W ostatnich kilku blogach opisaliśmy, jak uruchomić klaster Galera w Dockerze, niezależnie od tego, czy jest to samodzielny Docker, czy też w wielohostowym Docker Swarm z siecią nakładkową. W tym poście na blogu przyjrzymy się uruchamianiu Galera Cluster na Kubernetes, narzędziu do orkiestracji do uruchamiania kontenerów na dużą skalę. Niektóre elementy są różne, na przykład sposób, w jaki aplikacja powinna łączyć się z klastrem, jak Kubernetes obsługuje przełączanie awaryjne i jak działa równoważenie obciążenia w Kubernetes.
Kubernetes kontra rój Dockerów
Naszym nadrzędnym celem jest zapewnienie niezawodnego działania Galera Cluster w środowisku kontenerowym. Wcześniej omawialiśmy Docker Swarm i okazało się, że uruchamianie na nim Galera Cluster ma szereg blokad, które uniemożliwiają gotowość do produkcji. Nasza podróż jest teraz kontynuowana dzięki Kubernetes, narzędziu do orkiestracji kontenerów klasy produkcyjnej. Zobaczmy, jaki poziom „gotowości produkcyjnej” może obsługiwać podczas uruchamiania usługi stanowej, takiej jak Galera Cluster.
Zanim przejdziemy dalej, podkreślmy kilka kluczowych różnic między Kubernetes (1.6) a Docker Swarm (17.03) podczas uruchamiania Galera Cluster na kontenerach:
- Kubernetes obsługuje dwie sondy sprawdzające kondycję — żywotność i gotowość. Jest to ważne podczas uruchamiania Galera Cluster na kontenerach, ponieważ aktywny kontener Galera nie oznacza, że jest gotowy do obsługi i powinien być uwzględniony w zestawie równoważenia obciążenia (pomyśl o stanie dołączającym/dawcy). Docker Swarm obsługuje tylko jedną sondę kontroli kondycji podobną do żywotności Kubernetes, kontener jest albo w dobrej kondycji i nadal działa, albo w złej kondycji i zostaje przełożony. Przeczytaj tutaj, aby uzyskać szczegółowe informacje.
- Kubernetes ma panel UI dostępny przez „proxy Kubectl”.
- Docker Swarm obsługuje tylko równoważenie obciążenia typu round-robin (przychodzące), podczas gdy Kubernetes używa najmniejszego połączenia.
- Docker Swarm obsługuje siatkę routingu w celu publikowania usługi w sieci zewnętrznej, podczas gdy Kubernetes obsługuje coś podobnego o nazwie NodePort, a także zewnętrzne systemy równoważenia obciążenia (GCE GLB/AWS ELB) i zewnętrzne nazwy DNS (jak w wersji 1.7)
Instalowanie Kubernetes za pomocą Kubeadm
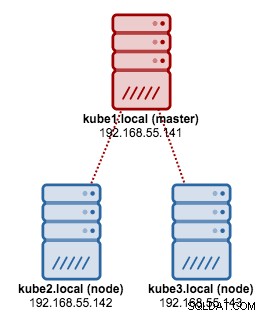
Zamierzamy użyć kubeadm do zainstalowania 3-węzłowego klastra Kubernetes na CentOS 7. Składa się on z 1 węzła głównego i 2 węzłów (minionów). Nasza fizyczna architektura wygląda tak:
1. Zainstaluj kubelet i Docker na wszystkich węzłach:
$ ARCH=x86_64
cat <<EOF > /etc/yum.repos.d/kubernetes.repo
[kubernetes]
name=Kubernetes
baseurl=https://packages.cloud.google.com/yum/repos/kubernetes-el7-${ARCH}
enabled=1
gpgcheck=1
repo_gpgcheck=1
gpgkey=https://packages.cloud.google.com/yum/doc/yum-key.gpg
https://packages.cloud.google.com/yum/doc/rpm-package-key.gpg
EOF
$ setenforce 0
$ yum install -y docker kubelet kubeadm kubectl kubernetes-cni
$ systemctl enable docker && systemctl start docker
$ systemctl enable kubelet && systemctl start kubelet2. Na masterze zainicjalizuj go, skopiuj plik konfiguracyjny, skonfiguruj sieć Pod za pomocą Weave i zainstaluj Kubernetes Dashboard:
$ kubeadm init
$ cp /etc/kubernetes/admin.conf $HOME/
$ export KUBECONFIG=$HOME/admin.conf
$ kubectl apply -f https://git.io/weave-kube-1.6
$ kubectl create -f https://git.io/kube-dashboard3. Następnie w pozostałych pozostałych węzłach:
$ kubeadm join --token 091d2a.e4862a6224454fd6 192.168.55.140:64434. Sprawdź, czy węzły są gotowe:
$ kubectl get nodes
NAME STATUS AGE VERSION
kube1.local Ready 1h v1.6.3
kube2.local Ready 1h v1.6.3
kube3.local Ready 1h v1.6.3Mamy teraz klaster Kubernetes do wdrożenia klastra Galera.
