydajności.
Więc jeśli dobrze myślisz o kluczu podstawowym i twoje zapytania są oparte na kluczu podstawowym, wydajność będzie superszybka.
Ograniczenia indeksu klastrowanego:
Ponieważ indeks klastrowy wpływa na fizyczną organizację danych, może istnieć tylko jeden indeks klastrowy na tabelę.
Związek między kluczem podstawowym a indeksem klastrowym:
Nie można ręcznie utworzyć indeksu klastrowego za pomocą InnoDB w MySQL. MySQL wybierze to za Ciebie. Ale jak to wybiera? Poniższe fragmenty pochodzą z dokumentacji MySQL:
Gdy definiujeszPRIMARY KEYna twoim stole,InnoDBużywa go jako indeksu klastrowego. Zdefiniuj klucz podstawowy dla każdej tworzonej tabeli. Jeśli nie ma logicznej unikatowej i innej niż null kolumny lub zestawu kolumn, dodaj nową kolumnę autoinkrementacji, której wartości są wypełniane automatycznie.
Jeśli nie zdefiniujeszPRIMARY KEYdla twojej tabeli, MySQL zlokalizuje pierwszyUNIQUEindeks, w którym wszystkie kluczowe kolumny sąNOT NULLiInnoDBużywa go jako indeksu klastrowego.
Jeśli w tabeli nie maPRIMARY KEYlub odpowiedniUNIQUEindeks,InnoDBwewnętrznie generuje ukryty indeks klastrowy o nazwieGEN_CLUST_INDEXna syntetycznej kolumnie zawierającej wartości identyfikatora wiersza. Wiersze są uporządkowane według identyfikatoraInnoDBprzypisuje do wierszy w takiej tabeli. Identyfikator wiersza to 6-bajtowe pole, które zwiększa się monotonicznie w miarę wstawiania nowych wierszy. W ten sposób wiersze uporządkowane według identyfikatora wiersza są fizycznie w kolejności wstawiania.
Krótko mówiąc, silnik MySQL InnoDB faktycznie zarządza indeksem podstawowym jako indeksem klastrowym w celu poprawy wydajności, więc klucz podstawowy i rzeczywisty rekord na dysku są zgrupowane razem.
Struktura klucza podstawowego (klastrowy) Indeks:
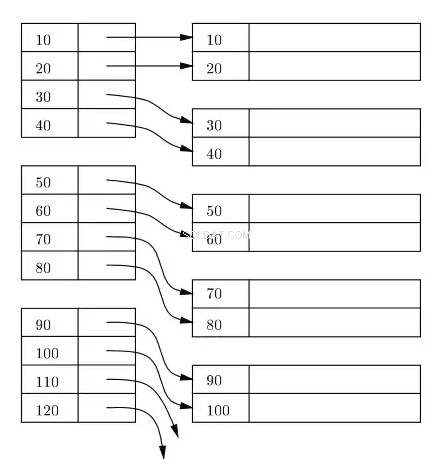
Indeks jest zwykle utrzymywany jako drzewo B+ na dysku iw pamięci, a każdy indeks jest przechowywany w blokach na dysku. Bloki te nazywane są blokami indeksowymi. Wpisy w bloku indeksu są zawsze sortowane według klucza indeksu/wyszukiwania. Blok indeksu liścia indeksu zawiera lokalizator wiersza. W przypadku indeksu podstawowego lokalizator wiersza odnosi się do wirtualnego adresu odpowiedniej fizycznej lokalizacji bloków danych na dysku, na którym znajdują się wiersze posortowane zgodnie z kluczem indeksu.
Na poniższym diagramie prostokąty po lewej stronie reprezentują bloki indeksu na poziomie liścia, a prostokąty po prawej stronie reprezentują bloki danych. Logicznie, bloki danych wyglądają na wyrównane w posortowanej kolejności, ale jak już opisano wcześniej, rzeczywiste fizyczne lokalizacje mogą być rozproszone tu i tam.
Czy można utworzyć indeks podstawowy na kluczu innym niż podstawowy?
