Replikacja jest jednym z najczęstszych sposobów osiągnięcia wysokiej dostępności dla MySQL i MariaDB. Dzięki dodaniu identyfikatorów GTID stał się znacznie bardziej niezawodny i został dokładnie przetestowany przez tysiące użytkowników. Replikacja MySQL nie jest jednak właściwością „ustaw i zapomnij”, musi być monitorowana pod kątem potencjalnych problemów i utrzymywana, aby pozostała w dobrym stanie. W tym poście na blogu chcielibyśmy podzielić się kilkoma wskazówkami i poradami, jak konserwować, rozwiązywać i naprawiać problemy z replikacją MySQL.
Jak sprawdzić, czy replikacja MySQL jest w dobrym stanie?
Jest to najważniejsza umiejętność, którą musi posiadać każdy, kto zajmuje się konfiguracją replikacji MySQL. Przyjrzyjmy się, gdzie szukać informacji o stanie replikacji. Istnieje niewielka różnica między MySQL i MariaDB i o tym również omówimy.
POKAŻ STATUS SLAVE
Jest to najczęstsza metoda sprawdzania stanu replikacji na hoście podrzędnym — jest z nami od zawsze i zwykle jest to pierwsze miejsce, do którego się udajemy, jeśli spodziewamy się, że wystąpi jakiś problem z replikacją.
mysql> SHOW SLAVE STATUS\G
*************************** 1. row ***************************
Slave_IO_State: Waiting for master to send event
Master_Host: 10.0.0.101
Master_User: rpl_user
Master_Port: 3306
Connect_Retry: 10
Master_Log_File: binlog.000002
Read_Master_Log_Pos: 767658564
Relay_Log_File: relay-bin.000002
Relay_Log_Pos: 405
Relay_Master_Log_File: binlog.000002
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
Replicate_Do_DB:
Replicate_Ignore_DB:
Replicate_Do_Table:
Replicate_Ignore_Table:
Replicate_Wild_Do_Table:
Replicate_Wild_Ignore_Table:
Last_Errno: 0
Last_Error:
Skip_Counter: 0
Exec_Master_Log_Pos: 767658564
Relay_Log_Space: 606
Until_Condition: None
Until_Log_File:
Until_Log_Pos: 0
Master_SSL_Allowed: No
Master_SSL_CA_File:
Master_SSL_CA_Path:
Master_SSL_Cert:
Master_SSL_Cipher:
Master_SSL_Key:
Seconds_Behind_Master: 0
Master_SSL_Verify_Server_Cert: No
Last_IO_Errno: 0
Last_IO_Error:
Last_SQL_Errno: 0
Last_SQL_Error:
Replicate_Ignore_Server_Ids:
Master_Server_Id: 1
Master_UUID: 5d1e2227-07c6-11e7-8123-080027495a77
Master_Info_File: mysql.slave_master_info
SQL_Delay: 0
SQL_Remaining_Delay: NULL
Slave_SQL_Running_State: Slave has read all relay log; waiting for more updates
Master_Retry_Count: 86400
Master_Bind:
Last_IO_Error_Timestamp:
Last_SQL_Error_Timestamp:
Master_SSL_Crl:
Master_SSL_Crlpath:
Retrieved_Gtid_Set:
Executed_Gtid_Set: 5d1e2227-07c6-11e7-8123-080027495a77:1-394233
Auto_Position: 1
Replicate_Rewrite_DB:
Channel_Name:
Master_TLS_Version:
1 row in set (0.00 sec)Niektóre szczegóły mogą się różnić w MySQL i MariaDB, ale większość treści będzie wyglądać tak samo. Zmiany będą widoczne w sekcji GTID, ponieważ MySQL i MariaDB robią to w inny sposób. Z POKAŻ STATUS SLAVE można uzyskać pewne informacje - który master jest używany, który użytkownik i który port jest używany do połączenia się z masterem. Mamy trochę danych o aktualnej pozycji dziennika binarnego (nie jest to już tak ważne, ponieważ możemy użyć GTID i zapomnieć o binlogach) oraz o stanie wątków SQL i replikacji we/wy. Następnie możesz sprawdzić, czy i jak skonfigurowano filtrowanie. Możesz również znaleźć informacje o błędach, opóźnieniach replikacji, ustawieniach SSL i GTID. Powyższy przykład pochodzi z urządzenia podrzędnego MySQL 5.7, które jest w dobrym stanie. Rzućmy okiem na przykład, w którym replikacja jest zepsuta.
