Korzystanie z klastra Galera to świetny sposób na zbudowanie wysoce dostępnego środowiska dla MySQL lub MariaDB. Jest to środowisko klastrowe typu „shared-nic”, które można skalować nawet poza 12-15 węzłów. Galera ma jednak pewne ograniczenia. Świeci się w środowiskach o niskich opóźnieniach i chociaż może być używany w sieci WAN, wydajność jest ograniczona przez opóźnienia sieci. Na wydajność Galery może również wpłynąć niepoprawne zachowanie jednego z węzłów. Na przykład nadmierne obciążenie jednego z węzłów może go spowolnić, powodując wolniejszą obsługę zapisów, co wpłynie na wszystkie inne węzły w klastrze. Z drugiej strony prowadzenie firmy bez analizy danych jest całkiem niemożliwe. Taka analiza zazwyczaj wymaga uruchamiania ciężkich zapytań, co znacznie różni się od obciążenia OLTP. W tym poście na blogu omówimy prosty sposób wykonywania zapytań analitycznych dla danych przechowywanych w Galera Cluster for MySQL lub MariaDB w sposób, który nie wpływa na wydajność klastra rdzenia.
Jak uruchamiać zapytania analityczne w klastrze Galera?
Jak już wspomnieliśmy, uruchamianie długo działających zapytań bezpośrednio w klastrze Galera jest wykonalne, ale może nie jest to dobry pomysł. Zależne od sprzętu może to być akceptowalne rozwiązanie (jeśli użyjesz mocnego sprzętu i nie uruchomisz wielowątkowego obciążenia analitycznego), ale nawet jeśli wykorzystanie procesora nie będzie problemem, fakt, że jeden z węzłów będzie miał mieszane obciążenie ( OLTP i OLAP) same w sobie będą stanowić pewne wyzwania dotyczące wydajności. Zapytania OLAP wyrzucą dane wymagane dla obciążenia OLTP z puli buforów, a to spowolni Twoje zapytania OLTP. Na szczęście istnieje prosty, ale skuteczny sposób oddzielenia obciążenia analitycznego od zwykłych zapytań — asynchroniczny niewolnik replikacji.
Urządzenie podrzędne replikacji to bardzo proste rozwiązanie — wystarczy tylko kolejny host, który można udostępnić, a replikacja asynchroniczna musi zostać skonfigurowana z klastra Galera do tego węzła. W przypadku replikacji asynchronicznej urządzenie podrzędne nie wpłynie w żaden sposób na resztę klastra. Bez względu na to, czy jest mocno obciążony, używa innego (mniej wydajnego) sprzętu, po prostu będzie kontynuował replikację z klastra rdzenia. Najgorszy scenariusz jest taki, że urządzenie podrzędne replikacji zacznie pozostawać w tyle, ale wtedy od Ciebie zależy wdrożenie replikacji wielowątkowej lub, ewentualnie, skalowanie podrzędnego replikacji w górę.
Po uruchomieniu i uruchomieniu urządzenia podrzędnego replikacji należy uruchamiać na nim cięższe zapytania i odciążać klaster Galera. Można to zrobić na wiele sposobów, w zależności od konfiguracji i środowiska. Jeśli używasz ProxySQL, możesz łatwo kierować zapytania do analitycznego urządzenia podrzędnego na podstawie hosta źródłowego, użytkownika, schematu, a nawet samego zapytania. W przeciwnym razie od Twojej aplikacji będzie zależeć wysyłanie zapytań analitycznych do właściwego hosta.
Konfiguracja niewolnika replikacji nie jest zbyt skomplikowana, ale nadal może być trudna, jeśli nie jesteś biegły w MySQL i narzędziach takich jak xtrabackup. Cały proces polegałby na ustawieniu repozytorium na nowym serwerze i zainstalowaniu bazy danych MySQL. Następnie będziesz musiał aprowizować ten host przy użyciu danych z klastra Galera. Możesz do tego użyć xtrabackup, ale inne narzędzia, takie jak mydumper/myloader lub nawet mysqldump, również będą działać (o ile wykonasz je poprawnie). Gdy dane będą już dostępne, będziesz musiał skonfigurować replikację między głównym węzłem Galera a podrzędnym serwerem replikacji. Na koniec będziesz musiał ponownie skonfigurować warstwę proxy, aby uwzględnić nowe urządzenie podrzędne i skierować do niego ruch lub wprowadzić poprawki w sposobie łączenia aplikacji z bazą danych, aby przekierować część obciążenia do podrzędnego replikacji.