W MySQL indeks podstawowy jest tworzony automatycznie i już opisaliśmy powyżej, w jaki sposób MySQL wybiera indeks podstawowy. Ale w świecie baz danych w rzeczywistości nie jest konieczne tworzenie indeksu w kolumnie klucza podstawowego — indeks podstawowy można utworzyć również w dowolnej kolumnie klucza innego niż podstawowy. Ale po utworzeniu na kluczu podstawowym wszystkie wpisy klucza są unikatowe w indeksie, podczas gdy w innym przypadku indeks podstawowy może mieć również zduplikowany klucz.
Czy można usunąć klucz podstawowy?
Istnieje możliwość usunięcia klucza podstawowego. Gdy usuniesz klucz podstawowy, powiązany indeks klastrowy oraz właściwość unikalności tej kolumny zostaną utracone.
ALTER TABLE `index_demo` DROP PRIMARY KEY;
- If the primary key does not exist, you get the following error:
"ERROR 1091 (42000): Can't DROP 'PRIMARY'; check that column/key exists"Zalety indeksu podstawowego:
- Kwerendy zakresu oparte na indeksie podstawowym są bardzo wydajne. Może istnieć możliwość, że blok dysku, który baza danych odczytała z dysku, zawiera wszystkie dane należące do zapytania, ponieważ indeks podstawowy jest zgrupowany, a rekordy są uporządkowane fizycznie. Tak więc lokalizacja danych może być podana przez główny indeks.
- Każde zapytanie korzystające z klucza podstawowego jest bardzo szybkie.
Wady indeksu podstawowego:
- Ponieważ indeks podstawowy zawiera bezpośrednie odniesienie do adresu bloku danych poprzez wirtualną przestrzeń adresową, a bloki dysku są fizycznie zorganizowane w kolejności klucza indeksu, za każdym razem, gdy system operacyjny dokonuje podziału strony dysku z powodu
DMLoperacje takie jakINSERT/UPDATE/DELETE, indeks podstawowy również musi zostać zaktualizowany. WięcDMLoperacje wywierają pewną presję na wydajność głównego indeksu.
Indeks dodatkowy:
Każdy indeks inny niż indeks klastrowy jest nazywany indeksem wtórnym. Indeksy dodatkowe nie wpływają na fizyczne lokalizacje pamięci w przeciwieństwie do indeksów podstawowych.
Kiedy potrzebujesz dodatkowego indeksu?
Możesz mieć kilka przypadków użycia w swojej aplikacji, w których nie wysyłasz zapytań do bazy danych za pomocą klucza podstawowego. W naszym przykładzie phone_no jest kluczem podstawowym, ale może być konieczne wykonanie zapytania do bazy danych za pomocą pan_no lub name . W takich przypadkach potrzebne są dodatkowe indeksy w tych kolumnach, jeśli częstotliwość takich zapytań jest bardzo wysoka.
Jak utworzyć dodatkowy indeks w MySQL?
Poniższe polecenie tworzy dodatkowy indeks w name kolumna w index_demo tabela.
CREATE INDEX secondary_idx_1 ON index_demo (name);
Struktura indeksu dodatkowego:
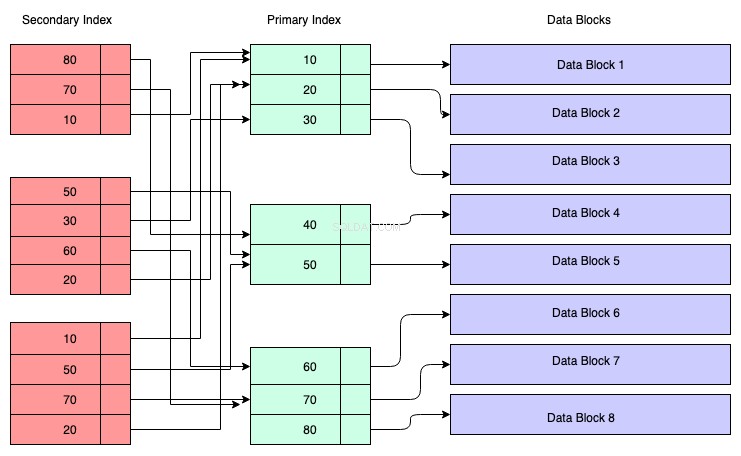
Na poniższym diagramie prostokąty w kolorze czerwonym reprezentują drugorzędne bloki indeksowe. Indeks wtórny jest również utrzymywany w drzewie B+ i jest sortowany według klucza, na którym indeks został utworzony. Węzły liści zawierają kopię klucza odpowiednich danych w indeksie głównym.
