Poniżej znajduje się fragment naszej białej księgi „Jak projektować wysoce dostępne środowiska baz danych typu open source”, które można pobrać bezpłatnie.
Kilka słów o „wysokiej dostępności”
W dzisiejszych czasach wysoka dostępność jest niezbędna przy każdym poważnym wdrożeniu. Dawno minęły czasy, kiedy można było zaplanować przestój bazy danych na kilka godzin w celu przeprowadzenia konserwacji. Jeśli Twoje usługi nie są dostępne, tracisz klientów i pieniądze. Dlatego zapewnienie wysokiej dostępności środowiska bazy danych ma zazwyczaj jeden z najwyższych priorytetów.
Stanowi to duże wyzwanie dla administratorów baz danych. Po pierwsze, jak sprawdzić, czy Twoje środowisko jest wysoce dostępne, czy nie? Jak byś to zmierzył? Jakie kroki należy podjąć, aby poprawić dostępność? Jak zaprojektować konfigurację, aby była jak najbardziej dostępna od samego początku?
Istnieje wiele rozwiązań HA dostępnych w ekosystemie MySQL (i MariaDB), ale skąd mamy wiedzieć, którym z nich możemy zaufać? Niektóre rozwiązania mogą działać w określonych warunkach, ale mogą powodować więcej problemów, gdy zostaną zastosowane poza tymi warunkami. Nawet podstawowa funkcjonalność, taka jak replikacja MySQL, którą można skonfigurować na wiele sposobów, może spowodować znaczne szkody – na przykład replikacja cykliczna z wieloma zapisywalnymi wzorcami. Chociaż łatwo jest skonfigurować „konfigurację z wieloma wzorcami” za pomocą replikacji, może to bardzo łatwo zepsuć i pozostawić nas z rozbieżnymi zestawami danych na różnych serwerach. W przypadku bazy danych, która jest często uważana za jedyne źródło prawdy, naruszenie integralności danych może mieć katastrofalne konsekwencje.
W kolejnych rozdziałach omówimy wymagania dotyczące wysokiej dostępności w
konfiguracjach baz danych oraz jak zaprojektować system od podstaw.
Pomiar wysokiej dostępności
Czym jest wysoka dostępność? Aby móc zdecydować, czy dane środowisko jest wysoce dostępne, czy nie, trzeba mieć do tego pewne metryki. Istnieje wiele sposobów mierzenia wysokiej dostępności, skupimy się na niektórych z najbardziej podstawowych rzeczy.
Najpierw jednak zastanówmy się, o co chodzi w tej całej wysokiej dostępności? Jaki jest jego cel? Chodzi o upewnienie się, że Twoje środowisko spełnia swoje zadanie. Cel można zdefiniować na wiele sposobów, ale zazwyczaj będzie to dostarczenie jakiejś usługi. W świecie baz danych zazwyczaj jest to w pewnym stopniu związane z danymi. Może udostępniać dane do Twojej aplikacji wewnętrznej. Może to być przechowywanie danych i umożliwianie ich odpytywania przez procesy analityczne. Może to być przechowywanie niektórych danych dla użytkowników i udostępnianie ich na żądanie. Gdy już ustalimy cel, możemy ustalić zaangażowane czynniki sukcesu. Pomoże nam to określić, co oznacza wysoka dostępność w naszym konkretnym przypadku.
SLA
Umowa o poziomie usług (SLA). Dość powszechne jest również definiowanie umów SLA dla usług wewnętrznych. Co to jest umowa SLA? Jest to definicja poziomu usług, który planujesz świadczyć swoim klientom. Ma to na celu lepsze zrozumienie, jaki poziom stabilności planujesz dla usługi, którą kupili lub zamierzają kupić. Istnieje wiele metod, które możesz wykorzystać do przygotowania umowy SLA, ale typowe to:
- Dostępność usługi (w procentach)
- Reakcja usługi – opóźnienie (średnia, maks., 95 percentyl, 99 percentyl)
- Utrata pakietów w sieci (procent)
- Przepustowość (średnia, minimalna, 95 percentyl, 99 percentyl)
Jednak może się to stać bardziej złożone. W podzielonym środowisku wielu użytkowników możesz zdefiniować, powiedzmy, SLA jako:„Usługa będzie dostępna przez 99,99% czasu, przestój jest deklarowany, gdy dotyczy to ponad 2% użytkowników. Rozwiązanie żadnego incydentu nie może zająć więcej niż 15 minut”. Taka umowa SLA może być również rozszerzona o czas odpowiedzi na zapytanie:„przestój jest wywoływany, jeśli 99 percentyl opóźnienia dla zapytań przekroczy 200 milisekund”.