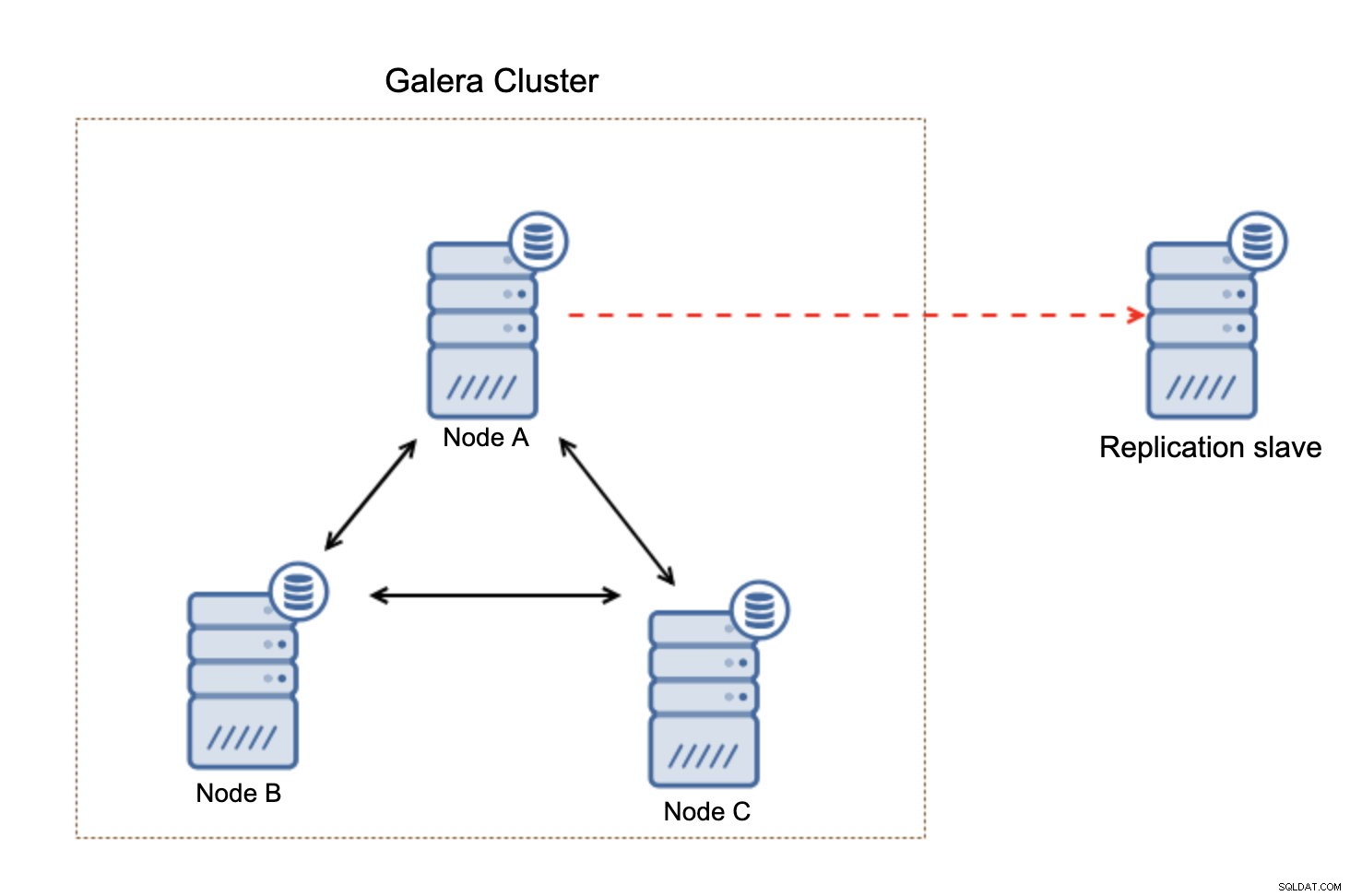
Należy pamiętać, że ta konfiguracja nie jest elastyczna. Jeśli „główny” węzeł Galera ulegnie awarii, łącze replikacji zostanie przerwane i podejmie ręczne działanie w celu podporządkowania repliki innemu węzłowi głównemu w klastrze Galera.
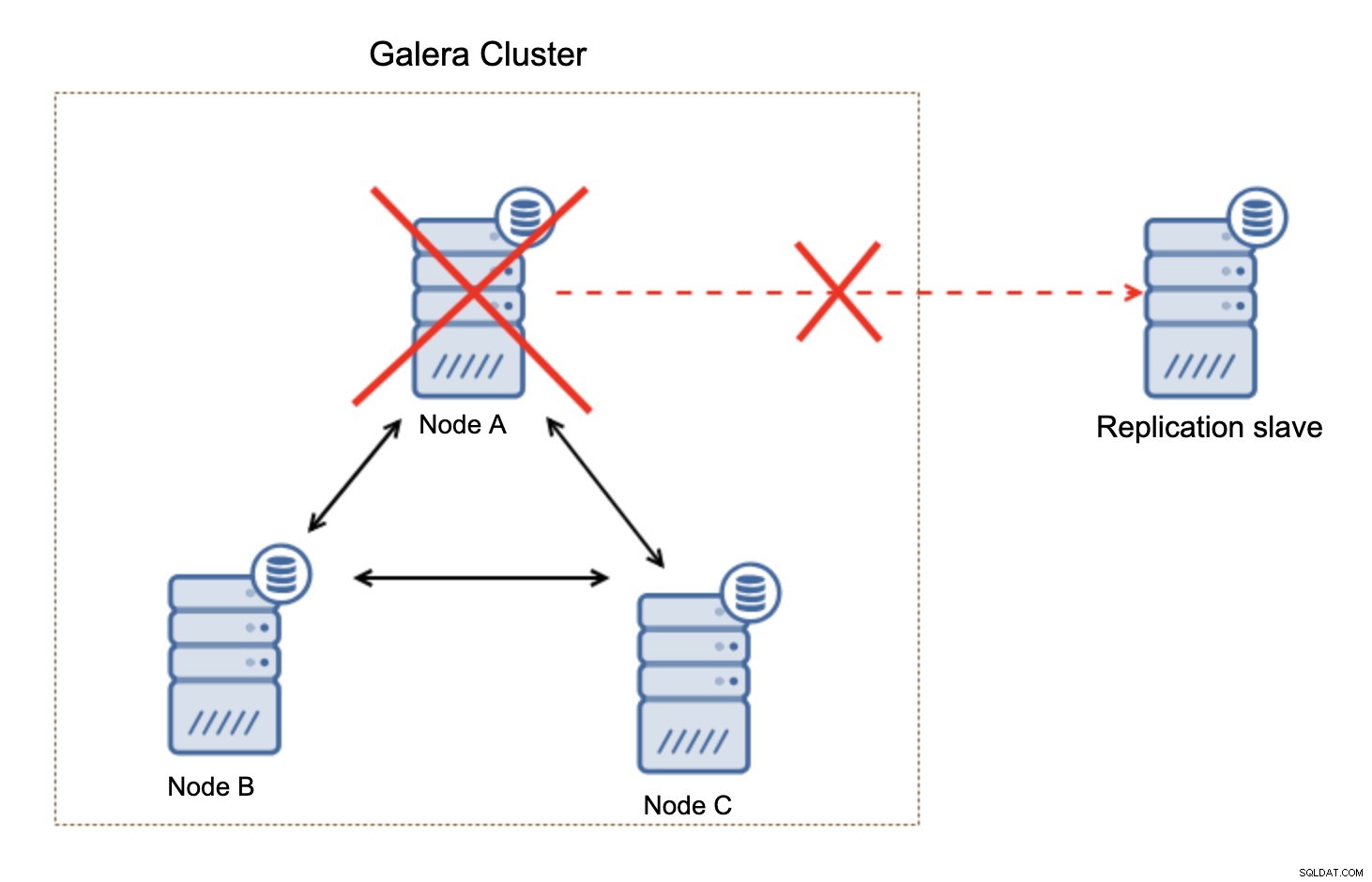
To nie jest wielka sprawa, zwłaszcza jeśli używasz replikacji z GTID (Globalny identyfikator transakcji), ale musisz zidentyfikować, że replikacja jest uszkodzona, a następnie podjąć ręczne działanie.
Jak skonfigurować asynchroniczne urządzenie podrzędne do Galera Cluster za pomocą ClusterControl?