MariaDB [test]> show slave status\G
*************************** 1. row ***************************
Slave_IO_State: Waiting for master to send event
Master_Host: 10.0.0.104
Master_User: rpl_user
Master_Port: 3306
Connect_Retry: 10
Master_Log_File: binlog.000003
Read_Master_Log_Pos: 636
Relay_Log_File: relay-bin.000002
Relay_Log_Pos: 765
Relay_Master_Log_File: binlog.000003
Slave_IO_Running: Yes
Slave_SQL_Running: No
Replicate_Do_DB:
Replicate_Ignore_DB:
Replicate_Do_Table:
Replicate_Ignore_Table:
Replicate_Wild_Do_Table:
Replicate_Wild_Ignore_Table:
Last_Errno: 1032
Last_Error: Could not execute Update_rows_v1 event on table test.tab; Can't find record in 'tab', Error_code: 1032; handler error HA_ERR_KEY_NOT_FOUND; the event's master log binlog.000003, end_log_pos 609
Skip_Counter: 0
Exec_Master_Log_Pos: 480
Relay_Log_Space: 1213
Until_Condition: None
Until_Log_File:
Until_Log_Pos: 0
Master_SSL_Allowed: No
Master_SSL_CA_File:
Master_SSL_CA_Path:
Master_SSL_Cert:
Master_SSL_Cipher:
Master_SSL_Key:
Seconds_Behind_Master: NULL
Master_SSL_Verify_Server_Cert: No
Last_IO_Errno: 0
Last_IO_Error:
Last_SQL_Errno: 1032
Last_SQL_Error: Could not execute Update_rows_v1 event on table test.tab; Can't find record in 'tab', Error_code: 1032; handler error HA_ERR_KEY_NOT_FOUND; the event's master log binlog.000003, end_log_pos 609
Replicate_Ignore_Server_Ids:
Master_Server_Id: 1
Master_SSL_Crl:
Master_SSL_Crlpath:
Using_Gtid: Slave_Pos
Gtid_IO_Pos: 0-1-73243
Replicate_Do_Domain_Ids:
Replicate_Ignore_Domain_Ids:
Parallel_Mode: conservative
1 row in set (0.00 sec)Ten przykład pochodzi z MariaDB 10.1, możesz zobaczyć zmiany na dole danych wyjściowych, aby działał z MariaDB GTID. Dla nas ważny jest błąd - widać, że coś jest nie tak w wątku SQL:
Last_SQL_Error: Could not execute Update_rows_v1 event on table test.tab; Can't find record in 'tab', Error_code: 1032; handler error HA_ERR_KEY_NOT_FOUND; the event's master log binlog.000003, end_log_pos 609Ten konkretny problem omówimy później, na razie wystarczy, że zobaczysz, jak możesz sprawdzić, czy są jakieś błędy w replikacji za pomocą POKAŻ STATUS SLAVE.
Kolejną ważną informacją płynącą z SHOW SLAVE STATUS jest to, jak bardzo nasz niewolnik pozostaje w tyle. Możesz to sprawdzić w kolumnie „Seconds_Behind_Master”. Ta metryka jest szczególnie ważna do śledzenia, jeśli wiesz, że Twoja aplikacja jest wrażliwa, jeśli chodzi o nieaktualne odczyty.