Dziewiątki
Dostępność mierzy się zazwyczaj w „dziewiątkach”, przyjrzyjmy się, co dokładnie gwarantuje dana liczba „dziewiątek”. Poniższa tabela pochodzi z Wikipedii:
| % dostępności | Przestój rocznie | Przestój miesięcznie | Przestój tygodniowo | Przestój dziennie |
|---|---|---|---|---|
| 90% ("jeden dziewięć") | 36,5 dnia | 72 godziny | 16,8 godzin | 2,4 godziny |
| 95% („półtora dziewiątek”) | 18,25 dni | 36 godzin | 8,4 godziny | 1,2 godziny |
| 97% | 10,96 dni | 21,6 godziny | 5,04 godziny | 43,2 min |
| 98% | 7,30 dnia | 14,4 godziny | 3,36 godziny | 28,8 min |
| 99% („dwie dziewiątki”) | 3,65 dnia | 7,20 godziny | 1,68 godziny | 14,4 min |
| 99,5% („dwie i pół dziewiątek”) | 1,83 dnia | 3,60 godziny | 50,4 min | 7,2 min |
| 99,8% | 17,52 godziny | 86,23 min | 20,16 min | 2,88 min |
| 99,9% („trzy dziewiątki”) | 8,76 godziny | 43,8 min | 10,1 min | 1,44 min |
| 99,95% („trzy i pół dziewiątki”) | 4,38 godziny | 21,56 min | 5,04 min | 43,2 s |
| 99,99% („cztery dziewiątki”) | 52,56 min | 4,38 min | 1,01 min | 8,64 s |
| 99,995% („cztery i pół dziewiątki”) | 26,28 min | 2,16 min | 30,24 s | 4,32 s |
| 99,999% („pięć dziewiątek”) | 5,26 min | 25,9 s | 6,05 s | 864,3 ms |
| 99,9999% („sześć dziewiątek”) | 31,5 s | 2,59 s | 604,8 ms | 86,4 ms |
| 99,99999% („siedem dziewiątek”) | 3,15 s | 262,97 ms | 60,48 ms | 8,64 ms |
| 99,999999% („osiem dziewiątek”) | 315,569 ms | 26,297 ms | 6,048 ms | 0,864 ms |
| 99,9999999% („dziewięć dziewiątek”) | 31,5569 ms | 2,6297 ms | 0,6048 ms | 0,0864 ms |
Jak widać, szybko się eskaluje. Pięć dziewiątek (dostępność 99,999%) odpowiada 5,26 minutom przestoju w ciągu roku. Dostępność można też liczyć w różnych, mniejszych przedziałach:miesięcznie, tygodniowo, dziennie. Pamiętaj o tych liczbach, ponieważ przydadzą się one, gdy zaczniemy omawiać koszty związane z utrzymaniem różnych poziomów dostępności.
Pomiar dostępności
Aby stwierdzić, czy jest przestój, czy nie, trzeba mieć wgląd w środowisko. Musisz śledzić wskaźniki, które definiują dostępność Twoich systemów. Należy pamiętać, że należy mierzyć go z punktu widzenia klienta, biorąc pod uwagę szerszy obraz. Nie ma znaczenia, czy Twoje bazy danych są aktywne, jeśli, powiedzmy, z powodu problemu z siecią żadna aplikacja nie może do nich dotrzeć. Każdy element składowy Twojej konfiguracji ma wpływ na dostępność.
Jednym z dobrych miejsc do szukania danych o dostępności są logi serwera WWW. Wszystkie żądania, które zakończyły się błędami, oznaczają, że coś się stało. Może to być błąd HTTP 500 zwrócony przez aplikację, ponieważ połączenie z bazą danych nie powiodło się. Mogą to być błędy programistyczne wskazujące na pewne problemy z bazą danych, które trafiły do dziennika błędów Apache. Możesz również użyć prostej metryki jako czasu pracy serwerów baz danych, chociaż przy bardziej złożonych umowach SLA może być trudne określenie, w jaki sposób niedostępność jednej bazy danych wpłynęła na twoją bazę użytkowników. Bez względu na to, co robisz, powinieneś używać więcej niż jednej metryki — jest to potrzebne do uchwycenia problemów, które mogły wystąpić na różnych warstwach Twojego środowiska.
