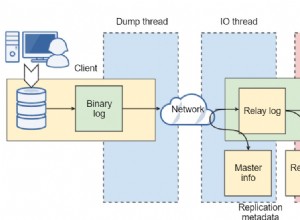
Istotnym elementem zapobiegania wszelkiego rodzaju utracie danych w każdej sytuacji jest posiadanie odpowiednich zasad tworzenia kopii zapasowych i odzyskiwania. Niezbędne jest również zapewnienie odzyskiwania danych w dowolnym momencie cyklu życia aplikacji. Zarówno MySQL, jak i MariaDB oferują rozwiązania dla tych przypadków. W tym artykule omówimy istniejące opcje i procedury, a także inne potencjalne opcje tworzenia kopii zapasowych dla MySQL i MariaDB.
Strategie tworzenia kopii zapasowych
Ponieważ dane są najważniejszą częścią każdej aplikacji, ochrona ich integralności ma kluczowe znaczenie dla przetrwania w bitwie o byt. Każde zakłócenie dostępności lub integralności danych w dowolnym momencie może poważnie zaszkodzić aplikacji i świadczonej przez nią firmie/usługi.
Aby zapewnić pomyślny przepływ pracy aplikacji i ciągłość biznesową, należy wdrożyć odpowiednie zasady tworzenia kopii zapasowych i odzyskiwania z codziennymi, tygodniowymi, miesięcznymi i rocznymi kopiami zapasowymi. Takie kopie zapasowe będą działać w krytycznych okresach, takich jak:
- przed dziennym oknem wsadowym;
- przed masowym pozyskiwaniem danych;
- przed aktualizacją aplikacji;
- cotygodniowe, miesięczne i roczne kopie zapasowe w celu spełnienia wymagań prawnych;
- lub inną zaplanowaną codzienną/cotygodniową konserwację.
Narzędzia do tworzenia kopii zapasowych
MySQL i MariaDB oferują kilka sposobów konfigurowania i wykonywania planów tworzenia kopii zapasowych i odzyskiwania. Metody te obejmują fizyczne kopie zapasowe za pomocą narzędzia MySQL Enterprise mysqlbackup , narzędzie MariaDB mariabackup lub narzędzie XtraBackup firmy Percona . Ponadto logiczne kopie zapasowe utworzone za pomocą narzędzia mysqldump firmy Mysql może się przydać. Inną opcją jest odzyskiwanie do określonego momentu za pomocą dzienników bin baz danych (dzienników transakcji) w połączeniu z narzędziami wspomnianymi wcześniej.
Możesz zasymilować odpowiednie metody w swojej strategii tworzenia kopii zapasowych, aby zmaksymalizować odzyskiwanie bazy danych w przypadku awarii lub katastrofy.
Uwaga:w MariaDB w wersji 10.4.6 symlink mysqldump nazywa się mariadb-dump . W późniejszych wersjach, w tym 10.5.2, nazwy zmieniły się ponownie – mysqldump stał się linkiem symbolicznym .
Aby zilustrować procedury, użyję narzędzia mariabackup do tworzenia fizycznych kopii zapasowych. Podstawowa funkcjonalność narzędzia jest taka sama, jak w przypadku wyżej wymienionych narzędzi, chociaż istnieją pewne niewielkie różnice unikalne dla każdego narzędzia.
Fizyczne kopie zapasowe baz danych
Fizyczne kopie zapasowe to kopie zapasowe na poziomie plików, które zapewniają szybkie metody kopiowania plików. Takie kopie zapasowe są preferowane w scenariuszach odzyskiwania po awarii, klonowaniu baz danych i/lub tworzeniu podrzędnych baz danych.
Tworząc fizyczne kopie zapasowe, możesz wybrać tworzenie pełnych lub przyrostowych kopii zapasowych. Pełne kopie zapasowe obejmują pełną kopię zapasową serwera bazy danych. Przyrostowe kopie zapasowe zapisują tylko zmiany z ostatniej pełnej lub przyrostowej kopii zapasowej.