Na szczęście, jeśli używasz ClusterControl, cały proces można zautomatyzować i wymaga tylko kilku kliknięć. Stan początkowy został już skonfigurowany za pomocą ClusterControl - 3-węzłowego klastra Galera z 2 węzłami ProxySQL i 2 węzłami Keepalved dla wysokiej dostępności zarówno bazy danych, jak i warstwy proxy.
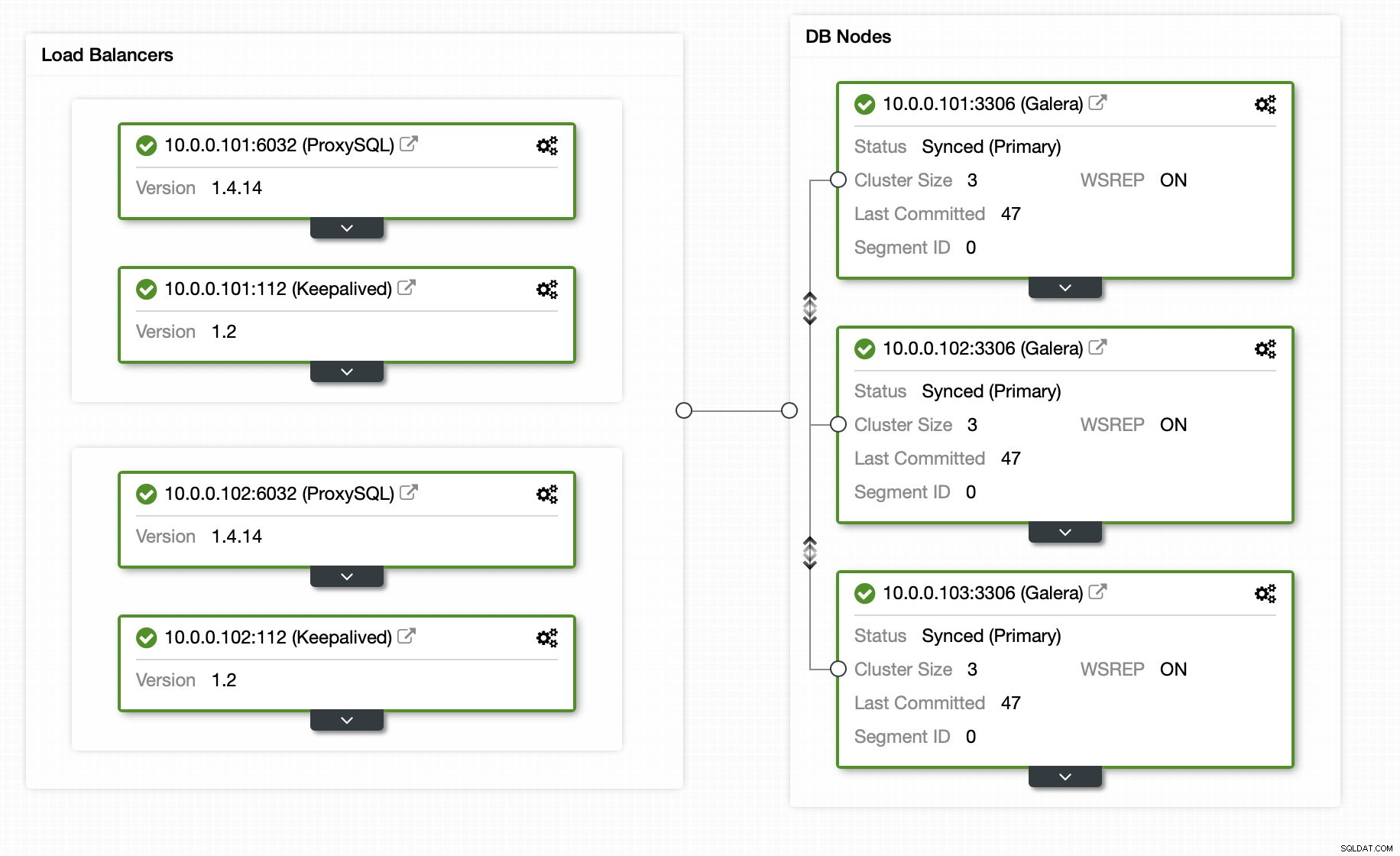
Wystarczy jedno kliknięcie, aby dodać urządzenie podrzędne replikacji:
Replikacja oczywiście wymaga włączenia dzienników binarnych. Jeśli nie masz włączonych binlogów na swoich węzłach Galera, możesz to zrobić również z ClusterControl. Pamiętaj, że włączenie dzienników binarnych będzie wymagało ponownego uruchomienia węzła w celu zastosowania zmian w konfiguracji.