Magiczny numer:„Trzy”
Choć wysoka dostępność wiąże się również z redundancją, w przypadku klastrów bazodanowych trzy to magiczna liczba. Nie wystarczy mieć dwa węzły do redundancji - taka konfiguracja nie zapewnia wbudowanej wysokiej dostępności. Jasne, może to być lepsze niż pojedynczy węzeł, ale do odzyskania usług wymagana jest interwencja człowieka. Zobaczmy, dlaczego tak jest.
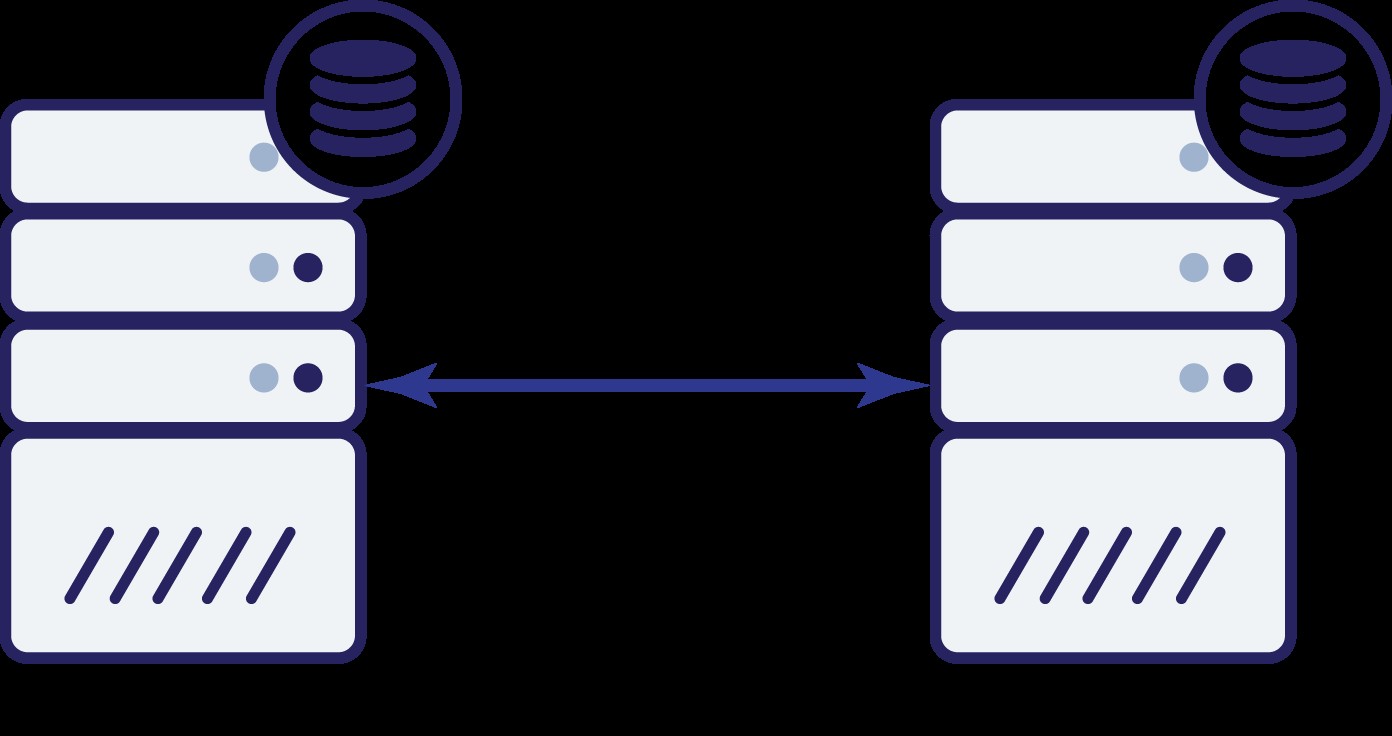
Załóżmy, że mamy dwa węzły, A i B. Między nimi jest połączenie sieciowe. Załóżmy, że zarówno A, jak i B obsługują zapisy, a aplikacja losowo wybiera, gdzie się połączyć (co oznacza, że część aplikacji połączy się z węzłem A, a druga część z węzłem B). Teraz wyobraźmy sobie, że mamy problem z siecią, który powoduje utratę łączności sieciowej między A i B.
