Zła wydajność zapytań to najczęstszy problem, z którym muszą sobie radzić administratorzy baz danych. Istnieje wiele sposobów gromadzenia, przetwarzania i analizowania danych związanych z wydajnością zapytań — w niektórych z naszych poprzednich postów na blogu omówiliśmy jedno z najpopularniejszych narzędzi, pt-query-digest:
Zostań serią blogów MySQL DBA
- Analiza obciążenia SQL za pomocą pt-query-digest
- Głęboka analiza obciążenia SQL przy użyciu pt-query-digest
Jednak w przypadku korzystania z ClusterControl nie zawsze jest to potrzebne. Możesz wykorzystać dane dostępne w ClusterControl, aby rozwiązać swój problem. W tym poście na blogu przyjrzymy się, w jaki sposób ClusterControl może pomóc w rozwiązaniu problemów związanych z wydajnością zapytań.
Może się zdarzyć, że zapytanie nie zostanie zakończone w odpowiednim czasie. Zapytanie może zostać zablokowane z powodu pewnych problemów z blokowaniem, może nie być optymalne lub niewłaściwie zindeksowane lub może być zbyt ciężkie do ukończenia w rozsądnym czasie. Pamiętaj, że kilka nieindeksowanych złączeń może łatwo przeskanować miliardy wierszy, jeśli masz dużą produkcyjną bazę danych. Niezależnie od tego, co się stało, zapytanie prawdopodobnie wykorzystuje niektóre zasoby — czy to procesor, czy we/wy w przypadku niezoptymalizowanego zapytania, czy nawet po prostu blokady wierszy. Zasoby te są wymagane również w przypadku innych zapytań i mogą poważnie spowolnić działanie. Jednym z bardzo prostych, ale ważnych zadań byłoby wskazanie obraźliwego zapytania i zatrzymanie go.
