Przez lata replikacja MySQL opierała się na zdarzeniach z dziennika binarnego – wszystko, co wiedział niewolnik, to dokładne zdarzenie i dokładna pozycja, którą właśnie odczytał z urządzenia głównego. Każda pojedyncza transakcja z mastera mogła zakończyć się w różnych dziennikach binarnych i na różnych pozycjach w tych dziennikach. Było to proste rozwiązanie, które miało pewne ograniczenia — bardziej złożone zmiany topologii mogą wymagać od administratora zatrzymania replikacji na zaangażowanych hostach. Lub te zmiany mogą powodować inne problemy, np. slave nie może zostać przeniesiony w dół łańcucha replikacji bez czasochłonnego procesu odbudowy (nie mogliśmy łatwo zmienić replikacji z A -> B -> C na A -> C -> B bez zatrzymywania replikacji na obu B i C). Wszyscy musieliśmy obejść te ograniczenia, marząc o globalnym identyfikatorze transakcji.
GTID został wprowadzony wraz z MySQL 5.6 i przyniósł kilka poważnych zmian w sposobie działania MySQL. Przede wszystkim każda transakcja posiada unikalny identyfikator, który identyfikuje ją w ten sam sposób na każdym serwerze. Nie jest już ważne, w której pozycji dziennika binarnego zarejestrowano transakcję, wystarczy tylko GTID:„966073f3-b6a4-11e4-af2c-080027880ca6:4”. GTID składa się z dwóch części - unikalnego identyfikatora serwera, na którym transakcja została wykonana po raz pierwszy, oraz numeru sekwencyjnego. W powyższym przykładzie widzimy, że transakcja została wykonana przez serwer o identyfikatorze server_uuid o wartości „966073f3-b6a4-11e4-af2c-080027880ca6” i jest tam wykonana czwarta transakcja. Ta informacja wystarczy do przeprowadzenia skomplikowanych zmian topologii - MySQL wie, które transakcje zostały wykonane i dzięki temu wie, które transakcje należy wykonać w następnej kolejności. Zapomnij o dziennikach binarnych, wszystko jest w GTID.
Gdzie więc znaleźć identyfikatory GTID? Znajdziesz je w dwóch miejscach. Na urządzeniu podrzędnym w „pokaż status urządzenia podrzędnego” znajdziesz dwie kolumny:Retrieved_Gtid_Set i Executed_Gtid_Set. Pierwsza obejmuje identyfikatory GTID, które zostały pobrane z mastera poprzez replikację, druga informuje o wszystkich transakcjach, które zostały wykonane na danym hoście - zarówno poprzez replikację, jak i wykonane lokalnie.
Łatwa konfiguracja klastra replikacji
Wdrożenie klastra replikacji MySQL jest bardzo proste w ClusterControl (możesz go wypróbować za darmo). Jedynym warunkiem wstępnym jest to, aby wszystkie hosty, na których będziesz wdrażać węzły MySQL, były dostępne z instancji ClusterControl za pomocą połączenia SSH bez hasła.
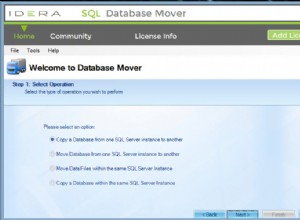
Gdy łączność jest na miejscu, możesz wdrożyć klaster, korzystając z opcji „Wdróż”. Kiedy okno kreatora jest otwarte, musisz podjąć kilka decyzji - co chcesz zrobić? Wdrożyć nowy klaster? Wdróż węzeł Postgresql lub zaimportuj istniejący klaster.
Chcemy wdrożyć nowy klaster. Zostanie nam wtedy przedstawiony następujący ekran, na którym musimy zdecydować, jaki rodzaj klastra chcemy wdrożyć. Wybierzmy replikację, a następnie przekażmy wymagane szczegóły dotyczące łączności ssh.
