Wcześniej opublikowaliśmy blog omawiający Osiąganie przełączania awaryjnego i powrotu po awarii w Google Cloud Platform (GCP), a w tym blogu przyjrzymy się, jak jego rywal, Amazon Relational Database Service (RDS), radzi sobie z przełączaniem awaryjnym. Przyjrzymy się również, w jaki sposób można wykonać powrót po awarii do poprzedniego węzła głównego, przywracając go do pierwotnej kolejności jako głównego.
Porównując gigantyczne technologicznie chmury publiczne obsługujące zarządzane usługi relacyjnych baz danych, Amazon jako jedyny oferuje alternatywną opcję (wraz z MySQL/MariaDB, PostgreSQL, Oracle i SQL Server) w celu dostarczenia własny rodzaj zarządzania bazą danych o nazwie Amazon Aurora. Dla tych, którzy nie znają Aurory, jest to w pełni zarządzany silnik relacyjnej bazy danych, który jest kompatybilny z MySQL i PostgreSQL. Aurora jest częścią usługi zarządzanej bazy danych Amazon RDS, usługi sieciowej, która ułatwia konfigurację, obsługę i skalowanie relacyjnej bazy danych w chmurze.
Dlaczego trzeba by było przełączać się po awarii lub po awarii?
Projektowanie dużego systemu, który jest odporny na awarie, wysoce dostępny, bez pojedynczego punktu awarii (SPOF) wymaga odpowiednich testów, aby określić, jak zareaguje, gdy coś pójdzie nie tak.
Jeśli obawiasz się, jak system będzie działał podczas reagowania na FDIR (Fault Detection, Isolation and Recovery), wtedy przełączenie awaryjne i powrót po awarii powinny mieć duże znaczenie.
Awaryjne przełączanie bazy danych w Amazon RDS
Przełączanie awaryjne następuje automatycznie (ponieważ ręczne przełączanie awaryjne nazywa się przełączaniem). Jak omówiono w poprzednim blogu, konieczność przełączenia awaryjnego występuje, gdy w bieżącym systemie głównym bazy danych wystąpi awaria sieci lub nieprawidłowe zakończenie działania systemu hosta. Przełączanie awaryjne przełącza go do stabilnego stanu nadmiarowości lub do rezerwowego serwera komputerowego, systemu, komponentu sprzętowego lub sieci.
W Amazon RDS nie musisz tego robić, ani nie musisz sam tego monitorować, ponieważ RDS jest usługą zarządzanej bazy danych (co oznacza, że Amazon wykonuje to zadanie za Ciebie). Ta usługa zarządza takimi rzeczami, jak problemy ze sprzętem, tworzenie kopii zapasowych i odzyskiwanie, aktualizacje oprogramowania, uaktualnienia pamięci masowej, a nawet łatanie oprogramowania. Porozmawiamy o tym w dalszej części tego bloga.
Powrót po awarii bazy danych w Amazon RDS
W poprzednim blogu omówiliśmy również, dlaczego konieczne jest przełączanie po awarii. W typowym środowisku replikowanym master musi być wystarczająco mocny, aby przenosić ogromne obciążenie, zwłaszcza gdy wymagania dotyczące obciążenia są wysokie. Twoja główna konfiguracja wymaga odpowiednich specyfikacji sprzętowych, aby zapewnić stabilne przetwarzanie zapisów, generowanie zdarzeń replikacji, przetwarzanie krytycznych odczytów itp. Gdy wymagane jest przełączanie awaryjne podczas odzyskiwania po awarii (lub w celu konserwacji), często zdarza się, że promując nowy master, można użyć gorszego sprzętu. Ta sytuacja może chwilowo być w porządku, ale na dłuższą metę wyznaczony master musi zostać przywrócony, aby poprowadzić replikację po uznaniu jej za zdrową (lub zakończeniu konserwacji).
W przeciwieństwie do przełączania awaryjnego, operacje powrotu po awarii zwykle odbywają się w kontrolowanym środowisku przy użyciu przełączania. Rzadko się to robi w trybie paniki. Takie podejście zapewnia inżynierom wystarczająco dużo czasu, aby dokładnie zaplanować i przećwiczyć ćwiczenie, aby zapewnić płynne przejście. Jego głównym celem jest po prostu przywrócenie dobrego, starego wzorca do najnowszego stanu i przywrócenie konfiguracji replikacji do pierwotnej topologii. Ponieważ mamy do czynienia z Amazon RDS, naprawdę nie musisz się zbytnio przejmować tego typu problemami, ponieważ jest to usługa zarządzana, w której większość zadań jest obsługiwana przez Amazon.
