W ClusterControl 1.5 dodaliśmy obsługę MySQL NDB Cluster 7.5. W tym poście na blogu przyjrzymy się niektórym funkcjom, które sprawiają, że ClusterControl jest doskonałym narzędziem do zarządzania klastrem MySQL NDB. Przede wszystkim, ponieważ istnieje wiele produktów z „klasterem” w nazwie, chcielibyśmy powiedzieć kilka słów o samym klastrze MySQL NDB i o tym, jak różni się od innych rozwiązań.
Klaster MySQL NDB
MySQL NDB Cluster to synchroniczny klaster MySQL oparty na silniku NDB. Jest to produkt z własną listą funkcji i zupełnie inny niż Galera Cluster czy MySQL InnoDB Cluster. Jedną z głównych różnic jest użycie silnika NDB, a nie InnoDB, który jest domyślnym silnikiem dla MySQL. W klastrze NDB dane są podzielone na wiele węzłów danych, podczas gdy klaster Galera lub klaster MySQL InnoDB zawierają pełny zestaw danych w każdym z węzłów. Ma to poważne reperkusje w sposobie, w jaki MySQL NDB Cluster radzi sobie z zapytaniami, które wykorzystują JOIN i duże fragmenty zbioru danych.
Jeśli chodzi o architekturę, klaster MySQL NDB składa się z trzech różnych typów węzłów. Węzły danych przechowują dane za pomocą silnika NDB. Dane są dublowane w celu zapewnienia nadmiarowości, z maksymalnie 4 replikami danych. Należy zauważyć, że ClusterControl wdroży 2 repliki na grupę węzłów, ponieważ jest to najbardziej przetestowana i stabilna konfiguracja. Węzły zarządzania są przeznaczone do kontrolowania klastra — ze względu na wysoką dostępność zazwyczaj masz dwa takie węzły. Węzły SQL są używane jako punkty wejścia do klastra. Analizują SQL, żądają danych z węzłów danych i w razie potrzeby agregują zestawy wyników.
Funkcje ClusterControl dla klastra MySQL NDB
Wdrożenie
ClusterControl 1.5 obsługuje wdrożenie MySQL NDB Cluster 7.5. Odbywa się to za pomocą tego samego kreatora wdrażania, co w przypadku pozostałych typów klastrów.
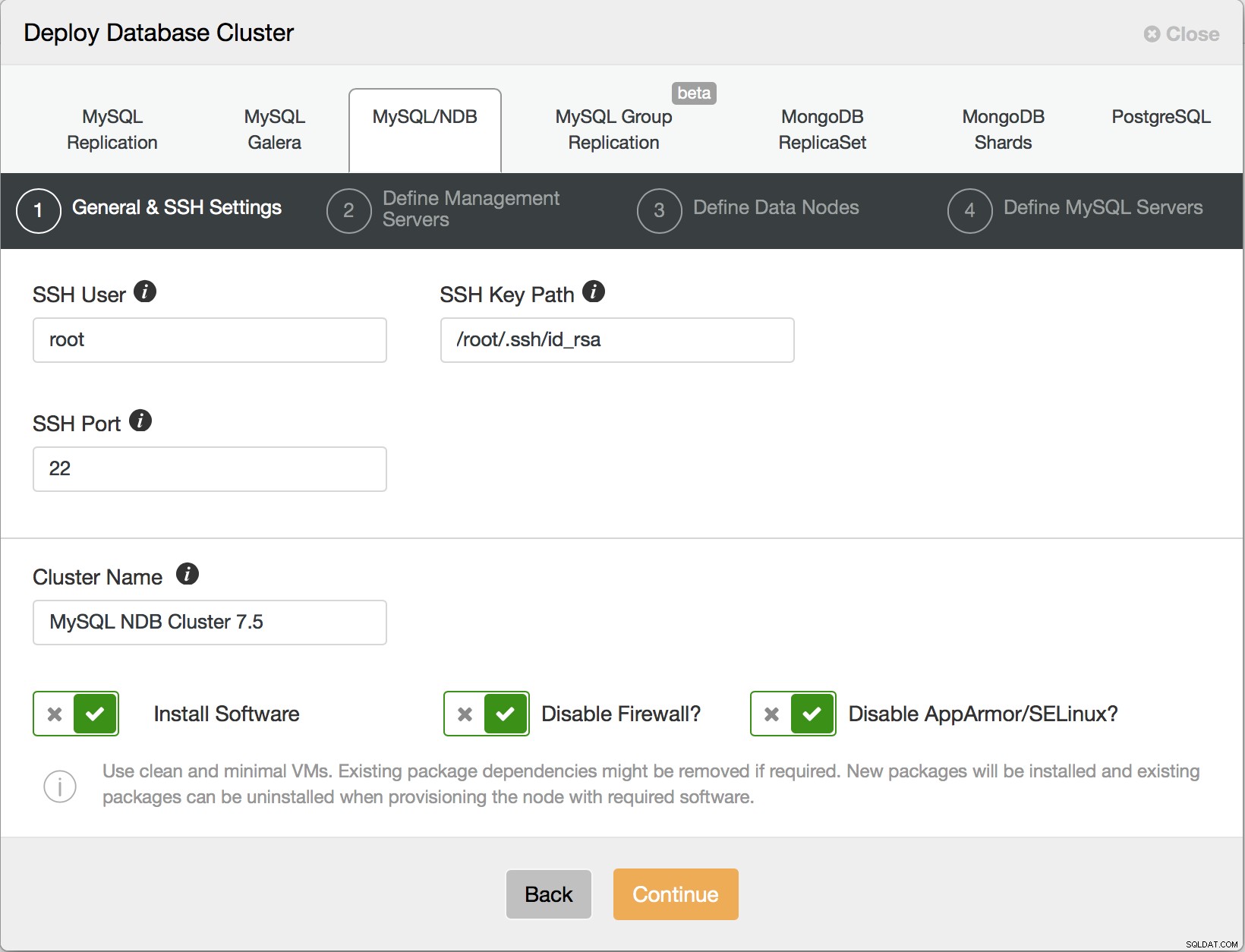
W pierwszym kroku musisz skonfigurować sposób, w jaki ClusterControl może logować się przez SSH do hostów — jest to standardowe wymaganie dla ClusterControl — jest bez agenta, więc wymaga dostępu do roota SSH bezpośrednio, do konta root lub przez (hasło lub hasło) sudo.