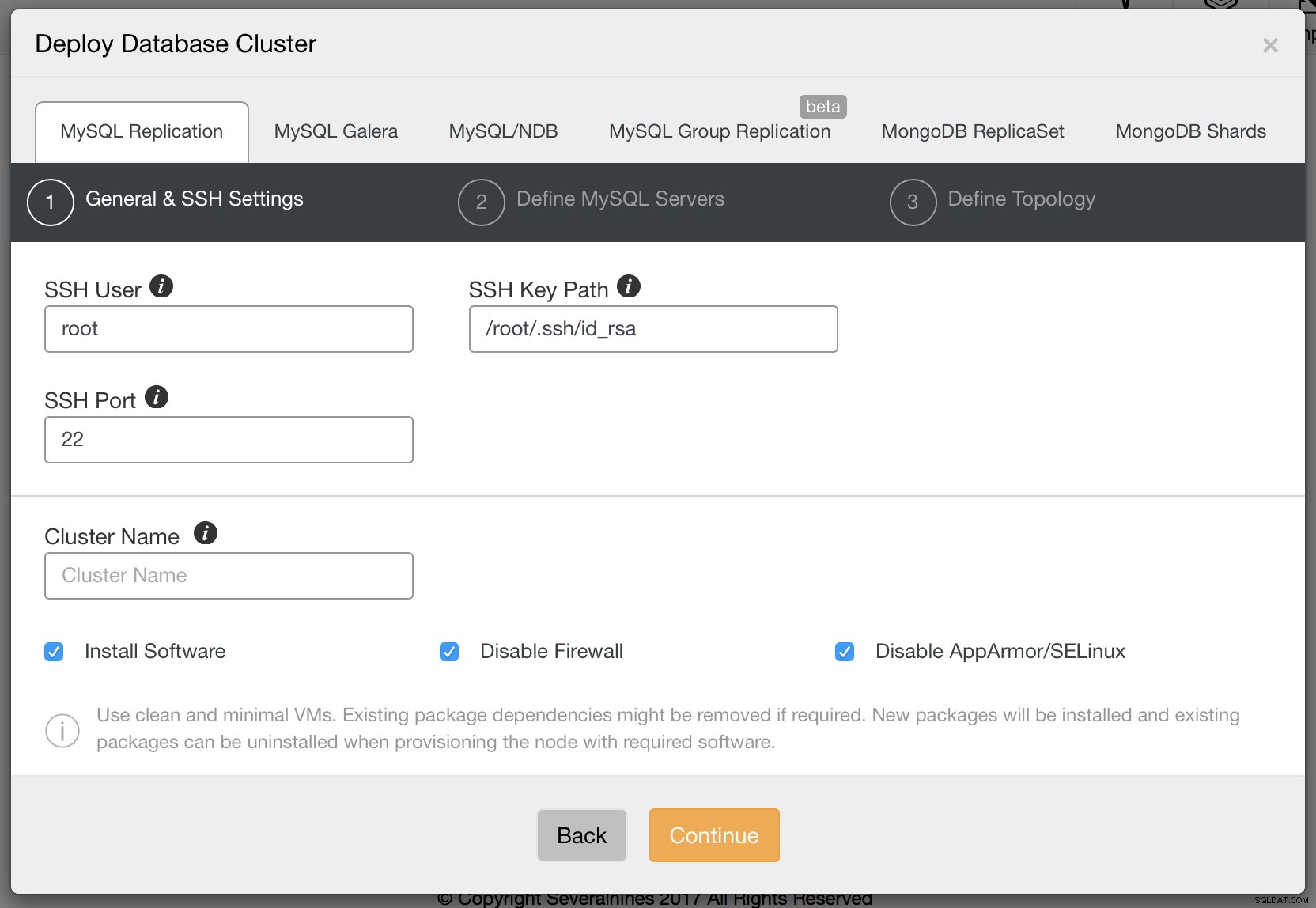
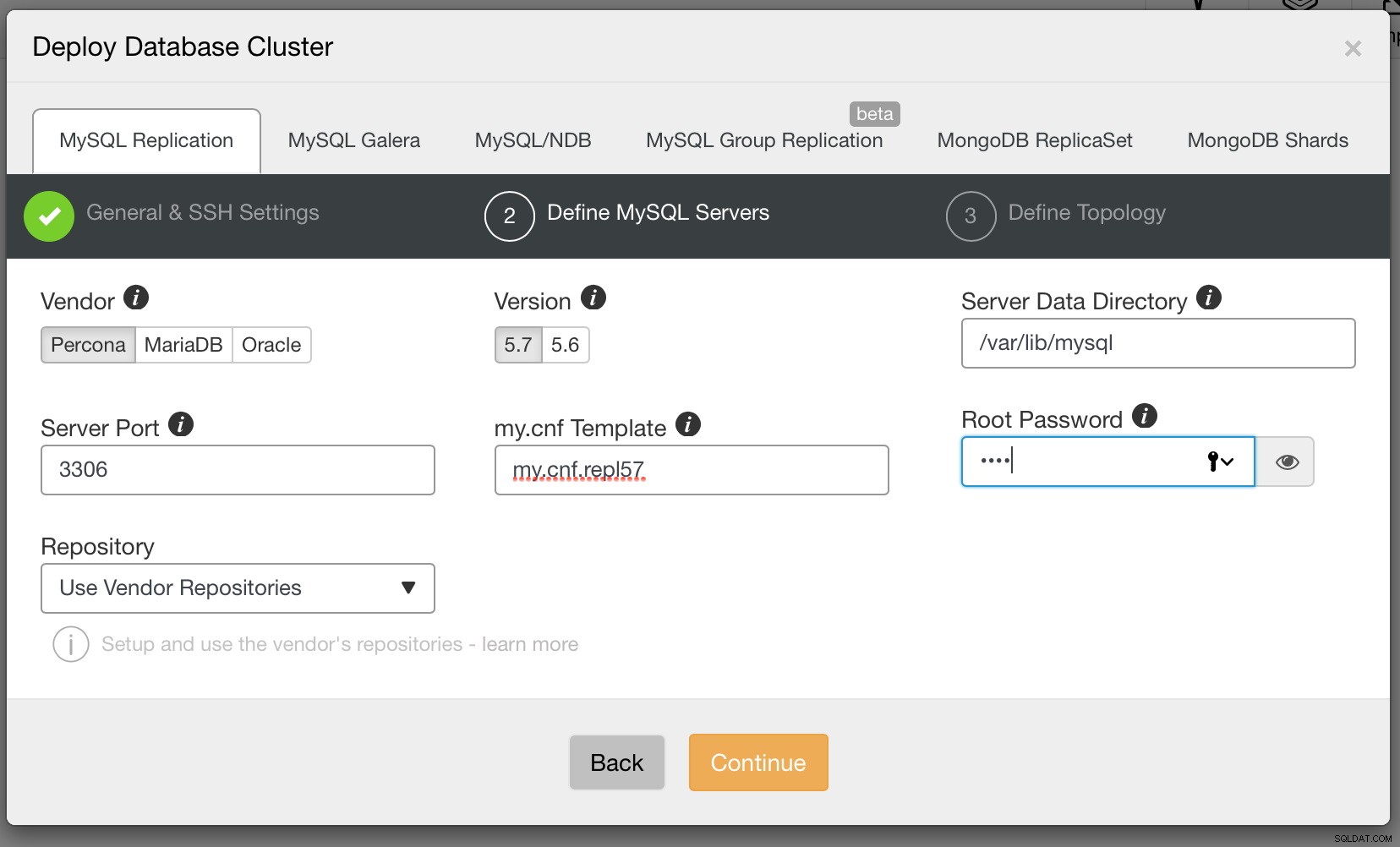
Gdy wszystko będzie gotowe, kliknij Kontynuuj. Tym razem musimy zdecydować, którego dostawcy MySQL chcemy użyć, jakiej wersji i kilku ustawień konfiguracyjnych, w tym m.in. hasła do konta root w MySQL.