Można to dość łatwo zrobić z interfejsu ClusterControl. Przejdź do zakładki Monitor zapytań -> sekcja Uruchamianie zapytań - powinieneś zobaczyć wynik podobny do poniższego zrzutu ekranu.
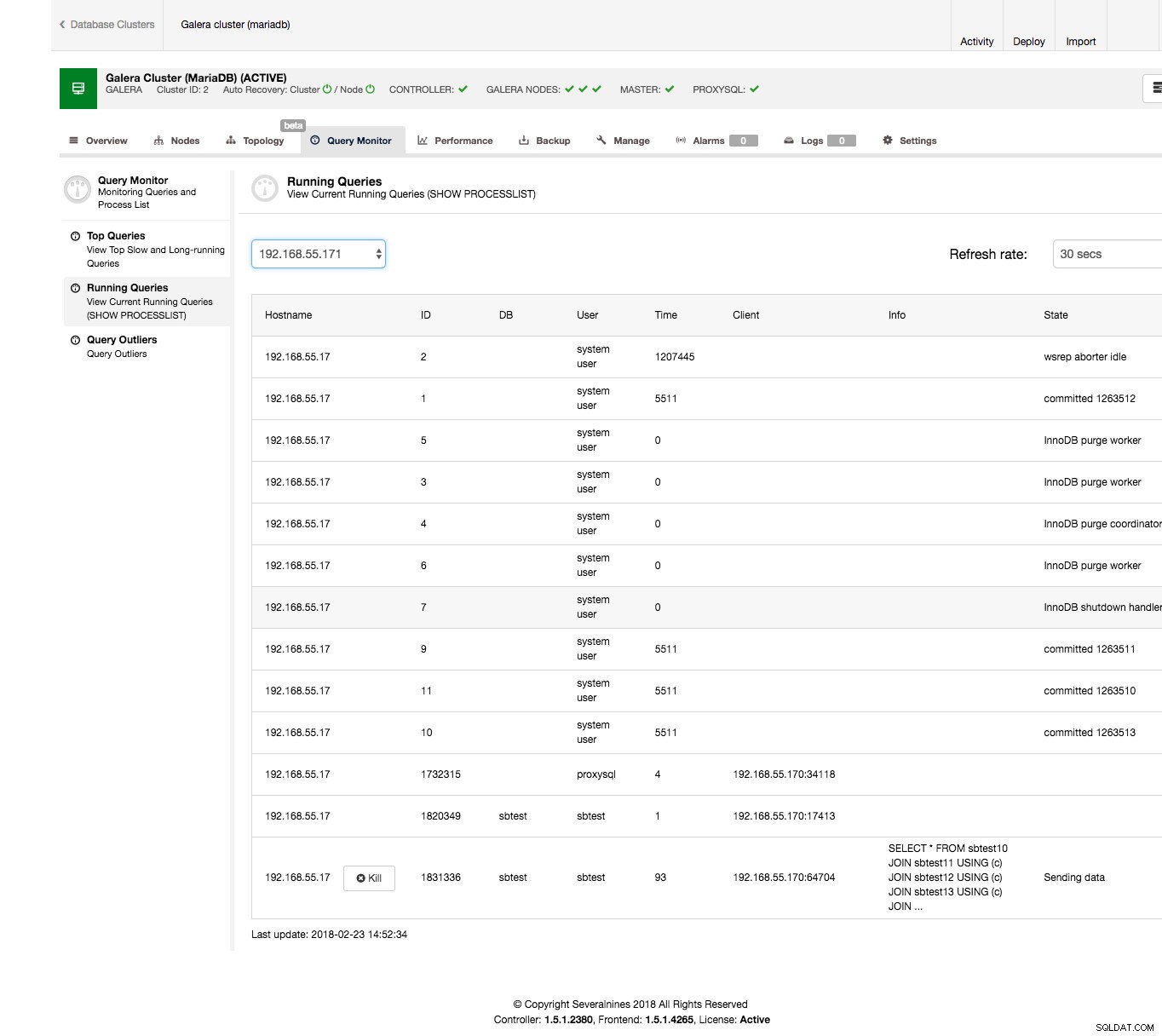
Jak widać, utknęliśmy w stosie zapytań. Zwykle obraźliwe zapytanie to takie, które zajmuje dużo czasu, możesz chcieć je zabić. Możesz również dokładniej to zbadać, aby upewnić się, że wybrałeś właściwy. W naszym przypadku wyraźnie widzimy SELECT … FOR UPDATE, który łączy kilka tabel i który jest w stanie „Wysyłanie danych”, co oznacza, że przetwarza dane przez ostatnie 90 sekund.
Innym rodzajem pytania, na które administrator może potrzebować odpowiedzi, jest:wykonanie których zapytań zajmuje najwięcej czasu? To częste pytanie, ponieważ takie zapytania mogą być nisko zawieszonym owocem - mogą być optymalizowane, a im dłuższy czas wykonania odpowiada danemu zapytaniu w całym zestawie zapytań, tym większy zysk z jego optymalizacji. Jest to proste równanie — jeśli zapytanie odpowiada za 50% całkowitego czasu wykonania, przyspieszenie 10 razy da o wiele lepszy wynik niż optymalizacja zapytania, które odpowiada za zaledwie 1% całkowitego czasu wykonania.