Klaster Galera na Kubernetes
W tym przykładzie zamierzamy wdrożyć MariaDB Galera Cluster 10.1 przy użyciu obrazu Docker pobranego z naszego repozytorium DockerHub. Pliki definicji YAML używane w tym wdrożeniu można znaleźć w katalogu example-kubernetes w repozytorium Github.
Kubernetes obsługuje wiele kontrolerów wdrażania. Aby wdrożyć klaster Galera, można użyć:
- Zestaw replik
- StatefulSet
Każdy z nich ma swoje zalety i wady. Przyjrzymy się każdemu z nich i zobaczymy, jaka jest różnica.
Wymagania wstępne
Zbudowany przez nas obraz wymaga etcd (samodzielnego lub klastra) do wykrywania usług. Uruchomienie klastra etcd wymaga, aby każda instancja etcd działała z różnymi poleceniami, więc zamiast Deploymentu użyjemy kontrolera Pods i stworzymy usługę o nazwie „etcd-client” jako punkt końcowy do podów etcd. Plik definicji etcd-cluster.yaml mówi wszystko.
Aby wdrożyć 3-podowy klaster etcd, po prostu uruchom:
$ kubectl create -f etcd-cluster.yamlSprawdź, czy klaster etcd jest gotowy:
$ kubectl get po,svc
NAME READY STATUS RESTARTS AGE
po/etcd0 1/1 Running 0 1d
po/etcd1 1/1 Running 0 1d
po/etcd2 1/1 Running 0 1d
NAME CLUSTER-IP EXTERNAL-IP PORT(S) AGE
svc/etcd-client 10.104.244.200 <none> 2379/TCP 1d
svc/etcd0 10.100.24.171 <none> 2379/TCP,2380/TCP 1d
svc/etcd1 10.108.207.7 <none> 2379/TCP,2380/TCP 1d
svc/etcd2 10.101.9.115 <none> 2379/TCP,2380/TCP 1dNasza architektura wygląda teraz mniej więcej tak:
ReplicaSet zapewnia, że określona liczba „replik” pod jest uruchomiona w danym momencie. Jednak wdrożenie to koncepcja wyższego poziomu, która zarządza zestawami replik i zapewnia deklaratywne aktualizacje zasobników wraz z wieloma innymi przydatnymi funkcjami. Dlatego zaleca się używanie wdrożeń zamiast bezpośredniego korzystania z zestawów ReplicaSets, chyba że potrzebujesz niestandardowej aranżacji aktualizacji lub w ogóle nie potrzebujesz aktualizacji. Korzystając z wdrożeń, nie musisz martwić się o zarządzanie tworzonymi przez nich zestawami replik. Wdrożenia posiadają własne zestawy replik i zarządzają nimi.