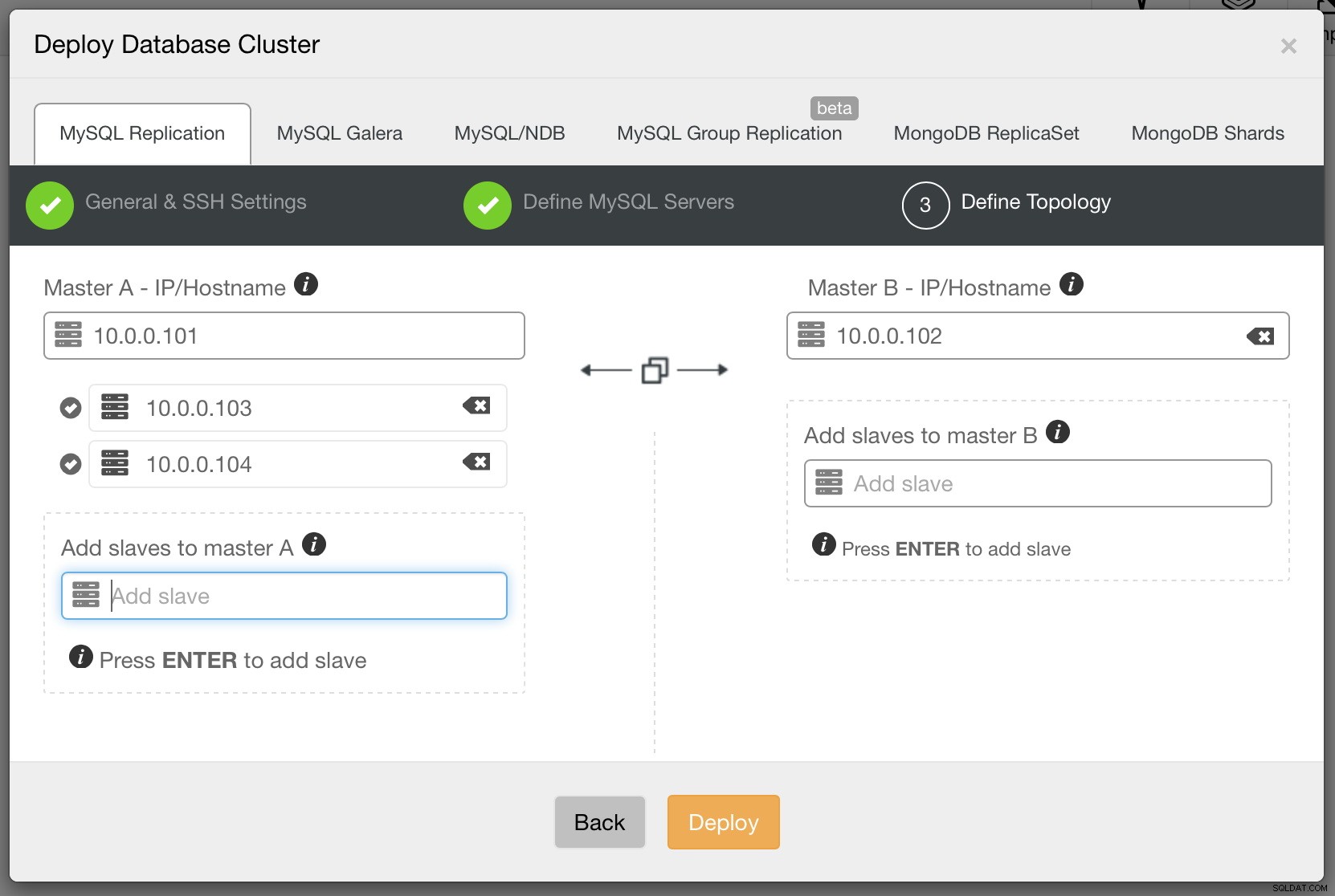
Na koniec musimy zdecydować się na topologię replikacji - możesz użyć typowej konfiguracji master - slave lub stworzyć bardziej złożoną, aktywną - standby master - parę master (+ slave'y, jeśli chcesz je dodać). Gdy będziesz gotowy, po prostu kliknij „Wdróż”, a za kilka minut powinieneś wdrożyć swój klaster.