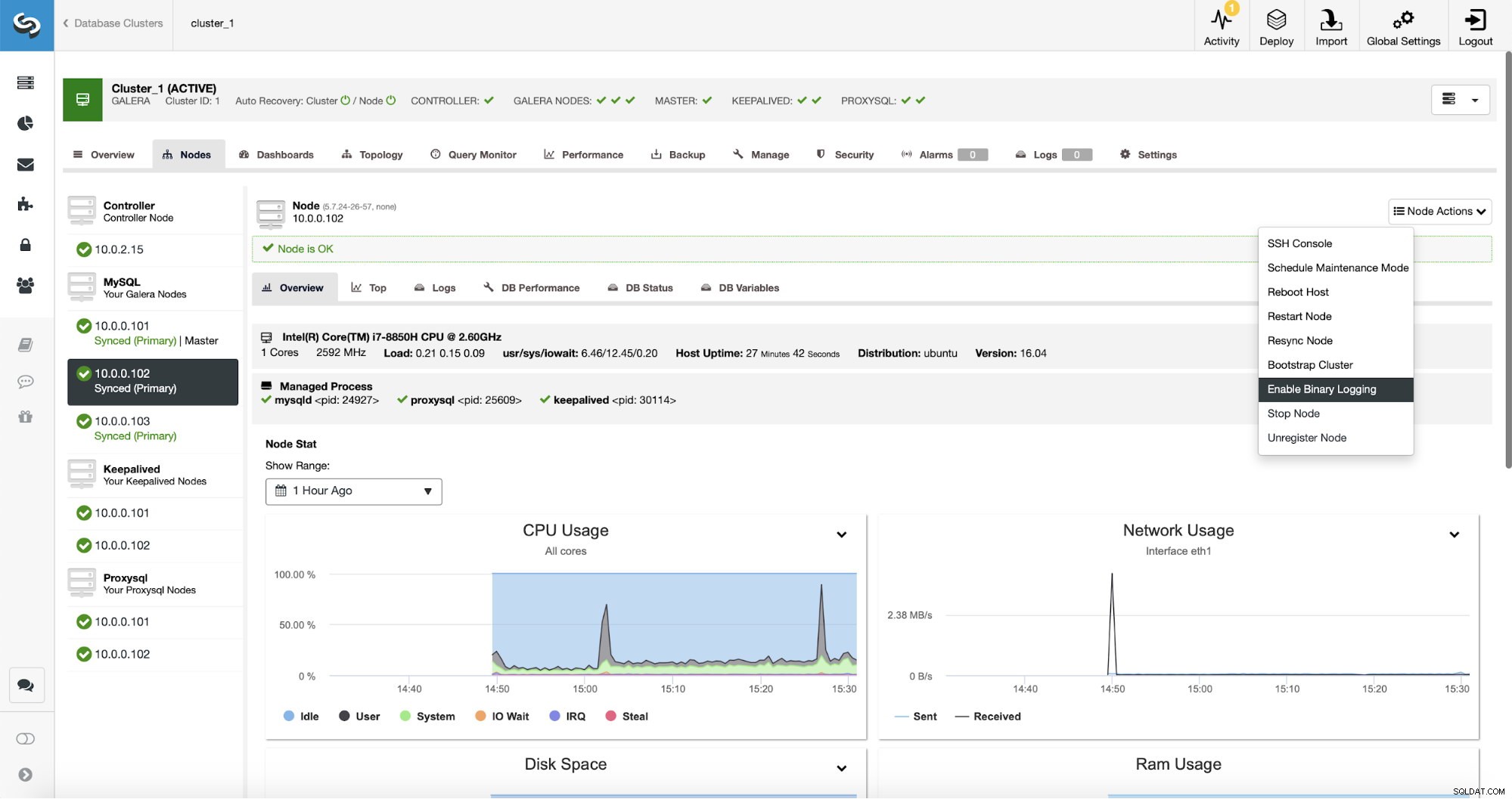
Nawet jeśli jeden węzeł w klastrze ma włączone logi binarne (oznaczone jako „Master” na powyższym zrzucie ekranu), nadal dobrze jest włączyć logowanie binarne na co najmniej jeszcze jednym węźle. ClusterControl może automatycznie przełączać awaryjnie podrzędny węzeł replikacji po wykryciu, że główny węzeł Galera uległ awarii, ale do tego wymagany jest inny węzeł główny z włączonymi dziennikami binarnymi, w przeciwnym razie nie będzie miał do czego przełączyć się w trybie awaryjnym.
