Python jest obecnie bardzo popularny. Ponieważ Python jest językiem programowania ogólnego przeznaczenia, może być również używany do wykonywania procesów Extract, Transform, Load (ETL). Dostępne są różne moduły ETL, ale dzisiaj pozostaniemy przy połączeniu Pythona i MySQL. Użyjemy Pythona do wywoływania procedur składowanych oraz przygotowywania i wykonywania instrukcji SQL.
Użyjemy dwóch podobnych, ale różnych podejść. Najpierw wywołamy procedury składowane, które wykonają całą pracę, a następnie przeanalizujemy, jak możemy wykonać ten sam proces bez procedur składowanych, używając kodu MySQL w Pythonie.
Gotowy? Zanim zagłębimy się w temat, spójrzmy na model danych – lub modele danych, ponieważ w tym artykule są dwa z nich.
Modele danych
Będziemy potrzebować dwóch modeli danych, jednego do przechowywania naszych danych operacyjnych, a drugiego do przechowywania naszych danych raportowania.
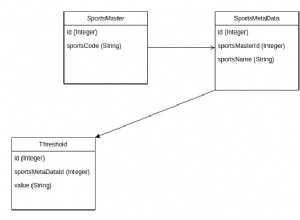
Pierwszy model pokazuje powyższy obrazek. Ten model służy do przechowywania danych operacyjnych (na żywo) dla działalności opartej na subskrypcji. Aby uzyskać więcej informacji na temat tego modelu, zapoznaj się z naszym poprzednim artykułem, Tworzenie DWH, część pierwsza:model danych biznesowych subskrypcji.
Rozdzielenie danych operacyjnych i sprawozdawczych jest zwykle bardzo mądrą decyzją. Aby to osiągnąć, musimy stworzyć hurtownię danych (DWH). Już to zrobiliśmy; możesz zobaczyć model na powyższym obrazku. Model ten jest również szczegółowo opisany w poście Tworzenie DWH, część druga:model danych biznesowych subskrypcji.
Na koniec musimy wyodrębnić dane z działającej bazy danych, przekształcić je i załadować do naszego DWH. Zrobiliśmy to już za pomocą procedur składowanych SQL. Opis tego, co chcemy osiągnąć, wraz z przykładami kodu można znaleźć w Tworzenie hurtowni danych, część 3:Model danych biznesowych subskrypcji.
Jeśli potrzebujesz dodatkowych informacji na temat DWH, zalecamy przeczytanie tych artykułów:
- Schemat gwiazdy
- Schemat płatka śniegu
- Schemat gwiazdy kontra schemat płatka śniegu.
Naszym dzisiejszym zadaniem jest zastąpienie procedur składowanych SQL kodem Pythona. Jesteśmy gotowi na odrobinę magii Pythona. Zacznijmy od używania tylko procedur składowanych w Pythonie.
Metoda 1:ETL przy użyciu procedur zapisanych
Zanim zaczniemy opisywać proces, warto wspomnieć, że na naszym serwerze mamy dwie bazy danych.
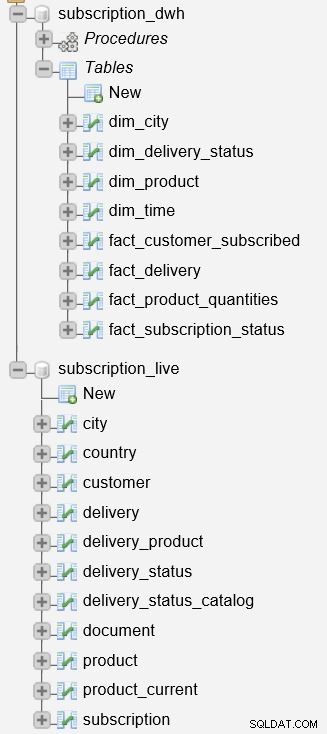
subscription_live baza danych służy do przechowywania danych transakcyjnych/na żywo, natomiast subscription_dwh to nasza baza danych raportowania (DWH).
