Gdy rok 2014 dobiega końca, rozpoczynam serię postów na temat proaktywnych kontroli stanu SQL Server, opartych na jednym, który napisałem na początku tego roku – Problemy z wydajnością:pierwsze spotkanie. W tym poście omówiłem, czego szukam w pierwszej kolejności podczas rozwiązywania problemów z wydajnością w nieznanym środowisku. W tej serii postów chcę opowiedzieć o tym, czego szukam, kontaktując się z moimi długoterminowymi klientami. Świadczymy usługę Remote DBA, a jednym z naszych stałych zadań jest comiesięczny „mini” audyt stanu ich środowiska. Mamy monitoring i zazwyczaj pracuję nad projektami, więc regularnie przebywam w środowisku. Ale jako dodatkowy krok, aby upewnić się, że niczego nam nie brakuje, raz w miesiącu przeglądamy te same dane, które zbieramy w naszym standardowym audycie zdrowia i szukamy czegoś niezwykłego. To może być wiele rzeczy, prawda? Tak! Zacznijmy więc od miejsca.
Whoa, przestrzeń? Tak, przestrzeń. Nie martw się, przejdę do innych tematów.
Co sprawdzić
Dlaczego miałbym zacząć od przestrzeni? Ponieważ jest to coś, co często uważam za zaniedbywane, a jeśli zabraknie miejsca na dysku dla plików bazy danych, stajesz się bardzo ograniczony w tym, co możesz zrobić w swojej bazie danych. Chcesz dodać dane, ale nie możesz powiększyć pliku, ponieważ dysk jest pełny? Przepraszamy, teraz użytkownicy nie mogą dodawać danych. Z jakiegoś powodu nie robisz kopii zapasowych dziennika, więc dziennik transakcji zapełnia dysk? Przepraszamy, teraz nie możesz modyfikować żadnych danych. Przestrzeń ma kluczowe znaczenie. Mamy zadania, które monitorują wolne miejsce na dysku i w plikach, ale nadal sprawdzam następujące elementy przy każdym audycie i porównuję wartości z tymi z poprzedniego miesiąca:
- Rozmiar każdego pliku dziennika
- Rozmiar każdego pliku danych
- Wolne miejsce w każdym pliku danych
- Wolne miejsce na każdym dysku z plikami bazy danych
- Wolne miejsce na każdym dysku z plikami kopii zapasowej
Rozwój pliku dziennika
Większość problemów, które widzę, związanych z miejscem na dysku, wynika z rozrostu pliku dziennika. Wzrost zazwyczaj występuje z jednego z dwóch powodów:
- Baza danych jest w PEŁNYM odzyskiwaniu, a kopie zapasowe dziennika transakcji z jakiegoś powodu nie są brane
- Ktoś uruchamia pojedynczą, bardzo dużą transakcję, która zużywa całą istniejącą przestrzeń dziennika, zmuszając plik do wzrostu
Widziałem również, jak plik dziennika rośnie w ramach konserwacji indeksu. W przypadku przebudowy każda alokacja jest rejestrowana, a w przypadku dużych indeksów, które mogą generować znaczną ilość dziennika. Nawet w przypadku zwykłych kopii zapasowych dziennika transakcji, dziennik może nadal rosnąć szybciej niż mogą powstawać kopie zapasowe. Aby zarządzać dziennikiem, musisz dostosować częstotliwość tworzenia kopii zapasowych lub zmodyfikować metodologię konserwacji indeksu.