W ClusterControl możesz śledzić te dane w sekcji „Przegląd”:
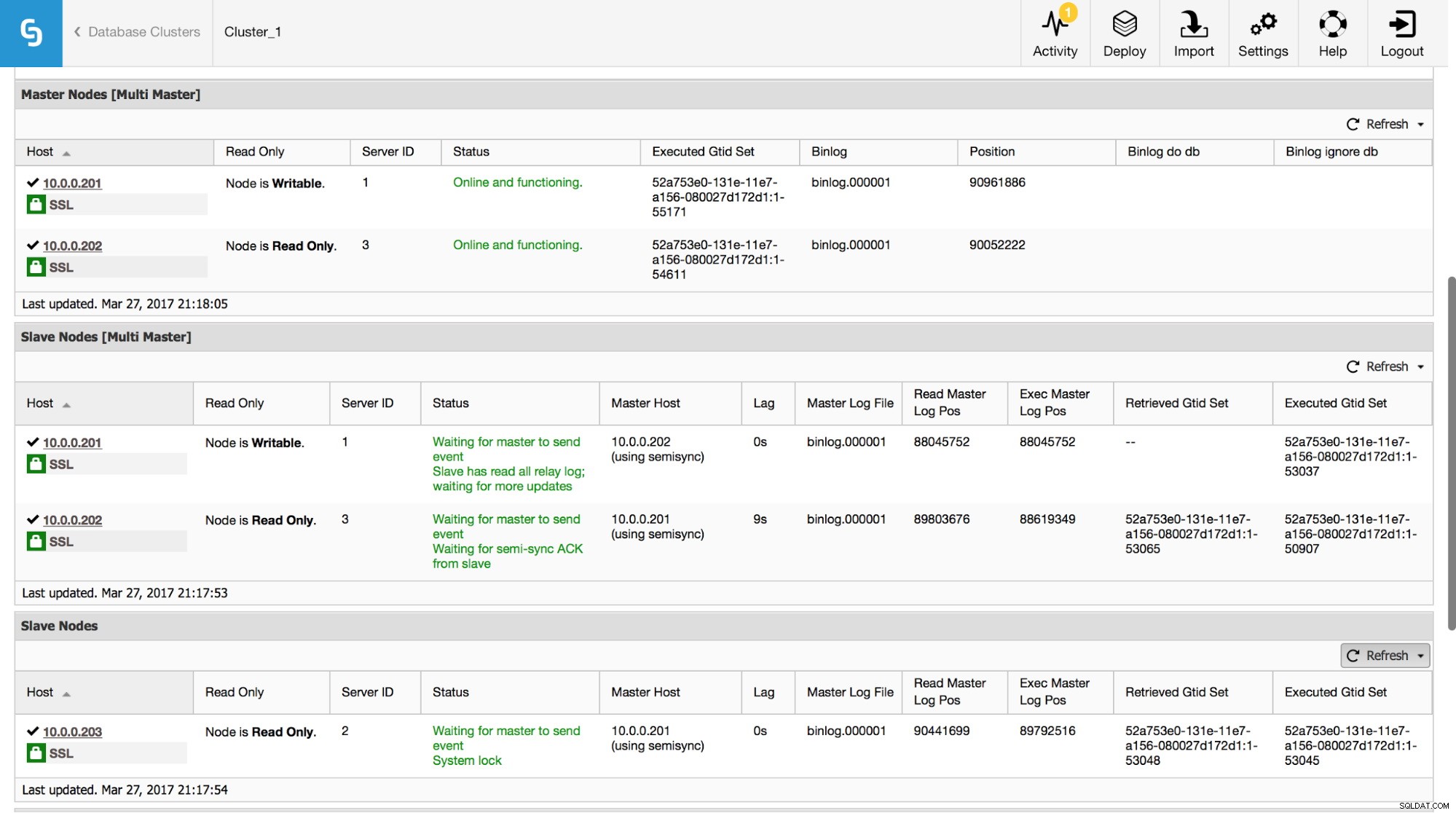
Uwidoczniliśmy wszystkie najważniejsze informacje z polecenia SHOW SLAVE STATUS. Możesz sprawdzić stan replikacji, kto jest masterem, czy występuje opóźnienie replikacji, czy nie, pozycje dziennika binarnego. Możesz także znaleźć pobrane i wykonane identyfikatory GTID.