W naszym przypadku zamierzamy użyć Deploymentu jako kontrolera obciążenia, jak pokazano w tej definicji YAML. Możemy bezpośrednio utworzyć zestaw replik klastra Galera i usługę, uruchamiając następujące polecenie:
$ kubectl create -f mariadb-rs.ymlSprawdź, czy klaster jest gotowy, patrząc na ReplicaSet (rs), pody (po) i usługi (svc):
$ kubectl get rs,po,svc
NAME DESIRED CURRENT READY AGE
rs/galera-251551564 3 3 3 5h
NAME READY STATUS RESTARTS AGE
po/etcd0 1/1 Running 0 1d
po/etcd1 1/1 Running 0 1d
po/etcd2 1/1 Running 0 1d
po/galera-251551564-8c238 1/1 Running 0 5h
po/galera-251551564-swjjl 1/1 Running 1 5h
po/galera-251551564-z4sgx 1/1 Running 1 5h
NAME CLUSTER-IP EXTERNAL-IP PORT(S) AGE
svc/etcd-client 10.104.244.200 <none> 2379/TCP 1d
svc/etcd0 10.100.24.171 <none> 2379/TCP,2380/TCP 1d
svc/etcd1 10.108.207.7 <none> 2379/TCP,2380/TCP 1d
svc/etcd2 10.101.9.115 <none> 2379/TCP,2380/TCP 1d
svc/galera-rs 10.107.89.109 <nodes> 3306:30000/TCP 5h
svc/kubernetes 10.96.0.1 <none> 443/TCP 1dZ powyższego wyniku możemy zilustrować nasze pody i usługę jak poniżej:
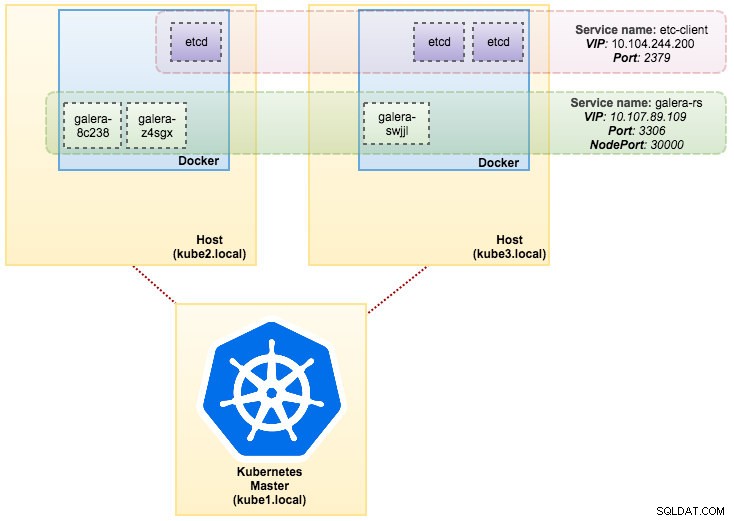
Uruchamianie Galera Cluster na ReplicaSet jest podobne do traktowania go jako aplikacji bezstanowej. Organizuje tworzenie, usuwanie i aktualizowanie podów i może być ukierunkowany na poziome autoskalowanie podów (HPA), tj. ReplicaSet może być automatycznie skalowany, jeśli spełnia określone progi lub cele (zużycie procesora, pakiety na sekundę, żądania na sekundę itp).
Jeśli jeden z węzłów Kubernetes ulegnie awarii, nowe pody zostaną zaplanowane na dostępnym węźle, aby spełnić żądane repliki. Woluminy powiązane z podem zostaną usunięte, jeśli pod zostanie usunięty lub przełożony. Nazwa hosta poda będzie generowana losowo, co utrudni śledzenie, gdzie należy kontener, po prostu patrząc na nazwę hosta.
Wszystko to działa całkiem dobrze w środowiskach testowych i testowych, w których można wykonać pełny cykl życia kontenera, taki jak wdrażanie, skalowanie, aktualizowanie i niszczenie bez żadnych zależności. Skalowanie w górę i w dół jest proste, dzięki zaktualizowaniu pliku YAML i wysłaniu go do klastra Kubernetes lub za pomocą polecenia scale:
$ kubectl scale replicaset galera-rs --replicas=5Korzystanie z zestawu stanowego
Znany jako PetSet w wersji przed 1.6, StatefulSet to najlepszy sposób na wdrożenie Galera Cluster w środowisku produkcyjnym, ponieważ:
- Usunięcie i/lub skalowanie w dół StatefulSet nie spowoduje usunięcia woluminów skojarzonych z StatefulSet. Ma to na celu zapewnienie bezpieczeństwa danych, które jest ogólnie bardziej wartościowe niż automatyczne czyszczenie wszystkich powiązanych zasobów StatefulSet.
- W przypadku StatefulSet z N replikami, podczas wdrażania podów są one tworzone sekwencyjnie, w kolejności od {0 .. N-1 }.
- Kiedy pody są usuwane, są kończone w odwrotnej kolejności, od {N-1 .. 0}.