Ważne:Rozmiar bazy danych reguluje czas tworzenia kopii zapasowej. Z tego powodu dobrą strategią tworzenia kopii zapasowych bardzo dużej bazy danych może być połączenie kopii pełnych i przyrostowych. W ten sposób oszczędzasz zarówno miejsce na kopie zapasowe, jak i całkowity czas tworzenia kopii zapasowych i odzyskiwania.
Innym momentem, który powinieneś zauważyć, jest to, że gdy odzyskujesz dane z fizycznej kopii zapasowej, musisz zatrzymać proces instancji bazy danych MySQL/MariaDB do czasu zakończenia końcowych kroków odzyskiwania.
Możesz wykonać prostą pełną fizyczną kopię zapasową w następujący sposób:
mariabackup --backup \
--target-dir=/data/backups/mariadb/D20210220 \
--user=backupuser --password=backuppasswd
–target-dir opcja informuje narzędzie do tworzenia kopii zapasowych, gdzie umieścić kopię zapasową.
W tym przykładzie zorganizowałem kopię zapasową w katalogu o nazwie RRRRMMDD gdzie przechowywana jest każda pełna kopia zapasowa (D oznacza Daily). W ten sposób mamy łatwy sposób na przywrócenie bazy danych z kopii zapasowej wykonanej w określonym dniu.
Następny przykład ilustruje wykonanie prostej przyrostowej kopii zapasowej:
mariabackup --backup \
--target-dir=/data/backups/mariadb/D20210220_inc1/ \
--incremental-basedir=/data/backups/mariadb/D20210220/ \
--user=backupuser --password=backuppasswd
Kolejna przyrostowa kopia zapasowa wyglądałaby w następujący sposób:
mariabackup --backup \
--target-dir=/data/backups/mariadb/D20210220_inc2/ \
--incremental-basedir=/data/backups/mariadb/D20210220_inc1 \
--user=backupuser --password=backuppasswd
–incremental-basedir opcja nakazuje narzędziu do tworzenia kopii zapasowych użycie poprzednio wykonanej pełnej lub przyrostowej kopii zapasowej jako punktu wyjścia do tworzenia przyrostowych plików delta dla bieżącej kopii zapasowej. W ten sposób tworzy łańcuch składający się z jednej pełnej kopii zapasowej z kolejnymi kopiami przyrostowymi. Razem tworzą jedną kopię zapasową, którą można przywrócić w razie potrzeby.
Teraz dowiedzmy się, jak nazywa się fizyczny plik bazy danych, w którym przechowywane są wszystkie dane katalogowe. Baza danych znajdująca się na kontrolerach domeny to usługa Active Directory. Ten katalog służy do zarządzania użytkownikami, danymi itp. Rdzeniem usługi Active Directory jest plik bazy danych NTDS.DIT, który składa się z łączy, deskryptora zabezpieczeń i tabel danych. Wszystkie dane katalogowe są przechowywane w tym fizycznym pliku bazy danych.
Konieczne jest rozróżnienie między plikami fizycznymi i logicznymi. Rzeczywiste dane systemowe znajdują się w plikach fizycznych, podczas gdy pliki logiczne zawierają opis rekordów przechowywanych w plikach fizycznych.
Zadanie przywrócenia bazy danych MySQL z fizycznych plików może być czasami trudne. mysqldump w tym przypadku pomocne może okazać się polecenie. Omówimy ten temat dalej.
Kopie zapasowe logicznej bazy danych
Logiczne kopie zapasowe są tworzone za pomocą mysqldump narzędzie. Ta metoda tworzenia kopii zapasowej jest bardziej elastyczna niż fizyczna kopia zapasowa. Składa się ze wszystkich instrukcji DML i/lub DDL SQL niezbędnych do utworzenia spójnej kopii zapasowej, łączącej wszystkie zatwierdzone dane i zmiany wprowadzone przed i podczas tworzenia kopii zapasowej. Jeśli chcesz dowiedzieć się więcej o tworzeniu kopii zapasowych i przywracaniu wszystkich baz danych, możesz przeczytać ten artykuł.