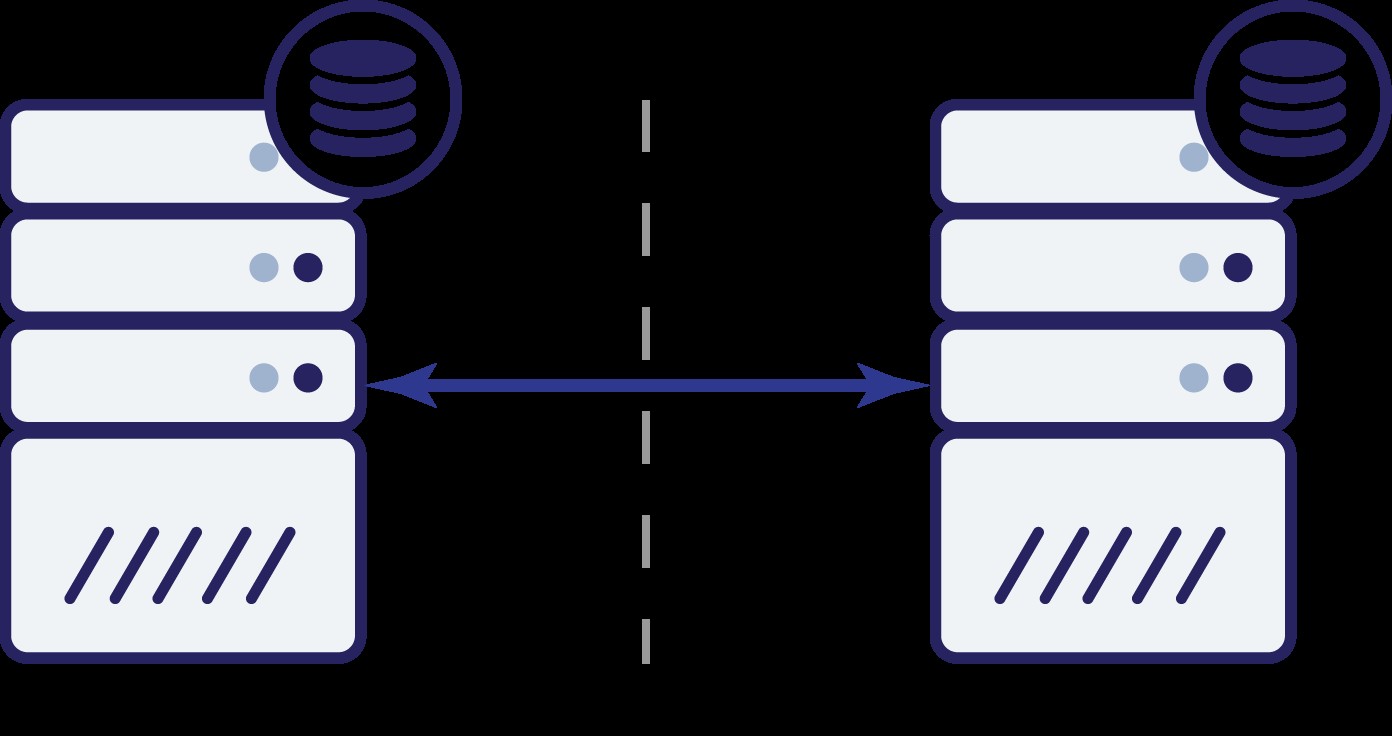
Co teraz? Ani A, ani B nie mogą znać stanu drugiego węzła. Oba węzły mogą wykonać dwie czynności:
- Mogą nadal akceptować ruch
- Mogą przestać działać i odmówić obsługi jakiegokolwiek ruchu
Pomyślmy o pierwszej opcji. Dopóki drugi węzeł rzeczywiście nie działa, jest to preferowane działanie — chcemy, aby nasza baza danych nadal obsługiwała ruch. To jest przecież główna idea wysokiej dostępności. Co by się jednak stało, gdyby oba węzły nadal przyjmowały ruch, gdy byłyby od siebie rozłączone? Po obu stronach zostaną dodane nowe dane, a zestawy danych nie będą zsynchronizowane. Kiedy problem z siecią zostanie rozwiązany, połączenie tych dwóch zbiorów danych będzie trudnym zadaniem. Dlatego niedopuszczalne jest, aby oba węzły były sprawne i działały. Problem polega na tym - jak węzeł A może stwierdzić, czy węzeł B jest żywy, czy nie (i odwrotnie)? Odpowiedź brzmi – nie może. Jeśli cała łączność nie działa, nie ma możliwości odróżnienia uszkodzonego węzła od uszkodzonej sieci. W rezultacie jedynym bezpiecznym działaniem jest przerwanie wszystkich operacji przez oba węzły i odmowa
obsługi ruchu.