Aby zrozumieć, możesz założyć, że indeks pomocniczy ma odniesienie do adresu klucza podstawowego, chociaż tak nie jest. Pobieranie danych przez indeks wtórny oznacza, że musisz przejść przez dwa drzewa B+ — jedno to samo drzewo z indeksem wtórnym B+, a drugie to drzewo z indeksem głównym B+.
Zalety indeksu dodatkowego:
Logicznie możesz stworzyć tyle indeksów wtórnych, ile chcesz. Ale w rzeczywistości liczba wymaganych indeksów wymaga poważnego procesu myślowego, ponieważ każdy indeks ma swoją własną karę.
Wady indeksu dodatkowego:
Z DML operacje takie jak DELETE / INSERT , indeks pomocniczy również musi zostać zaktualizowany, aby można było usunąć / wstawić kopię kolumny klucza podstawowego. W takich przypadkach istnienie wielu indeksów wtórnych może powodować problemy.
Ponadto, jeśli klucz podstawowy jest bardzo duży, jak URL , ponieważ indeksy pomocnicze zawierają kopię wartości kolumny klucza podstawowego, może to być nieefektywne pod względem przechowywania. Więcej kluczy pomocniczych oznacza większą liczbę zduplikowanych kopii wartości kolumny klucza podstawowego, więc więcej miejsca do przechowywania w przypadku dużego klucza podstawowego. Również klucz podstawowy przechowuje klucze, więc łączny wpływ na przechowywanie będzie bardzo wysoki.
Rozważenie przed usunięciem indeksu podstawowego:
W MySQL możesz usunąć indeks podstawowy, upuszczając klucz podstawowy. Widzieliśmy już, że indeks wtórny zależy od indeksu podstawowego. Jeśli więc usuniesz indeks główny, wszystkie indeksy drugorzędne muszą zostać zaktualizowane, aby zawierały kopię nowego klucza indeksu głównego, który MySQL automatycznie dostosowuje.
Ten proces jest kosztowny, gdy istnieje kilka indeksów pomocniczych. Również inne tabele mogą mieć odniesienia do klucza obcego do klucza podstawowego, więc musisz usunąć te odniesienia do klucza obcego przed usunięciem klucza podstawowego.
Po usunięciu klucza podstawowego MySQL automatycznie tworzy wewnętrznie inny klucz podstawowy, co jest kosztowną operacją.
UNIKALNY indeks klucza:
Podobnie jak klucze podstawowe, unikalne klucze mogą również jednoznacznie identyfikować rekordy z jedną różnicą — kolumna unikalnych kluczy może zawierać null wartości.
W przeciwieństwie do innych serwerów baz danych, w MySQL unikalna kolumna klucza może mieć tyle null wartości jak to możliwe. W standardzie SQL null oznacza niezdefiniowaną wartość. Więc jeśli MySQL ma zawierać tylko jeden null wartości w unikalnej kolumnie klucza, należy założyć, że wszystkie wartości null są takie same.
Ale logicznie nie jest to poprawne, ponieważ null oznacza niezdefiniowane — a niezdefiniowane wartości nie mogą być ze sobą porównywane, taka jest natura null . Ponieważ MySQL nie może potwierdzić, jeśli wszystkie null s oznacza to samo, pozwala na wiele null wartości w kolumnie.
Poniższe polecenie pokazuje, jak utworzyć unikalny indeks klucza w MySQL:
CREATE UNIQUE INDEX unique_idx_1 ON index_demo (pan_no);
Indeks złożony:
MySQL umożliwia definiowanie indeksów na wielu kolumnach, do 16 kolumn. Ten indeks nazywa się indeksem wielokolumnowym / złożonym / złożonym.