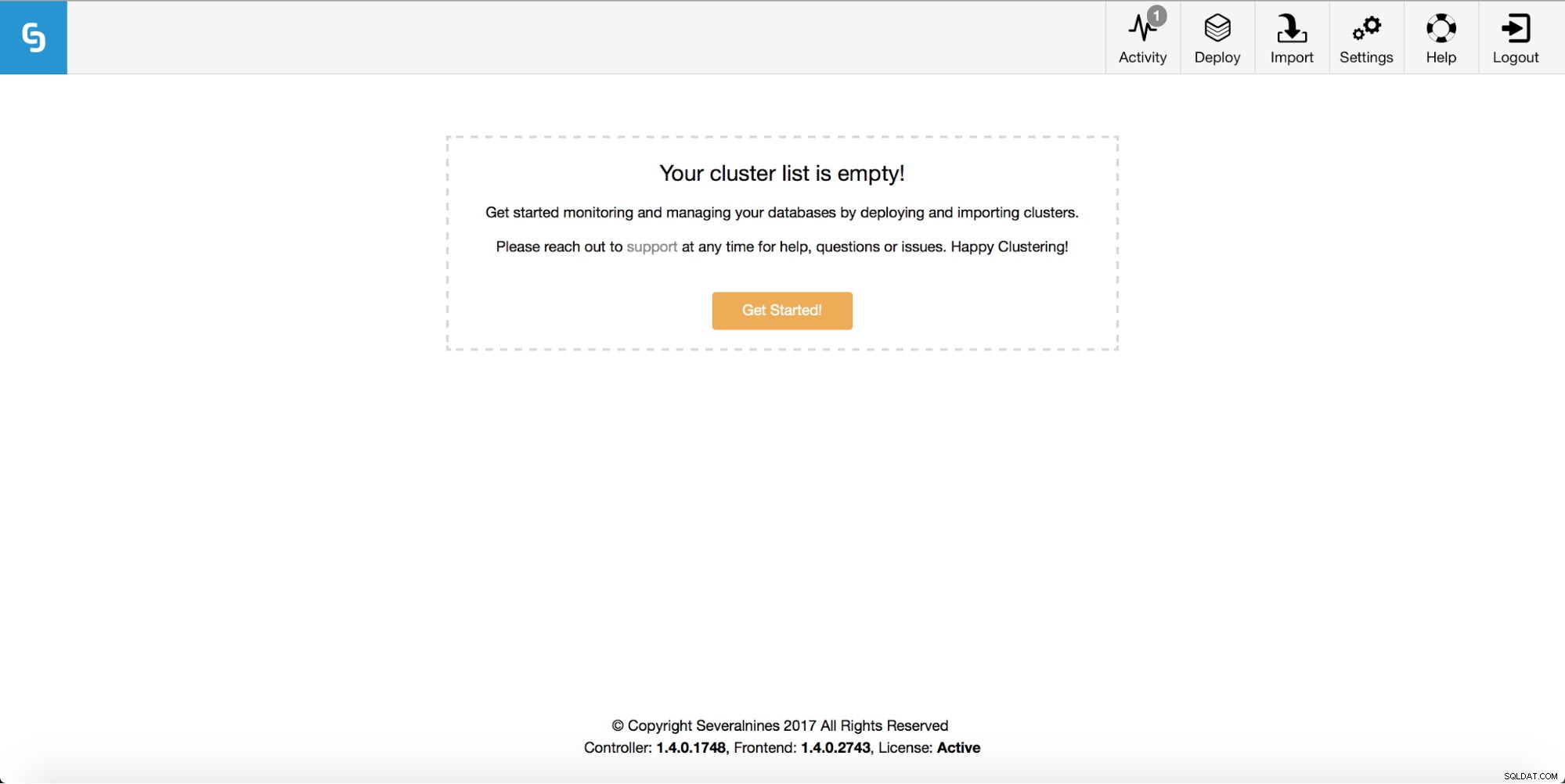
Gdy to zrobisz, zobaczysz swój klaster na liście klastrów interfejsu użytkownika ClusterControl.
Mając uruchomioną replikację, możemy przyjrzeć się bliżej działaniu GTID.
Błędne transakcje — na czym polega problem?