Logiczna kopia zapasowa może być pojedynczym plikiem lub wieloma plikami (utworzonymi za pomocą określonego skryptu). Co więcej, możesz przywrócić strukturę i/lub dane bez zamykania instancji (procesu) MySQL/MariaDB. W związku z tym logiczne kopie zapasowe są wykonywane na poziomie bazy danych i/lub tabeli, podczas gdy fizyczne kopie zapasowe są na poziomie systemu plików (katalogów i plików).
Należy również pamiętać, że logiczne kopie zapasowe to wyłącznie pełne kopie zapasowe obrazów zamierzonych baz danych i/lub tabel.
Tworzenie logicznej kopii zapasowej całej instancji MySQL/MariaDB znajduje się poniżej:
mysqldump --all-databases --single-transaction \
--quick --lock-tables=false \
-u backupuser -p backuppasswd \
> /data/backups/mariadb/logical/D20210220/full-backup-$(date +'%Y%m%d_%H%M%S').sql
Zwróć uwagę, że fizyczne kopie zapasowe i logiczne kopie zapasowe są specjalnie rozróżniane w systemie plików do celów zarządzania kopiami zapasowymi.
W przeciwieństwie do poprzedniego przykładu, logiczna kopia zapasowa pojedynczej bazy danych (schematu) jest tworzona w następujący sposób:
mysqldump empdb --single-transaction \
--quick --lock-tables=false \
-u backupuser -p backuppasswd \
> /data/backups/mariadb/logical/D20210220/empdb-full-backup-$(date +'%Y%m%d_%H%M%S').sql
Na koniec, aby utworzyć logiczną kopię zapasową pojedynczej tabeli w bazie danych, dodaj nazwę tabeli po bazie danych:
mysqldump empdb departments --single-transaction \
--quick --lock-tables=false \
-u backupuser -p backuppasswd \
> /data/backups/mariadb/logical/D20210220/empdb-departments-full-backup-$(date +'%Y%m%d_%H%M%S').sql
Kiedy musisz edytować i dodać instrukcje DROP DATABASE lub DROP TABLE do scenariusza odzyskiwania, praca z dużymi plikami kopii zapasowych może mieć ograniczający wpływ na edytory tekstu do tego stopnia, że się zatkają.
W takich przypadkach rozważ dodanie innych opcji, takich jak –add-drop-database i/lub –add-drop-table aby uwzględnić te instrukcje DROP w kopii zapasowej. W innych sytuacjach możesz chcieć wykluczyć te stwierdzenia i zastąpić je tabelą –skip-add-drop-table opcja polecenia.
Możesz jednak również tworzyć kopie zapasowe tylko danych lub tylko DDL za pomocą –no-create-info lub –brak danych opcje. Oddzielne kopie zapasowe danych i struktury mogą być dobrym wyborem w niektórych scenariuszach odzyskiwania, zwłaszcza gdy do utworzenia pustej sklonowanej bazy danych i/lub jej tabel potrzebna jest tylko struktura DDL.
Tworzenie kopii zapasowej bazy danych za pomocą migawek dysków
W miarę wzrostu danych może być konieczne zorganizowanie ich na kilku dyskach i/lub systemach plików. Oprócz powodów związanych z wydajnością, ponieważ wejścia/wyjścia są rozłożone na wiele dysków/systemów plików, należy upewnić się, że skuteczne strategie tworzenia kopii zapasowych i odzyskiwania obejmują możliwości tworzenia migawek dysku i systemu plików.
Zacznij od zaprojektowania i zbudowania układu systemu plików, w którym znajduje się każda baza danych, grupa tabel i indeksy. Następnie uporządkuj swoje tabele i skonfiguruj system baz danych. Powinny one znajdować się w jednym katalogu:
innodb_home_dir = /<path where your InnoDB tables will reside>Możesz też użyć DATA_DIRECTORY i INDEX_DIRECTORY opcje w UTWÓRZ oświadczenie table, aby dystrybuować je oddzielnie do różnych lokalizacji systemu plików.