Załóżmy, że mamy indeks zdefiniowany na 4 kolumnach — col1 , col2 , col3 , col4 . Dzięki indeksowi złożonemu mamy możliwość wyszukiwania w col1 , (col1, col2) , (col1, col2, col3) , (col1, col2, col3, col4) . Możemy więc użyć dowolnego prefiksu po lewej stronie indeksowanych kolumn, ale nie możemy pominąć kolumny ze środka i użyć jej w ten sposób — (col1, col3) lub (col1, col2, col4) lub col3 lub col4 itp. To są nieprawidłowe kombinacje.
Poniższe polecenia tworzą 2 złożone indeksy w naszej tabeli:
CREATE INDEX composite_index_1 ON index_demo (phone_no, name, age);
CREATE INDEX composite_index_2 ON index_demo (pan_no, name, age);
Jeśli masz zapytania zawierające WHERE klauzula na wielu kolumnach, napisz klauzulę w kolejności kolumn indeksu złożonego. Indeks przyniesie korzyści temu zapytaniu. W rzeczywistości, decydując o kolumnach dla indeksu złożonego, możesz analizować różne przypadki użycia swojego systemu i spróbować ustalić kolejność kolumn, która będzie korzystna dla większości przypadków użycia.
Indeksy złożone mogą pomóc w JOIN &SELECT zapytania. Przykład:w następującym SELECT * zapytanie, composite_index_2 jest używany.

Gdy zdefiniowanych jest kilka indeksów, optymalizator zapytań MySQL wybiera ten indeks, który eliminuje największą liczbę wierszy lub skanuje jak najmniej wierszy, aby uzyskać lepszą wydajność.
Dlaczego używamy złożonych indeksów ? Dlaczego nie zdefiniować wielu wskaźników wtórnych w kolumnach, które nas interesują?
MySQL używa tylko jednego indeksu na tabelę na zapytanie, z wyjątkiem UNION. (W UNION każde logiczne zapytanie jest uruchamiane oddzielnie, a wyniki są scalane). Tak więc zdefiniowanie wielu indeksów w wielu kolumnach nie gwarantuje, że te indeksy zostaną użyte, nawet jeśli są częścią zapytania.
MySQL utrzymuje coś, co nazywa się statystykami indeksów, które pomagają MySQL w wywnioskowaniu, jak dane wyglądają w systemie. Statystyki indeksów są jednak uogólnieniem, ale na podstawie tych metadanych MySQL decyduje, który indeks jest odpowiedni dla bieżącego zapytania.
Jak działa indeks złożony?
Kolumny używane w indeksach złożonych są łączone razem, a te połączone klucze są przechowywane w kolejności posortowanej przy użyciu drzewa B+. Podczas wyszukiwania konkatenacja kluczy wyszukiwania jest dopasowywana do kluczy indeksu złożonego. Następnie, jeśli wystąpi jakakolwiek niezgodność między kolejnością kluczy wyszukiwania a kolejnością kolumn indeksu złożonego, nie można użyć indeksu.
W naszym przykładzie dla następującego rekordu złożony klucz indeksu jest tworzony przez połączenie pan_no , name , age — HJKXS9086Wkousik28 .
+--------+------+------------+------------+
name
age
pan_no
phone_no
+--------+------+------------+------------+
kousik
28
HJKXS9086W
9090909090Jak określić, czy potrzebny jest indeks złożony:
- Najpierw przeanalizuj swoje zapytania zgodnie z przypadkami użycia. Jeśli zauważysz, że pewne pola pojawiają się razem w wielu zapytaniach, możesz rozważyć utworzenie indeksu złożonego.
- Jeśli tworzysz indeks w
col1&indeks złożony w (col1,col2), wtedy tylko indeks złożony powinien być w porządku.col1sam może być obsługiwany przez sam indeks złożony, ponieważ jest to prefiks po lewej stronie indeksu. - Rozważ kardynalność. Jeśli kolumny użyte w indeksie złożonym mają razem wysoką kardynalność, są dobrymi kandydatami do indeksu złożonego.