Jak Amazon RDS obsługuje awaryjne przełączanie bazy danych?
Wdrażając węzły Amazon RDS, możesz skonfigurować klaster bazy danych ze strefą Multi-Availability Zone (AZ) lub Single-Availability Zone. Sprawdźmy każdy z nich, w jaki sposób przetwarzane jest przełączanie awaryjne.
Co to jest konfiguracja Multi-AZ?
W przypadku wystąpienia katastrofy lub katastrofy, takiej jak nieplanowane przestoje lub klęski żywiołowe, których dotyczy wystąpienie Twojej bazy danych, Amazon RDS automatycznie przełącza się na replikę rezerwową w innej Strefie Dostępności. Ten AZ znajduje się zwykle w innym oddziale centrum danych, często daleko od aktualnej strefy dostępności, w której znajdują się instancje. Te AZ są wysoce dostępnymi, najnowocześniejszymi funkcjami chroniącymi instancje baz danych. Czasy przełączania awaryjnego zależą od zakończenia konfiguracji, która często jest oparta na rozmiarze i aktywności bazy danych, a także innych warunkach występujących w momencie, gdy podstawowa instancja bazy danych stała się niedostępna.
Czasy przełączania awaryjnego wynoszą zazwyczaj 60-120 sekund. Mogą być jednak dłuższe, ponieważ duże transakcje lub długi proces odzyskiwania mogą wydłużyć czas przełączania awaryjnego. Po zakończeniu przełączania awaryjnego może upłynąć dodatkowy czas, zanim konsola RDS (UI) odzwierciedli nową strefę dostępności.
Co to jest konfiguracja pojedynczego AZ?
Konfiguracje Single-AZ powinny być używane dla instancji bazy danych tylko wtedy, gdy RTO (Cel czasu odzyskiwania) i RPO (Cel punktu odzyskiwania) są wystarczająco wysokie, aby to umożliwić. Istnieje ryzyko związane z używaniem Single-AZ, takie jak duże przestoje, które mogą zakłócić działalność biznesową.
Częste scenariusze awarii RDS
Ilość przestojów zależy od rodzaju awarii. Przyjrzyjmy się, co to jest i jak obsługiwane jest odzyskiwanie instancji.
Naprawialna awaria wystąpienia
Awaria instancji Amazon RDS występuje, gdy ulegnie awarii bazowa instancja EC2. Po wystąpieniu AWS uruchomi powiadomienie o zdarzeniu i wyśle do Ciebie alert za pomocą Powiadomień o zdarzeniach Amazon RDS. Ten system używa usługi AWS Simple Notification Service (SNS) jako procesora alertów.
RDS automatycznie spróbuje uruchomić nową instancję w tej samej strefie dostępności, podłączyć wolumin EBS i spróbuje odzyskać dane. W tym scenariuszu RTO jest zwykle poniżej 30 minut. RPO wynosi zero, ponieważ udało się odzyskać wolumen EBS. Wolumin EBS znajduje się w jednej Strefie dostępności, a ten typ odzyskiwania odbywa się w tej samej Strefie dostępności, co oryginalne wystąpienie.
Nienaprawialne awarie instancji lub awarie wolumenów EBS
W przypadku nieudanego odzyskiwania instancji RDS (lub jeśli bazowy wolumin EBS ulegnie awarii związanej z utratą danych) wymagane jest odzyskiwanie do punktu w czasie (PITR). PITR nie jest automatycznie obsługiwany przez Amazon, więc musisz albo utworzyć skrypt, aby go zautomatyzować (za pomocą AWS Lambda), albo zrobić to ręcznie.
Czas RTO wymaga uruchomienia nowej instancji Amazon RDS, która po utworzeniu będzie miała nową nazwę DNS, a następnie zastosowania wszystkich zmian od ostatniej kopii zapasowej.
Okres RPO trwa zwykle 5 minut, ale można go znaleźć, wywołując RDS:describe-db-instances:LatestRestorableTime. Czas ten może wahać się od 10 minut do godzin w zależności od liczby kłód, które należy zastosować. Można to określić tylko przez testowanie, ponieważ zależy to od rozmiaru bazy danych, liczby zmian wprowadzonych od ostatniej kopii zapasowej i poziomów obciążenia bazy danych. Ponieważ kopie zapasowe i dzienniki transakcji są przechowywane w Amazon S3, to odzyskiwanie może nastąpić w dowolnej obsługiwanej strefie dostępności w regionie.
Po utworzeniu nowej instancji konieczne będzie zaktualizowanie nazwy punktu końcowego klienta. Masz również możliwość zmiany jego nazwy na nazwę punktu końcowego starej instancji DB (ale wymaga to usunięcia starej, nieudanej instancji), ale to uniemożliwia określenie głównej przyczyny problemu.