- Zanim operacja skalowania zostanie zastosowana do poda, wszyscy jego poprzednicy muszą być uruchomieni i gotowi.
- Zanim pod zostanie zamknięty, wszystkie jego następcy muszą zostać całkowicie zamknięte.
StatefulSet zapewnia pierwszorzędną obsługę kontenerów stanowych. Zapewnia gwarancję wdrożenia i skalowania. Po utworzeniu trzywęzłowego klastra Galera zostaną wdrożone trzy pody w kolejności db-0, db-1, db-2. db-1 nie zostanie wdrożony, dopóki db-0 nie będzie „uruchomiony i gotowy”, a db-2 nie zostanie wdrożony, dopóki db-1 nie będzie „uruchomiony i gotowy”. Jeśli db-0 ulegnie awarii, po tym, jak db-1 jest „Uruchomiony i gotowy”, ale przed uruchomieniem db-2, db-2 nie zostanie uruchomiony, dopóki db-0 nie zostanie pomyślnie uruchomiony ponownie i stanie się „Uruchomiony i gotowy”.
Zamierzamy użyć implementacji Kubernetes pamięci trwałej o nazwie PersistentVolume i PersistentVolumeClaim. Ma to zapewnić trwałość danych, jeśli pod został przeniesiony do innego węzła. Mimo że Galera Cluster zapewnia dokładną kopię danych w każdej replice, trwałe dane w każdym zasobniku są dobre do rozwiązywania problemów i odzyskiwania.
Aby utworzyć trwały magazyn, najpierw musimy utworzyć PersistentVolume dla każdego poda. PV to wtyczki głośności, takie jak Volumes w Dockerze, ale mają cykl życia niezależny od poszczególnych podów, które korzystają z PV. Ponieważ zamierzamy wdrożyć 3-węzłowy klaster Galera, musimy utworzyć 3 PV:
apiVersion: v1
kind: PersistentVolume
metadata:
name: datadir-galera-0
labels:
app: galera-ss
podindex: "0"
spec:
accessModes:
- ReadWriteOnce
capacity:
storage: 10Gi
hostPath:
path: /data/pods/galera-0/datadir
---
apiVersion: v1
kind: PersistentVolume
metadata:
name: datadir-galera-1
labels:
app: galera-ss
podindex: "1"
spec:
accessModes:
- ReadWriteOnce
capacity:
storage: 10Gi
hostPath:
path: /data/pods/galera-1/datadir
---
apiVersion: v1
kind: PersistentVolume
metadata:
name: datadir-galera-2
labels:
app: galera-ss
podindex: "2"
spec:
accessModes:
- ReadWriteOnce
capacity:
storage: 10Gi
hostPath:
path: /data/pods/galera-2/datadirPowyższa definicja pokazuje, że zamierzamy stworzyć 3 PV, zmapowane do fizycznej ścieżki węzłów Kubernetes z 10 GB przestrzeni dyskowej. Zdefiniowaliśmy ReadWriteOnce, co oznacza, że wolumin może być montowany w trybie odczytu-zapisu tylko przez jeden węzeł. Zapisz powyższe wiersze w mariadb-pv.yml i prześlij je do Kubernetes:
$ kubectl create -f mariadb-pv.yml
persistentvolume "datadir-galera-0" created
persistentvolume "datadir-galera-1" created
persistentvolume "datadir-galera-2" createdNastępnie zdefiniuj zasoby PersistentVolumeClaim:
kind: PersistentVolumeClaim
apiVersion: v1
metadata:
name: mysql-datadir-galera-ss-0
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 10Gi
selector:
matchLabels:
app: galera-ss
podindex: "0"
---
kind: PersistentVolumeClaim
apiVersion: v1
metadata:
name: mysql-datadir-galera-ss-1
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 10Gi
selector:
matchLabels:
app: galera-ss
podindex: "1"
---
kind: PersistentVolumeClaim
apiVersion: v1
metadata:
name: mysql-datadir-galera-ss-2
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 10Gi
selector:
matchLabels:
app: galera-ss
podindex: "2"Powyższa definicja pokazuje, że chcielibyśmy przejąć zasoby PV i użyć spec.selector.matchLabels szukać naszego PV (metadata.labels.app:galera-ss ) na podstawie odpowiedniego indeksu pod (metadata.labels.podindex ) przypisane przez Kubernetes. nazwa.metadanych zasób musi mieć format „{volumeMounts.name}-{pod}-{indeks porządkowy}” zdefiniowany w spec.templates.containers więc Kubernetes wie, który punkt montowania zmapować roszczenie do pod.