Indeks pokrycia:
Indeks pokrywający to specjalny rodzaj indeksu złożonego, w którym wszystkie kolumny określone w zapytaniu gdzieś istnieją w indeksie. Tak więc optymalizator zapytań nie musi trafiać do bazy danych, aby uzyskać dane — raczej pobiera wynik z samego indeksu. Przykład:zdefiniowaliśmy już indeks złożony na (pan_no, name, age) , więc teraz rozważ następujące zapytanie:
SELECT age FROM index_demo WHERE pan_no = 'HJKXS9086W' AND name = 'kousik'
Kolumny wymienione w SELECT &WHERE klauzule są częścią indeksu złożonego. Tak więc w tym przypadku możemy faktycznie uzyskać wartość age kolumna z samego indeksu złożonego. Zobaczmy, co EXPLAIN polecenie pokazuje dla tego zapytania:
EXPLAIN FORMAT=JSON SELECT age FROM index_demo WHERE pan_no = 'HJKXS9086W' AND name = '111kousik1';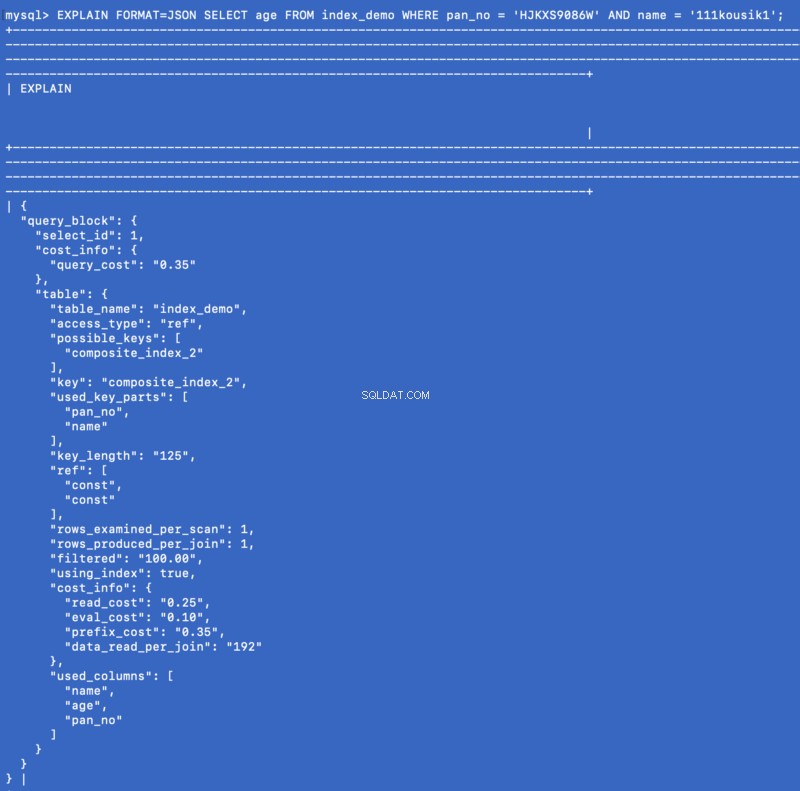
W powyższej odpowiedzi zauważ, że jest klucz — using_index który jest ustawiony na true co oznacza, że indeks pokrycia został użyty do odpowiedzi na zapytanie.
Nie wiem, jak bardzo indeksy pokrywające są doceniane w środowiskach produkcyjnych, ale najwyraźniej wydaje się to dobrą optymalizacją w przypadku, gdy zapytanie pasuje do rachunku.
Indeks częściowy:
Wiemy już, że indeksy przyspieszają nasze zapytania kosztem miejsca. Im więcej masz indeksów, tym większe zapotrzebowanie na miejsce. Stworzyliśmy już indeks o nazwie secondary_idx_1 w kolumnie name . Kolumna name może zawierać duże wartości o dowolnej długości. Również w indeksie metadane lokalizatorów wierszy lub wskaźników wierszy mają swój własny rozmiar. Ogólnie rzecz biorąc, indeks może mieć duże obciążenie pamięci masowej i pamięci.