Opisaliśmy już procedury składowane używane do aktualizowania tabel wymiarów i faktów. Będą czytać dane z subscription_live bazy danych, połącz ją z danymi w subscription_dwh bazy danych i wstaw nowe dane do subscription_dwh Baza danych. Te dwie procedury to:
p_update_dimensions– Aktualizuje tabele wymiarówdim_timeidim_city.p_update_facts– Aktualizuje dwie tabele faktów,fact_customer_subscribedifact_subscription_status.
Jeśli chcesz zobaczyć pełny kod dla tych procedur, przeczytaj Tworzenie hurtowni danych, część 3:Model danych biznesowych subskrypcji.
Teraz jesteśmy gotowi do napisania prostego skryptu w Pythonie, który połączy się z serwerem i wykona proces ETL. Przyjrzyjmy się najpierw całemu skryptowi (etl_procedures.py ). Następnie wyjaśnimy najważniejsze części.
# import MySQL connector import mysql.connector # connect to server connection = mysql.connector.connect(user='', password=' ', host='127.0.0.1') print('Connected to database.') cursor = connection.cursor() # I update dimensions cursor.callproc('subscription_dwh.p_update_dimensions') print('Dimension tables updated.') # II update facts cursor.callproc('subscription_dwh.p_update_facts') print('Fact tables updated.') # commit & close connection cursor.close() connection.commit() connection.close() print('Disconnected from database.')
etl_procedures.py
Importowanie modułów i łączenie się z bazą danych
Python używa modułów do przechowywania definicji i instrukcji. Możesz użyć istniejącego modułu lub napisać własny. Korzystanie z istniejących modułów uprości Twoje życie, ponieważ korzystasz z gotowego kodu, ale pisanie własnego modułu jest również bardzo przydatne. Gdy zamkniesz interpreter Pythona i uruchomisz go ponownie, stracisz funkcje i zmienne, które wcześniej zdefiniowałeś. Oczywiście nie chcesz w kółko wpisywać tego samego kodu. Aby tego uniknąć, możesz przechowywać swoje definicje w module i zaimportować je do Pythona.
Powrót do etl_procedures.py . W naszym programie zaczynamy od importu MySQL Connector:
# import MySQL connector import mysql.connector
MySQL Connector for Python jest używany jako ustandaryzowany sterownik, który łączy się z serwerem/bazą danych MySQL. Musisz go pobrać i zainstalować, jeśli wcześniej tego nie zrobiłeś. Oprócz łączenia się z bazą danych oferuje szereg metod i właściwości do pracy z bazą danych. Wykorzystamy niektóre z nich, ale pełną dokumentację możesz sprawdzić tutaj.
Następnie musimy połączyć się z naszą bazą danych:
# connect to server connection = mysql.connector.connect(user='', password=' ', host='127.0.0.1') print('Connected to database.') cursor = connection.cursor()
Pierwszy wiersz połączy się z serwerem (w tym przypadku łączę się z moim lokalnym komputerem) przy użyciu twoich danych uwierzytelniających (zastąp
connection = mysql.connector.connect(user='', password=' ', host='127.0.0.1', database=' ')
Celowo połączyłem się tylko z serwerem, a nie z konkretną bazą danych, ponieważ będę używał dwóch baz danych znajdujących się na tym samym serwerze.
Następne polecenie – drukuj – jest tutaj tylko powiadomienie, że udało nam się połączyć. Chociaż nie ma to znaczenia programistycznego, można go użyć do debugowania kodu, jeśli coś poszło nie tak w skrypcie.
Ostatni wiersz w tej części to:
kursor =connection.cursor()
Cursors are the handler structure used to work with the data. We’ll use them for retrieving data from the database (SELECT), but also to modify the data (INSERT, UPDATE, DELETE). Before using a cursor, we need to create it. And that is what this line does.