Zakłócenia w strefie dostępności
Zakłócenia w strefie dostępności mogą być tymczasowe i rzadkie, jednak jeśli awaria AZ jest bardziej trwała, instancja zostanie ustawiona w stan niepowodzenia. Odzyskiwanie działałoby zgodnie z wcześniejszym opisem, a nowe wystąpienie mogłoby zostać utworzone w innej strefie AZ przy użyciu odzyskiwania do określonego momentu. Ten krok należy wykonać ręcznie lub za pomocą skryptów. Strategia dla tego typu scenariusza odzyskiwania powinna być częścią większych planów odzyskiwania po awarii (DR).
Jeśli awaria strefy dostępności jest tymczasowa, baza danych przestanie działać, ale pozostanie w stanie dostępności. Jesteś odpowiedzialny za monitorowanie na poziomie aplikacji (przy użyciu narzędzi Amazon lub innych firm) w celu wykrycia tego typu scenariusza. W takim przypadku możesz poczekać, aż strefa dostępności zostanie przywrócona, lub możesz wybrać odzyskanie instancji do innej strefy dostępności z odzyskiwaniem do określonego momentu.
RTO to czas potrzebny do uruchomienia nowej instancji RDS, a następnie zastosowania wszystkich zmian od ostatniej kopii zapasowej. RPO może być dłuższy, do czasu wystąpienia awarii strefy dostępności.
Testowanie przełączania awaryjnego i powrotu po awarii w Amazon RDS
Stworzyliśmy i skonfigurowaliśmy Amazon RDS Aurora przy użyciu db.r4.large z wdrożeniem Multi-AZ (co utworzy replikę/czytnik Aurora w innym AZ), który jest dostępny tylko przez EC2. Musisz wybrać tę opcję podczas tworzenia, jeśli zamierzasz korzystać z Amazon RDS jako mechanizmu przełączania awaryjnego.
Podczas udostępniania naszej instancji RDS zajęło to około 11 minut instancje stały się dostępne i dostępne. Poniżej znajduje się zrzut ekranu węzłów dostępnych w RDS po utworzeniu:
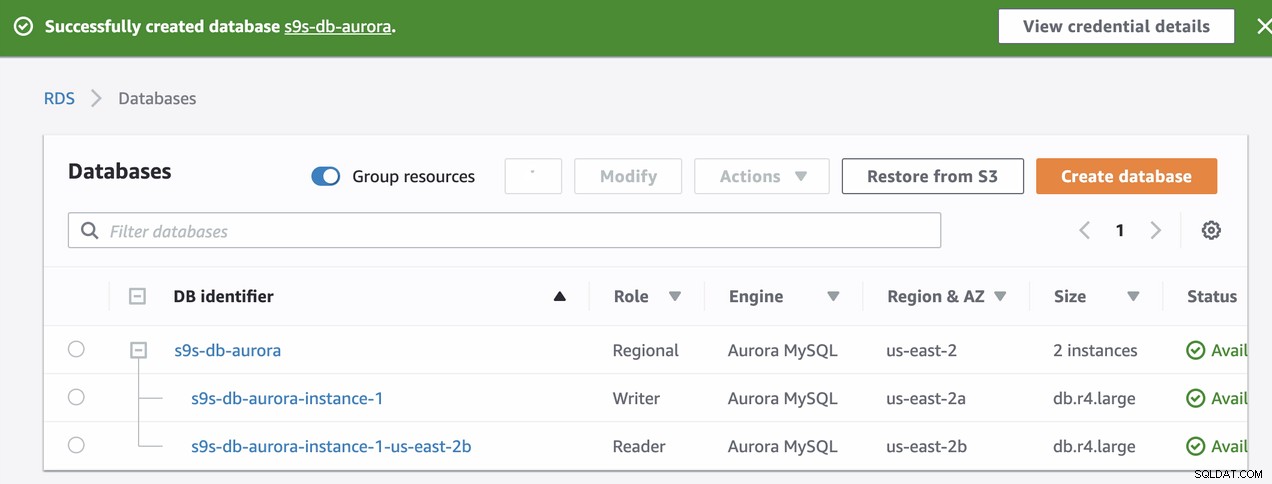
Te dwa węzły będą miały własne wyznaczone nazwy punktów końcowych, które będziemy służy do łączenia się z perspektywy klienta. Sprawdź go najpierw i sprawdź podstawową nazwę hosta dla każdego z tych węzłów. Aby to sprawdzić, możesz uruchomić to polecenie bash poniżej i po prostu odpowiednio zamienić nazwy hostów/nazwy punktów końcowych:
example@sqldat.com:~# host=('s9s-db-aurora.cluster-cmu8qdlvkepg.us-east-2.rds.amazonaws.com' 's9s-db-aurora.cluster-ro-cmu8qdlvkepg.us-east-2.rds.amazonaws.com'); for h in "${host[@]}"; do mysql -h $h -e "select @@hostname; select @@global.innodb_read_only"; done;
+---------------+
| @@hostname |
+---------------+
| ip-10-20-0-94 |
+---------------+
+---------------------------+
| @@global.innodb_read_only |
+---------------------------+
| 0 |
+---------------------------+
+----------------+
| @@hostname |
+----------------+
| ip-10-20-1-139 |
+----------------+
+---------------------------+
| @@global.innodb_read_only |
+---------------------------+
| 1 |
+---------------------------+Wynik wyjaśnia się następująco,