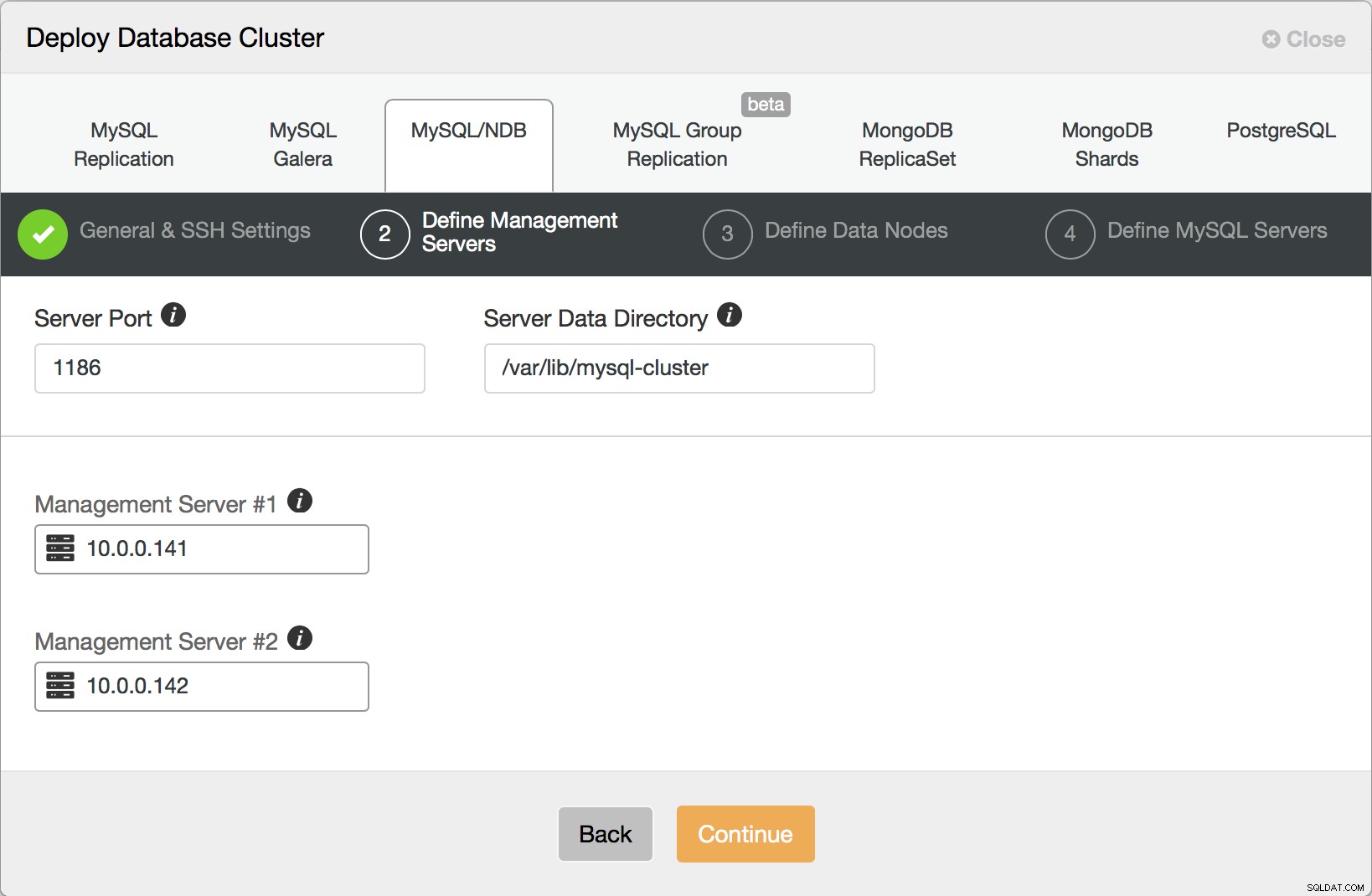
W następnym kroku zdefiniujesz węzły zarządzania dla swojego klastra.
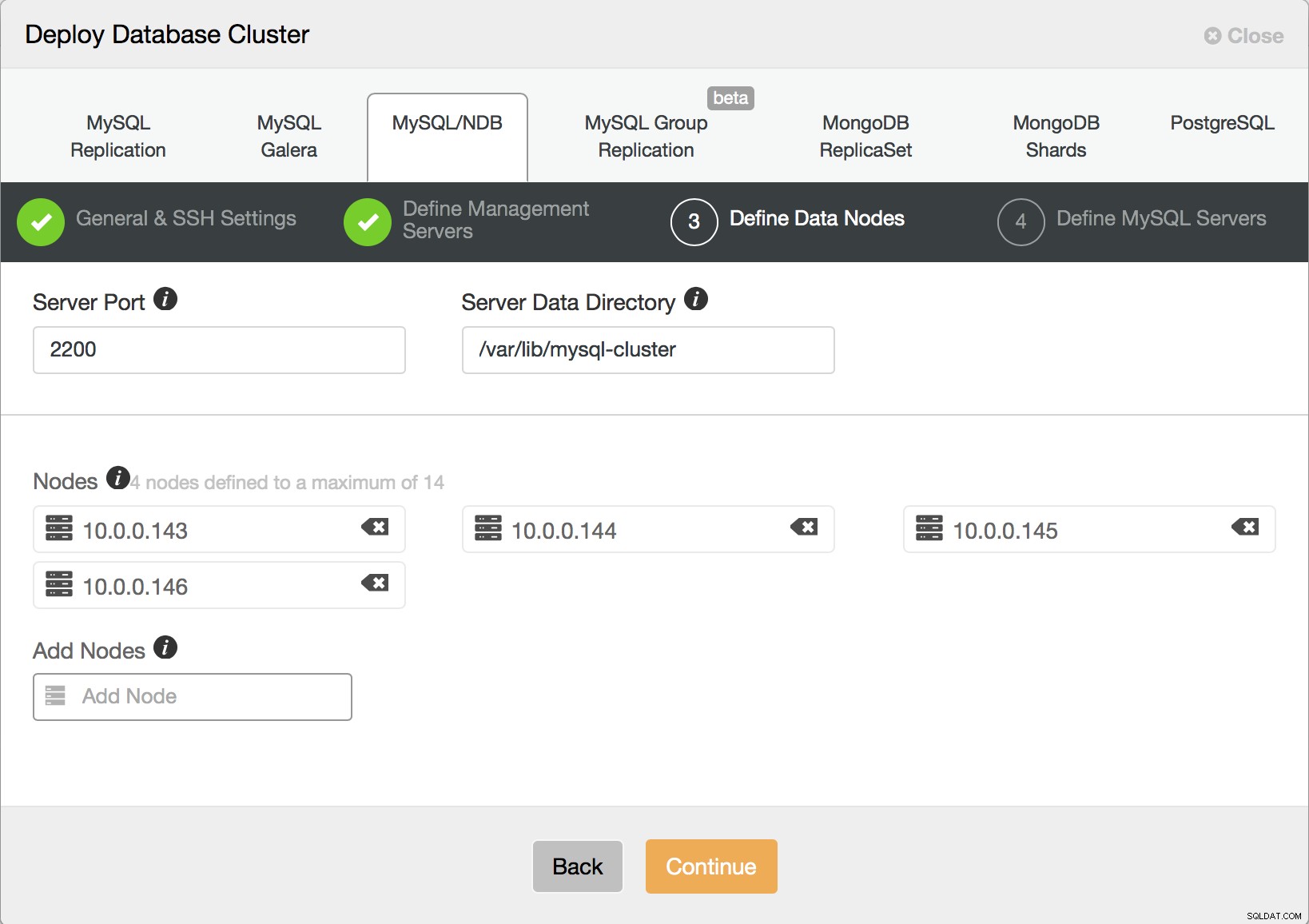
Tutaj musisz zdecydować, ile węzłów danych chcesz mieć. Jak wcześniej powiedzieliśmy, co 2 węzły będą częścią grupy węzłów, więc powinna to być liczba parzysta.