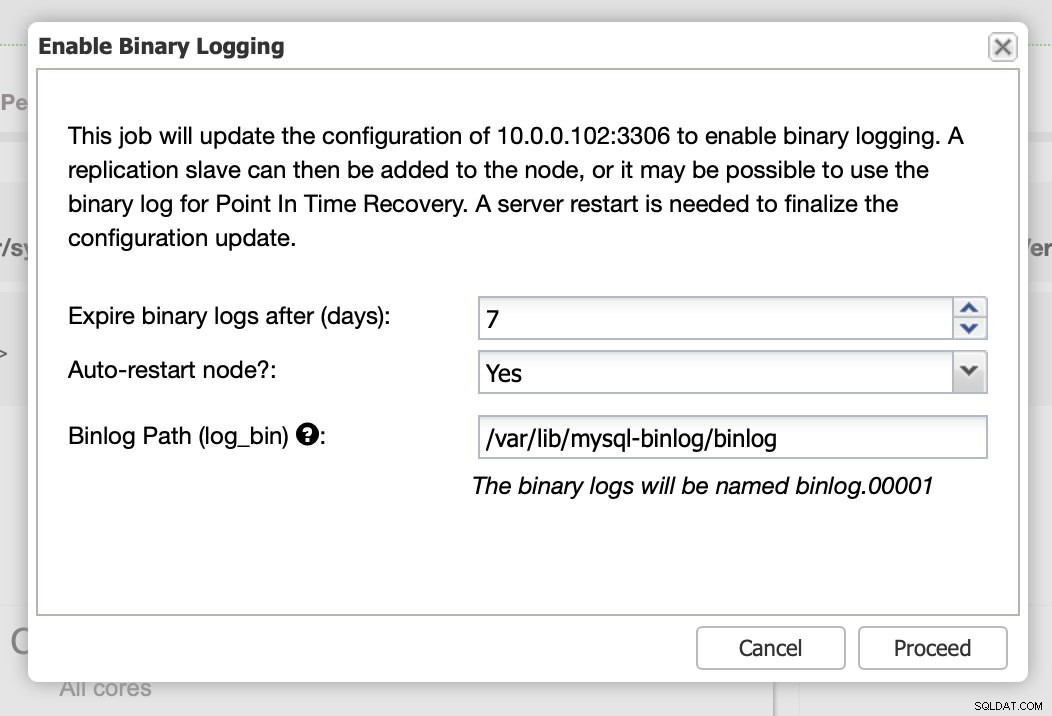
Jak już wspomnieliśmy, włączenie dzienników binarnych wymaga ponownego uruchomienia. Możesz wykonać to od razu lub po prostu wprowadzić zmiany w konfiguracji i ponownie uruchomić w innym czasie.
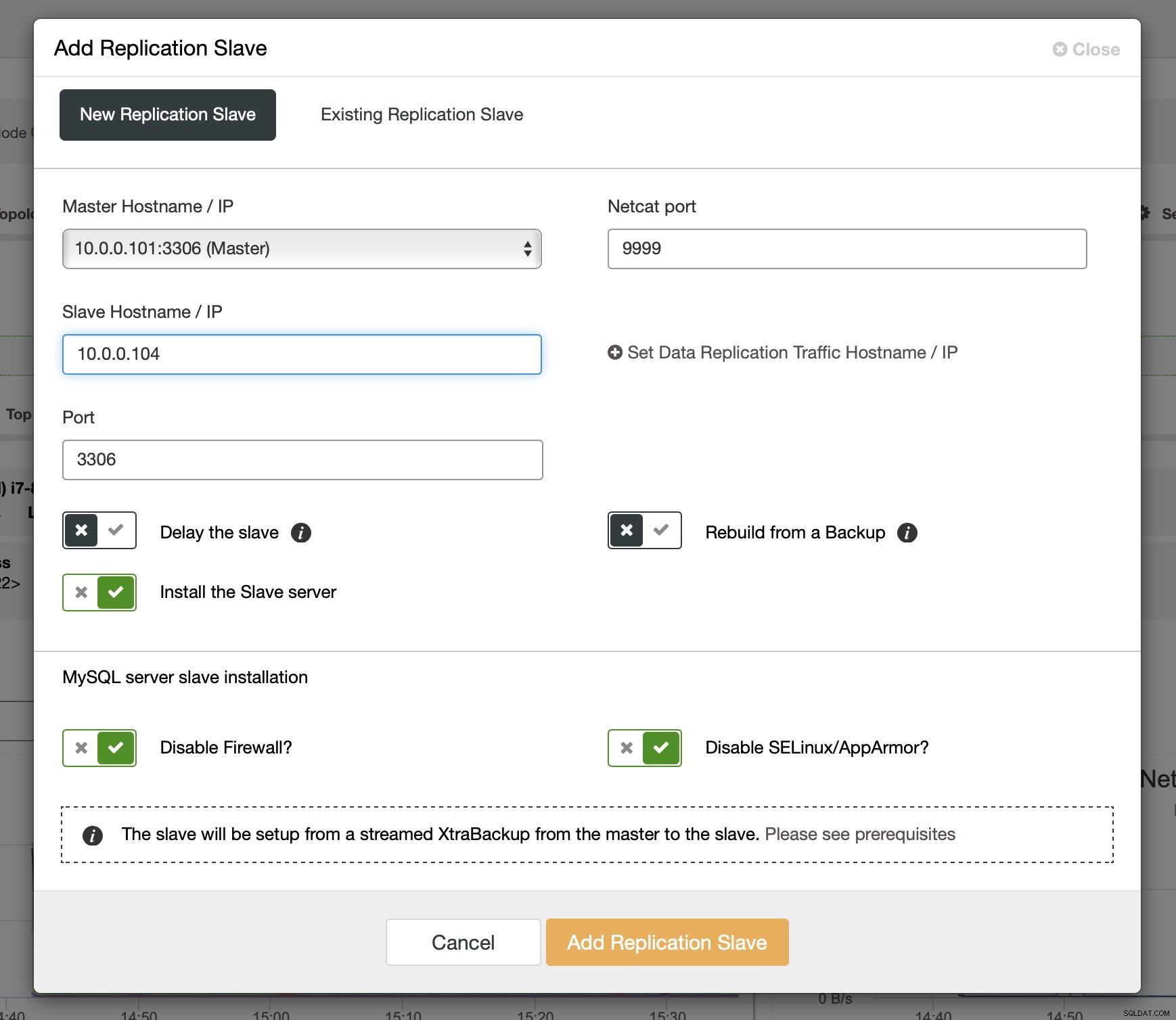
Po włączeniu dzienników binarnych na niektórych węzłach Galera możesz kontynuować dodawanie urządzenia podrzędnego replikacji. W oknie dialogowym musisz wybrać hosta głównego, podać nazwę hosta lub adres IP urządzenia podrzędnego. Jeśli masz pod ręką ostatnie kopie zapasowe (co