s9s-db-aurora-instance-1 = s9s-db-aurora.cluster-cmu8qdlvkepg.us-east-2.rds.amazonaws.com = ip-10-20-0-94 (read-write)
s9s-db-aurora-instance-1-us-east-2b = s9s-db-aurora.cluster-ro-cmu8qdlvkepg.us-east-2.rds.amazonaws.com = ip-10-20-1-139 (read-only)Symulowanie przełączania awaryjnego Amazon RDS
Teraz zasymulujmy awarię, aby zasymulować przełączenie awaryjne dla instancji programu zapisującego Amazon RDS Aurora, czyli s9s-db-aurora-instance-1 z punktem końcowym s9s-db-aurora.cluster-cmu8qdlvkepg.us -wschód-2.rds.amazonaws.com.
W tym celu połącz się z instancją programu piszącego za pomocą wiersza poleceń klienta mysql, a następnie wprowadź poniższą składnię:
ALTER SYSTEM SIMULATE percentage_of_failure PERCENT DISK FAILURE [ IN DISK index | NODE index ]
FOR INTERVAL quantity [ YEAR | QUARTER | MONTH | WEEK| DAY | HOUR | MINUTE | SECOND ];Wydanie tego polecenia ma wykrywanie odzyskiwania Amazon RDS i działa dość szybko. Chociaż zapytanie jest przeznaczone do celów testowych, może się różnić, gdy to zdarzenie ma miejsce w zdarzeniu faktycznym. Możesz chcieć dowiedzieć się więcej o testowaniu awarii instancji w ich dokumentacji. Zobacz, jak kończymy poniżej:
mysql> ALTER SYSTEM SIMULATE 100 PERCENT DISK FAILURE FOR INTERVAL 3 MINUTE;
Query OK, 0 rows affected (0.01 sec)Uruchomienie powyższego polecenia SQL oznacza, że musi ono symulować awarię dysku przez co najmniej 3 minuty. Monitorowałem moment rozpoczęcia symulacji i zajęło mi około 18 sekund, zanim rozpocznie się przełączanie awaryjne.
Zobacz poniżej, jak RDS radzi sobie z awarią symulacji i przełączaniem awaryjnym,
Tue Sep 24 10:06:29 UTC 2019
+---------------+
| @@hostname |
+---------------+
| ip-10-20-0-94 |
+---------------+
+---------------------------+
| @@global.innodb_read_only |
+---------------------------+
| 0 |
+---------------------------+
+----------------+
| @@hostname |
+----------------+
| ip-10-20-1-139 |
+----------------+
+---------------------------+
| @@global.innodb_read_only |
+---------------------------+
| 1 |
+---------------------------+
….
…..
………..
Tue Sep 24 10:06:44 UTC 2019
+---------------+
| @@hostname |
+---------------+
| ip-10-20-0-94 |
+---------------+
+---------------------------+
| @@global.innodb_read_only |
+---------------------------+
| 0 |
+---------------------------+
ERROR 2003 (HY000): Can't connect to MySQL server on 's9s-db-aurora.cluster-ro-cmu8qdlvkepg.us-east-2.rds.amazonaws.com' (111)
….
……..
………..
Tue Sep 24 10:06:51 UTC 2019
+---------------+
| @@hostname |
+---------------+
| ip-10-20-0-94 |
+---------------+
+---------------------------+
| @@global.innodb_read_only |
+---------------------------+
| 0 |
+---------------------------+
+----------------+
| @@hostname |
+----------------+
| ip-10-20-1-139 |
+----------------+
+---------------------------+
| @@global.innodb_read_only |
+---------------------------+
| 0 |
+---------------------------+
….
………..