W przypadku InnoDB upewnij się, że używasz file_per_table =ON (domyślnie ON w najnowszych wersjach). Ostrożnie wybierz ścieżkę do tabel InnoDB podczas ich tworzenia. Nie można zmienić ścieżki bez upuszczenia i ponownego utworzenia tabeli.
Pomocne jest posiadanie odpowiednich systemów plików z wbudowanymi funkcjami tworzenia migawek, np. XFS i ZFS w systemie Linux. Zwróć uwagę, że tworzenie kopii zapasowych migawek jest podobne do tworzenia kopii fizycznych, ale ma swoją specyfikę. Wymaga zatrzymania procesu pisania (FLUSH z READ LOCK lub podobne — zobacz ETAP ZAPASOWY w dokumentacji online MariaDB) przed wykonaniem migawki i zwolnieniem BLOKADA natychmiast po wykonaniu migawki. Konieczne jest zapewnienie spójności danych.
Należy wziąć pod uwagę kopie zapasowe migawek i używać ich w scenariuszach odzyskiwania po awarii. Nadają się jednak również do klonowania instancji baz danych.
Strategie odzyskiwania
Odzyskiwanie z fizycznych kopii zapasowych

Wcześniej opisaliśmy fizyczne kroki tworzenia kopii zapasowej. W ten sposób można zbudować łańcuch pełnych kopii zapasowych lub łańcuch pełnych i przyrostowych kopii zapasowych. Ta druga opcja oznacza, że pełna kopia zapasowa, po której następuje kolejna przyrostowa kopia zapasowa, ma punkt zero w przypadku awarii.
Na przykład administrator baz danych wykonuje pełne kopie zapasowe w niedziele i przyrostowe kopie zapasowe w inne dni. Błąd występuje po utworzeniu przyrostowej kopii zapasowej w środę. Dlatego muszą przywrócić bazę danych. W takich okolicznościach nasz administrator baz danych musi korzystać z pełnej kopii zapasowej wykonanej w niedzielę oraz przyrostowej kopii zapasowej wykonanej w poniedziałek, wtorek i środę. Gdyby codziennie były pełne kopie zapasowe, wystarczyłoby przywrócić środową kopię zapasową.
Aby odzyskać „najbliższą” kopię zapasową po awarii, niezależnie od tego, czy jest to pełna, czy przyrostowa kopia zapasowa, musisz upewnić się, że WSZYSTKIE pliki kopii zapasowych są spójne w określonym punkcie w czasie z godziną najbliższego zakończenia kopii zapasowej. W przeciwnym razie silnik InnoDB odrzuci dane, uznając je za uszkodzone.
Inną kluczową kwestią jest to, że podczas przygotowywania kopii zapasowych skopiuj odpowiednie pełne kopie zapasowe do innej lokalizacji przed zastosowaniem kroków w celu zapewnienia spójności punktu w czasie. W ten sposób zachowasz pierwotny stan kopii zapasowej, który może być przydatny później. Zdecydowanie zalecam stosowanie tego podejścia.