Schemat wydajności
Kolejnym miejscem, w którym możesz szukać informacji o replikacji, jest schemat performance_schema. Dotyczy to tylko Oracle MySQL 5.7 — wcześniejsze wersje i MariaDB nie zbierają tych danych.
mysql> SHOW TABLES FROM performance_schema LIKE 'replication%';
+---------------------------------------------+
| Tables_in_performance_schema (replication%) |
+---------------------------------------------+
| replication_applier_configuration |
| replication_applier_status |
| replication_applier_status_by_coordinator |
| replication_applier_status_by_worker |
| replication_connection_configuration |
| replication_connection_status |
| replication_group_member_stats |
| replication_group_members |
+---------------------------------------------+
8 rows in set (0.00 sec)Poniżej znajdziesz kilka przykładów danych dostępnych w niektórych z tych tabel.
mysql> select * from replication_connection_status\G
*************************** 1. row ***************************
CHANNEL_NAME:
GROUP_NAME:
SOURCE_UUID: 5d1e2227-07c6-11e7-8123-080027495a77
THREAD_ID: 32
SERVICE_STATE: ON
COUNT_RECEIVED_HEARTBEATS: 1
LAST_HEARTBEAT_TIMESTAMP: 2017-03-17 19:41:34
RECEIVED_TRANSACTION_SET: 5d1e2227-07c6-11e7-8123-080027495a77:715599-724966
LAST_ERROR_NUMBER: 0
LAST_ERROR_MESSAGE:
LAST_ERROR_TIMESTAMP: 0000-00-00 00:00:00
1 row in set (0.00 sec)mysql> select * from replication_applier_status_by_worker\G
*************************** 1. row ***************************
CHANNEL_NAME:
WORKER_ID: 0
THREAD_ID: 31
SERVICE_STATE: ON
LAST_SEEN_TRANSACTION: 5d1e2227-07c6-11e7-8123-080027495a77:726086
LAST_ERROR_NUMBER: 0
LAST_ERROR_MESSAGE:
LAST_ERROR_TIMESTAMP: 0000-00-00 00:00:00