…………………
Tue Sep 24 10:07:13 UTC 2019
+----------------+
| @@hostname |
+----------------+
| ip-10-20-1-139 |
+----------------+
+---------------------------+
| @@global.innodb_read_only |
+---------------------------+
| 0 |
+---------------------------+
+---------------+
| @@hostname |
+---------------+
| ip-10-20-0-94 |
+---------------+
+---------------------------+
| @@global.innodb_read_only |
+---------------------------+
| 1 |
+---------------------------+Wyniki tej symulacji są dość interesujące. Przyjrzyjmy się temu pojedynczo.
- Około 10:06:29 zacząłem uruchamiać zapytanie symulacyjne, jak wspomniano powyżej.
- Około 10:06:44 pokazuje, że punkt końcowy s9s-db-aurora.cluster-ro-cmu8qdlvkepg.us-east-2.rds.amazonaws.com z przypisaną nazwą hosta ip-10-20-1- 139, gdzie w rzeczywistości jest to instancja tylko do odczytu, stała się niedostępna, mimo to polecenie symulacji zostało uruchomione w instancji do odczytu i zapisu.
- Około 10:06:51 pokazuje, że punkt końcowy s9s-db-aurora.cluster-ro-cmu8qdlvkepg.us-east-2.rds.amazonaws.com z przypisaną nazwą hosta ip-10-20-1- 139 jest włączone, ale ma stan do odczytu i zapisu. Zwróć uwagę, że zmienna innodb_read_only, dla instancji zarządzanych przez Aurora MySQL, jest to jej identyfikator do określenia, czy host jest węzłem do odczytu i zapisu, czy tylko do odczytu, a Aurora działa również tylko na silniku pamięci InnoDB dla instancji zgodnych z MySQL.
- Około 10:07:13 kolejność uległa zmianie. Oznacza to, że przełączenie awaryjne zostało wykonane, a wystąpienia zostały przypisane do wyznaczonych punktów końcowych.
Sprawdź poniższy wynik, który jest wyświetlany w konsoli RDS:
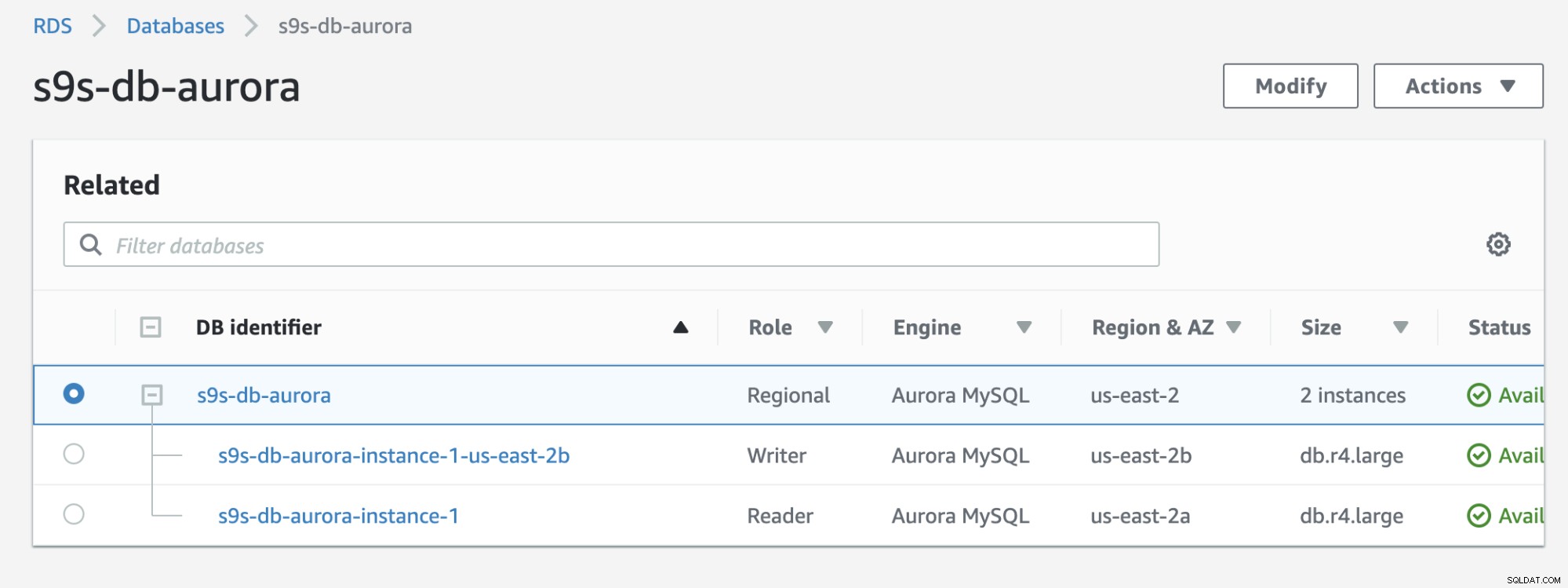
W porównaniu z wcześniejszym, s9s-db-aurora- instance-1 był czytelnikiem, ale po przełączeniu awaryjnym został awansowany na pisarza. Proces, w tym test, zajął około 44 sekund, aby ukończyć zadanie, ale pokaz przełączania awaryjnego zakończył się po prawie 30 sekundach. To imponujące i szybkie w przypadku przełączania awaryjnego, zwłaszcza biorąc pod uwagę, że jest to baza danych usług zarządzanych; co oznacza, że nie musisz się martwić o żadne problemy ze sprzętem lub konserwacją.