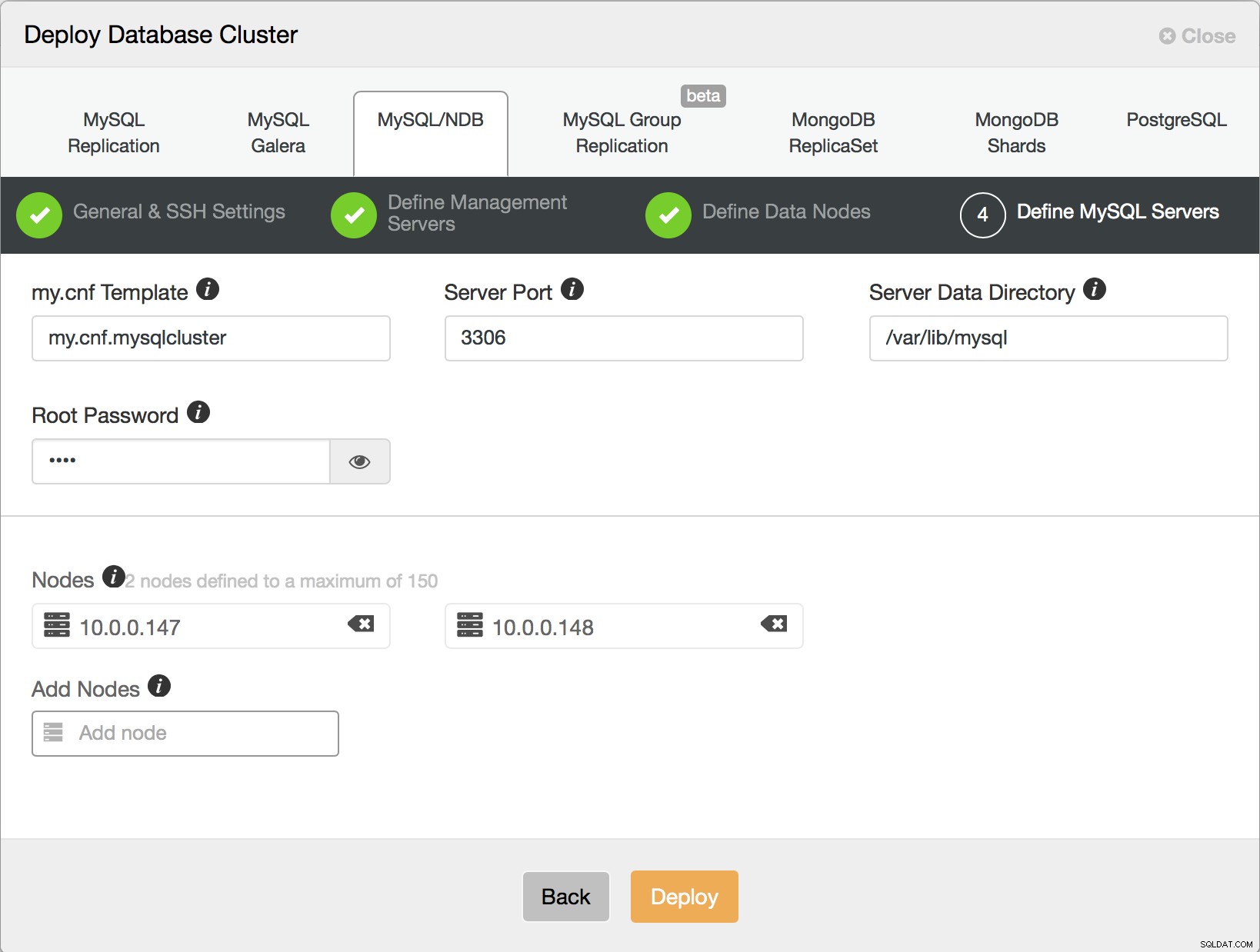
Na koniec musisz zdecydować, ile węzłów SQL chcesz wdrożyć w swoim klastrze. Po kliknięciu przycisku wdrożenia ClusterControl połączy się z hostami, zainstaluje oprogramowanie i skonfiguruje wszystkie usługi. Po chwili powinieneś zobaczyć wdrożony klaster.
Skalowanie klastra MySQL NDB
W przypadku klastra MySQL NDB ClusterControl 1.5.0 obsługuje skalowanie węzłów SQL. Możesz uzyskać dostęp do zadania z listy rozwijanej Zadania klastra.
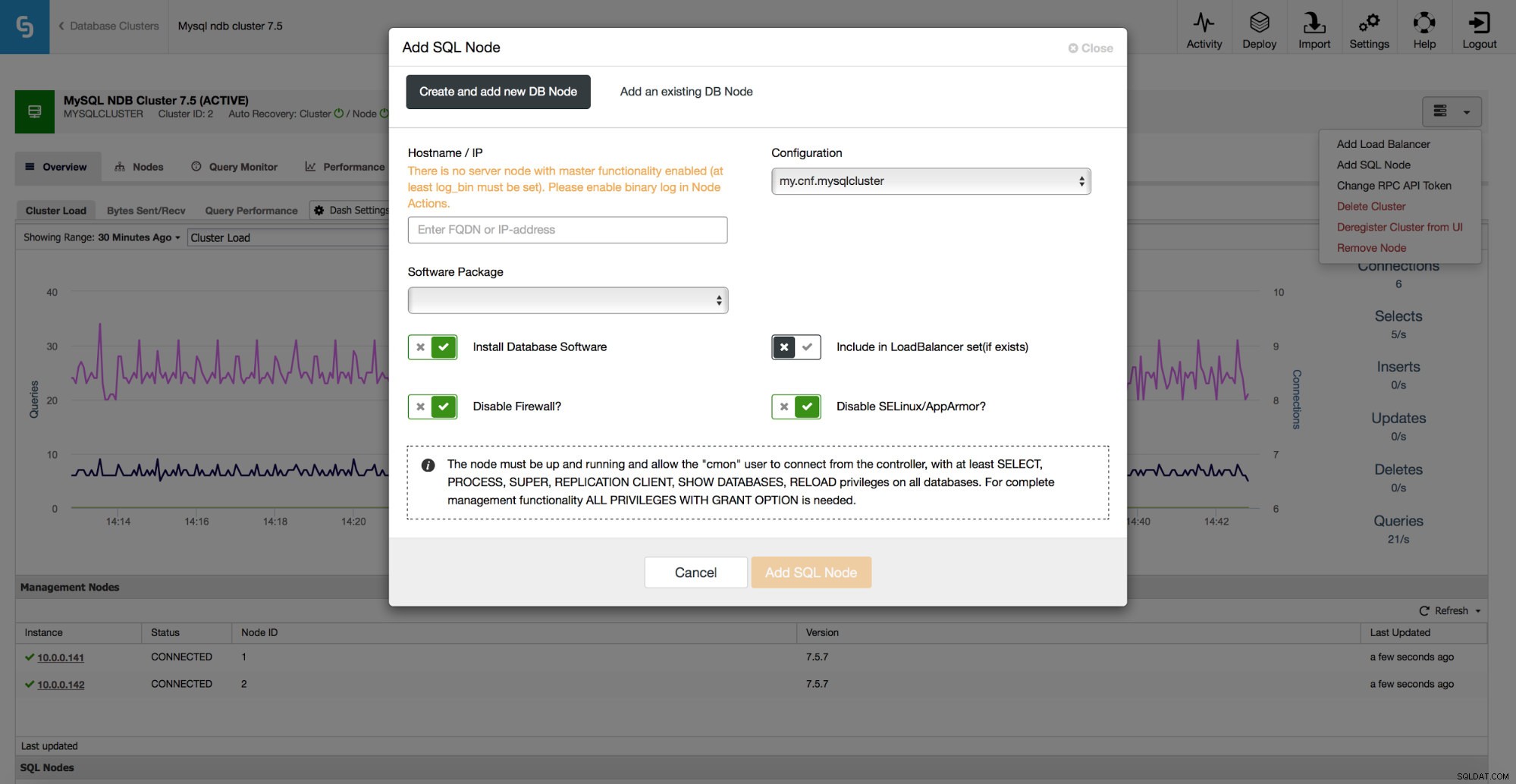
Tam możesz wpisać nazwę hosta węzła, który chcesz dodać i to wszystko, czego potrzebujesz - ClusterControl zajmie się resztą.