Musisz ustalić, dlaczego plik dziennika urósł, co może być trudne, chyba że go śledzisz. Mam zadanie, które jest uruchamiane co godzinę, aby określić rozmiar i użycie pliku dziennika migawki:
USE [Baselines];
GO
IF (NOT EXISTS (SELECT *
FROM INFORMATION_SCHEMA.TABLES
WHERE TABLE_SCHEMA = 'dbo'
AND TABLE_NAME = 'SQLskills_TrackLogSpace'))
BEGIN
CREATE TABLE [dbo].[SQLskills_TrackLogSpace](
[DatabaseName] [VARCHAR](250) NULL,
[LogSizeMB] [DECIMAL](38, 0) NULL,
[LogSpaceUsed] [DECIMAL](38, 0) NULL,
[LogStatus] [TINYINT] NULL,
[CaptureDate] [DATETIME2](7) NULL
) ON [PRIMARY];
ALTER TABLE [dbo].[SQLskills_TrackLogSpace] ADD DEFAULT (SYSDATETIME()) FOR [CaptureDate];
END
CREATE TABLE #LogSpace_Temp (
DatabaseName VARCHAR(100),
LogSizeMB DECIMAL(10,2),
LogSpaceUsed DECIMAL(10,2),
LogStatus VARCHAR(1)
);
INSERT INTO #LogSpace_Temp EXEC('dbcc sqlperf(logspace)');
INSERT INTO Baselines.dbo.SQLskills_TrackLogSpace
(DatabaseName, LogSizeMB, LogSpaceUsed, LogStatus)
SELECT DatabaseName, LogSizeMB, LogSpaceUsed, LogStatus
FROM #LogSpace_Temp;
DROP TABLE #LogSpace_Temp; Używam tych informacji, aby określić, kiedy plik dziennika zaczął się powiększać, i zaczynam przeglądać dzienniki i historię zadań, aby zobaczyć, jakie dodatkowe informacje mogę znaleźć. Wzrost dziennika powinien być statyczny – dziennik powinien mieć odpowiedni rozmiar i być zarządzany za pomocą kopii zapasowych (jeśli działa w trybie PEŁNEGO odzyskiwania), a jeśli plik musi być większy, muszę zrozumieć dlaczego i odpowiednio zmienić jego rozmiar.
Jeśli masz do czynienia z tym problemem i nie śledziłeś jeszcze aktywnie zdarzeń wzrostu plików, nadal możesz dowiedzieć się, co się stało. Zdarzenia automatycznego wzrostu są przechwytywane przez program SQL Server; Aaron Bertrand z SQL Sentry pisał o tym na blogu w 2007 roku, gdzie pokazuje, jak dowiedzieć się, kiedy te zdarzenia miały miejsce (o ile były na tyle niedawne, że nadal istniały w domyślnym śledzeniu).
Rozmiar i wolne miejsce w plikach danych
Prawdopodobnie słyszałeś już, że pliki danych powinny mieć wstępnie ustalony rozmiar, aby nie musiały rosnąć automatycznie. Jeśli zastosujesz się do tych wskazówek, prawdopodobnie nie doświadczyłeś zdarzenia, w którym plik danych nieoczekiwanie się powiększa. Ale jeśli nie zarządzasz plikami danych, prawdopodobnie wzrost występuje regularnie – niezależnie od tego, czy zdajesz sobie z tego sprawę, czy nie (zwłaszcza przy domyślnych ustawieniach wzrostu 10% i 1 MB).