W MySQL możliwe jest również utworzenie indeksu na pierwszych kilku bajtach danych. Przykład:poniższe polecenie tworzy indeks na pierwszych 4 bajtach nazwy. Chociaż ta metoda zmniejsza obciążenie pamięci o pewną ilość, indeks nie może wyeliminować wielu wierszy, ponieważ w tym przykładzie pierwsze 4 bajty mogą być wspólne dla wielu nazw. Zwykle ten rodzaj indeksowania prefiksów jest obsługiwany w CHAR ,VARCHAR , BINARY , VARBINARY typ kolumn.
CREATE INDEX secondary_index_1 ON index_demo (name(4));Co dzieje się pod maską, gdy definiujemy indeks?
Uruchommy SHOW EXTENDED polecenie ponownie:
SHOW EXTENDED INDEXES FROM index_demo;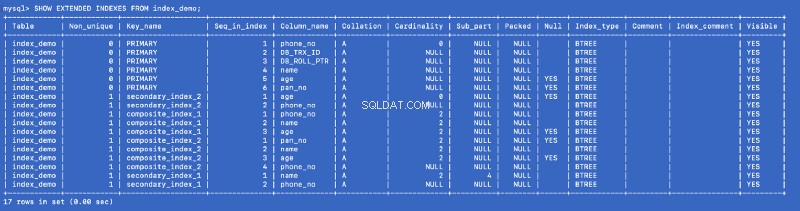
Zdefiniowaliśmy secondary_index_1 na name , ale MySQL utworzył indeks złożony na (name , phone_no ) gdzie phone_no to kolumna klucza podstawowego. Stworzyliśmy secondary_index_2 na age &MySQL utworzył złożony indeks w dniu (age , phone_no ). Stworzyliśmy composite_index_2 włączone (pan_no , name , age ) &MySQL utworzył złożony indeks na (pan_no , name , age , phone_no ). Indeks złożony composite_index_1 ma już phone_no jako jego część.
Niezależnie od tego, jaki indeks utworzymy, MySQL w tle tworzy zapasowy indeks złożony, który z kolei wskazuje na klucz podstawowy. Oznacza to, że klucz podstawowy jest obywatelem pierwszej klasy w świecie indeksowania MySQL. It also proves that all the indexes are backed by a copy of the primary index —but I am not sure whether a single copy of the primary index is shared or different copies are used for different indexes.
There are many other indices as well like Spatial index and Full Text Search index offered by MySQL. I have not yet experimented with those indices, so I’m not discussing them in this post.
General Indexing guidelines:
- Since indices consume extra memory, carefully decide how many &what type of index will suffice your need.
- With
DMLoperations, indices are updated, so write operations are quite costly with indexes. The more indices you have, the greater the cost. Indexes are used to make read operations faster. So if you have a system that is write heavy but not read heavy, think hard about whether you need an index or not. - Cardinality is important — cardinality means the number of distinct values in a column. If you create an index in a column that has low cardinality, that’s not going to be beneficial since the index should reduce search space. Low cardinality does not significantly reduce search space.
Example:if you create an index on a boolean (int1or0only ) type column, the index will be very skewed since cardinality is less (cardinality is 2 here). But if this boolean field can be combined with other columns to produce high cardinality, go for that index when necessary. - Indices might need some maintenance as well if old data still remains in the index. They need to be deleted otherwise memory will be hogged, so try to have a monitoring plan for your indices.
In the end, it’s extremely important to understand the different aspects of database indexing. It will help while doing low level system designing. Many real-life optimizations of our applications depend on knowledge of such intricate details. A carefully chosen index will surely help you boost up your application’s performance.
Please do clap &share with your friends &on social media if you like this article. :)
References:
- https://dev.mysql.com/doc/refman/5.7/en/innodb-index-types.html
- https://www.quora.com/What-is-difference-between-primary-index-and-secondary-index-exactly-And-whats-advantage-of-one-over-another
- https://dev.mysql.com/doc/refman/8.0/en/create-index.html
- https://www.oreilly.com/library/view/high-performance-mysql/0596003064/ch04.html
- https://www.unofficialmysqlguide.com/covering-indexes.html
- https://dev.mysql.com/doc/refman/8.0/en/multiple-column-indexes.html
- https://dev.mysql.com/doc/refman/8.0/en/show-index.html
- https://dev.mysql.com/doc/refman/8.0/en/create-index.html