Obecnie istnieje wielu dostawców usług w chmurze. Mogą być małe lub duże, lokalne lub z centrami danych rozsianymi po całym świecie. Wielu z tych dostawców usług w chmurze oferuje pewnego rodzaju zarządzane rozwiązanie relacyjnej bazy danych. Obsługiwane bazy danych to MySQL lub PostgreSQL lub inny rodzaj relacyjnej bazy danych.
Podczas projektowania dowolnego rodzaju infrastruktury bazodanowej ważne jest, aby zrozumieć potrzeby biznesowe i zdecydować, jaki rodzaj dostępności trzeba osiągnąć.
W tym poście na blogu przyjrzymy się opcjom wysokiej dostępności rozwiązań opartych na MySQL od jednego z największych dostawców chmury — Google Cloud Platform.
Wdrażanie środowiska o wysokiej dostępności przy użyciu wystąpienia GCP SQL
Dla tego bloga chcemy mieć bardzo proste środowisko - jedna baza danych, może z jedną lub dwiema replikami. Chcemy mieć możliwość łatwego przełączania awaryjnego i przywracania operacji tak szybko, jak to możliwe, jeśli master ulegnie awarii. Użyjemy MySQL 5.7 jako wybranej wersji i zaczniemy od kreatora wdrażania instancji:
Następnie musimy utworzyć hasło roota, ustawić nazwę instancji i określ, gdzie ma się znajdować:
Następnie przyjrzymy się opcjom konfiguracji:
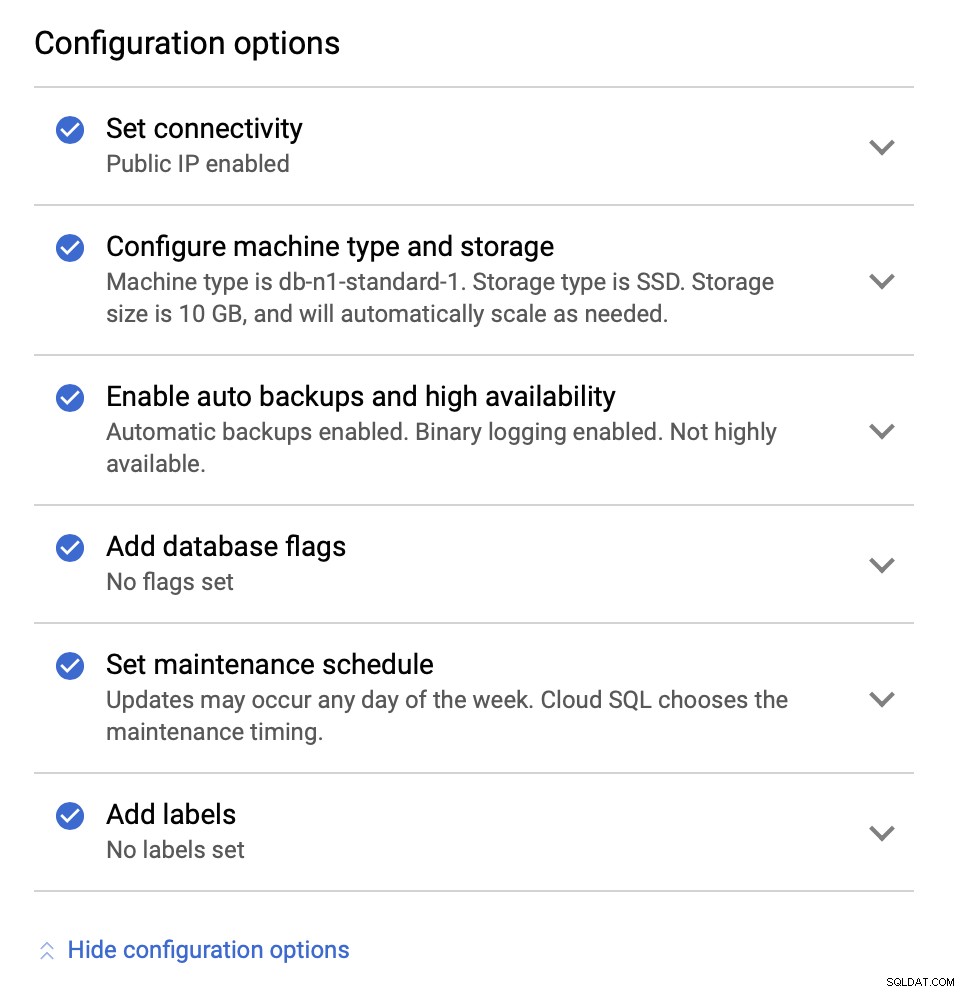
Możemy dokonać zmian w zakresie rozmiaru instancji (będziemy db-n1-standard-4), harmonogram przechowywania i konserwacji. Najważniejsze dla nas w tej konfiguracji są opcje wysokiej dostępności:
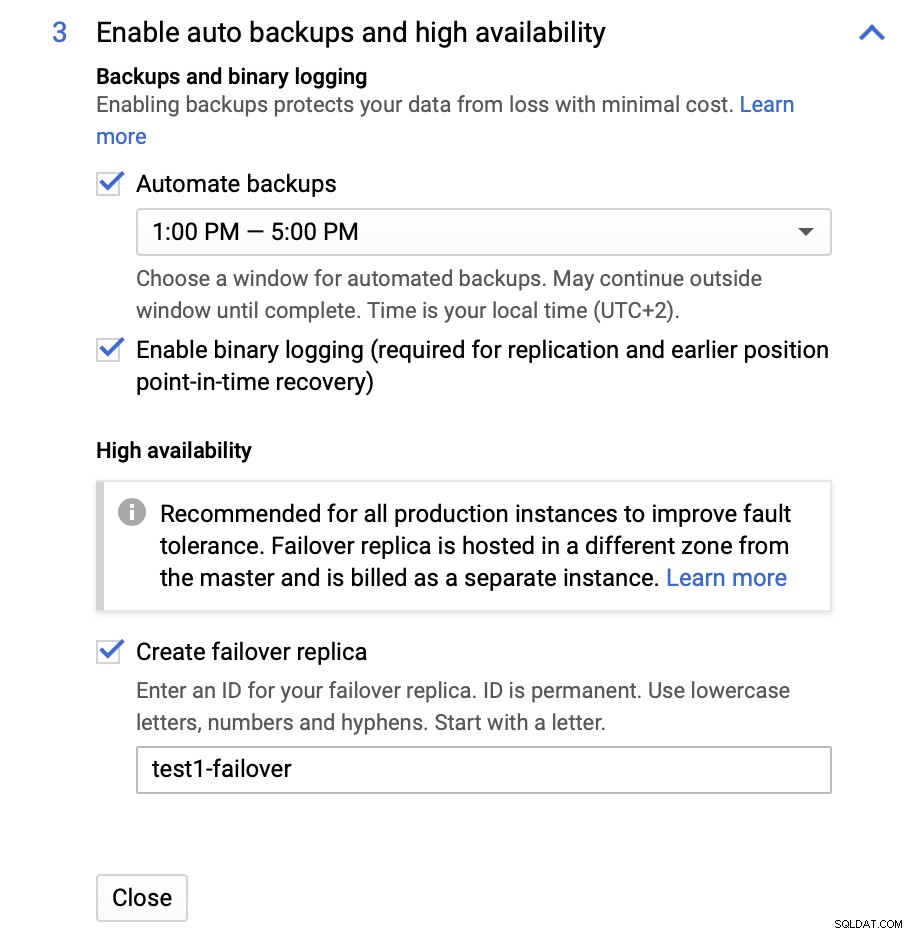
Tutaj możemy wybrać utworzenie repliki awaryjnej. Ta replika zostanie awansowana na mastera, jeśli oryginalny master zawiedzie.