Procedury telefoniczne
Poprzednia część była ogólna i mogła być wykorzystana do innych zadań związanych z bazą danych. Poniższa część kodu jest przeznaczona specjalnie dla ETL:wywoływanie naszych procedur składowanych za pomocą cursor.callproc Komenda. Wygląda to tak:
# 1. update dimensions
cursor.callproc('subscription_dwh.p_update_dimensions')
print('Dimension tables updated.')
# 2. update facts
cursor.callproc('subscription_dwh.p_update_facts')
print('Fact tables updated.')
Procedury wywoływania nie wymagają wyjaśnień. Po każdym wywołaniu dodawana była komenda drukowania. Ponownie, to po prostu daje nam powiadomienie, że wszystko poszło dobrze.
Zatwierdź i zamknij
Ostatnia część skryptu zatwierdza zmiany w bazie danych i zamyka wszystkie używane obiekty:
# commit & close connection
cursor.close()
connection.commit()
connection.close()
print('Disconnected from database.')
Procedury wywoływania nie wymagają wyjaśnień. Po każdym wywołaniu dodawana była komenda drukowania. Ponownie, to po prostu daje nam powiadomienie, że wszystko poszło dobrze.
Zaangażowanie jest tutaj niezbędne; bez tego nie będzie żadnych zmian w bazie danych, nawet jeśli wywołasz procedurę lub wykonasz instrukcję SQL.
Uruchamianie skryptu
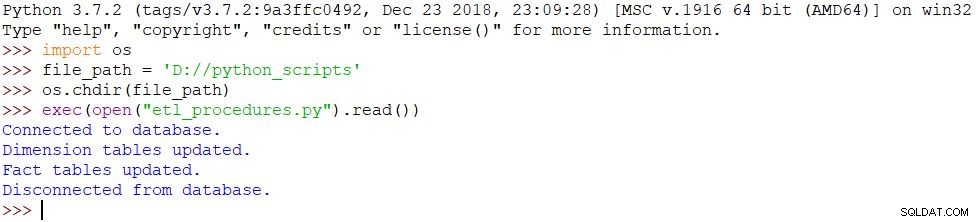
Ostatnią rzeczą, którą musimy zrobić, to uruchomić nasz skrypt. Aby to osiągnąć, użyjemy następujących poleceń w powłoce Pythona:
import osfile_path ='D://python_scripts'os.chdir(ścieżka_pliku)exec(open("etl_procedures.py").read())Skrypt jest wykonywany i wszystkie zmiany w bazie danych są odpowiednio wprowadzane. Wynik można zobaczyć na poniższym obrazku.
Metoda 2:ETL przy użyciu Pythona i MySQL
Przedstawione powyżej podejście nie różni się zbytnio od podejścia polegającego na wywoływaniu procedur składowanych bezpośrednio w MySQL. Jedyną różnicą jest to, że teraz mamy skrypt, który wykona za nas całą robotę.
Moglibyśmy zastosować inne podejście:umieszczenie wszystkiego w skrypcie Pythona. Zamieścimy instrukcje Pythona, ale przygotujemy również zapytania SQL i wykonamy je w bazie danych. Źródłowa baza danych (na żywo) i docelowa baza danych (DWH) są takie same, jak w przykładzie z procedurami składowanymi.