powinieneś zrobić), możesz użyć ich do zaopatrywania urządzenia podrzędnego. W przeciwnym razie ClusterControl dostarczy go za pomocą xtrabackup - wszystkie ostatnie dane główne zostaną przesłane do urządzenia podrzędnego, a następnie zostanie skonfigurowana replikacja.
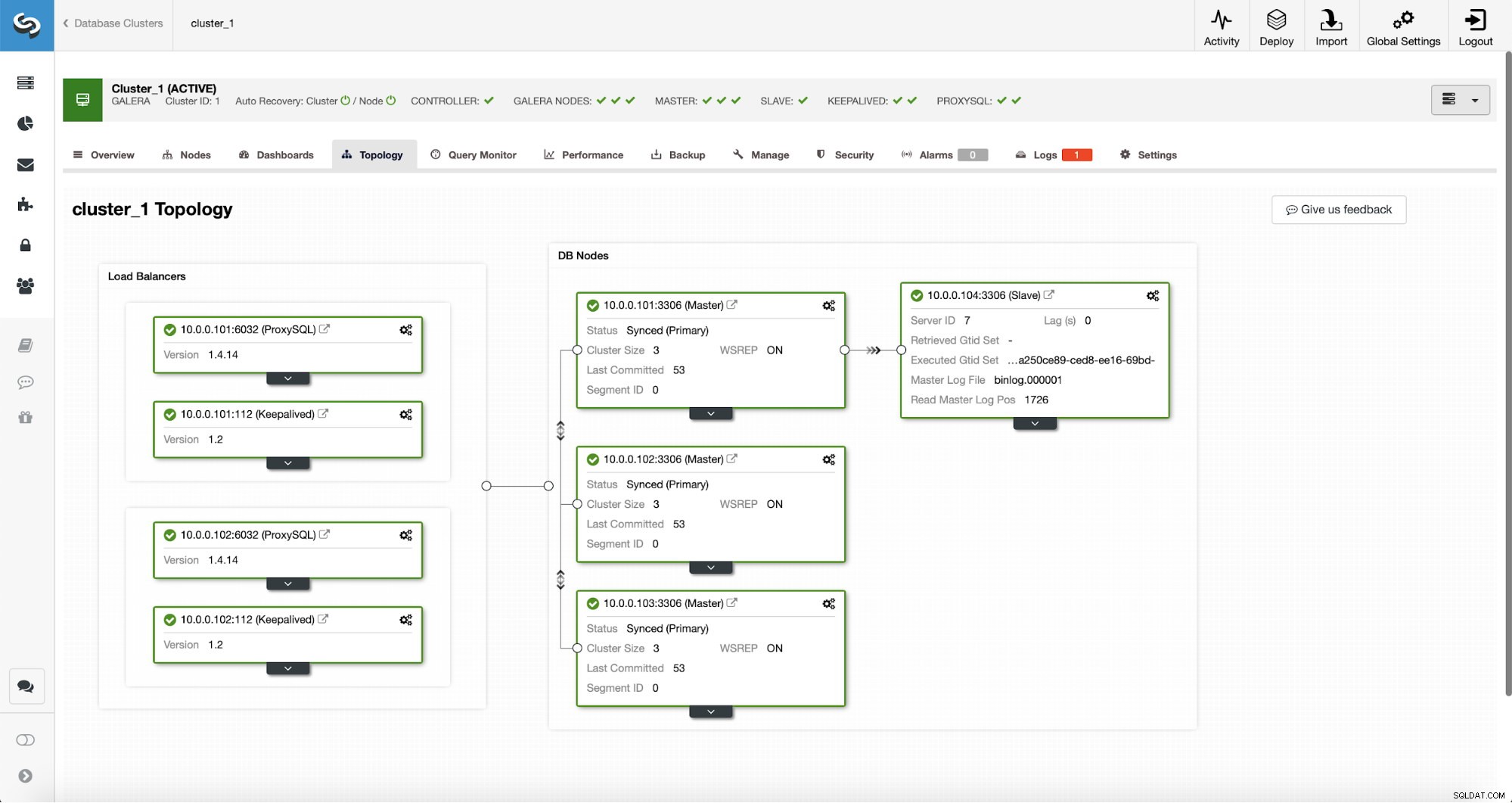
Po zakończeniu zadania do klastra dodano urządzenie podrzędne replikacji. Jak wspomniano wcześniej, jeśli 10.0.0.101 umrze, inny host w klastrze Galera zostanie wybrany jako główny, a ClusterControl automatycznie zwolni 10.0.0.104 z innego węzła.