ClusterControl może pomóc w odpowiedzi na takie pytania, ale najpierw musimy upewnić się, że monitor zapytań jest włączony. Możesz przełączyć Monitor zapytań na WŁĄCZONY na stronie Monitor zapytań. Ponadto możesz skonfigurować opcje „Długi czas zapytań” i „Zapisuj zapytania nie używające indeksów” w Ustawieniach, aby dopasować je do obciążenia:
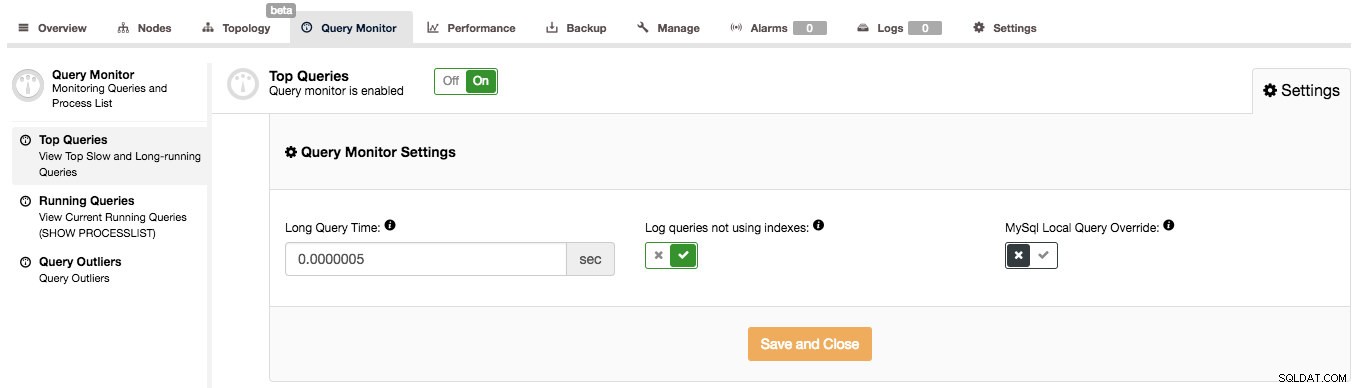
Monitor zapytań w ClusterControl działa w dwóch trybach, w zależności od tego, czy masz dostępny schemat wydajności z wymaganymi danymi w uruchomionych zapytaniach, czy nie. Jeśli jest dostępny (a tak jest domyślnie w MySQL 5.6 i nowszych), Performance Schema będzie używany do zbierania danych zapytań, minimalizując wpływ na system. W przeciwnym razie zostanie użyty dziennik powolnych zapytań i wszystkie ustawienia widoczne na powyższym zrzucie ekranu. Są one dość dobrze wyjaśnione w interfejsie użytkownika, więc nie ma potrzeby tego robić tutaj. Gdy Monitor zapytań korzysta ze schematu wydajności, te ustawienia nie są używane (z wyjątkiem włączania/wyłączania Monitora zapytań w celu włączenia/wyłączenia zbierania danych).
Po potwierdzeniu, że Monitor zapytań jest włączony w ClusterControl, możesz przejść do Monitor zapytań -> Najważniejsze zapytania, gdzie zostanie wyświetlony ekran podobny do poniższego:
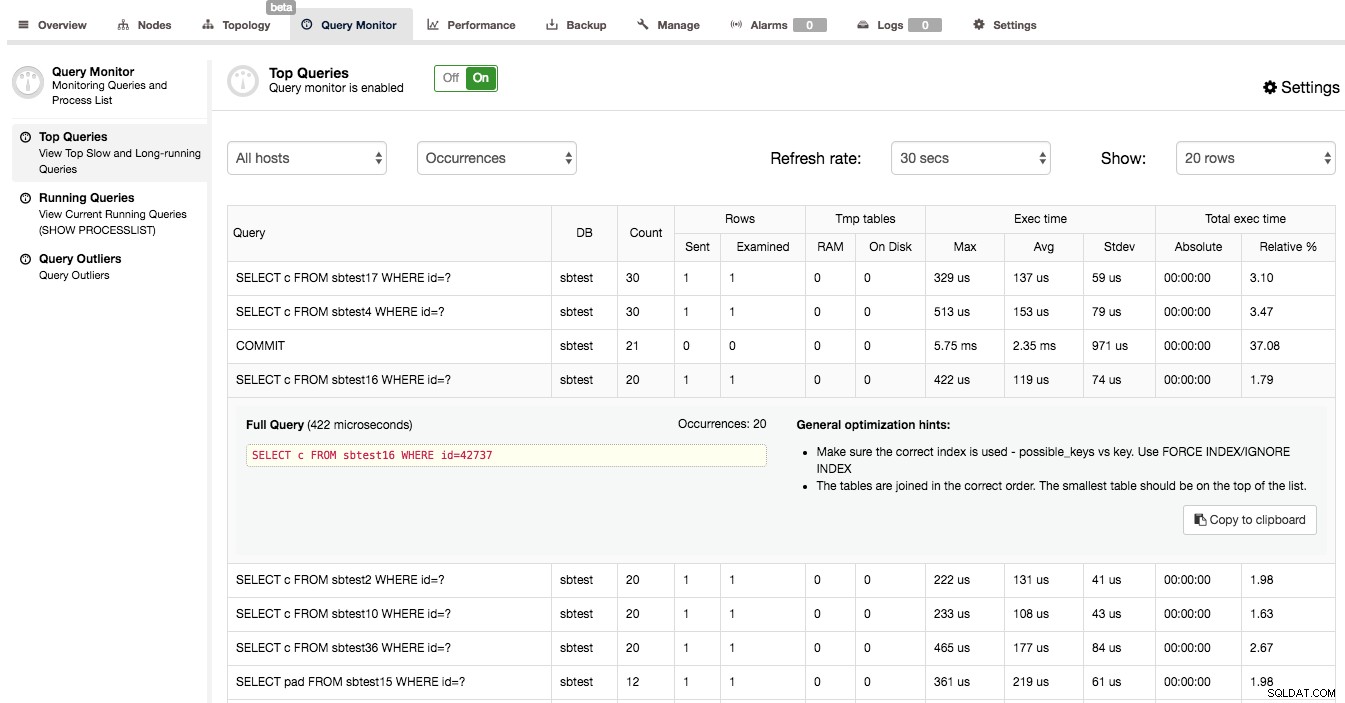