Zastanówmy się teraz, jak trzeci węzeł może nam pomóc w takiej sytuacji.
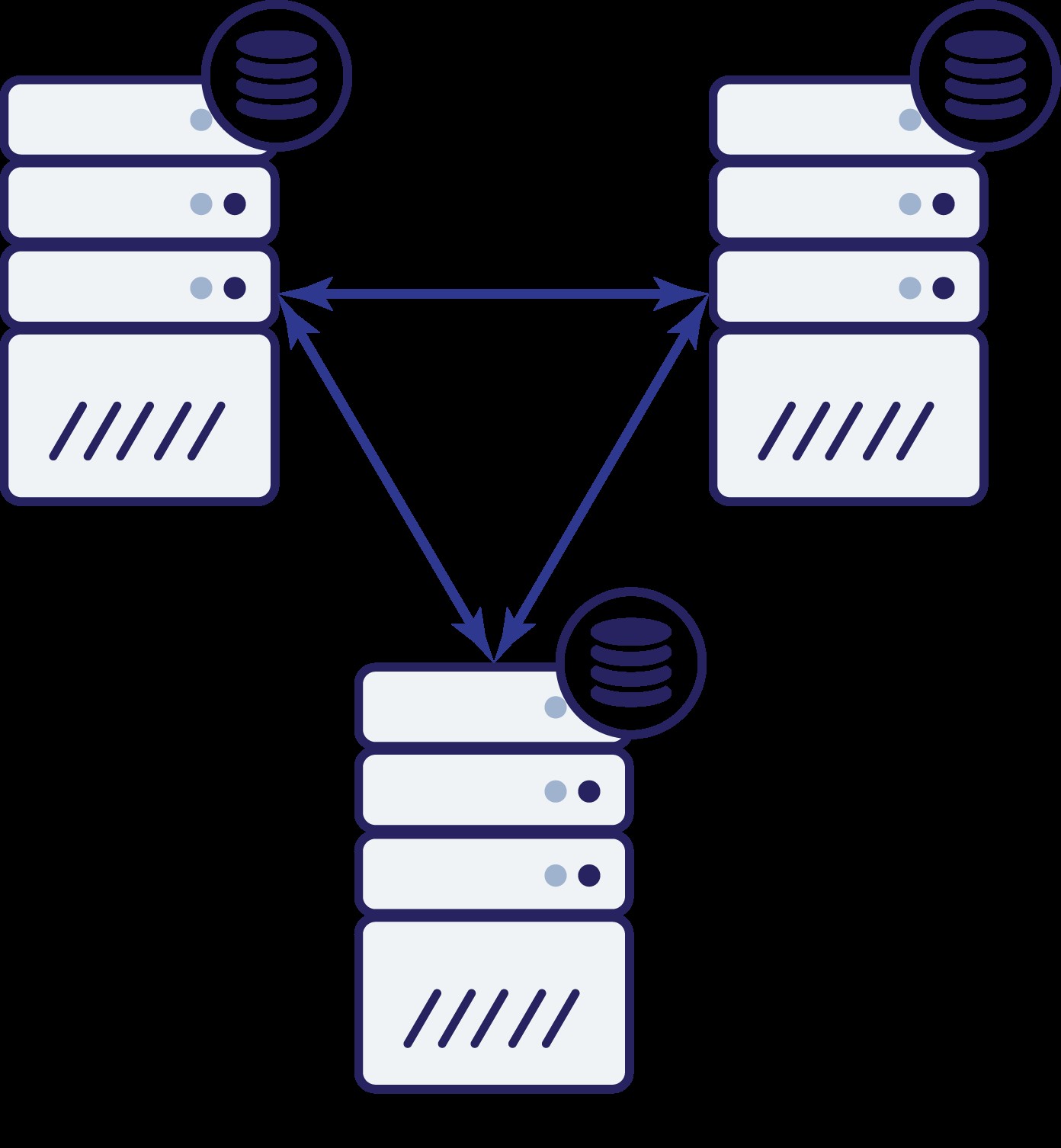
Mamy więc teraz trzy węzły:A, B i C. Wszystkie są ze sobą połączone, wszystkie obsługują odczyty i zapisy.