1 row in set (0.00 sec)Jak widać, możemy zweryfikować stan replikacji, ostatni błąd, otrzymany zestaw transakcji i trochę więcej danych. Co ważne — jeśli włączyłeś replikację wielowątkową, w tabeli replication_applier_status_by_worker zobaczysz stan każdego pojedynczego pracownika — to pomoże Ci zrozumieć stan replikacji dla każdego z wątków roboczych.
Opóźnienie replikacji
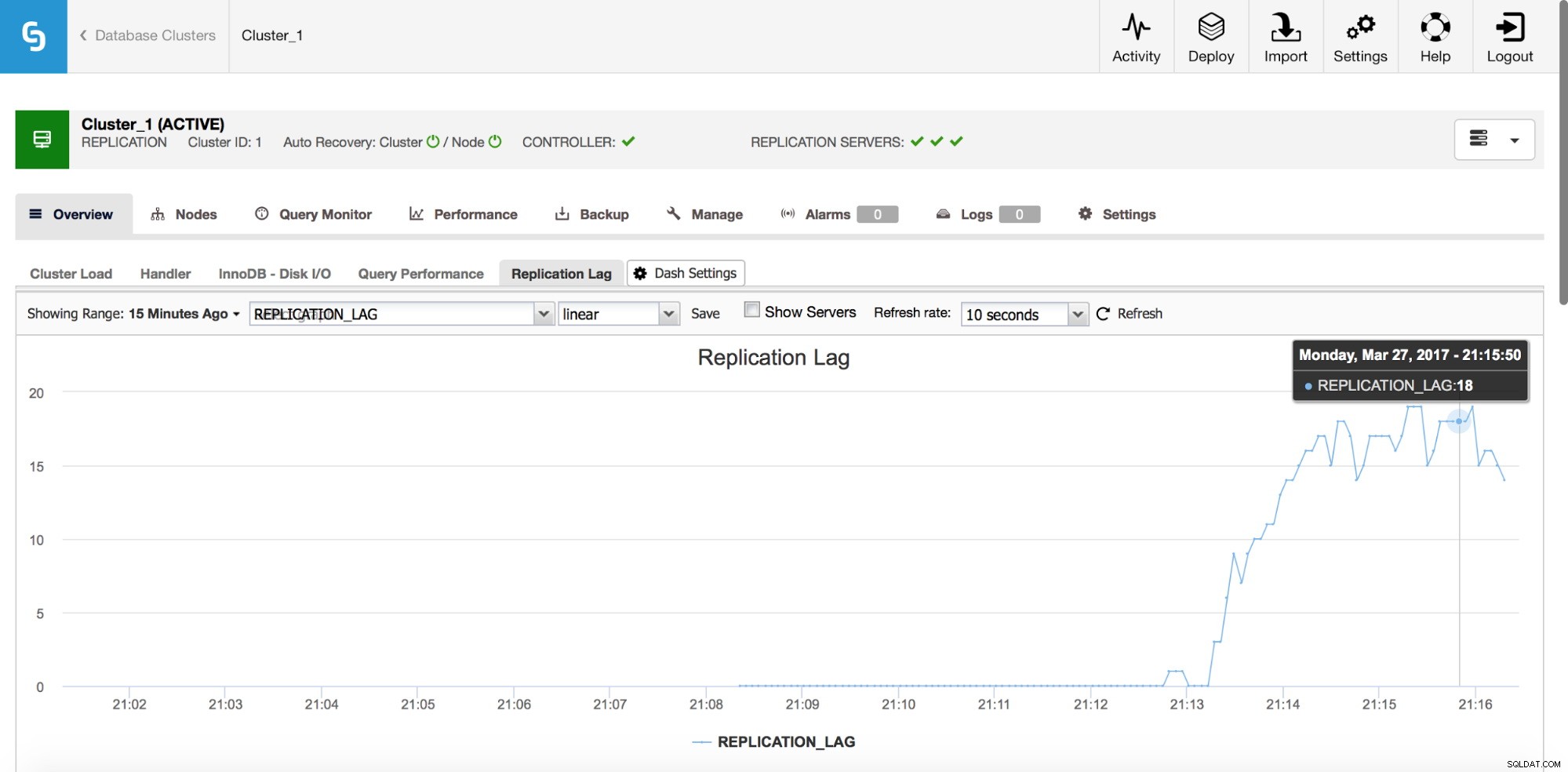
Lagi to zdecydowanie jeden z najczęstszych problemów, z jakimi będziesz się spotykać podczas pracy z replikacją MySQL. Opóźnienie replikacji pojawia się, gdy jedno z urządzeń podrzędnych nie jest w stanie nadążyć za ilością operacji zapisu wykonywanych przez urządzenie nadrzędne. Przyczyny mogą być różne - inna konfiguracja sprzętowa, większe obciążenie na slave, wysoki stopień zrównoleglenia zapisu na master, który musi być serializowany (gdy używasz pojedynczego wątku do replikacji) lub zapisy nie mogą być zrównoleglone w tym samym stopniu, co ma był na masterze (gdy używasz replikacji wielowątkowej).
Jak to wykryć?
Istnieje kilka metod wykrywania opóźnienia replikacji. Przede wszystkim możesz zaznaczyć „Seconds_Behind_Master” w wyjściu SHOW SLAVE STATUS - powie ci to, czy slave jest opóźniony, czy nie. Działa to dobrze w większości przypadków, ale w bardziej złożonych topologiach, gdy używasz masterów pośrednich na hostach gdzieś nisko w łańcuchu replikacji, może to być nieprecyzyjne. Innym, lepszym rozwiązaniem jest poleganie na zewnętrznych narzędziach, takich jak pt-heartbeat. Pomysł jest prosty - tworzona jest tabela z m.in. kolumną sygnatury czasowej. Ta kolumna jest aktualizowana na wzorcu w regularnych odstępach czasu. Na urządzeniu podrzędnym możesz następnie porównać znacznik czasu z tej kolumny z aktualnym czasem — pokaże Ci to, jak daleko jest za urządzeniem podrzędnym.