Ponieważ używamy ProxySQL, musimy go skonfigurować. Dodamy nowy serwer do ProxySQL.
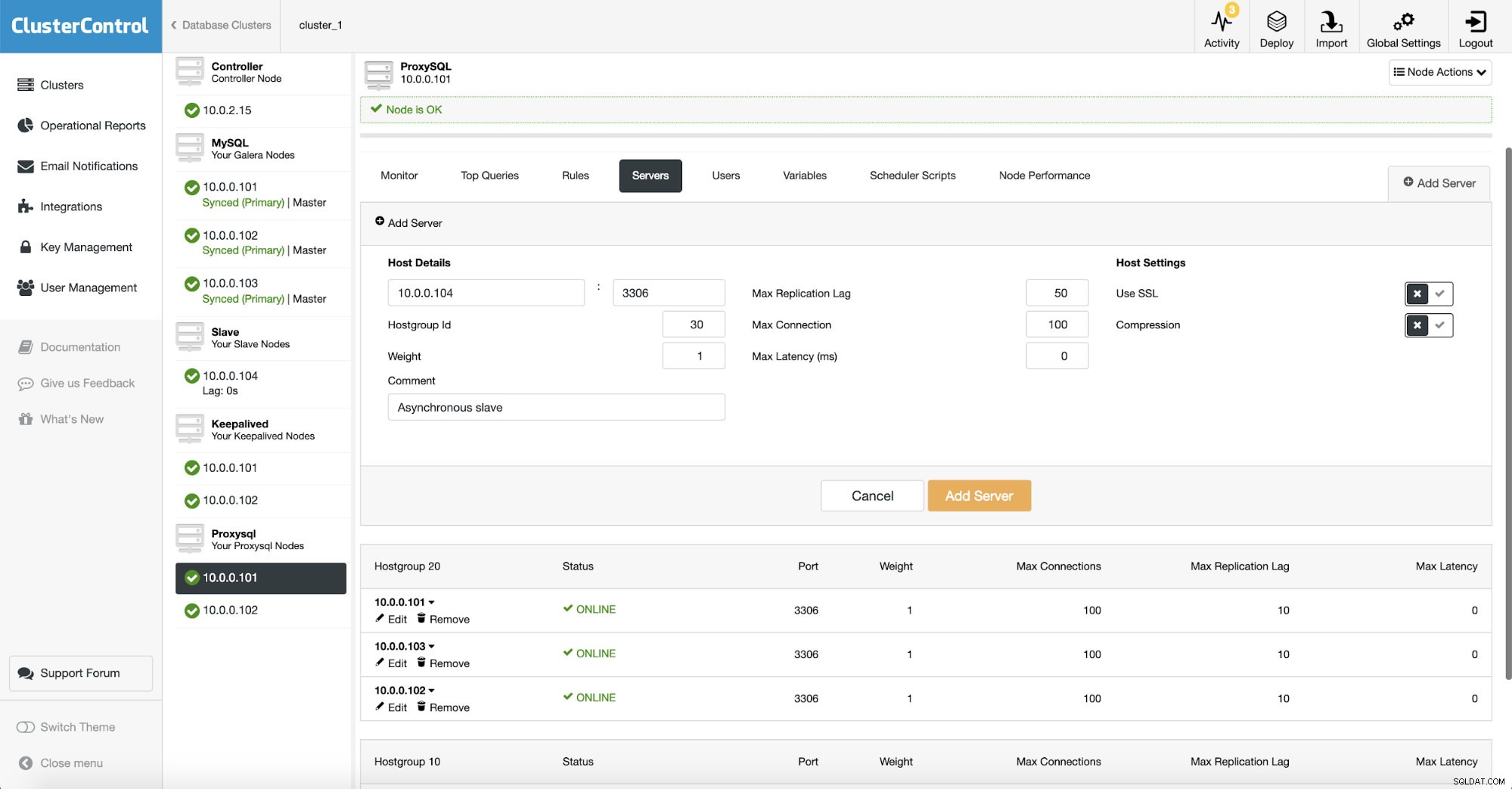
Stworzyliśmy kolejną grupę hostów (30), w której umieściliśmy nasze asynchroniczne urządzenie podrzędne. Zwiększyliśmy również „Maksymalne opóźnienie replikacji” do 50 sekund z domyślnych 10. Od wymagań Twojej firmy zależy, jak bardzo moduł analityczny może opóźniać się, zanim stanie się problemem.