Aby przygotować pełną kopię zapasową, wybierz tę najbliższą awarii, skopiuj ją do preferowanej lokalizacji i wykonaj następujące polecenie:
mariabackup --prepare \
--target-dir=data/backups/mariadb/COPY_D20210220
Aby przywrócić do najbliższej przyrostowej kopii zapasowej, przygotuj kopię najbliższej pełnej kopii zapasowej i dodaj wszystkie odpowiednie przyrostowe kopie zapasowe w kolejnej kolejności . Przywrócony obraz bazy danych powinien wyglądać następująco:

Osiągamy to, wykonując przygotowanie polecenie dla każdej przyrostowej kopii zapasowej, jak pokazano poniżej:
mariabackup --prepare \
--target-dir=/data/backups/mariadb/COPY_D20210220 \
--incremental-dir=/data/backups/mariadb/D20210220_INC#
Po przygotowaniu kopii zapasowej musimy wyłączyć instancję bazy danych (proces). Ponadto musimy opróżnić katalog bazy danych przed zakończeniem procesu przywracania. Możesz wydać polecenie za pomocą –kopii zwrotnej opcja
mariabackup --copy-back \
--target-dir=data/backups/mariadb/COPY_D20210220
lub za pomocą –przesuń do tyłu opcja:
mariabackup --move-back \
--target-dir=data/backups/mariadb/COPY_D20210220
To ostatnie polecenie przenosi skopiowany katalog do katalogu bazy danych. Kopiowanie oryginalnej kopii zapasowej do innej lokalizacji to mądry wybór. W przeciwnym razie kopia zapasowa zostanie utracona, ponieważ nie będzie można jej użyć w innych sytuacjach i scenariuszach.
Ostatnim krokiem przed uruchomieniem instancji bazy danych jest dostosowanie własności plików do użytkownika i grupy właściciela procesu. Zazwyczaj jest to MySQL.
Odzyskiwanie z logicznych kopii zapasowych
Dość często pomijamy jeden kluczowy punkt podczas odzyskiwania baz danych i/lub tabel przy użyciu logicznych kopii zapasowych. Ten punkt ustawia max_allowed_packet rozmiar sesji (może rozsądniej ustawić go globalnie) do maksymalnej wartości 1073741824. Należy zadbać o to, aby duże bufory i instrukcje INSERT zmieściły się w jednym pakiecie pomiędzy klientem a serwerem. Powinno to skrócić czas odzyskiwania.
Innym kluczowym aspektem podczas tworzenia kopii zapasowej jest uwzględnienie lub wykluczenie instrukcji DROP, jak wspomniano wcześniej. Potrzebujemy go, aby zapewnić płynne działanie procesu przywracania kopii zapasowej. Mając to na uwadze, użyj poniższego kodu, aby wykonać przywracanie kopii zapasowej:
mysql -u backupuser -p backuppasswd < /data/backups/mariadb/logical/D20210220/emp-full-backup-20210228_153726.sqlJeśli nie masz żadnej bazy danych zawartej w kopii zapasowej, tak jak w przypadku pojedynczych kopii zapasowych baz danych, lub musisz przekierować przywracanie do innej bazy danych, użyj innego kodu:
mysql -u backupuser -p backuppasswd newemp < /data/backups/mariadb/logical/D20210220/emp-full-backup-20210228_153726.sqlOdzyskiwanie za pomocą migawek dysków
Aby odzyskać z migawki dysku zawsze zacznij odzapewnienia że system bazy danych jest wyłączony przed proces odzyskiwania jest wykonywany . Każda próba odzyskania działającej bazy danych przy użyciu migawki dysku spowoduje niespójność danych i, co bardziej prawdopodobne, uszkodzenie danych.
Odzyskiwanie do określonego momentu
Odzyskiwanie do punktu w czasie (PITR) jest, jak sama nazwa wskazuje, metodą odzyskiwania baz danych i tabel jak najbliżej czasu przed awarią. Lub, jeśli codzienny proces wsadowy nie powiódł się i musi zostać wykonany ponownie, masz również jedyną opcję – wykonaj kopię zapasową PITR.
Ważne jest, aby włączyć dziennik bin bazy danych i ustawić format dziennika bin na rejestrowanie oparte na instrukcjach, wierszowe lub mieszane, w zależności od typu obciążenia bazy danych. Ponadto może być konieczne włączenie kompresji za pomocą log_bin_compress =ON (domyślnie OFF) aby zaoszczędzić miejsce na dysku.