Tutaj możesz zobaczyć listę najdroższych zapytań (pod względem czasu wykonania), które trafiły do naszego klastra. Każdy z nich posiada dodatkowe szczegóły - ile razy został wykonany, ile wierszy zostało przebadanych lub wysłanych do klienta, jak różnił się czas wykonania, ile czasu klaster poświęcił na wykonanie danego typu zapytania. Zapytania są pogrupowane według typu zapytania i schematu.
Możesz być zaskoczony, gdy dowiesz się, że głównym miejscem, w którym spędzany jest czas wykonania, jest zapytanie „COMMIT”. W rzeczywistości jest to dość typowe dla szybkich zapytań OLTP wykonywanych w klastrze Galera. Zawarcie transakcji jest kosztownym procesem, ponieważ musi nastąpić certyfikacja. Prowadzi to do tego, że COMMIT jest jednym z najbardziej czasochłonnych zapytań w zestawie zapytań.
Kiedy klikniesz na zapytanie, możesz zobaczyć pełne zapytanie, maksymalny czas wykonania, liczbę wystąpień, kilka ogólnych wskazówek dotyczących optymalizacji i dane wyjściowe EXPLAIN - całkiem przydatne do określenia, czy coś jest z nim nie tak. W naszym przykładzie sprawdziliśmy SELECT … FOR UPDATE z dużą liczbą przebadanych wierszy. Zgodnie z oczekiwaniami, to zapytanie jest przykładem fatalnego SQL - JOIN, które nie używa żadnego indeksu. Możesz zobaczyć na wyjściu EXPLAIN, że żaden indeks nie jest używany, ani jeden nie był nawet uważany za możliwy do użycia. Nic dziwnego, że to zapytanie poważnie wpłynęło na wydajność naszego klastra.
Innym sposobem na uzyskanie wglądu w wydajność zapytań jest zajrzenie do Monitor zapytań -> Wartości odstające zapytań. Zasadniczo jest to lista zapytań, których wydajność znacznie różni się od ich średniej.