Zarządzanie klastrem MySQL NDB
ClusterControl pomaga zarządzać klastrem MySQL NDB. W tej sekcji chcielibyśmy omówić niektóre z naszych funkcji zarządzania.
Kopie zapasowe
Kopie zapasowe mają kluczowe znaczenie dla każdego środowiska produkcyjnego. W przypadku awarii tylko dobra kopia zapasowa może zminimalizować utratę danych i pomóc w szybkim rozwiązaniu problemu. Replikacja może nie zawsze być skutecznym rozwiązaniem — DROP TABLE usunie tabelę na wszystkich hostach w topologii. Nawet spóźniony niewolnik może opóźnić nieuniknione tylko o tyle.
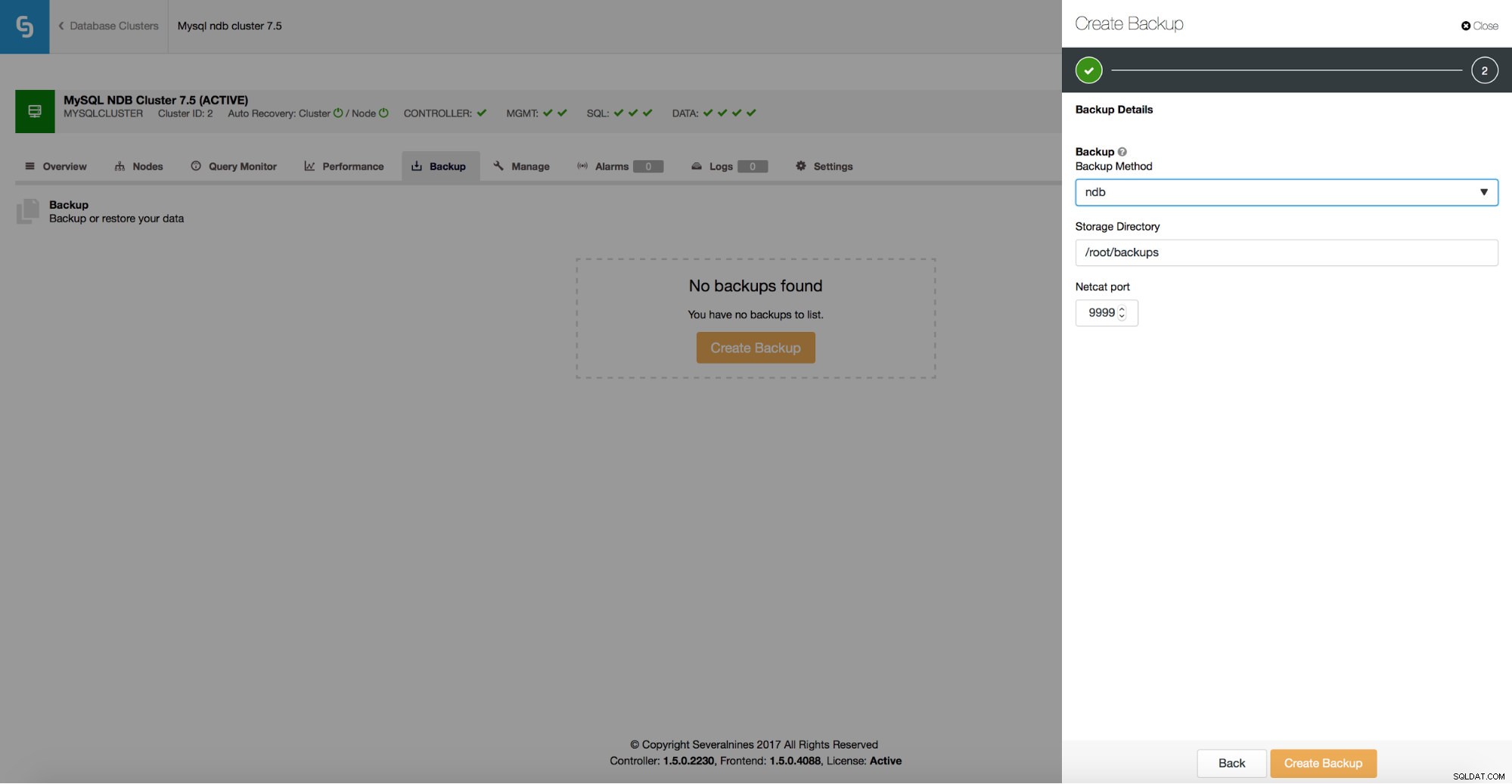
ClusterControl obsługuje tworzenie kopii zapasowych ndb dla klastra MySQL NDB.
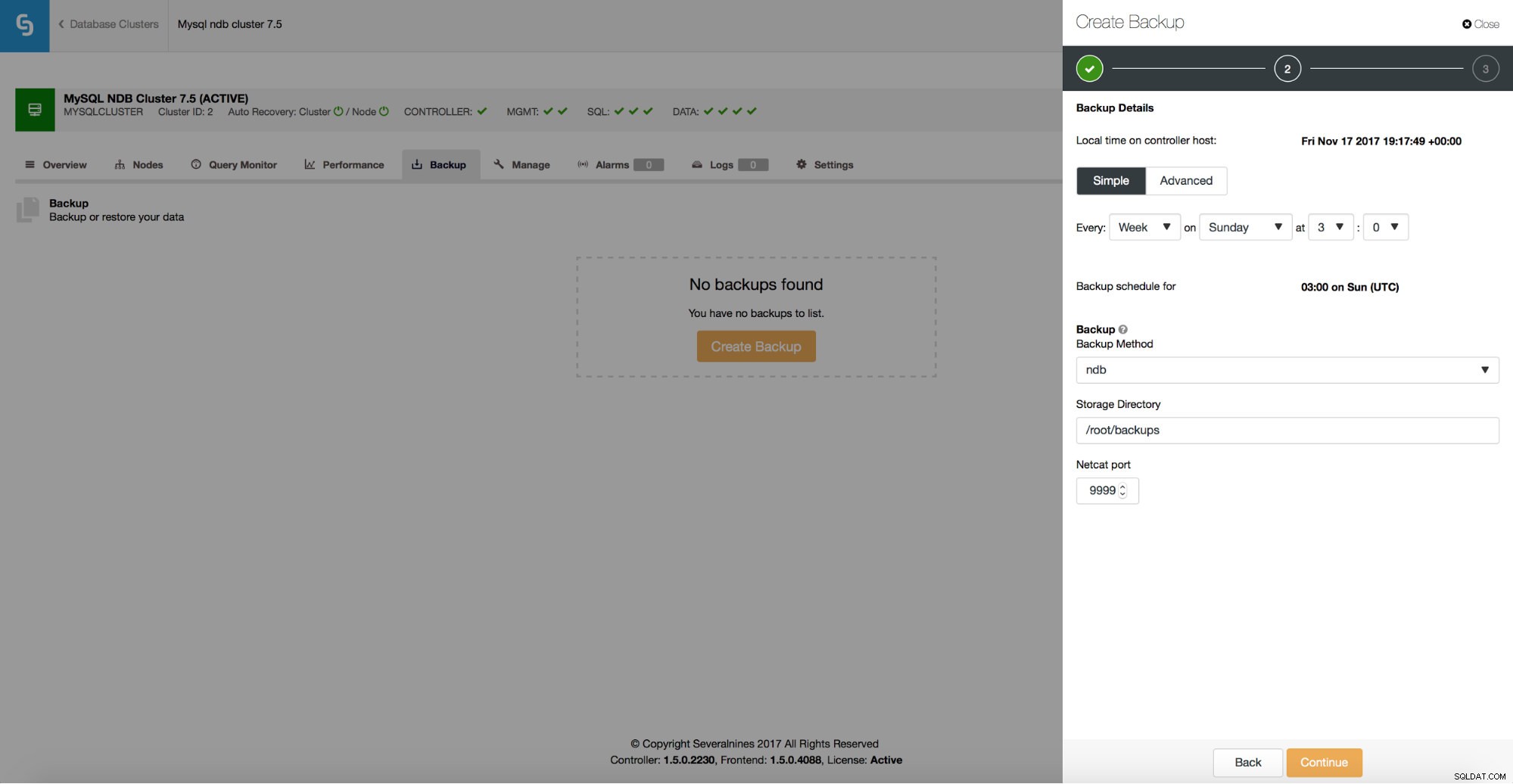
Możesz łatwo utworzyć harmonogram tworzenia kopii zapasowych do wykonania przez ClusterControl.