Ponieważ bin-log jest dziennikiem transakcji i jest tworzony w sekwencji, ważne jest, aby wykonać kopię zapasową wszystkich plików dziennika. Jeśli chodzi o proces PITR, jest to niemożliwe bez plików dziennika. Poza tym konserwacja i cykl życia bin-log powinny być zgodne z cyklem życia wszystkich pełnych i przyrostowych kopii zapasowych. Dlatego upewnij się, że usuwasz tylko te dzienniki, które są starsze niż najstarsza kopia zapasowa w zasadach tworzenia kopii zapasowych.
Dzienniki binarne można wyczyścić na dwa sposoby. Po pierwsze, należy zadeklarować najbliższą nazwę dziennika bin najstarszej kopii zapasowej, jak pokazano w poniższym poleceniu czyszczenia:
PURGE BINARY LOGS TO 'mariadb-bin.000063';Po drugie, należy zadeklarować datę najstarszej kopii zapasowej przechowywanej w poleceniu czyszczenia:
PURGE BINARY LOGS BEFORE '2021-01-20 00:00:00';Aby przygotować się do wyzdrowienia, musimy odzyskać wszystkie niezbędne stwierdzenia, aby odtworzyć je do niezbędnego punktu w czasie. Zbierz wszystkie dzienniki pojemników dostępne od momentu rozpoczęcia tworzenia kopii zapasowej do momentu, w którym odzyskujesz.
Zacznij od sprawdzenia listy dzienników od czasu zakończenia tworzenia kopii zapasowej do czasu PITR:
mysqlbinlog --start-datetime=<backup end datetime> --stop-datetime=<PITR datetime> \
<list of binlogs> \
> temporary_file.sql
Następnie sprawdź pliki tymczasowe, aby znaleźć dokładne pozycje dziennika, które chcesz zastosować i użyć. Są to –pozycja startowa i –pozycja stop które ustawiają dokładne pozycje w poleceniu i ponownie wykonują mysqlbinlog polecenie:
mysqlbinlog --start-position=<exact log start position> --stop-position=<exact log position to stop on> \
<list of binlogs> \
> final_temporary_PITR_file.sql
W tym momencie rozpoczął się proces odzyskiwania. Wykorzystuje fizyczne lub logiczne kopie zapasowe, pełne lub przyrostowe.
Zakończ odzyskiwanie, stosując plik final_temporary_PITR_file.sql używając klienta MySQL, jak pokazano poniżej:
mysql -u backupuser -p backuppasswd < final_temporary_PTR_file.sqlZakończyliśmy odzyskiwanie PITR, przywracając kopię zapasową i odtwarzane transakcje z dziennika do punktu najbliższego chwili wystąpienia awarii.
Stół warsztatowy
Do projektowania i tworzenia baz danych, testowania i konserwacji w MySQL i MariaDB możemy użyć aplikacji Windows Workbench. Działa również na Linuksie. Dzięki tej aplikacji użytkownicy mogą projektować bazy danych, przeglądać i zmieniać metadane, przesyłać dane i metadane oraz wiele więcej. Warto dodać, że możliwe jest użycie dbForge Studio dla MySQL zamiast Workbencha.
Wniosek
Podsumowując, krótko omówiliśmy i zilustrowaliśmy techniki tworzenia kopii zapasowych i odzyskiwania baz danych za pomocą narzędzi i metod dostępnych w MySQL i MariaDB.
Aby pomyślnie odzyskać system bazy danych po każdej awarii, musimy wdrożyć zarówno fizyczną, jak i logiczną kopię zapasową metody wymienione powyżej do polityk i planów, od całego systemu do poszczególnych tabel.
Aby pomyślnie przeprowadzić PITR, potrzebujemy włączonego dziennika bin i odpowiedniego zarządzania dziennikami na miejscu.
Jednak użycie tylko jednej metody tworzenia kopii zapasowych i brakujące bin-logs byłoby niewłaściwym podejściem. Może to spowodować utratę danych i zaszkodzić ciągłości biznesowej aplikacji. Dlatego połącz różne metody i zawsze dołączaj pliki dziennika do zasad tworzenia kopii zapasowych i przywracania!