Zanim zagłębimy się w to, przyjrzyjmy się całemu skryptowi (etl_queries.py ):
from datetime import date # import MySQL connector import mysql.connector # connect to server connection = mysql.connector.connect(user='', password=' ', host='127.0.0.1') print('Connected to database.') # 1. update dimensions # 1.1 update dim_time # date - yesterday yesterday = date.fromordinal(date.today().toordinal()-1) yesterday_str = '"' + str(yesterday) + '"' # test if date is already in the table cursor = connection.cursor() query = ( "SELECT COUNT(*) " "FROM subscription_dwh.dim_time " "WHERE time_date = " + yesterday_str) cursor.execute(query) result = cursor.fetchall() yesterday_subscription_count = int(result[0][0]) if yesterday_subscription_count == 0: yesterday_year = 'YEAR("' + str(yesterday) + '")' yesterday_month = 'MONTH("' + str(yesterday) + '")' yesterday_week = 'WEEK("' + str(yesterday) + '")' yesterday_weekday = 'WEEKDAY("' + str(yesterday) + '")' query = ( "INSERT INTO subscription_dwh.`dim_time`(`time_date`, `time_year`, `time_month`, `time_week`, `time_weekday`, `ts`) " " VALUES (" + yesterday_str + ", " + yesterday_year + ", " + yesterday_month + ", " + yesterday_week + ", " + yesterday_weekday + ", Now())") cursor.execute(query) # 1.2 update dim_city query = ( "INSERT INTO subscription_dwh.`dim_city`(`city_name`, `postal_code`, `country_name`, `ts`) " "SELECT city_live.city_name, city_live.postal_code, country_live.country_name, Now() " "FROM subscription_live.city city_live " "INNER JOIN subscription_live.country country_live ON city_live.country_id = country_live.id " "LEFT JOIN subscription_dwh.dim_city city_dwh ON city_live.city_name = city_dwh.city_name AND city_live.postal_code = city_dwh.postal_code AND country_live.country_name = city_dwh.country_name " "WHERE city_dwh.id IS NULL") cursor.execute(query) print('Dimension tables updated.') # 2. update facts # 2.1 update customers subscribed # delete old data for the same date query = ( "DELETE subscription_dwh.`fact_customer_subscribed`.* " "FROM subscription_dwh.`fact_customer_subscribed` " "INNER JOIN subscription_dwh.`dim_time` ON subscription_dwh.`fact_customer_subscribed`.`dim_time_id` = subscription_dwh.`dim_time`.`id` " "WHERE subscription_dwh.`dim_time`.`time_date` = " + yesterday_str) cursor.execute(query) # insert new data query = ( "INSERT INTO subscription_dwh.`fact_customer_subscribed`(`dim_city_id`, `dim_time_id`, `total_active`, `total_inactive`, `daily_new`, `daily_canceled`, `ts`) " " SELECT city_dwh.id AS dim_ctiy_id, time_dwh.id AS dim_time_id, SUM(CASE WHEN customer_live.active = 1 THEN 1 ELSE 0 END) AS total_active, SUM(CASE WHEN customer_live.active = 0 THEN 1 ELSE 0 END) AS total_inactive, SUM(CASE WHEN customer_live.active = 1 AND DATE(customer_live.time_updated) = @time_date THEN 1 ELSE 0 END) AS daily_new, SUM(CASE WHEN customer_live.active = 0 AND DATE(customer_live.time_updated) = @time_date THEN 1 ELSE 0 END) AS daily_canceled, MIN(NOW()) AS ts " "FROM subscription_live.`customer` customer_live " "INNER JOIN subscription_live.`city` city_live ON customer_live.city_id = city_live.id " "INNER JOIN subscription_live.`country` country_live ON city_live.country_id = country_live.id " "INNER JOIN subscription_dwh.dim_city city_dwh ON city_live.city_name = city_dwh.city_name AND city_live.postal_code = city_dwh.postal_code AND country_live.country_name = city_dwh.country_name " "INNER JOIN subscription_dwh.dim_time time_dwh ON time_dwh.time_date = " + yesterday_str + " " "GROUP BY city_dwh.id, time_dwh.id") cursor.execute(query) # 2.2 update subscription statuses # delete old data for the same date query = ( "DELETE subscription_dwh.