Wykonywanie powrotu po awarii w Amazon RDS
Powrót po awarii w Amazon RDS jest dość prosty. Zanim przejdziemy przez to, dodajmy nową replikę czytnika. Potrzebujemy opcji przetestowania i zidentyfikowania, z którego węzła AWS RDS wybrałby, gdy próbuje wrócić po awarii do żądanego mastera (lub powrotu po awarii do poprzedniego mastera) i sprawdzić, czy wybiera właściwy węzeł na podstawie priorytetu. Aktualna lista instancji od teraz i jej punkty końcowe są pokazane poniżej.
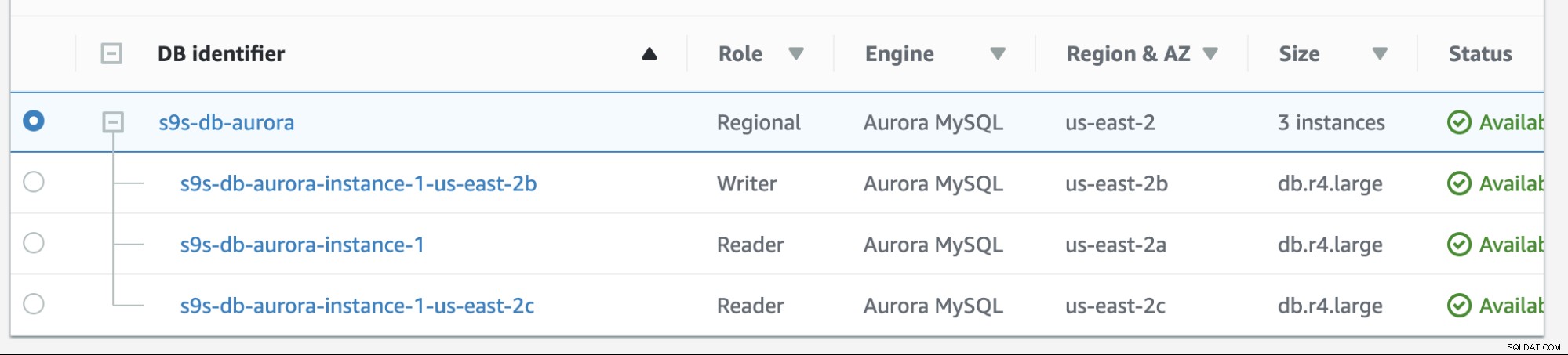

Nowa replika znajduje się na us-east-2c AZ z nazwą hosta db z IP-10-20-2-239.
Spróbujemy wykonać powrót po awarii, używając instancji s9s-db-aurora-instance-1 jako pożądanego celu powrotu po awarii. W tej konfiguracji mamy dwie instancje czytnika. Aby upewnić się, że podczas przełączania awaryjnego zostanie wybrany właściwy węzeł, musisz ustalić, czy priorytet lub dostępność są na szczycie (poziom-0> poziom-1> poziom-2 i tak dalej, aż do poziomu 15). Można to zrobić modyfikując instancję lub podczas tworzenia repliki.
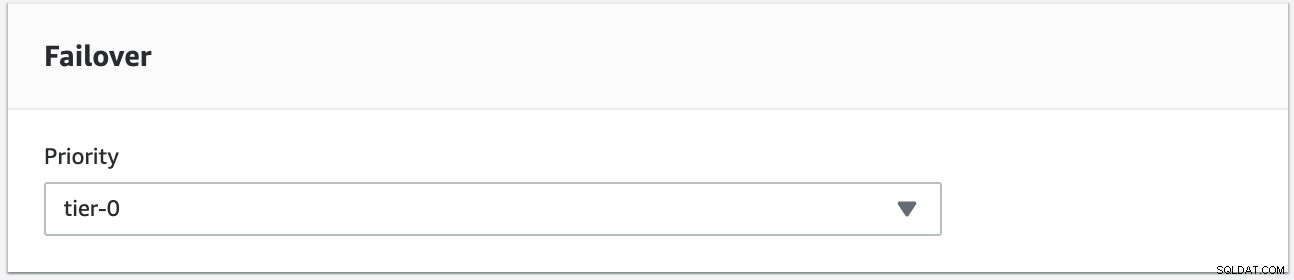
Możesz to zweryfikować w konsoli RDS.