Jak wspomnieliśmy na początku tego postu, GTID przyniosło znaczącą zmianę w sposobie myślenia o replikacji MySQL. Chodzi o nawyki. Załóżmy, że z jakiegoś powodu aplikacja wykonała zapis na jednym z niewolników. To nie powinno się wydarzyć, ale co zaskakujące, zdarza się to cały czas. W rezultacie replikacja zatrzymuje się z błędem zduplikowanego klucza. Jest kilka sposobów na poradzenie sobie z takim problemem. Jednym z nich byłoby usunięcie naruszającego wiersza i ponowne uruchomienie replikacji. Innym byłoby pominięcie zdarzenia dziennika binarnego, a następnie ponowne uruchomienie replikacji.
STOP SLAVE SQL_THREAD; SET GLOBAL sql_slave_skip_counter = 1; START SLAVE SQL_THREAD;Oba sposoby powinny przywrócić działanie replikacji, ale mogą wprowadzać dryf danych, dlatego należy pamiętać, że po takim zdarzeniu należy sprawdzić spójność modułu podrzędnego (w tym przypadku dobrze działają pt-table-checksum i pt-table-sync).
Jeśli podobny problem wystąpi podczas korzystania z GTID, zauważysz pewne różnice. Usunięcie nieprawidłowego wiersza może wydawać się rozwiązaniem problemu, replikacja powinna być w stanie się rozpocząć. Druga metoda, używająca sql_slave_skip_counter, w ogóle nie zadziała - zwróci błąd. Pamiętaj, że teraz nie chodzi o zdarzenia z binlogu, chodzi o to, czy GTID jest wykonywany, czy nie.
Dlaczego usunięcie wiersza „wydaje się” tylko rozwiązać problem? Jedną z najważniejszych rzeczy, o których należy pamiętać w odniesieniu do GTID, jest to, że slave, łącząc się z masterem, sprawdza, czy nie brakuje mu transakcji, które zostały wykonane na masterze. Nazywa się to błędnymi transakcjami. Jeśli niewolnik znajdzie takie transakcje, wykona je. Załóżmy, że uruchomiliśmy następujący kod SQL, aby wyczyścić nieprawidłowy wiersz:
DELETE FROM mytable WHERE id=100;Sprawdźmy pokaż status urządzenia podrzędnego:
Master_UUID: 966073f3-b6a4-11e4-af2c-080027880ca6
Retrieved_Gtid_Set: 966073f3-b6a4-11e4-af2c-080027880ca6:1-29
Executed_Gtid_Set: 84d15910-b6a4-11e4-af2c-080027880ca6:1,
966073f3-b6a4-11e4-af2c-080027880ca6:1-29,I zobacz, skąd pochodzi 84d15910-b6a4-11e4-af2c-080027880ca6:1:
mysql> SHOW VARIABLES LIKE 'server_uuid'\G
*************************** 1. row ***************************
Variable_name: server_uuid
Value: 84d15910-b6a4-11e4-af2c-080027880ca6
1 row in set (0.00 sec)Jak widać, mamy 29 transakcji, które pochodziły od mastera, UUID 966073f3-b6a4-11e4-af2c-080027880ca6 i jedną, która została wykonana lokalnie. Powiedzmy, że w pewnym momencie przechodzimy w tryb failover i master (966073f3-b6a4-11e4-af2c-080027880ca6) staje się slave. Sprawdzi listę wykonanych numerów GTID i nie znajdzie tego:84d15910-b6a4-11e4-af2c-080027880ca6:1. W rezultacie zostanie wykonany powiązany kod SQL:
DELETE FROM mytable WHERE id=100;Nie jest to coś, czego się spodziewaliśmy… Jeśli w międzyczasie binlog zawierający tę transakcję zostanie wyczyszczony ze starego urządzenia podrzędnego, to nowe urządzenie podrzędne złoży skargę po przełączeniu awaryjnym:
Last_IO_Error: Got fatal error 1236 from master when reading data from binary log: 'The slave is connecting using CHANGE MASTER TO MASTER_AUTO_POSITION = 1, but the master has purged binary logs containing GTIDs that the slave requires.'Jak wykrywać błędne transakcje?
MySQL udostępnia dwie funkcje, które są bardzo przydatne, gdy chcesz porównać zestawy GTID na różnych hostach.