Istnieje pewien trik dotyczący wstępnego określania rozmiaru plików danych – nie chcesz, aby rozmiar bazy danych był zbyt duży, ponieważ pamiętaj, że jeśli przywrócisz, powiedzmy, środowisko deweloperskie lub QA, pliki mają taki sam rozmiar, nawet jeśli „ nie są pełne danych. Ale nadal chcesz ręcznie zarządzać wzrostem. Uważam, że administratorzy baz danych mają najwięcej trudności z nowymi bazami danych. Użytkownicy biznesowi nie mają pojęcia o tempie wzrostu i ilości dodawanych danych, a ta baza danych jest trochę luźną armatą w twoim środowisku. Musisz zwracać szczególną uwagę na te pliki, dopóki nie opanujesz rozmiaru i oczekiwanego wzrostu. Używam zapytania, które zawiera informacje o rozmiarze i wolnej przestrzeni:
SELECT
[file_id] AS [File ID],
[type] AS [File Type],
substring([physical_name],1,1) AS [Drive],
[name] AS [Logical Name],
[physical_name] AS [Physical Name],
CAST([size] as DECIMAL(38,0))/128. AS [File Size MB],
CAST(FILEPROPERTY([name],'SpaceUsed') AS DECIMAL(38,0))/128. AS [Space Used MB],
(CAST([size] AS DECIMAL(38,0))/128) - (CAST(FILEPROPERTY([name],'SpaceUsed') AS DECIMAL(38,0))/128.) AS [Free Space],
[max_size] AS [Max Size],
[is_percent_growth] AS [Percent Growth Enabled],
[growth] AS [Growth Rate],
SYSDATETIME() AS [Current Date]
FROM sys.database_files; Co miesiąc sprawdzam rozmiar plików danych i zajmowaną przestrzeń, a następnie decyduję, czy rozmiar należy zwiększyć. Monitoruję również domyślne śledzenie zdarzeń wzrostu, ponieważ informuje mnie on dokładnie, kiedy następuje wzrost. Z wyjątkiem nowych baz danych, zawsze mogę wyprzedzić automatyczny wzrost plików i obsłużyć go ręcznie. Ok, prawie zawsze. Tuż przed zeszłorocznymi wakacjami zostałem powiadomiony przez dział IT klienta o małej ilości wolnego miejsca na dysku (pomyśl o tym do następnej sekcji). Teraz powiadomienie jest oparte na progu mniejszym niż 20% za darmo. Ten dysk miał ponad 1 TB, więc podczas sprawdzania dysku było około 150 GB wolnego miejsca. To nie była sytuacja awaryjna, ale musiałem zrozumieć, gdzie się podziała przestrzeń.
Sprawdzając pliki bazy danych pod kątem jednej bazy danych, zauważyłem, że są one pełne – a w poprzednim miesiącu każdy plik miał ponad 50 GB wolnego miejsca. Następnie zagłębiłem się w rozmiary tabel i odkryłem, że w jednej tabeli w ciągu ostatnich 16 dni dodano ponad 270 milionów wierszy – łącznie ponad 100 GB danych. Okazuje się, że nastąpiła modyfikacja kodu i nowy kod rejestrował więcej informacji, niż zamierzano. Szybko skonfigurowaliśmy zadanie, aby wyczyścić wiersze i odzyskać wolne miejsce w plikach (i naprawiliśmy kod). Nie mogłem jednak odzyskać miejsca na dysku – musiałbym zmniejszyć pliki, a to nie było możliwe. Następnie musiałem określić, ile miejsca zostało na dysku i zdecydować, czy jest to ilość, z którą czuję się komfortowo, czy nie. Mój poziom komfortu zależy od tego, ile danych jest dodawanych miesięcznie – typowa stopa wzrostu. I wiem tylko, ile danych jest dodawanych, ponieważ monitoruję wykorzystanie plików i mogę oszacować, ile miejsca będzie potrzebne w tym miesiącu, w tym roku i na następne dwa lata.
Miejsce na dysku
Wspomniałem wcześniej, że mamy zadania do monitorowania wolnego miejsca na dysku. Opiera się to na wartości procentowej, a nie stałej kwocie. Moją ogólną zasadą jest wysyłanie powiadomień, gdy mniej niż 10% dysku jest wolne, ale w przypadku niektórych dysków może być konieczne ustawienie tego wyższego poziomu. Na przykład z dyskiem o pojemności 1 TB otrzymuję powiadomienie, gdy jest mniej niż 100 GB wolnego miejsca. Z dyskiem 100 GB otrzymuję powiadomienie, gdy jest mniej niż 10 GB wolnego miejsca. Z dyskiem 20 GB… cóż, widzisz, dokąd zmierzam. Ten próg musi Cię ostrzec, zanim pojawi się problem. Jeśli mam tylko 10 GB wolnego miejsca na dysku, na którym znajduje się plik dziennika, mogę nie mieć wystarczająco dużo czasu na reakcję, zanim pojawi się to jako problem dla użytkowników – w zależności od tego, jak często sprawdzam wolną przestrzeń i na czym polega problem jest.