Warstwa proxy
ClusterControl umożliwia wdrożenie pełnego stosu wysokiej dostępności na szczycie klastra MySQL NDB. W przypadku warstwy proxy wspieramy wdrażanie HAProxy i MaxScale.
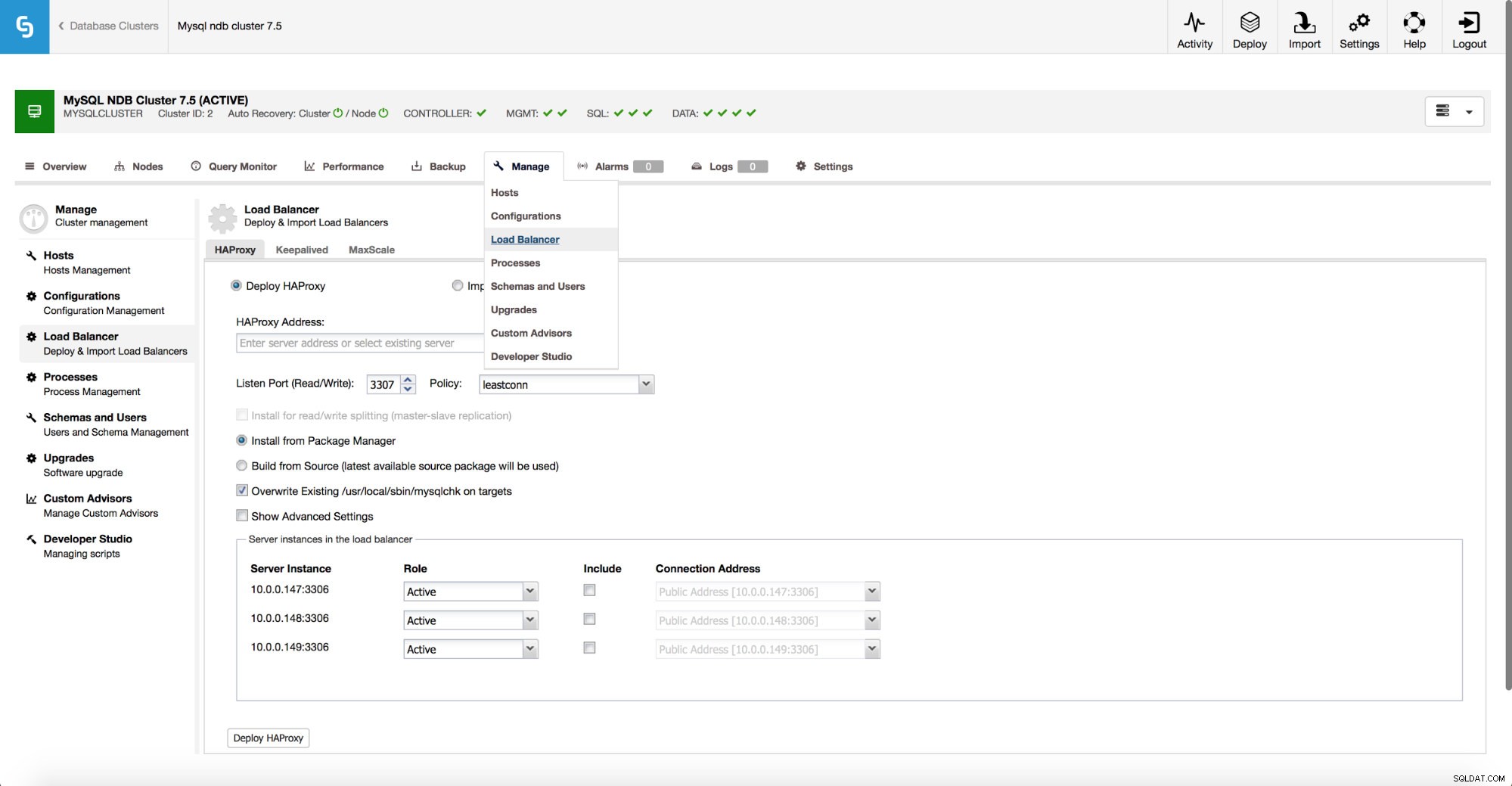
Jak pokazano na powyższym zrzucie ekranu, wdrożenie wygląda bardzo podobnie do innych typów klastrów. Musisz zdecydować, czy chcesz użyć istniejącego HAProxy, czy wdrożyć nowy. Następnie musisz dokonać wyboru, jak go zainstalować - korzystając z pakietów z repozytoriów dostępnych w węźle lub skompilować go z kodu źródłowego najnowszej wersji.
Jeśli zdecydujesz się użyć HAProxy, będziesz mieć możliwość skonfigurowania wysokiej dostępności za pomocą Keepalved i Virtual IP.