Zapisz powyższe wiersze w mariadb-pvc.yml i prześlij je do Kubernetes:
$ kubectl create -f mariadb-pvc.yml
persistentvolumeclaim "mysql-datadir-galera-ss-0" created
persistentvolumeclaim "mysql-datadir-galera-ss-1" created
persistentvolumeclaim "mysql-datadir-galera-ss-2" createdNasza pamięć trwała jest już gotowa. Następnie możemy rozpocząć wdrażanie klastra Galera, tworząc zasób StatefulSet wraz z zasobem usługi Headless, jak pokazano w mariadb-ss.yml:
$ kubectl create -f mariadb-ss.yml
service "galera-ss" created
statefulset "galera-ss" createdTeraz pobierz podsumowanie naszego wdrożenia StatefulSet:
$ kubectl get statefulsets,po,pv,pvc -o wide
NAME DESIRED CURRENT AGE
statefulsets/galera-ss 3 3 1d galera severalnines/mariadb:10.1 app=galera-ss
NAME READY STATUS RESTARTS AGE IP NODE
po/etcd0 1/1 Running 0 7d 10.36.0.1 kube3.local
po/etcd1 1/1 Running 0 7d 10.44.0.2 kube2.local
po/etcd2 1/1 Running 0 7d 10.36.0.2 kube3.local
po/galera-ss-0 1/1 Running 0 1d 10.44.0.4 kube2.local
po/galera-ss-1 1/1 Running 1 1d 10.36.0.5 kube3.local
po/galera-ss-2 1/1 Running 0 1d 10.44.0.5 kube2.local
NAME CAPACITY ACCESSMODES RECLAIMPOLICY STATUS CLAIM STORAGECLASS REASON AGE
pv/datadir-galera-0 10Gi RWO Retain Bound default/mysql-datadir-galera-ss-0 4d
pv/datadir-galera-1 10Gi RWO Retain Bound default/mysql-datadir-galera-ss-1 4d
pv/datadir-galera-2 10Gi RWO Retain Bound default/mysql-datadir-galera-ss-2 4d
NAME STATUS VOLUME CAPACITY ACCESSMODES STORAGECLASS AGE
pvc/mysql-datadir-galera-ss-0 Bound datadir-galera-0 10Gi RWO 4d
pvc/mysql-datadir-galera-ss-1 Bound datadir-galera-1 10Gi RWO 4d
pvc/mysql-datadir-galera-ss-2 Bound datadir-galera-2 10Gi RWO 4dW tym momencie nasz klaster Galera działający na StatefulSet można zilustrować na poniższym diagramie:
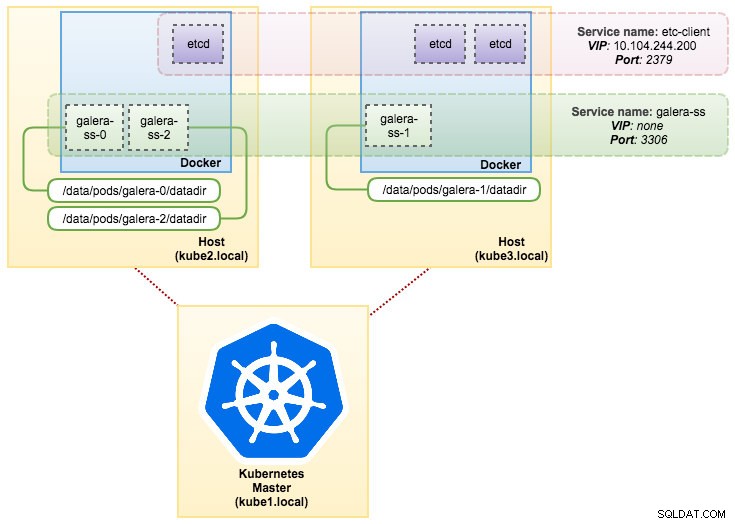
Działanie na StatefulSet gwarantuje spójne identyfikatory, takie jak nazwa hosta, adres IP, identyfikator sieci, domena klastra, Pod DNS i pamięć masowa. Dzięki temu Pod może łatwo odróżnić się od innych w grupie Podów. Wolumin zostanie zachowany na hoście i nie zostanie usunięty, jeśli pod zostanie usunięty lub przeniesiony na inny węzeł. Pozwala to na odzyskanie danych i zmniejsza ryzyko całkowitej utraty danych.