Niezależnie od sposobu obliczania opóźnienia, upewnij się, że hosty są zsynchronizowane w czasie. Użyj ntpd lub innych sposobów synchronizacji czasu - jeśli występuje przesunięcie czasu, zobaczysz „fałszywe” opóźnienie na swoich niewolnikach.
Jak zmniejszyć opóźnienia?
Nie jest łatwo odpowiedzieć na to pytanie. Krótko mówiąc, zależy to od tego, co powoduje opóźnienie, a co stało się wąskim gardłem. Istnieją dwa typowe wzorce - slave jest powiązany z I/O, co oznacza, że jego podsystem I/O nie radzi sobie z ilością operacji zapisu i odczytu. Po drugie - urządzenie podrzędne jest powiązane z procesorem, co oznacza, że wątek replikacji wykorzystuje cały procesor (jeden wątek może wykorzystywać tylko jeden rdzeń procesora) i nadal nie wystarcza do obsługi wszystkich operacji zapisu.
Gdy procesor jest wąskim gardłem, rozwiązanie może być tak proste, jak użycie replikacji wielowątkowej. Zwiększ liczbę wątków roboczych, aby umożliwić większą równoległość. Nie zawsze jest to jednak możliwe - w takim przypadku możesz pobawić się zmiennymi zatwierdzania grupowego (zarówno dla MySQL, jak i MariaDB), aby opóźnić zatwierdzenia na krótki okres czasu (mówimy tutaj o milisekundach) i w ten sposób , zwiększ równoległość zatwierdzeń.
Jeśli problem tkwi w I/O, problem jest nieco trudniejszy do rozwiązania. Oczywiście powinieneś przejrzeć swoje ustawienia I/O InnoDB - być może jest miejsce na ulepszenia. Jeśli dostrajanie my.cnf nie pomoże, nie masz zbyt wielu opcji - ulepsz swoje zapytania (tam, gdzie to możliwe) lub zaktualizuj swój podsystem I/O do czegoś bardziej wydajnego.
Większość serwerów proxy (na przykład wszystkie proxy, które można wdrożyć z ClusterControl:ProxySQL, HAProxy i MaxScale) daje możliwość usunięcia urządzenia podrzędnego z rotacji, jeśli opóźnienie replikacji przekroczy określony próg. W żadnym wypadku nie jest to metoda zmniejszenia opóźnień, ale może być pomocna w unikaniu nieaktualnych odczytów i, jako efekt uboczny, w zmniejszeniu obciążenia urządzenia podrzędnego, co powinno pomóc mu nadrobić zaległości.
Oczywiście dostrajanie zapytań może być rozwiązaniem w obu przypadkach - zawsze dobrze jest ulepszyć zapytania, które obciążają procesor lub I/O.
Błędne transakcje
Transakcje błędne to transakcje, które zostały wykonane tylko na urządzeniu podrzędnym, a nie na urządzeniu głównym. Krótko mówiąc, czynią niewolnika niezgodnym z panem. W przypadku korzystania z replikacji opartej na GTID może to spowodować poważne problemy, jeśli podrzędny zostanie awansowany na nadrzędny. Mamy obszerny post na ten temat i zachęcamy do zapoznania się z nim i zapoznania się ze sposobem wykrywania i rozwiązywania problemów z błędnymi transakcjami. Zawarliśmy tam również informacje, w jaki sposób ClusterControl wykrywa i obsługuje błędne transakcje.
Brak pliku Binlog na Master
Jak zidentyfikować problem?
W pewnych okolicznościach może się zdarzyć, że slave połączy się z masterem i poprosi o nieistniejący binarny plik dziennika. Jednym z powodów może być błędna transakcja - w pewnym momencie transakcja została wykonana na niewolniku, a później ten niewolnik staje się mistrzem. Inne hosty, które są skonfigurowane do podporządkowania się temu masterowi, poproszą o tę brakującą transakcję. Jeśli został wykonany dawno temu, istnieje szansa, że binarne pliki dziennika zostały już wyczyszczone.