Bardzo łatwo jest używać xp_fixeddrives do sprawdzania wolnego miejsca, ale nie polecam tego, ponieważ jest to nieudokumentowane, a korzystanie z rozszerzonych procedur składowanych zostało ogólnie przestarzałe. Nie podaje również całkowitego rozmiaru każdego dysku i może nie zgłaszać wszystkich typów dysków, z których mogą korzystać Twoje bazy danych. Dopóki używasz SQL Server 2008R2 SP1 lub nowszego, możesz użyć znacznie wygodniejszego sys.dm_os_volume_stats, aby uzyskać potrzebne informacje, przynajmniej o dyskach, na których istnieją pliki bazy danych:
SELECT DISTINCT vs.volume_mount_point AS [Drive], vs.logical_volume_name AS [Drive Name], vs.total_bytes/1024/1024 AS [Drive Size MB], vs.available_bytes/1024/1024 AS [Drive Free Space MB] FROM sys.master_files AS f CROSS APPLY sys.dm_os_volume_stats(f.database_id, f.file_id) AS vs ORDER BY vs.volume_mount_point;
Często widzę problem z miejscem na dysku na woluminach hostujących tempdb. Straciłem rachubę przypadków, w których miałem klientów z niewyjaśnionym wzrostem tempdb. Czasami to tylko kilka GB; ostatnio było to 200 GB. Tempdb to trudna bestia – nie ma formuły, którą można by się kierować przy jej doborze i zbyt często jest umieszczany na dysku z małą ilością wolnego miejsca, który nie poradzi sobie z szalonym zdarzeniem spowodowanym przez początkującego programistę lub DBA. Ustalenie rozmiaru plików danych tempdb wymaga uruchomienia obciążenia w „normalnym” cyklu biznesowym, aby określić, w jakim stopniu używa tempdb, a następnie odpowiednio dobrać rozmiar.
Niedawno usłyszałem sugestię dotyczącą sposobu na uniknięcie braku miejsca na dysku:utwórz bazę danych bez danych i ustaw rozmiar plików, aby zajmowały tyle miejsca, ile chcesz „odłożyć”. Następnie, jeśli napotkasz problem, po prostu upuść bazę danych i altówkę, znowu masz wolne miejsce. Osobiście uważam, że stwarza to wszelkiego rodzaju inne problemy i nie polecałbym tego. Ale jeśli masz administratorów pamięci masowej, którzy nie lubią widzieć setek nieużywanych GB na dysku, byłby to jeden ze sposobów, aby dysk „wyglądał” na pełny. Przypomina mi to coś, co słyszałem od mojego dobrego przyjaciela:„Jeśli nie mogę z tobą pracować, będę pracować wokół ciebie”.
Kopie zapasowe
Jednym z podstawowych zadań administratora baz danych jest ochrona danych. Kopie zapasowe to jedna z metod służących do ich ochrony, dlatego dyski, na których te kopie zapasowe są przechowywane, są integralną częścią życia administratora DBA. Przypuszczalnie przechowujesz jedną lub więcej kopii zapasowych online, aby w razie potrzeby przywrócić je natychmiast. Twoja książka uruchomienia SLA i DR pomaga dyktować, ile kopii zapasowych przechowujesz online, i musisz upewnić się, że masz dostępne miejsce. Zalecam, aby nie usuwać również starych kopii zapasowych, dopóki bieżąca kopia zapasowa nie zostanie pomyślnie zakończona. Zbyt łatwo wpaść w pułapkę usuwania starych kopii zapasowych, a następnie uruchamiania bieżącej kopii zapasowej. Ale co się stanie, jeśli bieżąca kopia zapasowa się nie powiedzie? A co się stanie, jeśli używasz kompresji? Chwileczkę… skompresowane kopie zapasowe są mniejsze, prawda? W końcu są mniejsze. Ale czy wiesz, że rozmiar pliku .bak zwykle zaczyna się od rozmiaru końcowego? Możesz użyć flagi śledzenia 3042, aby zmienić to zachowanie, ale powinieneś pomyśleć, że w przypadku kopii zapasowych potrzebujesz dużo miejsca. Jeśli twoja kopia zapasowa ma 100 GB i przechowujesz zasoby z 3 dni w trybie online, potrzebujesz 300 GB na 3 dni tworzenia kopii zapasowych, a następnie prawdopodobnie zdrową ilość (2x obecny rozmiar bazy danych) za darmo na następną kopię zapasową. Tak, oznacza to, że w dowolnym momencie na tym dysku będziesz mieć dużo ponad 100 GB wolnego miejsca. W porządku. To lepsze niż pomyślne wykonanie zadania usuwania i niepowodzenie zadania tworzenia kopii zapasowej, a trzy dni później dowiesz się, że w ogóle nie masz żadnych kopii zapasowych (przydarzyło mi się to klientowi w poprzednim zadaniu).
