Systemy równoważenia obciążenia są niezbędnym elementem wysokiej dostępności bazy danych; zwłaszcza przy wprowadzaniu zmian w topologii przezroczystych dla aplikacji i wdrażaniu funkcji dzielenia odczytu i zapisu. ClusterControl zapewnia szereg funkcji do bezpiecznego wdrażania, monitorowania i konfigurowania wiodących w branży technologii równoważenia obciążenia typu open source.
W zeszłym roku dodaliśmy obsługę ProxySQL i dodaliśmy wiele ulepszeń dla HAProxy i MariaDB Maxscale. Kontynuujemy tę tradycję w najnowszej wersji ClusterControl 1.5.
Na podstawie opinii, które otrzymaliśmy od naszych użytkowników, poprawiliśmy sposób zarządzania ProxySQL. Dodaliśmy również obsługę HAProxy i Keepalive, aby działały na szczycie klastrów PostgreSQL.
W tym poście na blogu przyjrzymy się tym ulepszeniom...
ProxySQL — ulepszenia zarządzania użytkownikami
Wcześniej interfejs użytkownika pozwalał tylko na utworzenie nowego użytkownika lub dodanie istniejącego, po jednym na raz. Jedną z opinii, którą otrzymaliśmy od naszych użytkowników, było to, że zarządzanie dużą liczbą użytkowników jest dość trudne. Posłuchaliśmy i w ClusterControl 1.5 można teraz importować duże partie użytkowników. Zobaczmy, jak możesz to zrobić. Przede wszystkim musisz mieć wdrożony serwer ProxySQL. Następnie przejdź do węzła ProxySQL, a na karcie Użytkownicy powinieneś zobaczyć przycisk „Importuj użytkowników”.

Po kliknięciu otworzy się nowe okno dialogowe:

Tutaj możesz zobaczyć wszystkich użytkowników, których ClusterControl wykrył w Twoim klastrze. Możesz je przewijać i wybierać te, które chcesz zaimportować. Możesz także zaznaczyć lub odznaczyć wszystkich użytkowników w bieżącym widoku.