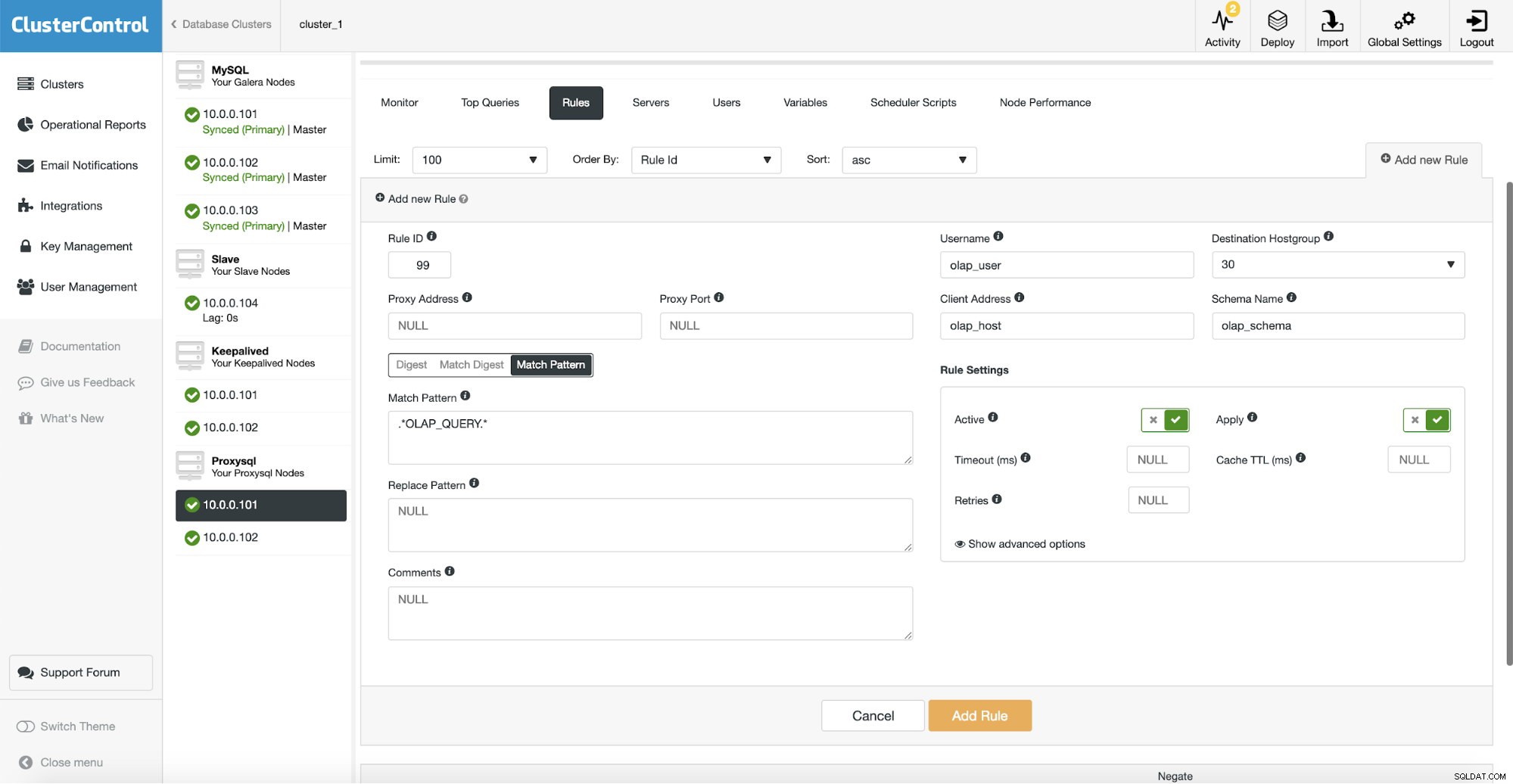
Następnie musimy skonfigurować regułę zapytania, która będzie pasować do naszego ruchu OLAP i skierować go do grupy hostów OLAP (30). Na powyższym zrzucie ekranu wypełniliśmy kilka pól - nie jest to obowiązkowe. Zazwyczaj będziesz musiał użyć jednego, najwyżej dwóch. Powyższy zrzut ekranu służy jako przykład, więc możemy łatwo zauważyć, że możesz dopasować zapytania za pomocą schematu (jeśli masz osobny schemat z danymi analitycznymi), nazwy hosta/IP (jeśli zapytania OLAP są wykonywane z określonego hosta), użytkownika (jeśli aplikacja używa konkretnego użytkownika dla zapytań analitycznych. Możesz także dopasować zapytania bezpośrednio, przekazując pełne zapytanie lub zaznaczając je komentarzami SQL i pozwól ProxySQL przekierować wszystkie zapytania z ciągiem „OLAP_QUERY” do naszej analitycznej grupy hostów.
Jak widać, dzięki ClusterControl byliśmy w stanie wdrożyć niewolnika replikacji w Galera Cluster za pomocą zaledwie kilku kliknięć. Niektórzy mogą argumentować, że MySQL nie jest najbardziej odpowiednią bazą danych do zadań analitycznych i zazwyczaj się z tym zgadzamy. Możesz łatwo rozszerzyć tę konfigurację za pomocą ClickHouse i konfigurując replikację z asynchronicznego urządzenia podrzędnego do kolumnowego magazynu danych ClickHouse, aby uzyskać znacznie lepszą wydajność zapytań analitycznych. Opisaliśmy tę konfigurację w jednym z wcześniejszych postów na blogu.