Po wdrożeniu konfiguracji dodajmy urządzenie podrzędne replikacji:
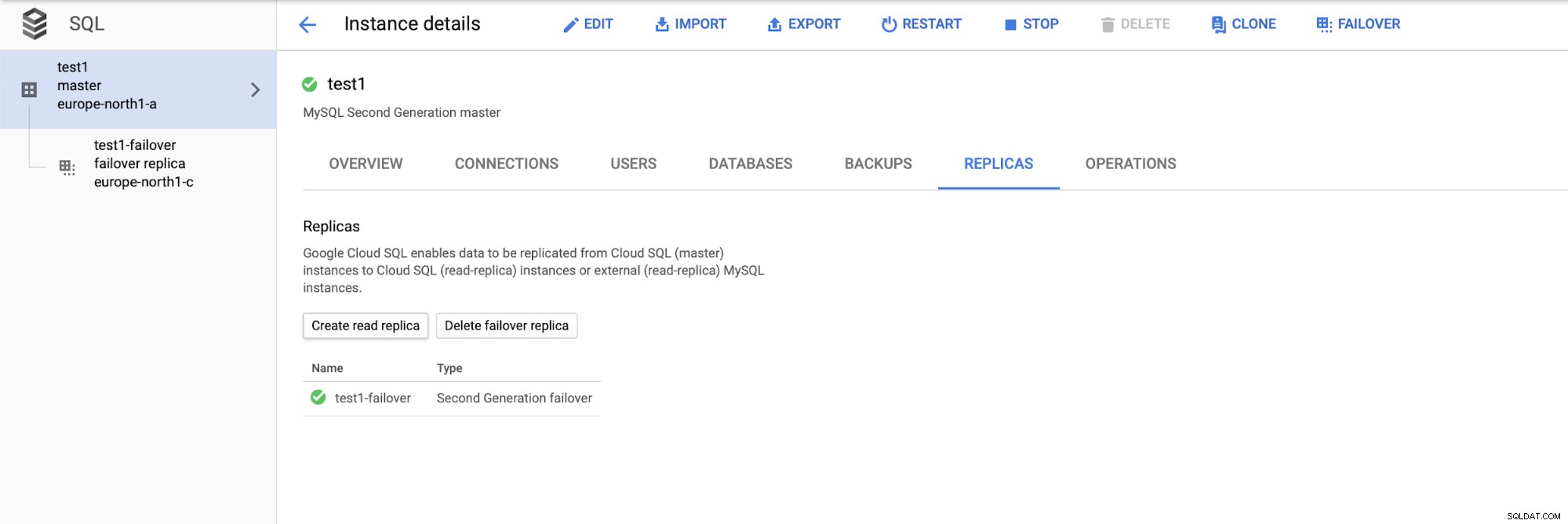
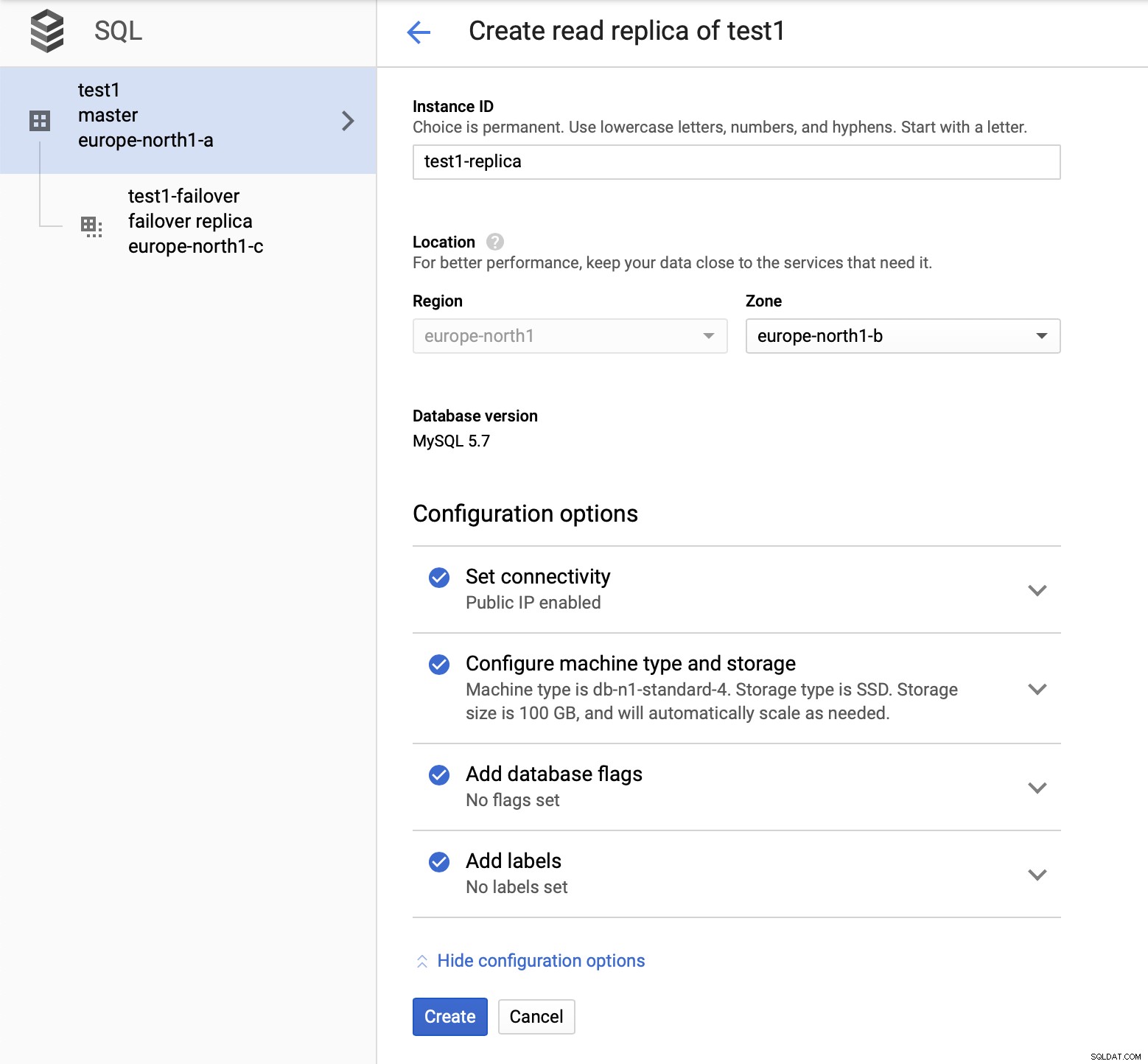
Po zakończeniu procesu dodawania repliki jesteśmy gotowi na testy. Zamierzamy uruchomić testowe obciążenie za pomocą Sysbench na naszej głównej, awaryjnej replice i