Większość baz danych z czasem powiększa się, co oznacza, że kopie zapasowe również stają się większe. Nie zapomnij regularnie sprawdzać rozmiaru plików kopii zapasowych i przydzielać dodatkowe miejsce w razie potrzeby – posiadanie zasady „200 GB za darmo” dla bazy danych, która rozrosła się do 350 GB, nie będzie zbyt pomocna. Jeśli zmienią się wymagania dotyczące miejsca, pamiętaj, aby zmienić również wszystkie powiązane alerty.
Korzystanie z Doradcy wydajności
W tym poście znajduje się kilka zapytań, których możesz użyć do monitorowania przestrzeni, jeśli chcesz przeprowadzić własny proces. Ale jeśli zdarzy ci się mieć SQL Sentry Performance Advisor w swoim środowisku, stanie się to o wiele łatwiejsze dzięki niestandardowym warunkom. Domyślnie dostępnych jest kilka stanów magazynowych, ale możesz także stworzyć własne.
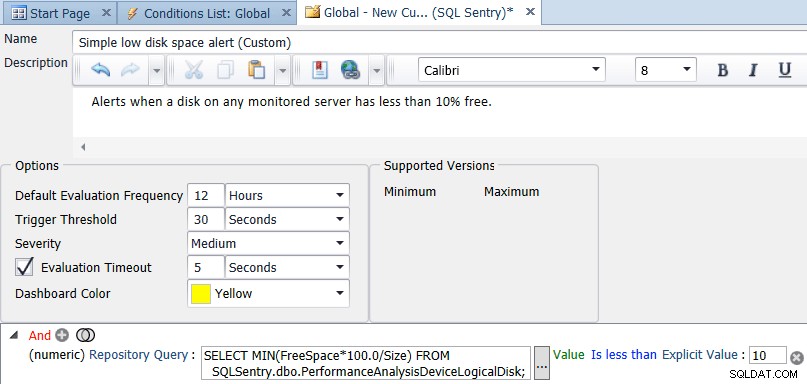
W kliencie SQL Sentry otwórz Nawigator, kliknij prawym przyciskiem myszy Shared Groups (Global) i wybierz Add Custom Condition → SQL Sentry. Podaj nazwę i opis warunku, a następnie dodaj porównanie liczbowe i zmień typ na Zapytanie o repozytorium. Wpisz zapytanie:
SELECT MIN(FreeSpace*100.0/Size) FROM SQLSentry.dbo.PerformanceAnalysisDeviceLogicalDisk;
Zmień Równa się na Jest mniejszy niż i ustaw jawną wartość 10. Na koniec zmień domyślną częstotliwość oceny na mniej niż co 10 sekund. Raz dziennie lub raz na 12 godzin to prawdopodobnie dobra wartość – nie powinieneś sprawdzać wolnego miejsca częściej niż raz dziennie, ale możesz to sprawdzać tak często, jak chcesz. Poniższy zrzut ekranu pokazuje ostateczną konfigurację:
Po kliknięciu przycisku Zapisz dla warunku zostaniesz zapytany, czy chcesz przypisać akcje dla warunku niestandardowego. Opcja Wyślij do kanałów alarmowych jest domyślnie zaznaczona, ale możesz chcieć wykonać inne zadania, takie jak Wykonaj zadanie – powiedzmy, aby skopiować stare kopie zapasowe do innej lokalizacji (jeśli jest to dysk z małą ilością miejsca).