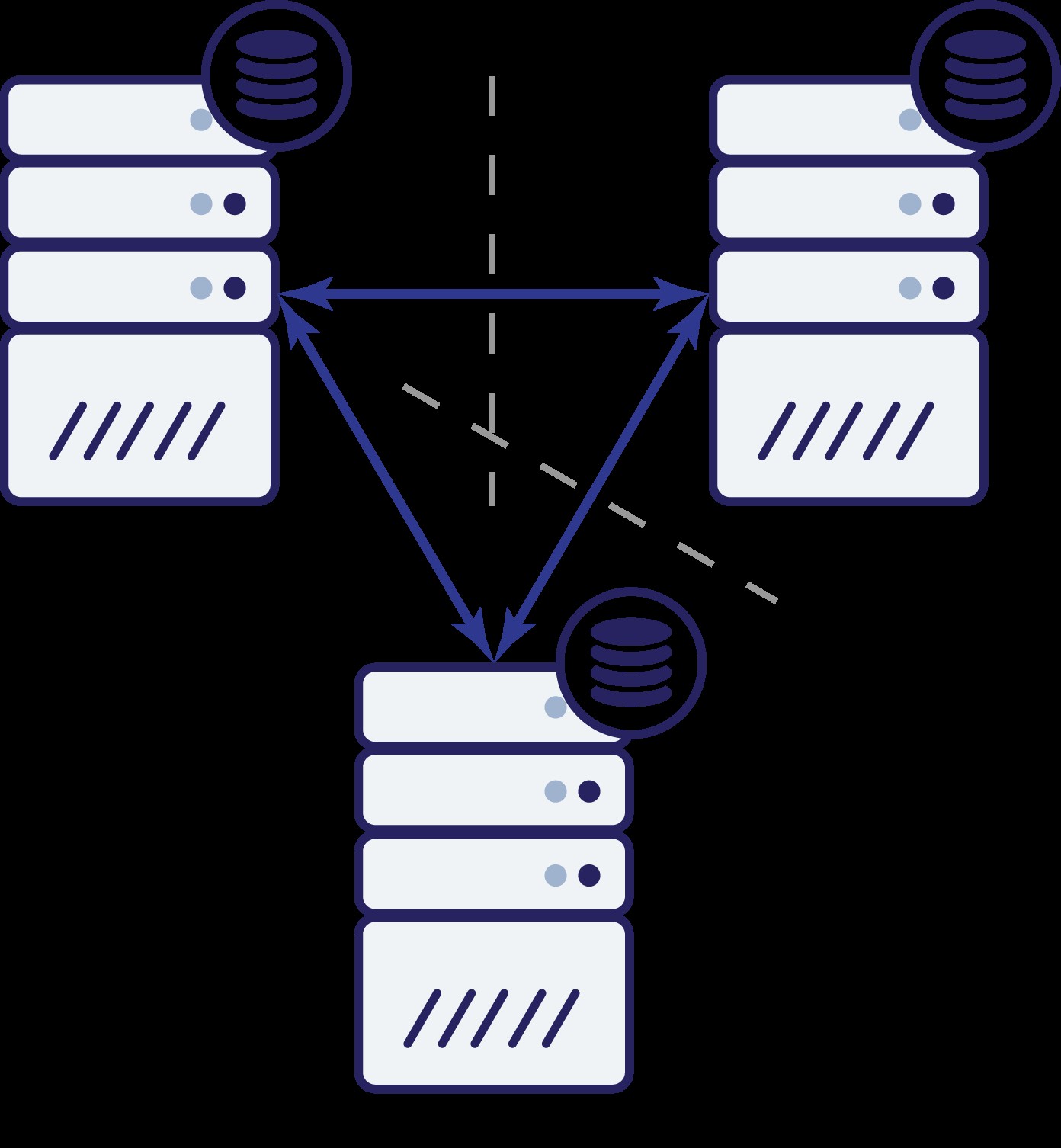
Ponownie, tak jak w poprzednim przykładzie, węzeł B został odcięty od reszty klastra z powodu problemów z siecią. Co może się wydarzyć dalej? Cóż, sytuacja jest dość podobna do tej, o której mówiliśmy wcześniej. Dwie opcje — węzeł B może być wyłączony (a reszta klastra powinna działać dalej) lub może być włączony, w takim przypadku nie powinien on obsługiwać żadnego ruchu. Czy możemy teraz powiedzieć, jaki jest stan klastra? Aktualnie tak. Widzimy, że węzły A i C mogą się ze sobą komunikować i w rezultacie mogą zgodzić się, że węzeł B jest niedostępny. Nie będą w stanie powiedzieć, dlaczego tak się stało, ale wiedzą, że z trzech węzłów w klastrze dwa nadal mają łączność między sobą. Biorąc pod uwagę, że te dwa węzły stanowią większość klastra, umożliwia to dalszą obsługę ruchu. Jednocześnie węzeł B może również wydedukować, że problem jest po jego stronie. Nie może uzyskać dostępu ani do węzła A, ani do węzła C, przez co węzeł B jest oddzielony od reszty klastra. Ponieważ jest odizolowany i nie jest częścią większości (1 z 3), jedynym bezpiecznym działaniem, jakie może podjąć, jest zatrzymanie obsługi ruchu i odmowa przyjmowania jakichkolwiek zapytań, zapewniając, że nie nastąpi dryf danych.
Oczywiście nie oznacza to, że możesz mieć tylko trzy węzły w klastrze. Jeśli chcesz mieć lepszą odporność na awarie, możesz dodać więcej. Pamiętaj jednak, że powinna to być liczba nieparzysta, jeśli chcesz poprawić wysoką dostępność. W powyższych przykładach mówiliśmy również o „węzłach”. Należy pamiętać, że dotyczy to również centrów danych, stref dostępności itp. Jeśli masz dwa centra