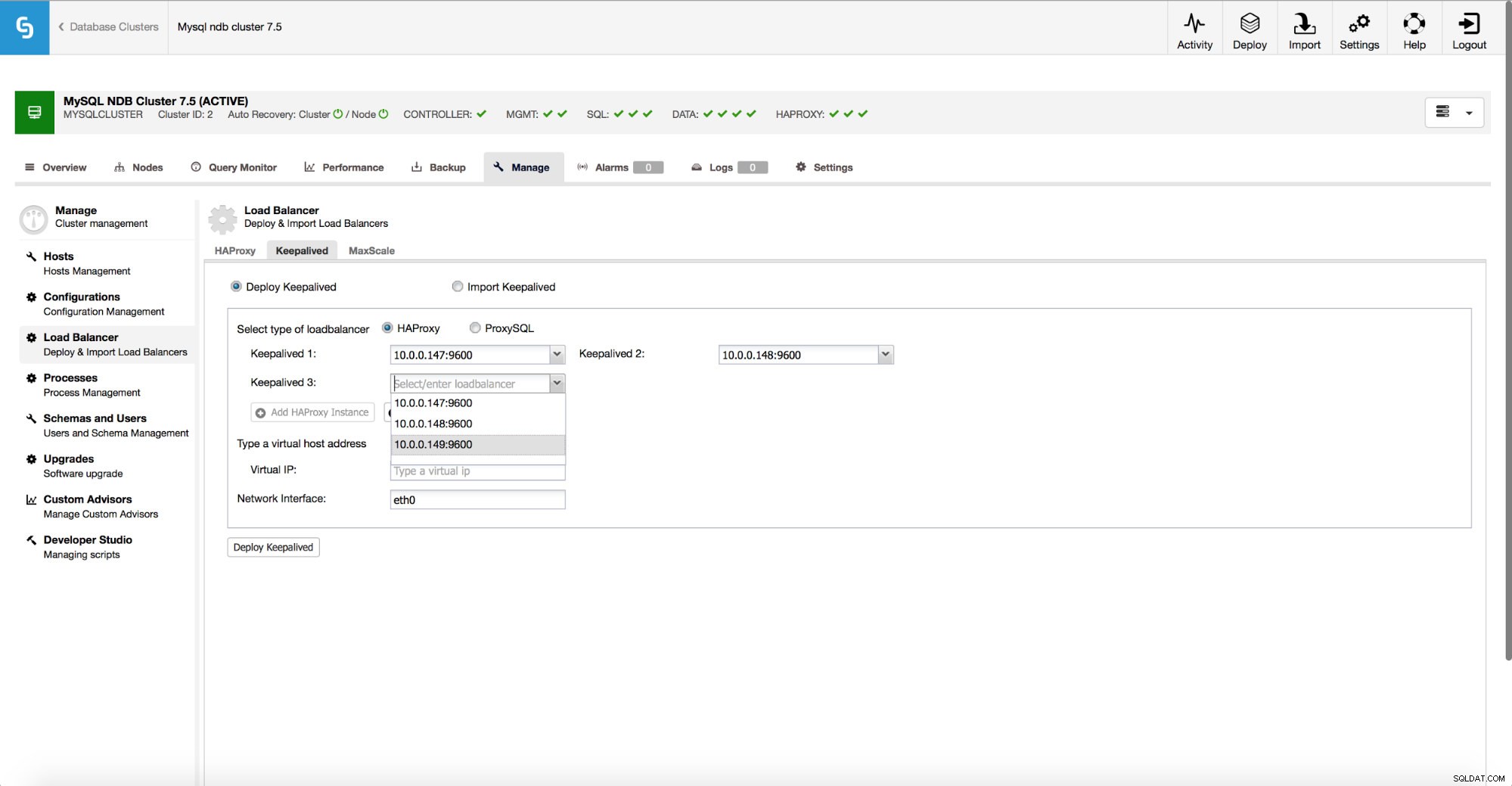
Proces wygląda następująco - definiujesz Wirtualne IP i interfejs, na którym ma być ono wywołane. Następnie możesz go wdrożyć dla każdego zainstalowanego HAProxy. Jeden z procesów Keepalived zostanie określony jako „master” i włączy VIP w swoim węźle. Twoja aplikacja łączy się następnie z tym konkretnym adresem IP. Gdy aktualnie aktywny HAProxy nie jest dostępny, VIP zostanie przeniesiony do innego dostępnego HAProxy, przywracając łączność.
Zarządzanie odzyskiwaniem
Chociaż klaster MySQL NDB może tolerować awarie poszczególnych węzłów, ważne jest, aby szybko na nie reagować. ClusterControl zapewnia automatyczne odzyskiwanie wszystkich komponentów klastra. Bez względu na to, co się nie powiedzie (węzeł zarządzania, węzeł danych lub węzeł SQL), ClusterControl automatycznie je zrestartuje.