GTID_SUBSET() pobiera dwa zestawy GTID i sprawdza, czy pierwszy zestaw jest podzbiorem drugiego.
Powiedzmy, że mamy następujący stan.
Mistrz:
mysql> show master status\G
*************************** 1. row ***************************
File: binlog.000002
Position: 160205927
Binlog_Do_DB:
Binlog_Ignore_DB:
Executed_Gtid_Set: 8a6962d2-b907-11e4-bebc-080027880ca6:1-153,
9b09b44a-b907-11e4-bebd-080027880ca6:1,
ab8f5793-b907-11e4-bebd-080027880ca6:1-2
1 row in set (0.00 sec)Niewolnik:
mysql> show slave status\G
[...]
Retrieved_Gtid_Set: 8a6962d2-b907-11e4-bebc-080027880ca6:1-153,
9b09b44a-b907-11e4-bebd-080027880ca6:1
Executed_Gtid_Set: 8a6962d2-b907-11e4-bebc-080027880ca6:1-153,
9b09b44a-b907-11e4-bebd-080027880ca6:1,
ab8f5793-b907-11e4-bebd-080027880ca6:1-4Możemy sprawdzić, czy urządzenie podrzędne ma jakieś błędne transakcje, wykonując następujące polecenie SQL:
mysql> SELECT GTID_SUBSET('8a6962d2-b907-11e4-bebc-080027880ca6:1-153,ab8f5793-b907-11e4-bebd-080027880ca6:1-4', '8a6962d2-b907-11e4-bebc-080027880ca6:1-153, 9b09b44a-b907-11e4-bebd-080027880ca6:1, ab8f5793-b907-11e4-bebd-080027880ca6:1-2') as is_subset\G
*************************** 1. row ***************************
is_subset: 0
1 row in set (0.00 sec)Wygląda na to, że są błędne transakcje. Jak je identyfikujemy? Możemy użyć innej funkcji, GTID_SUBTRACT()
mysql> SELECT GTID_SUBTRACT('8a6962d2-b907-11e4-bebc-080027880ca6:1-153,ab8f5793-b907-11e4-bebd-080027880ca6:1-4', '8a6962d2-b907-11e4-bebc-080027880ca6:1-153, 9b09b44a-b907-11e4-bebd-080027880ca6:1, ab8f5793-b907-11e4-bebd-080027880ca6:1-2') as mising\G
*************************** 1. row ***************************
mising: ab8f5793-b907-11e4-bebd-080027880ca6:3-4
1 row in set (0.01 sec)Nasze brakujące numery GTID to ab8f5793-b907-11e4-bebd-080027880ca6:3-4 – te transakcje zostały wykonane na urządzeniu podrzędnym, ale nie na urządzeniu głównym.
Jak rozwiązywać problemy spowodowane błędnymi transakcjami?
Istnieją dwa sposoby - wstrzyknąć puste transakcje lub wykluczyć transakcje z historii GTID.
Aby wstrzyknąć puste transakcje, możemy użyć następującego SQL:
mysql> SET gtid_next='ab8f5793-b907-11e4-bebd-080027880ca6:3';
Query OK, 0 rows affected (0.01 sec)mysql> begin ; commit;
Query OK, 0 rows affected (0.00 sec)
Query OK, 0 rows affected (0.01 sec)mysql> SET gtid_next='ab8f5793-b907-11e4-bebd-080027880ca6:4';
Query OK, 0 rows affected (0.00 sec)mysql> begin ; commit;
Query OK, 0 rows affected (0.00 sec)
Query OK, 0 rows affected (0.01 sec)mysql> SET gtid_next=automatic;
Query OK, 0 rows affected (0.00 sec)Musi to zostać wykonane na każdym hoście w topologii replikacji, na którym nie wykonano tych identyfikatorów GTID. Jeśli master jest dostępny, możesz wstrzyknąć tam te transakcje i pozwolić im na replikację w dół łańcucha. Jeśli master nie jest dostępny (na przykład uległ awarii), te puste transakcje muszą zostać wykonane na każdym slave. Oracle opracowało narzędzie o nazwie mysqlslavetrx, które ma na celu zautomatyzowanie tego procesu.