`fact_subscription_status`.* " "FROM subscription_dwh.`fact_subscription_status` " "INNER JOIN subscription_dwh.`dim_time` ON subscription_dwh.`fact_subscription_status`.`dim_time_id` = subscription_dwh.`dim_time`.`id` " "WHERE subscription_dwh.`dim_time`.`time_date` = " + yesterday_str) cursor.execute(query) # insert new data query = ( "INSERT INTO subscription_dwh.`fact_subscription_status`(`dim_city_id`, `dim_time_id`, `total_active`, `total_inactive`, `daily_new`, `daily_canceled`, `ts`) " "SELECT city_dwh.id AS dim_ctiy_id, time_dwh.id AS dim_time_id, SUM(CASE WHEN subscription_live.active = 1 THEN 1 ELSE 0 END) AS total_active, SUM(CASE WHEN subscription_live.active = 0 THEN 1 ELSE 0 END) AS total_inactive, SUM(CASE WHEN subscription_live.active = 1 AND DATE(subscription_live.time_updated) = @time_date THEN 1 ELSE 0 END) AS daily_new, SUM(CASE WHEN subscription_live.active = 0 AND DATE(subscription_live.time_updated) = @time_date THEN 1 ELSE 0 END) AS daily_canceled, MIN(NOW()) AS ts " "FROM subscription_live.`customer` customer_live " "INNER JOIN subscription_live.`subscription` subscription_live ON subscription_live.customer_id = customer_live.id " "INNER JOIN subscription_live.`city` city_live ON customer_live.city_id = city_live.id " "INNER JOIN subscription_live.`country` country_live ON city_live.country_id = country_live.id " "INNER JOIN subscription_dwh.dim_city city_dwh ON city_live.city_name = city_dwh.city_name AND city_live.postal_code = city_dwh.postal_code AND country_live.country_name = city_dwh.country_name " "INNER JOIN subscription_dwh.dim_time time_dwh ON time_dwh.time_date = " + yesterday_str + " " "GROUP BY city_dwh.id, time_dwh.id") cursor.execute(query) print('Fact tables updated.') # commit & close connection cursor.close() connection.commit() connection.close() print('Disconnected from database.')
etl_queries.py
Importowanie modułów i łączenie się z bazą danych
Jeszcze raz będziemy musieli zaimportować MySQL za pomocą następującego kodu:
import mysql.connector
Zaimportujemy również moduł datetime, jak pokazano poniżej. Potrzebujemy tego do operacji związanych z datami w Pythonie:
from datetime import date
Proces łączenia się z bazą danych jest taki sam jak w poprzednim przykładzie.
Aktualizacja wymiaru dim_time
Aby zaktualizować dim_time tabeli, musimy sprawdzić, czy wartość (za wczoraj) jest już w tabeli. W tym celu będziemy musieli użyć funkcji daty Pythona (zamiast SQL):
# date - yesterday yesterday = date.fromordinal(date.today().toordinal()-1) yesterday_str = '"' + str(yesterday) + '"'
Pierwszy wiersz kodu zwróci wczorajszą datę w zmiennej date, natomiast drugi wiersz przechowa tę wartość jako ciąg. Będziemy potrzebować tego jako ciągu, ponieważ połączymy go z innym ciągiem podczas tworzenia zapytania SQL.
Następnie musimy sprawdzić, czy ta data jest już w dim_time stół. Po zadeklarowaniu kursora przygotujemy zapytanie SQL. Aby wykonać zapytanie, użyjemy cursor.execute polecenie:
# test if date is already in the table cursor = connection.cursor() query = ( "SELECT COUNT(*) " "FROM subscription_dwh.dim_time " "WHERE time_date = " + yesterday_str) cursor.execute(query) '"'
Wyniki zapytania będziemy przechowywać w wyniku zmienny. Wynik będzie miał 0 lub 1 wiersz, więc możemy przetestować pierwszą kolumnę pierwszego wiersza. Będzie zawierać 0 lub 1. (Pamiętaj, że tę samą datę możemy podać tylko raz w tabeli wymiarów).