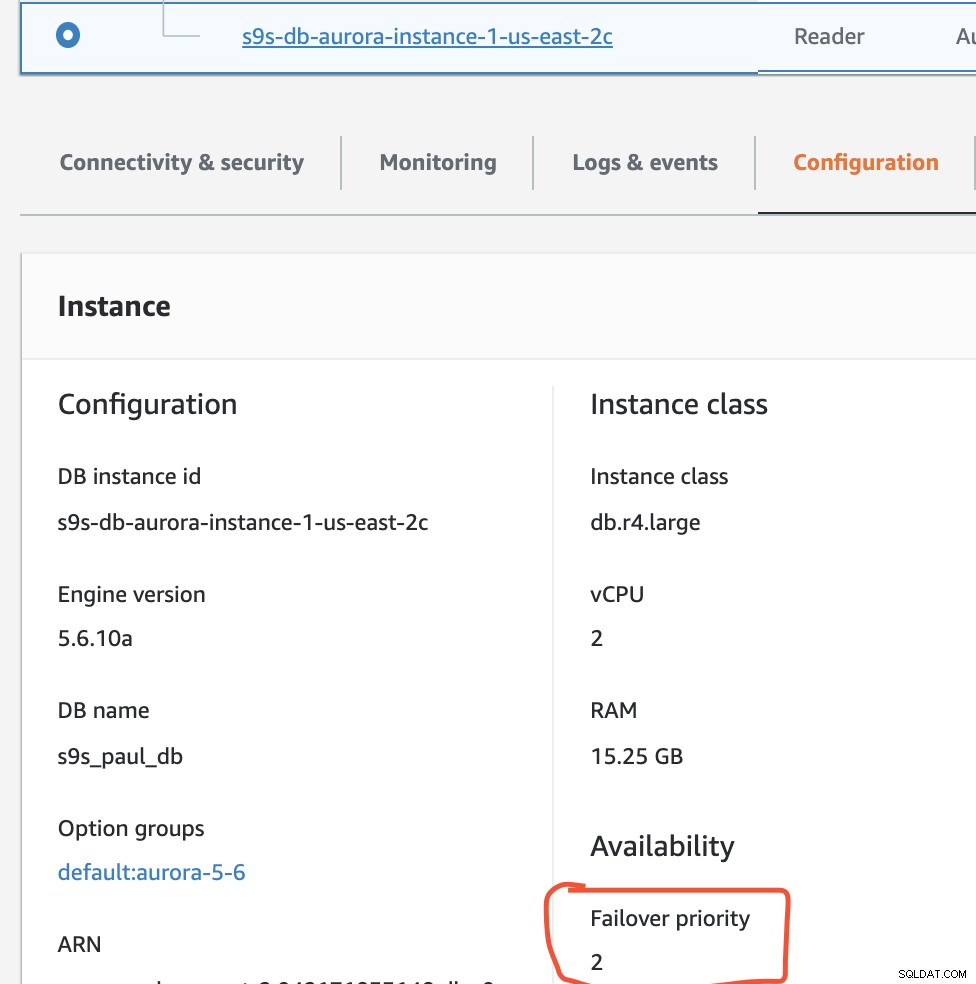
W tej konfiguracji s9s-db-aurora-instance-1 ma priorytet =0 (i jest repliką do odczytu), s9s-db-aurora-instance-1-us-east-2b ma priorytet =1 (i jest obecnym zapisem), a s9s-db-aurora-instance-1-us- east-2c ma priorytet =2 (i jest również repliką do odczytu). Zobaczmy, co się stanie, gdy spróbujemy wrócić po awarii.
Możesz monitorować stan za pomocą tego polecenia.
$ host=('s9s-db-aurora.cluster-cmu8qdlvkepg.us-east-2.rds.amazonaws.com' 's9s-db-aurora.cluster-ro-cmu8qdlvkepg.us-east-2.rds.amazonaws.com' 's9s-us-east-2c.cluster-custom-cmu8qdlvkepg.us-east-2.rds.amazonaws.com'); while true; do echo -e "\n==========================================="; date; echo -e "===========================================\n"; for h in "${host[@]}"; do mysql -h $h -e "select @@hostname; select @@global.innodb_read_only"; done; sleep 1; done;Po wyzwoleniu przełączenia awaryjnego nastąpi powrót do pożądanego celu, którym jest węzeł s9s-db-aurora-instance-1.