Z drugiej strony czas wdrożenia wyniesie N-1 razy (N =replik) dłużej, ponieważ Kubernetes będzie przestrzegać kolejności porządkowej podczas wdrażania, zmiany harmonogramu lub usuwania zasobów. Przygotowanie PV i roszczeń przed myśleniem o skalowaniu klastra byłoby trochę kłopotliwe. Pamiętaj, że aktualizowanie istniejącego zestawu StatefulSet jest obecnie procesem ręcznym, w którym można tylko aktualizować spec.replicas w tej chwili.
Łączenie z usługą Galera Cluster Service i podami
Istnieje kilka sposobów łączenia się z klastrem bazy danych. Możesz podłączyć się bezpośrednio do portu. W przykładzie usługi „galera-rs” używamy NodePort, eksponując usługę na IP każdego węzła na statycznym porcie (NodePort). Usługa ClusterIP, do której będzie kierować usługa NodePort, jest tworzona automatycznie. Będziesz mógł skontaktować się z usługą NodePort spoza klastra, żądając {NodeIP}:{NodePort} .
Przykład zewnętrznego połączenia z Galera Cluster:
(external)$ mysql -udb_user -ppassword -h192.168.55.141 -P30000
(external)$ mysql -udb_user -ppassword -h192.168.55.142 -P30000
(external)$ mysql -udb_user -ppassword -h192.168.55.143 -P30000W przestrzeni sieciowej Kubernetes Pody mogą łączyć się wewnętrznie przez adres IP klastra lub nazwę usługi, którą można pobrać za pomocą następującego polecenia:
$ kubectl get services -o wide
NAME CLUSTER-IP EXTERNAL-IP PORT(S) AGE SELECTOR
etcd-client 10.104.244.200 <none> 2379/TCP 1d app=etcd
etcd0 10.100.24.171 <none> 2379/TCP,2380/TCP 1d etcd_node=etcd0
etcd1 10.108.207.7 <none> 2379/TCP,2380/TCP 1d etcd_node=etcd1
etcd2 10.101.9.115 <none> 2379/TCP,2380/TCP 1d etcd_node=etcd2
galera-rs 10.107.89.109 <nodes> 3306:30000/TCP 4h app=galera-rs
galera-ss None <none> 3306/TCP 3m app=galera-ss
kubernetes 10.96.0.1 <none> 443/TCP 1d <none>Z listy usług widać, że Galera Cluster ReplicaSet Cluster-IP to 10.107.89.109. Wewnętrznie inny pod może uzyskać dostęp do bazy danych za pośrednictwem tego adresu IP lub nazwy usługi przy użyciu ujawnionego portu 3306:
(etcd0 pod)$ mysql -udb_user -ppassword -hgalera-rs -P3306 -e 'select @@hostname'
+------------------------+
| @@hostname |
+------------------------+
| galera-251551564-z4sgx |
+------------------------+Możesz także połączyć się z zewnętrznym NodePort z wnętrza dowolnego kapsuły na porcie 30000:
(etcd0 pod)$ mysql -udb_user -ppassword -h192.168.55.143 -P30000 -e 'select @@hostname'
+------------------------+
| @@hostname |
+------------------------+
| galera-251551564-z4sgx |
+------------------------+Połączenie z podami backendu będzie odpowiednio równoważone w oparciu o algorytm najmniejszego połączenia.
Podsumowanie
W tym momencie uruchomienie Galera Cluster na Kubernetes w środowisku produkcyjnym wydaje się znacznie bardziej obiecujące w porównaniu z Docker Swarm. Jak omówiono w ostatnim poście na blogu, zgłaszane problemy są rozwiązywane w inny sposób w sposobie, w jaki Kubernetes organizuje kontenery w StatefulSet (chociaż nadal jest to funkcja beta w wersji 1.6). Mamy nadzieję, że sugerowane podejście pomoże uruchomić Galera Cluster na kontenerach na dużą skalę w produkcji.