Gdy zaczniesz pisać w polu wyszukiwania, ClusterControl odfiltruje niepasujące wyniki, zawężając listę tylko do użytkowników istotnych dla Twojego wyszukiwania.
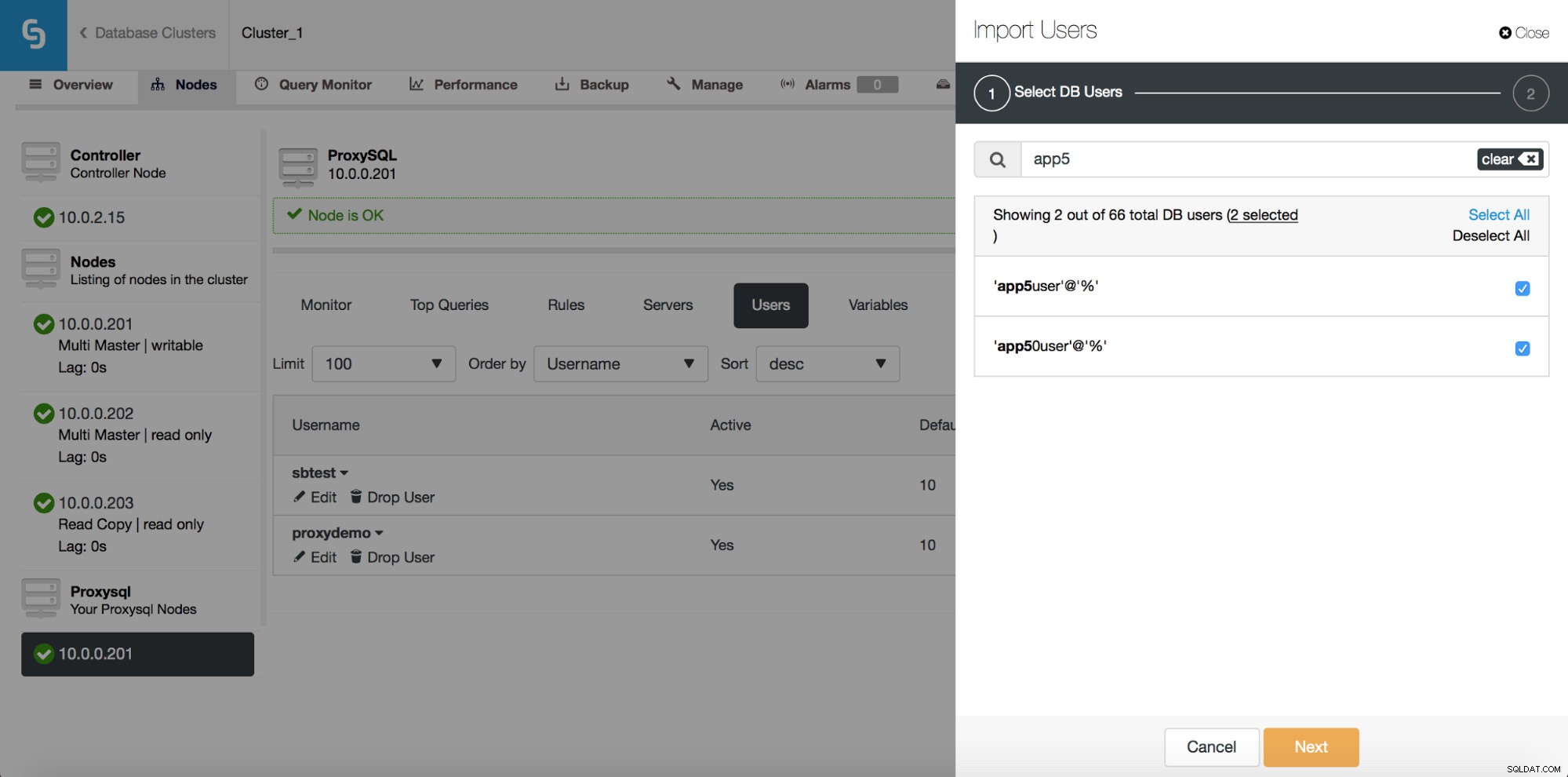
Możesz użyć przycisku „Zaznacz wszystko”, aby wybrać wszystkich użytkowników, którzy pasują do Twojego wyszukiwania. Oczywiście po wybraniu użytkowników, których chcesz zaimportować, możesz wyczyścić pole wyszukiwania i rozpocząć kolejne wyszukiwanie:

Zwróć uwagę na „(7 wybranych)” — pokazuje, ilu użytkowników łącznie (nie tylko z tego wyszukiwania) wybrałeś do zaimportowania. Możesz go również kliknąć, aby zobaczyć tylko tych użytkowników, których wybrałeś do zaimportowania.

Gdy dokonasz wyboru, możesz kliknąć „Dalej”, aby przejść do następnego ekranu.

Tutaj musisz zdecydować, jaka powinna być domyślna grupa hostów dla każdego użytkownika. Możesz to zrobić indywidualnie lub globalnie, dla całego zestawu lub podzbioru użytkowników będących wynikiem wyszukiwania.

Po kliknięciu przycisku „Importuj użytkowników” użytkownicy zostaną zaimportowani i pojawią się na karcie Użytkownicy.
ProxySQL — zarządzanie harmonogramem
Harmonogram ProxySQL to moduł podobny do crona, który pozwala ProxySQL na uruchamianie zewnętrznych skryptów w regularnych odstępach czasu. Harmonogram może być dość szczegółowy — do jednego wykonania na milisekundę. Zazwyczaj harmonogram służy do wykonywania skryptów sprawdzających Galera (takich jak proxysql_galera_checker.sh), ale może być również używany do wykonywania dowolnego innego skryptu, który Ci się podoba. W przeszłości ClusterControl używał harmonogramu do wdrażania skryptu sprawdzającego Galera, ale nie było to widoczne w interfejsie użytkownika. Od ClusterControl 1.5 masz teraz pełną kontrolę.

Jak widać, jeden skrypt został zaplanowany do uruchomienia co 2 sekundy (2000 milisekund) - jest to domyślna konfiguracja klastra Galera.