Innym podejściem jest usunięcie identyfikatorów GTID z historii:
Zatrzymaj niewolnika:
mysql> STOP SLAVE;Drukuj Executed_Gtid_Set na urządzeniu podrzędnym:
mysql> SHOW MASTER STATUS\GZresetuj informacje GTID:
RESET MASTER;Ustaw GTID_PURGED na poprawny zestaw GTID. na podstawie danych z POKAŻ STATUS MASTER. Powinieneś wykluczyć błędne transakcje z zestawu.
SET GLOBAL GTID_PURGED='8a6962d2-b907-11e4-bebc-080027880ca6:1-153, 9b09b44a-b907-11e4-bebd-080027880ca6:1, ab8f5793-b907-11e4-bebd-080027880ca6:1-2';Uruchom urządzenie podrzędne.
mysql> START SLAVE\GW każdym przypadku powinieneś zweryfikować spójność swoich urządzeń podrzędnych za pomocą sumy kontrolnej pt-table-sync i pt-table-sync (jeśli to konieczne) - błędna transakcja może spowodować dryf danych.
Przełączanie awaryjne w ClusterControl
Począwszy od wersji 1.4, ClusterControl udoskonalił swoje procesy obsługi awaryjnej replikacji MySQL. Nadal możesz wykonać ręczny przełącznik główny, promując jednego z urządzeń podrzędnych na nadrzędny. Reszta niewolników przełączy się następnie na nowego mastera. Od wersji 1.4 ClusterControl ma również możliwość wykonania w pełni zautomatyzowanego przełączania awaryjnego w przypadku awarii urządzenia nadrzędnego. Szczegółowo omówiliśmy to w poście na blogu opisującym ClusterControl i automatyczne przełączanie awaryjne. Chcielibyśmy nadal wspomnieć o jednej funkcji, bezpośrednio związanej z tematem tego posta.
Domyślnie ClusterControl wykonuje przełączanie awaryjne w „bezpieczny sposób” — w momencie przełączania awaryjnego (lub przełączania, jeśli jest to użytkownik, który wykonał przełącznik główny), ClusterControl wybiera głównego kandydata, a następnie weryfikuje, czy ten węzeł nie zawiera żadnych błędnych transakcji co miałoby wpływ na replikację po awansie do poziomu mistrzowskiego. Jeśli zostanie wykryta błędna transakcja, ClusterControl zatrzyma proces przełączania awaryjnego, a kandydat na master nie zostanie awansowany na nowego mastera.
Jeśli chcesz mieć 100% pewność, że ClusterControl będzie promować nowego mastera, nawet jeśli zostaną wykryte pewne problemy (takie jak błędne transakcje), możesz to zrobić za pomocą ustawienia replication_stop_on_error=0 w konfiguracji cmon. Oczywiście, jak wspomnieliśmy, może to prowadzić do problemów z replikacją - urządzenia podrzędne mogą zacząć prosić o zdarzenie dziennika binarnego, które nie jest już dostępne.
Aby poradzić sobie z takimi przypadkami, dodaliśmy eksperymentalne wsparcie dla odbudowy niewolników. Jeśli ustawisz replication_auto_rebuild_slave=1 w konfiguracji cmon, a twoje urządzenie podrzędne zostanie oznaczone jako wyłączone z następującym błędem w MySQL, ClusterControl spróbuje odbudować urządzenie podrzędne przy użyciu danych z urządzenia nadrzędnego:
Podczas odczytu danych z dziennika binarnego wystąpił błąd krytyczny 1236 od urządzenia głównego:„Urządzenie podrzędne łączy się za pomocą funkcji CHANGE MASTER TO MASTER_AUTO_POSITION =1, ale urządzenie główne wyczyściło dzienniki binarne zawierające identyfikatory GTID wymagane przez urządzenie podrzędne”.
Takie ustawienie może nie zawsze być odpowiednie, ponieważ proces odbudowy spowoduje zwiększone obciążenie urządzenia głównego. Może się również zdarzyć, że Twój zbiór danych jest bardzo duży i regularna przebudowa nie jest opcją - dlatego to zachowanie jest domyślnie wyłączone.