odczytać replikę, aby zobaczyć, jak to zadziała. Uruchomimy trzy instancje Sysbench, używając punktów końcowych dla wszystkich trzech typów węzłów.
Następnie uruchomimy ręczne przełączanie awaryjne za pomocą interfejsu użytkownika:
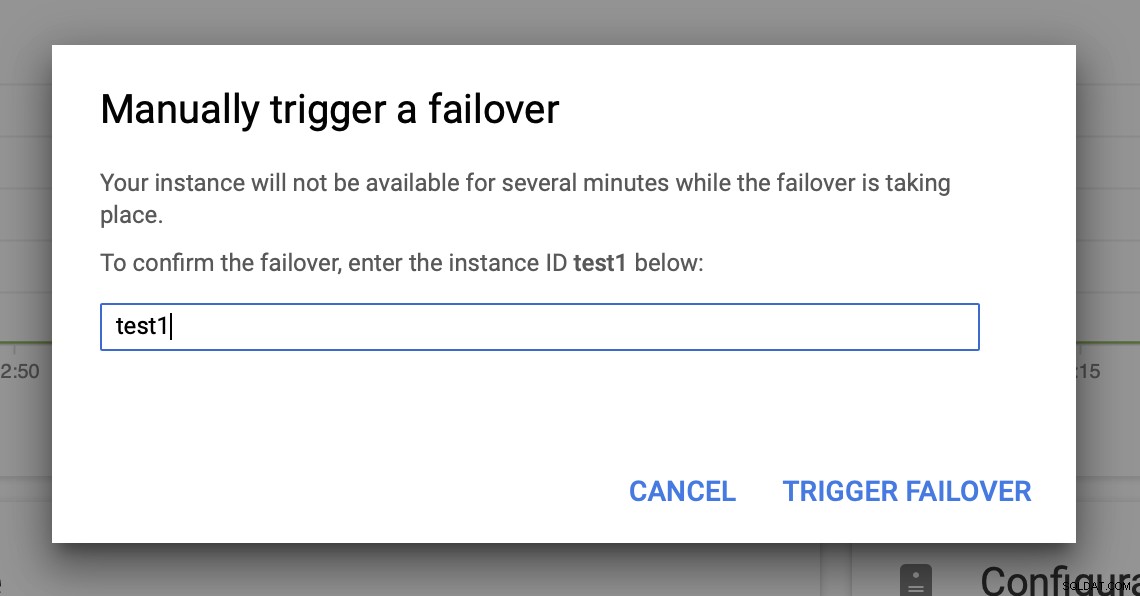
Testujesz MySQL Failover w Google Cloud Platform?