Powyższy zrzut ekranu pokazuje nam opcje edycji istniejących wpisów. Należy pamiętać, że ProxySQL obsługuje do 5 argumentów w skryptach, które będzie wykonywał za pomocą harmonogramu.

Jeśli chcesz, aby nowy skrypt został dodany do harmonogramu, możesz kliknąć przycisk „Dodaj nowy skrypt”, a zostanie wyświetlony ekran podobny do powyższego. Możesz także wyświetlić podgląd pełnego skryptu po wykonaniu. Po wypełnieniu wszystkich pól „Argument” i zdefiniowaniu interwału możesz kliknąć przycisk „Dodaj nowy skrypt”.

W rezultacie skrypt zostanie dodany do harmonogramu i będzie widoczny na liście zaplanowanych skryptów.
Pobierz oficjalny dokument już dziś Zarządzanie i automatyzacja PostgreSQL za pomocą ClusterControlDowiedz się, co musisz wiedzieć, aby wdrażać, monitorować, zarządzać i skalować PostgreSQLPobierz oficjalny dokumentPostgreSQL — budowanie stosu wysokiej dostępności
Skonfigurowanie replikacji z automatycznym przełączaniem awaryjnym jest dobre, ale aplikacje potrzebują prostego sposobu śledzenia zapisywalnego wzorca. Dodaliśmy więc obsługę HAProxy i Keepalive na szczycie klastrów PostgreSQL. Pozwala to naszym użytkownikom PostgreSQL na wdrożenie pełnego stosu wysokiej dostępności za pomocą ClusterControl.

Z podkarty Load Balancer możesz teraz wdrożyć HAProxy - jeśli wiesz, jak ClusterControl wdraża replikację MySQL, jest to bardzo podobna konfiguracja. Instalujemy HAProxy na danym hoście, dwa backendy, odczytuje na porcie 3308 i pisze na porcie 3307. Używa tcp-check, oczekując zwrócenia określonego łańcucha. Aby utworzyć ten ciąg, na wszystkich węzłach bazy danych wykonywane są następujące kroki. Po pierwsze, xinet.d jest skonfigurowany do uruchamiania usługi na porcie 9201 (aby uniknąć pomyłek z konfiguracją MySQL, która używa portu 9200).
# default: on
# description: postgreschk
service postgreschk
{
flags = REUSE
socket_type = stream
port = 9201
wait = no
user = root
server = /usr/local/sbin/postgreschk
log_on_failure += USERID
disable = no
#only_from = 0.0.0.0/0
only_from = 0.0.0.0/0
per_source = UNLIMITEDUsługa wykonuje skrypt /usr/local/sbin/postgreschk, który weryfikuje stan PostgreSQL i mówi, czy dany host jest dostępny i jakiego typu jest to host (master czy slave). Jeśli wszystko jest w porządku, zwraca łańcuch oczekiwany przez HAProxy.
Podobnie jak w przypadku MySQL, węzły HAProxy w klastrach PostgreSQL są widoczne w interfejsie użytkownika i można uzyskać dostęp do strony statusu:

Tutaj możesz zobaczyć oba backendy i sprawdzić, czy tylko master jest aktywny dla backendu r/w, a wszystkie węzły są dostępne za pośrednictwem backendu tylko do odczytu. Możesz także uzyskać statystyki dotyczące ruchu i połączeń.
HAProxy pomaga poprawić wysoką dostępność, ale może stać się pojedynczym punktem awarii. Musimy pójść o krok dalej i skonfigurować nadmiarowość za pomocą Keepalived.

W obszarze Zarządzaj -> Load balancer -> Keepalived wybierasz hosty HAProxy, których chcesz używać, a Keepalived zostanie wdrożony na nich z wirtualnym adresem IP podłączonym do wybranego interfejsu.
Od teraz cała łączność powinna iść do VIP, który zostanie dołączony do jednego z węzłów HAProxy. Jeśli ten węzeł ulegnie awarii, Keepalived wyłączy VIP na tym węźle i uruchomi go na innym węźle HAProxy.
To tyle, jeśli chodzi o funkcje równoważenia obciążenia wprowadzone w ClusterControl 1.5. Wypróbuj je i daj nam znać, jak się masz