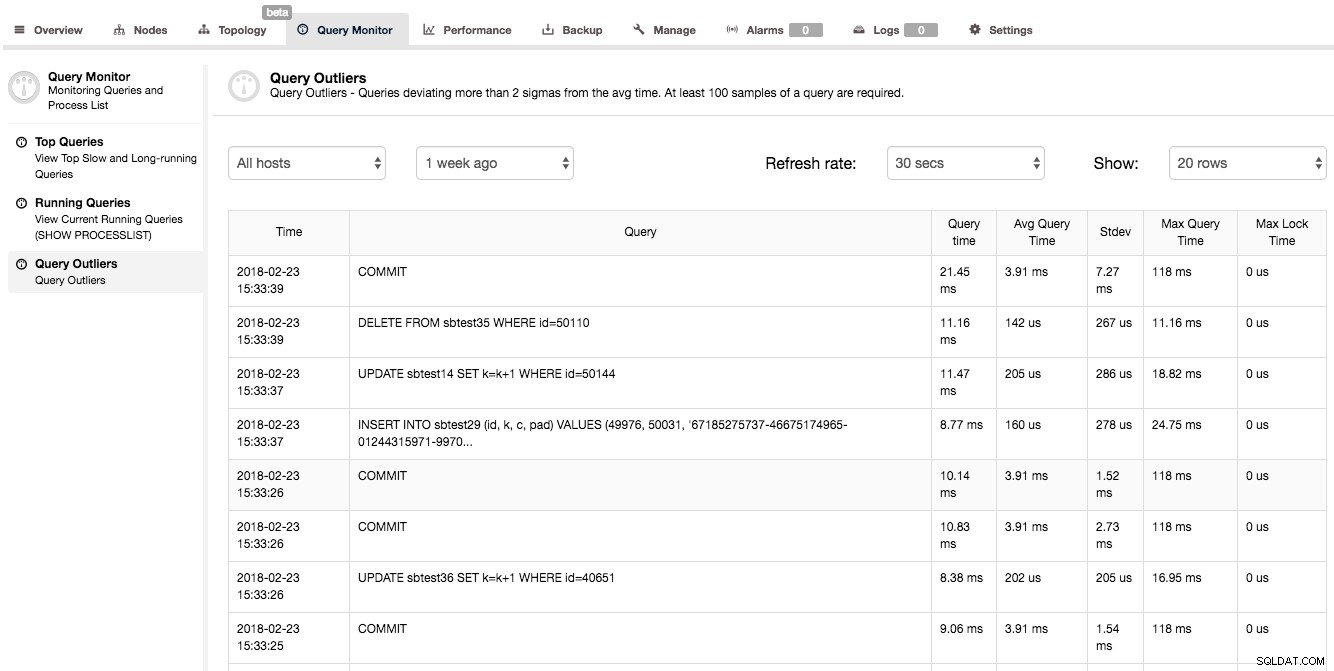
Jak widać na powyższym zrzucie ekranu, drugie zapytanie zajęło 0,01116s (czas podany jest w milisekundach), gdzie średni czas wykonania tego zapytania jest znacznie niższy (0,00142s). Mamy również dodatkowe informacje statystyczne dotyczące odchylenia standardowego i maksymalnego czasu wykonania zapytania. Taka lista zapytań może wydawać się mało przydatna – to nie do końca prawda. Kiedy widzisz zapytanie na tej liście, oznacza to, że coś było inne niż zwykle - zapytanie nie zostało ukończone w normalnym czasie. Może to wskazywać na pewne problemy z wydajnością w twoim systemie i sygnał, że powinieneś zbadać inne metryki i sprawdzić, czy w tym czasie coś się wydarzyło.
Ludzie skupiają się na osiąganiu maksymalnej wydajności, zapominając, że wysoka przepustowość nie wystarczy – musi być również spójna. Użytkownicy lubią stabilną wydajność – możesz być w stanie wycisnąć ze swojego systemu więcej transakcji na sekundę, ale jeśli oznacza to, że niektóre transakcje zaczną się zatrzymywać na kilka sekund, to nie jest tego warte. Patrzenie na histogram zapytań w ClusterControl pomaga zidentyfikować takie problemy ze spójnością w kombinacji zapytań.
Miłego monitorowania zapytań!
PS.:Aby rozpocząć korzystanie z ClusterControl, kliknij tutaj!