Monitorowanie klastra MySQL NDB
Każde środowisko gotowe do produkcji musi być monitorowane. ClusterControl zapewnia szereg metryk do monitorowania. Na stronie „Przegląd” pokazujemy wykresy oparte na najważniejszych danych dla Twojego klastra. Możesz także tworzyć własne pulpity nawigacyjne, pokazujące dodatkowe dane, które byłyby przydatne w Twoim środowisku.
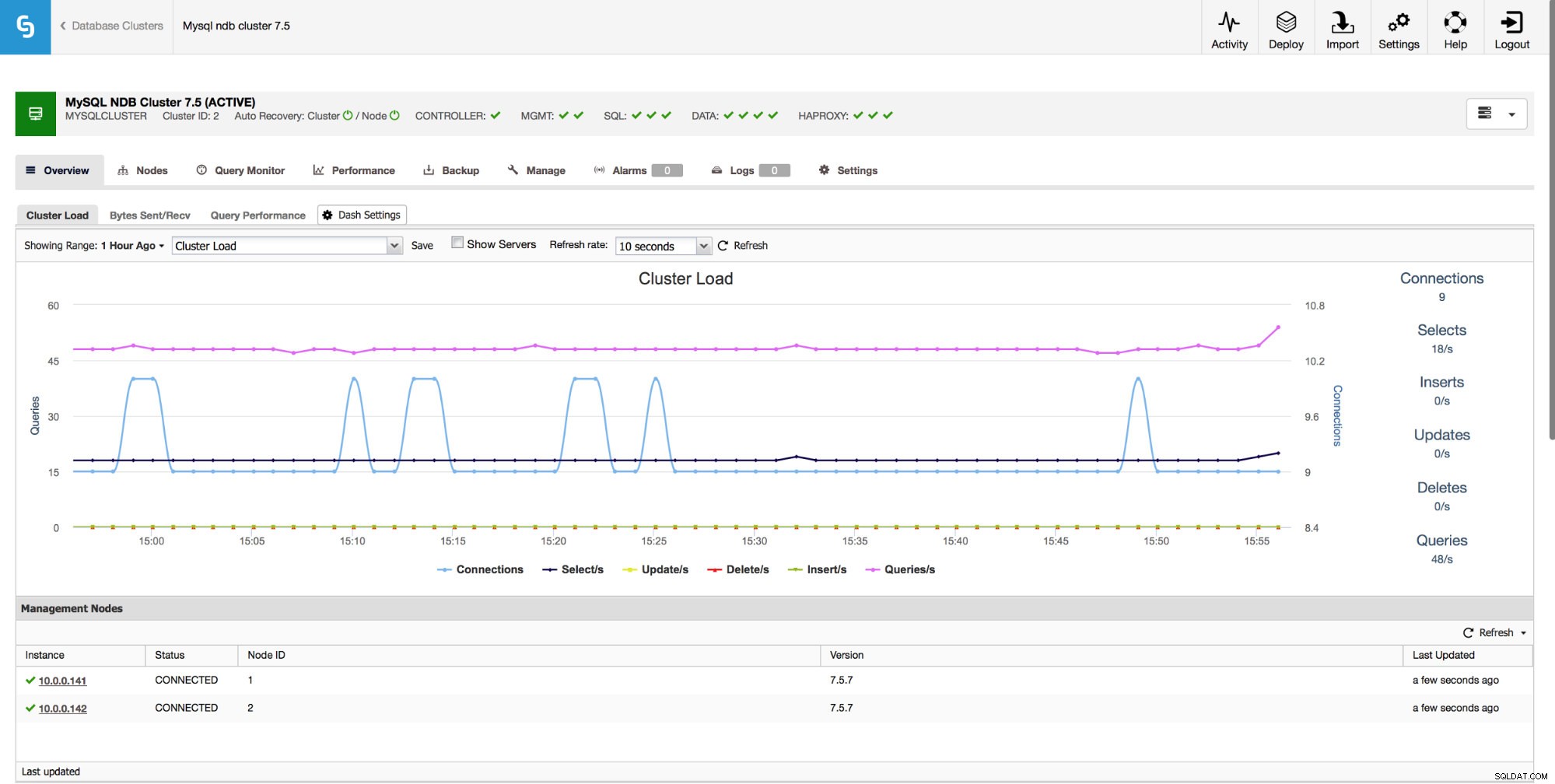
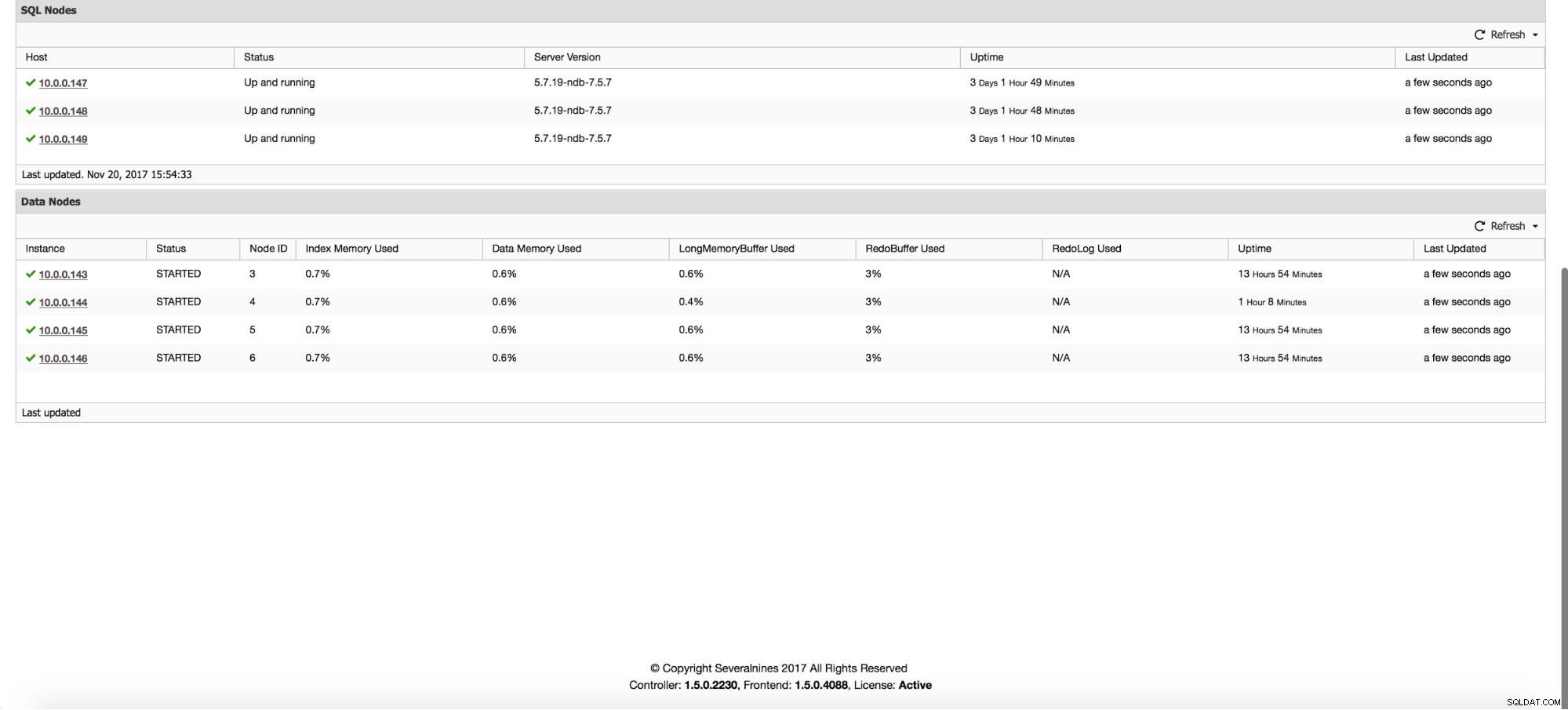
Oprócz wykresów strona „Przegląd” zapewnia wgląd w stan klastra na podstawie niektórych metryk klastra MySQL NDB, takich jak używana pamięć indeksów, pamięć danych i stan niektórych buforów.
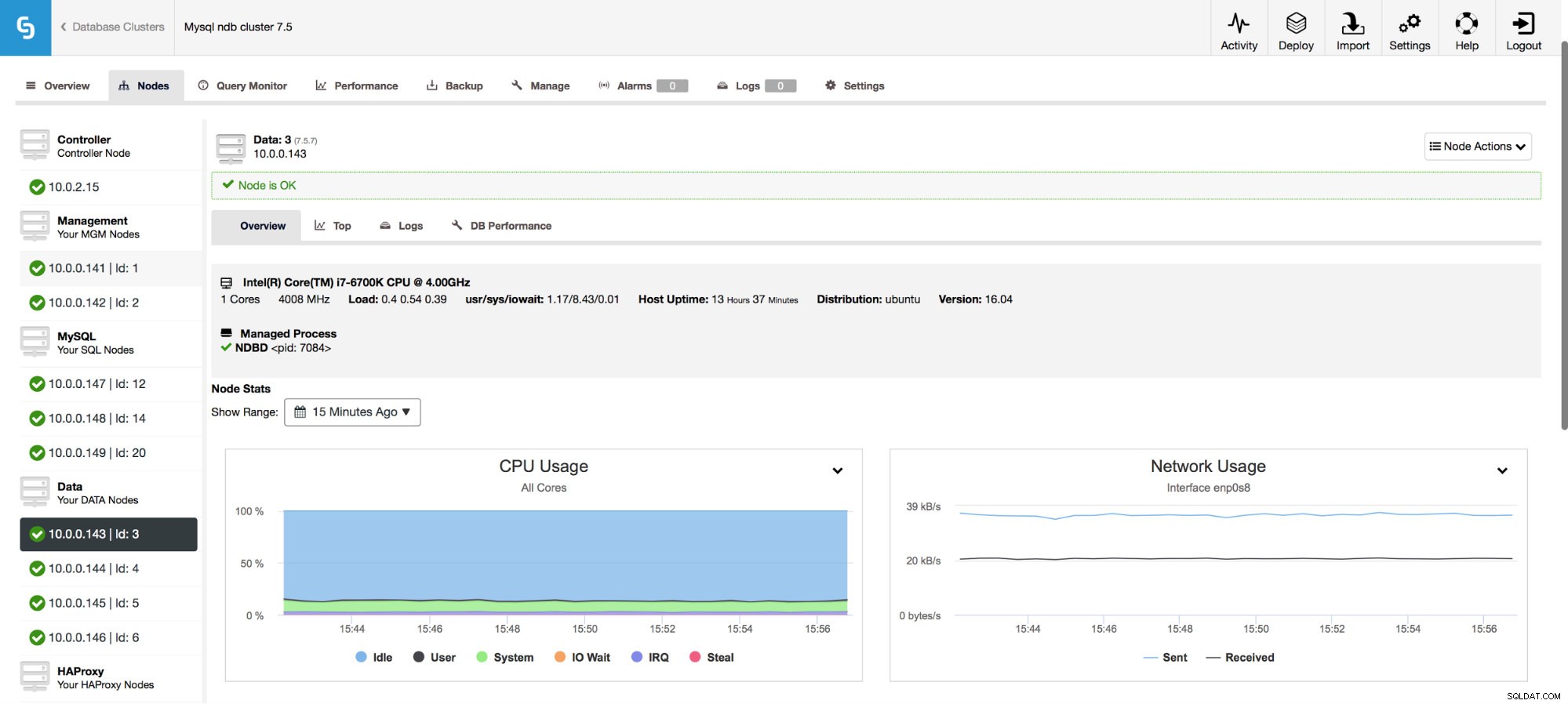
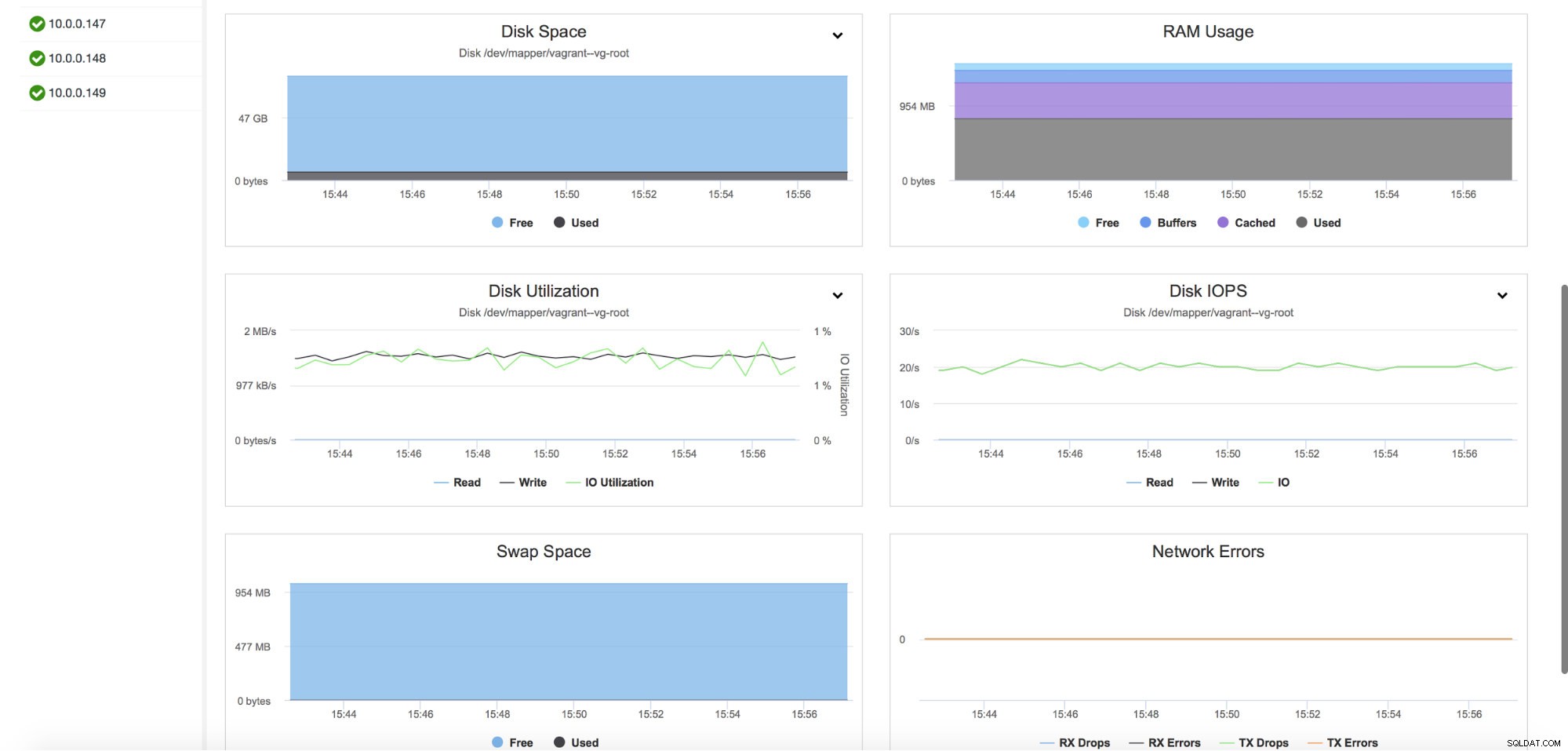