Jeśli data nie jest jeszcze w tabeli, przygotujemy ciągi, które będą częścią zapytania SQL:
result = cursor.fetchall()
yesterday_subscription_count = int(result[0][0])
if yesterday_subscription_count == 0:
yesterday_year = 'YEAR("' + str(yesterday) + '")'
yesterday_month = 'MONTH("' + str(yesterday) + '")'
yesterday_week = 'WEEK("' + str(yesterday) + '")'
yesterday_weekday = 'WEEKDAY("' + str(yesterday) + '")'
Na koniec zbudujemy zapytanie i je wykonamy. To zaktualizuje dim_time tabela po jej zatwierdzeniu. Proszę zauważyć, że użyłem pełnej ścieżki do tabeli, w tym nazwy bazy danych (subscription_dwh ).
query = (
"INSERT INTO subscription_dwh.`dim_time`(`time_date`, `time_year`, `time_month`, `time_week`, `time_weekday`, `ts`) "
" VALUES (" + yesterday_str + ", " + yesterday_year + ", " + yesterday_month + ", " + yesterday_week + ", " + yesterday_weekday + ", Now())")
cursor.execute(query)
Zaktualizuj wymiar dim_city
Aktualizacja dim_city tabela jest jeszcze prostsza, ponieważ nie musimy niczego testować przed wstawieniem. W rzeczywistości uwzględnimy ten test w zapytaniu SQL.
# 1.2 update dim_city query = ( "INSERT INTO subscription_dwh.`dim_city`(`city_name`, `postal_code`, `country_name`, `ts`) " "SELECT city_live.city_name, city_live.postal_code, country_live.country_name, Now() " "FROM subscription_live.city city_live " "INNER JOIN subscription_live.country country_live ON city_live.country_id = country_live.id " "LEFT JOIN subscription_dwh.dim_city city_dwh ON city_live.city_name = city_dwh.city_name AND city_live.postal_code = city_dwh.postal_code AND country_live.country_name = city_dwh.country_name " "WHERE city_dwh.id IS NULL") cursor.execute(query)
Tu przygotowujemy wykonanie zapytania SQL. Zauważ, że ponownie użyłem pełnych ścieżek do tabel, w tym nazw obu baz danych (subscription_live i subscription_dwh ).
Aktualizacja tabel faktów
Ostatnią rzeczą, którą musimy zrobić, to zaktualizować nasze tabele faktów. Proces przebiega prawie tak samo, jak aktualizacja tabel wymiarów:przygotowujemy zapytania i je wykonujemy. Te zapytania są znacznie bardziej złożone, ale są takie same jak zapytania używane w procedurach składowanych.
Dodaliśmy jedno ulepszenie w porównaniu z procedurami składowanymi:usunięcie istniejących danych z tej samej daty w tabeli faktów. Umożliwi nam to wielokrotne uruchomienie skryptu dla tej samej daty. Na koniec musimy zatwierdzić transakcję i zamknąć wszystkie obiekty oraz połączenie.
Uruchamianie skryptu
W tej części mamy niewielką zmianę, która polega na wywołaniu innego skryptu:
- import os
- file_path = 'D://python_scripts'
- os.chdir(file_path)
- exec(open("etl_queries.py").read())
Ponieważ użyliśmy tych samych wiadomości, a skrypt zakończył się pomyślnie, wynik jest taki sam:
Jak byś używał Pythona w ETL?
Dzisiaj widzieliśmy jeden przykład wykonania procesu ETL za pomocą skryptu Pythona. Można to zrobić na inne sposoby, m.in. szereg rozwiązań open-source, które wykorzystują biblioteki Pythona do pracy z bazami danych i wykonywania procesu ETL. W następnym artykule zagramy z jednym z nich. W międzyczasie możesz podzielić się swoimi doświadczeniami z Pythonem i ETL.