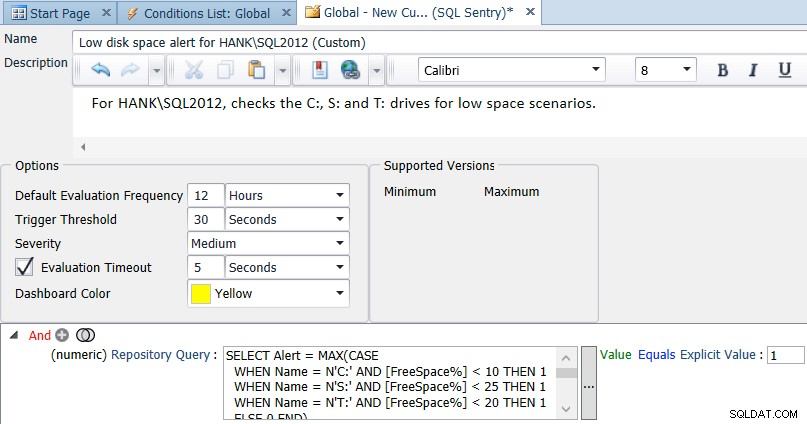
Jak wspomniałem wcześniej, domyślne 10% wolnego miejsca dla wszystkich dysków prawdopodobnie nie jest odpowiednie dla każdego dysku w twoim środowisku. Możesz dostosować zapytanie dla różnych instancji i dysków, na przykład:
SELECT Alert = MAX(CASE WHEN Name = N'C:' AND [FreeSpace%] < 10 THEN 1 WHEN Name = N'S:' AND [FreeSpace%] < 25 THEN 1 WHEN Name = N'T:' AND [FreeSpace%] < 20 THEN 1 ELSE 0 END) FROM ( SELECT d.Name, d.FreeSpace * 100.0/d.Size AS [FreeSpace%] FROM SQLSentry.dbo.PerformanceAnalysisDeviceLogicalDisk AS d INNER JOIN SQLSentry.dbo.EventSourceConnection AS c ON d.DeviceID = c.DeviceID WHERE c.ObjectName = N'HANK\SQL2012' -- replace with your server/instance ) AS s;
Możesz zmienić i rozszerzyć to zapytanie, jeśli jest to konieczne dla twojego środowiska, a następnie odpowiednio zmienić porównanie w warunku (zasadniczo oceniając na true, jeśli wynik jest kiedykolwiek 1):
Jeśli chcesz zobaczyć Performance Advisor w akcji, pobierz wersję próbną.
Pamiętaj, że w przypadku obu tych warunków zostaniesz ostrzeżony tylko raz, nawet jeśli wiele dysków spadnie poniżej progu. W złożonych środowiskach możesz chcieć skłaniać się ku większej liczbie bardziej szczegółowych warunków, aby zapewnić bardziej elastyczne i spersonalizowane ostrzeganie, a nie mniej warunków typu „catch-all”.
Podsumowanie
W środowisku SQL Server istnieje wiele krytycznych składników, a miejsce na dysku to takie, które należy aktywnie monitorować i konserwować. Przy odrobinie planowania jest to proste i łagodzi wiele niewiadomych oraz reaktywne rozwiązywanie problemów. Niezależnie od tego, czy używasz własnych skryptów, czy narzędzia innej firmy, upewnienie się, że jest dużo wolnego miejsca na pliki bazy danych i kopie zapasowe, jest problemem, który można łatwo rozwiązać i który jest wart zachodu.