Dotarłem do tego punktu bez szczegółowej wiedzy na temat działania węzłów SQL w GCP. Miałem jednak pewne oczekiwania w oparciu o wcześniejsze doświadczenia z MySQL i to, co widziałem u innych dostawców chmury. Na początek przełączenie awaryjne do węzła awaryjnego powinno być bardzo szybkie. Chcielibyśmy, aby niewolników replikacji był dostępny, bez potrzeby przebudowy. Chcielibyśmy również zobaczyć, jak szybko możemy wykonać przełączanie awaryjne po raz drugi (ponieważ nie jest niczym niezwykłym, że problem rozprzestrzenia się z jednej bazy danych do drugiej).
Co ustaliliśmy podczas naszych testów...
- Podczas przełączania w tryb awaryjny, mistrz stał się ponownie dostępny po 75–80 sekundach.
- Replika awaryjna nie była dostępna przez 5-6 minut.
- Replika do odczytu była dostępna podczas procesu przełączania awaryjnego, ale stała się niedostępna przez 55-60 sekund po udostępnieniu repliki awaryjnej
Czego nie jesteśmy pewni...
Co się dzieje, gdy replika awaryjna jest niedostępna? Na podstawie czasu wygląda na to, że replika awaryjna jest odbudowywana. Ma to sens, ale wtedy czas odzyskiwania byłby silnie powiązany z rozmiarem instancji (zwłaszcza wydajnością we/wy) i rozmiarem pliku danych.
Co się dzieje z repliką do odczytu po odbudowaniu repliki awaryjnej? Pierwotnie odczytana replika była podłączona do mastera. Gdy master ulegnie awarii, spodziewalibyśmy się, że replika do odczytu zapewni przestarzały widok zestawu danych. Gdy pojawi się nowy master, powinien ponownie połączyć się przez replikację z instancją (która była repliką awaryjną i która została promowana do mastera). Nie ma potrzeby przestoju przez minutę podczas wykonywania ZMIANY MASTER.
Co ważniejsze, podczas procesu przełączania awaryjnego nie ma możliwości wykonania kolejnego przełączania awaryjnego (co ma sens):
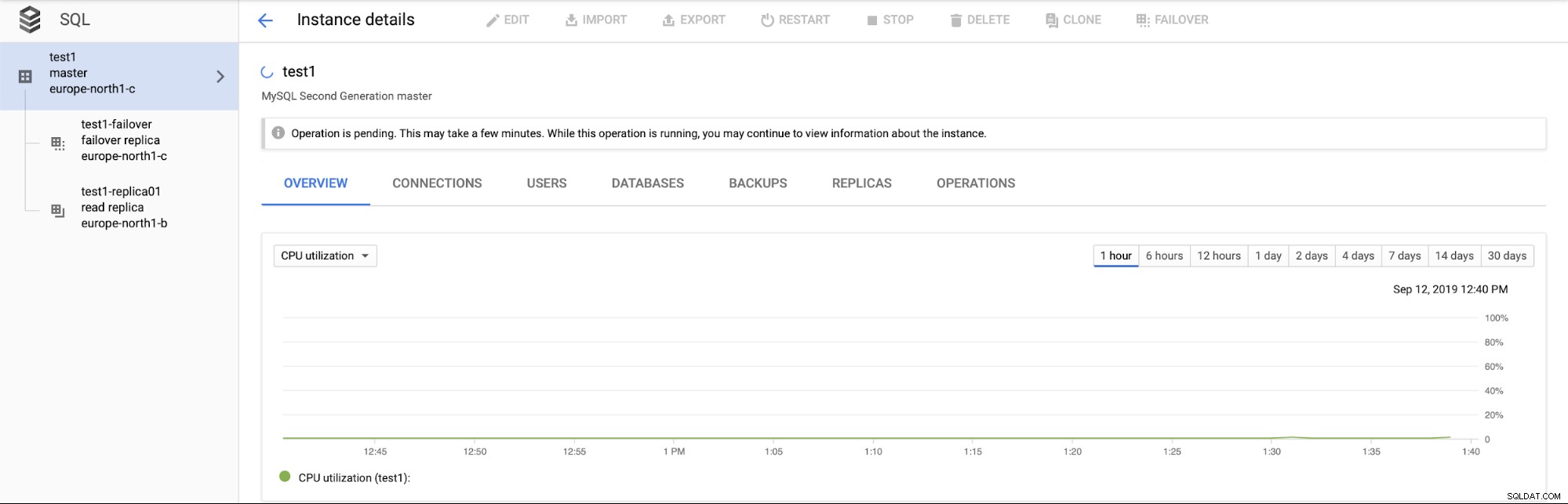
Nie można również promować repliki do odczytu (co niekoniecznie ma sens - spodziewamy się, że będziemy mogli promować repliki do odczytu w dowolnym momencie).