===========================================
Tue Sep 24 13:30:59 UTC 2019
===========================================
+----------------+
| @@hostname |
+----------------+
| ip-10-20-1-139 |
+----------------+
+---------------------------+
| @@global.innodb_read_only |
+---------------------------+
| 0 |
+---------------------------+
+---------------+
| @@hostname |
+---------------+
| ip-10-20-0-94 |
+---------------+
+---------------------------+
| @@global.innodb_read_only |
+---------------------------+
| 1 |
+---------------------------+
+----------------+
| @@hostname |
+----------------+
| ip-10-20-2-239 |
+----------------+
+---------------------------+
| @@global.innodb_read_only |
+---------------------------+
| 1 |
+---------------------------+
…
……
………
===========================================
Tue Sep 24 13:31:35 UTC 2019
===========================================
+----------------+
| @@hostname |
+----------------+
| ip-10-20-1-139 |
+----------------+
+---------------------------+
| @@global.innodb_read_only |
+---------------------------+
| 1 |
+---------------------------+
ERROR 2003 (HY000): Can't connect to MySQL server on 's9s-db-aurora.cluster-ro-cmu8qdlvkepg.us-east-2.rds.amazonaws.com' (111)
ERROR 2003 (HY000): Can't connect to MySQL server on 's9s-us-east-2c.cluster-custom-cmu8qdlvkepg.us-east-2.rds.amazonaws.com' (111)
….
…..
===========================================
Tue Sep 24 13:31:38 UTC 2019
===========================================
+---------------+
| @@hostname |
+---------------+
| ip-10-20-0-94 |
+---------------+
+---------------------------+
| @@global.innodb_read_only |
+---------------------------+
| 0 |
+---------------------------+
+----------------+
| @@hostname |
+----------------+
| ip-10-20-2-239 |
+----------------+
+---------------------------+
| @@global.innodb_read_only |
+---------------------------+
| 1 |
+---------------------------+
+----------------+
| @@hostname |
+----------------+
| ip-10-20-2-239 |
+----------------+
+---------------------------+
| @@global.innodb_read_only |
+---------------------------+
| 1 |
+---------------------------+Próba powrotu po awarii rozpoczęła się o 13:30:59 i zakończyła się około 13:31:38 (najbliżej 30 sekund). Kończy się to ~32 sekundy na tym teście, który wciąż jest szybki.
Wielokrotnie zweryfikowałem przełączanie awaryjne/powrót po awarii i konsekwentnie wymieniałem stan odczytu i zapisu między instancjami s9s-db-aurora-instance-1 i s9s-db-aurora-instance-1- us-wschód-2b. To pozostawia s9s-db-aurora-instance-1-us-east-2c niewybrane, chyba że oba węzły mają problemy (co jest bardzo rzadkie, ponieważ wszystkie znajdują się w różnych AZ).
Podczas prób przełączenia awaryjnego/powrotu poawaryjnego, RDS działa w szybkim tempie przejścia podczas przełączenia awaryjnego, około 15-25 sekund (co jest bardzo szybkie). Pamiętaj, że w tej instancji nie przechowujemy dużych plików danych, ale nadal jest to imponujące, biorąc pod uwagę, że nie ma już nic do zarządzania.
Wnioski
Uruchamianie Single-AZ wprowadza niebezpieczeństwo podczas przełączania awaryjnego. Amazon RDS umożliwia modyfikację i konwersję Twojego Single-AZ do konfiguracji obsługującej Multi-AZ, choć wiąże się to z pewnymi kosztami. Pojedyncze AZ może być w porządku, jeśli zgadzasz się z wyższym czasem RTO i RPO, ale zdecydowanie nie jest zalecane w przypadku aplikacji biznesowych o dużym natężeniu ruchu i o znaczeniu krytycznym.
Dzięki Multi-AZ możesz zautomatyzować przełączanie awaryjne i powrót po awarii w Amazon RDS, poświęcając swój czas na dostrajanie zapytań lub optymalizację. Łagodzi to wiele problemów, z jakimi borykają się DevOps lub administratorzy baz danych.
Chociaż Amazon RDS może powodować dylemat w niektórych organizacjach (ponieważ nie jest niezależny od platformy), nadal jest wart rozważenia; zwłaszcza jeśli Twoja aplikacja wymaga długoterminowego planu DR i nie chcesz tracić czasu na martwienie się o sprzęt i planowanie wydajności.