Zapewnia również monitorowanie metryk hosta, w tym wykorzystania procesora, pamięci RAM, statystyk dysku lub sieci. Te wykresy są również kluczowe w budowaniu obrazu kondycji klastra.
ClusterControl może również pomóc w zwiększeniu wydajności baz danych, zapewniając dostęp do Monitora zapytań, który przechowuje statystyki dotyczące ruchu.
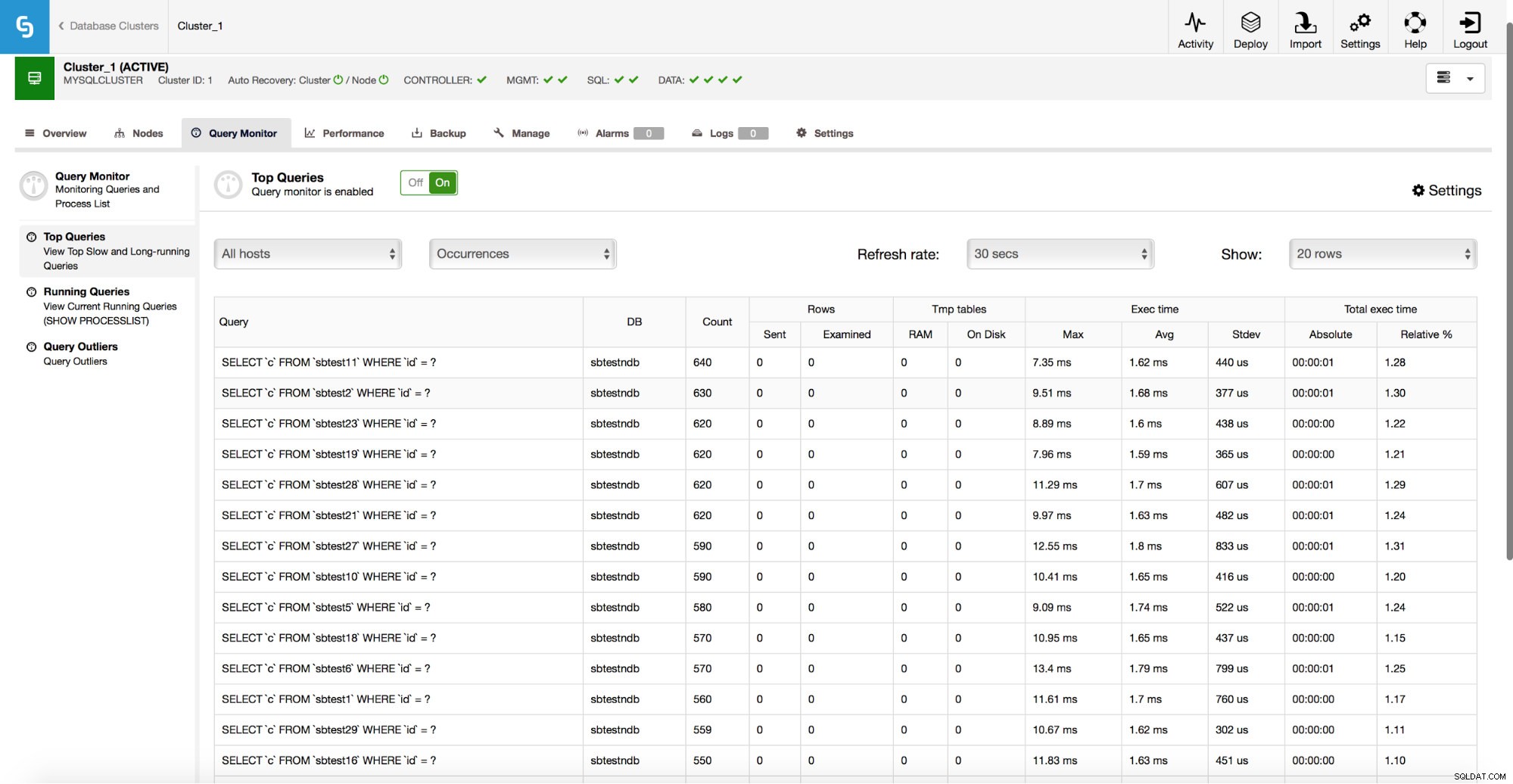
Jak widać na powyższym zrzucie ekranu, możesz zobaczyć, jakie zapytania są uruchamiane w Twoim klastrze, ile zapytań danego typu, jakie są czasy ich wykonania i łączne czasy wykonania. Pomaga to określić, które zapytania są powolne i które odpowiadają za większość ruchu. Następnie możesz skupić się na zapytaniach, które mogą zapewnić największą poprawę wydajności.