Inny, bardziej typowy przykład - chcesz udostępnić slave'a za pomocą xtrabackup. Kopiujesz kopię zapasową na hoście, stosujesz log, zmieniasz właściciela katalogu danych MySQL - typowe operacje przywracania kopii zapasowej. Wykonujesz
SET GLOBAL gtid_purged=na podstawie danych z xtrabackup_binlog_info i uruchamiasz CHANGE MASTER TO … MASTER_AUTO_POSITION=1 (to jest w MySQL, MariaDB ma trochę inny proces), uruchamiasz slave'a i kończysz z błędem takim jak:
Last_IO_Error: Got fatal error 1236 from master when reading data from binary log: 'The slave is connecting using CHANGE MASTER TO MASTER_AUTO_POSITION = 1, but the master has purged binary logs containing GTIDs that the slave requires.'w MySQL lub:
Last_IO_Error: Got fatal error 1236 from master when reading data from binary log: 'Could not find GTID state requested by slave in any binlog files. Probably the slave state is too old and required binlog files have been purged.'w MariaDB.
Zasadniczo oznacza to, że master nie ma wszystkich logów binarnych potrzebnych do wykonania wszystkich brakujących transakcji. Najprawdopodobniej kopia zapasowa jest za stara, a urządzenie główne wyczyściło już niektóre dzienniki binarne utworzone między utworzeniem kopii zapasowej a udostępnieniem urządzenia podrzędnego.
Jak rozwiązać ten problem?
Niestety w tym konkretnym przypadku niewiele można zrobić. Jeśli masz hosty MySQL, które przechowują logi binarne przez dłuższy czas niż master, możesz spróbować użyć tych logów do odtworzenia brakujących transakcji na slave. Zobaczmy, jak można to zrobić.
Przede wszystkim przyjrzyjmy się najstarszemu GTID w logach binarnych mastera:
mysql> SHOW BINARY LOGS\G
*************************** 1. row ***************************
Log_name: binlog.000021
File_size: 463
1 row in set (0.00 sec)Tak więc „binlog.000021” to najnowszy (i jedyny) plik. Sprawdźmy, jaki jest pierwszy wpis GTID w tym pliku:
example@sqldat.com:~# mysqlbinlog /var/lib/mysql/binlog.000021
/*!50530 SET @@SESSION.PSEUDO_SLAVE_MODE=1*/;
/*!50003 SET @example@sqldat.com@COMPLETION_TYPE,COMPLETION_TYPE=0*/;
DELIMITER /*!*/;
# at 4
#170320 10:39:51 server id 1 end_log_pos 123 CRC32 0x5644fc9b Start: binlog v 4, server v 5.7.17-11-log created 170320 10:39:51
# Warning: this binlog is either in use or was not closed properly.
BINLOG '
d7HPWA8BAAAAdwAAAHsAAAABAAQANS43LjE3LTExLWxvZwAAAAAAAAAAAAAAAAAAAAAAAAAAAAAA
AAAAAAAAAAAAAAAAAAAAAAAAEzgNAAgAEgAEBAQEEgAAXwAEGggAAAAICAgCAAAACgoKKioAEjQA
AZv8RFY=
'/*!*/;
# at 123
#170320 10:39:51 server id 1 end_log_pos 194 CRC32 0x5c096d62 Previous-GTIDs
# 5d1e2227-07c6-11e7-8123-080027495a77:1-1106668
# at 194
#170320 11:21:26 server id 1 end_log_pos 259 CRC32 0xde21b300 GTID last_committed=0 sequence_number=1
SET @@SESSION.GTID_NEXT= '5d1e2227-07c6-11e7-8123-080027495a77:1106669'/*!*/;
# at 259Jak widzimy, najstarszy dostępny wpis w dzienniku binarnym to:5d1e2227-07c6-11e7-8123-080027495a77:1106669
Musimy również sprawdzić, jaki jest ostatni numer GTID objęty kopią zapasową:
example@sqldat.com:~# cat /var/lib/mysql/xtrabackup_binlog_info
binlog.000017 194 5d1e2227-07c6-11e7-8123-080027495a77:1-1106666
Jest to:5d1e2227-07c6-11e7-8123-080027495a77:1-1106666 więc brakuje nam dwóch zdarzeń:
5d1e2227-07c6-11e7-8123-080027495a77:1106667-1106668
Zobaczmy, czy uda nam się znaleźć te transakcje na innym urządzeniu podrzędnym.