danych, z których każde ma taką samą liczbę węzłów (powiedzmy, trzy węzły każdy) i tracisz łączność między tymi dwoma kontrolerami domeny, obowiązują tutaj te same zasady - nie można powiedzieć, która połowa klastra powinna zacząć obsługiwać ruch. Aby móc to stwierdzić, musisz mieć obserwatora w trzecim centrum danych. Może to być kolejny zestaw węzłów lub tylko pojedynczy host z zadaniem
obserwowania stanu pozostałych dataceterów i brania udziału w podejmowaniu decyzji (przykładem może być tutaj arbiter Galera).
Pojedyncze punkty awarii
Wysoka dostępność polega na usuwaniu pojedynczych punktów awarii (SPOF) i nie wprowadzaniu nowych w procesie. Czym są SPOF? Każda część infrastruktury, która w przypadku awarii powoduje przestój zgodnie z definicją w umowie SLA, nazywana jest SPOF. Projektowanie infrastruktury wymaga podejścia holistycznego, różne komponenty nie mogą być projektowane niezależnie od siebie. Najprawdopodobniej nie jesteś odpowiedzialny za cały projekt -
administratorzy baz danych zwykle skupiają się na bazach danych, a nie na przykład na warstwie sieciowej. Mimo to musisz pamiętać o innych częściach i współpracować z zespołami, które są za nie odpowiedzialne, aby upewnić się, że nie tylko ta część, za którą jesteś odpowiedzialny, została zaprojektowana poprawnie, ale także, że pozostałe elementy infrastruktury zostały zaprojektowane przy użyciu te same zasady. Co więcej, taka wiedza o tym, jak projektowana jest cała
infrastruktura, pomaga również zaprojektować stos bazy danych. Wiedza o tym, jakie problemy mogą się wydarzyć, pomaga zbudować pewne mechanizmy, aby zapobiec ich wpływowi na dostępność bazy danych.