mysql> SHOW BINARY LOGS;
+---------------+------------+
| Log_name | File_size |
+---------------+------------+
| binlog.000001 | 1074130062 |
| binlog.000002 | 764366611 |
| binlog.000003 | 382576490 |
+---------------+------------+
3 rows in set (0.00 sec)Wygląda na to, że „binlog.000003” to najnowszy dziennik binarny. Musimy sprawdzić, czy można w nim znaleźć nasze brakujące numery GTID:
slave2:~# mysqlbinlog /var/lib/mysql/binlog.000003 | grep "5d1e2227-07c6-11e7-8123-080027495a77:110666[78]"
SET @@SESSION.GTID_NEXT= '5d1e2227-07c6-11e7-8123-080027495a77:1106667'/*!*/;
SET @@SESSION.GTID_NEXT= '5d1e2227-07c6-11e7-8123-080027495a77:1106668'/*!*/;Pamiętaj, że możesz chcieć skopiować pliki binlogu poza serwer produkcyjny, ponieważ ich przetwarzanie może zwiększyć obciążenie. Po zweryfikowaniu, że te identyfikatory GTID istnieją, możemy je wyodrębnić:
slave2:~# mysqlbinlog --exclude-gtids='5d1e2227-07c6-11e7-8123-080027495a77:1-1106666,5d1e2227-07c6-11e7-8123-080027495a77:1106669' /var/lib/mysql/binlog.000003 > to_apply_on_slave1.sqlPo krótkim scp możemy zastosować te zdarzenia na urządzeniu podrzędnym
slave1:~# mysql -ppass < to_apply_on_slave1.sqlPo zakończeniu możemy zweryfikować, czy te identyfikatory GTID zostały zastosowane, patrząc na dane wyjściowe SHOW SLAVE STATUS:
Last_IO_Error: Got fatal error 1236 from master when reading data from binary log: 'The slave is connecting using CHANGE MASTER TO MASTER_AUTO_POSITION = 1, but the master has purged binary logs containing GTIDs that the slave requires.'
Last_SQL_Errno: 0
Last_SQL_Error:
Replicate_Ignore_Server_Ids:
Master_Server_Id: 1
Master_UUID: 5d1e2227-07c6-11e7-8123-080027495a77
Master_Info_File: mysql.slave_master_info
SQL_Delay: 0
SQL_Remaining_Delay: NULL
Slave_SQL_Running_State: Slave has read all relay log; waiting for more updates
Master_Retry_Count: 86400
Master_Bind:
Last_IO_Error_Timestamp: 170320 10:45:04
Last_SQL_Error_Timestamp:
Master_SSL_Crl:
Master_SSL_Crlpath:
Retrieved_Gtid_Set:
Executed_Gtid_Set: 5d1e2227-07c6-11e7-8123-080027495a77:1-1106668Executed_GTID_set wygląda dobrze, dlatego możemy uruchomić wątki podrzędne:
mysql> START SLAVE;
Query OK, 0 rows affected (0.00 sec)Sprawdźmy, czy zadziałało dobrze. Ponownie użyjemy wyjścia SHOW SLAVE STATUS:
Master_SSL_Crlpath:
Retrieved_Gtid_Set: 5d1e2227-07c6-11e7-8123-080027495a77:1106669
Executed_Gtid_Set: 5d1e2227-07c6-11e7-8123-080027495a77:1-1106669Wygląda dobrze, działa!
Inną metodą rozwiązania tego problemu będzie ponowne wykonanie kopii zapasowej i ponowne udostępnienie urządzenia podrzędnego przy użyciu świeżych danych. Prawdopodobnie będzie to szybsze i zdecydowanie bardziej niezawodne. Rzadko zdarza się, że masz różne zasady czyszczenia binlogów na urządzeniu głównym i podrzędnym)
W następnym poście na blogu będziemy kontynuować omawianie innych rodzajów problemów z replikacją.