Należy pamiętać, że w celu zapewnienia wysokiej dostępności poleganie na replikach do odczytu (bez tworzenia repliki awaryjnej) nie jest dobrym rozwiązaniem. Replikę do odczytu można awansować na nadrzędną, jednak zostanie utworzony nowy klaster; odłączony od pozostałych węzłów.
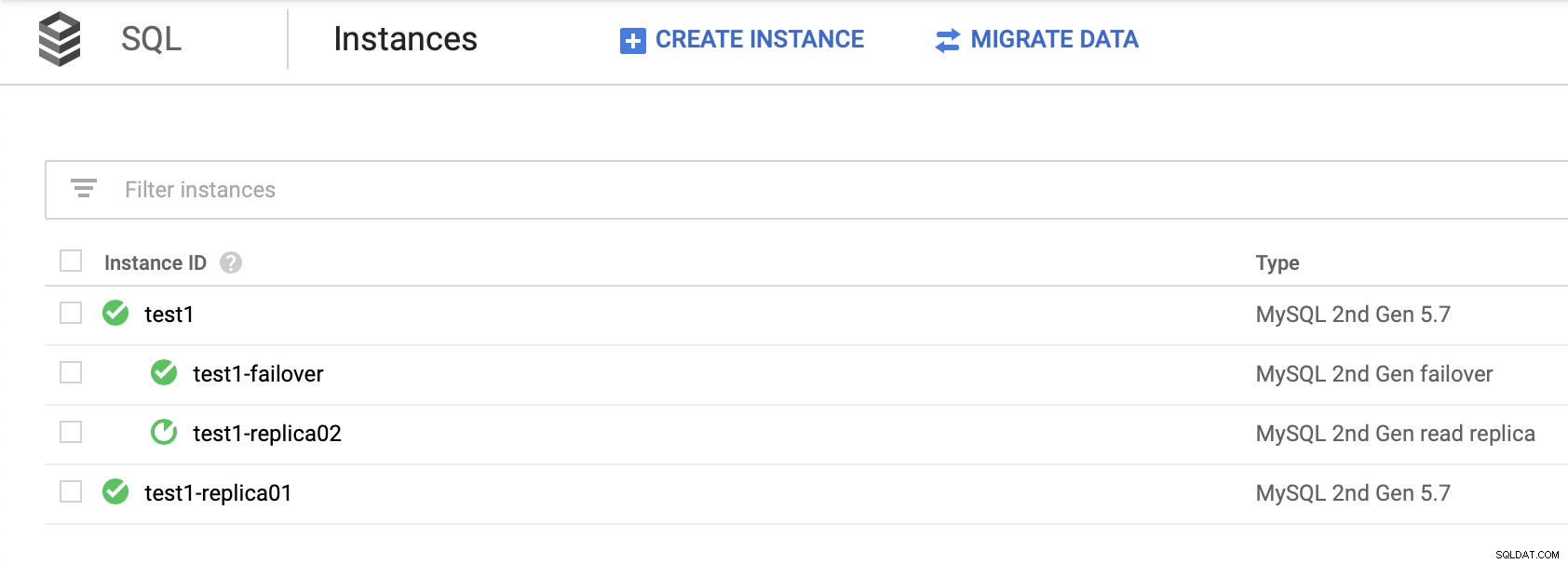
Nie ma możliwości podporządkowania innych replik nowego klastra. Jedynym sposobem, aby to zrobić, byłoby utworzenie nowych replik, ale jest to czasochłonny proces. Jest również praktycznie bezużyteczny, dzięki czemu replika awaryjna jest jedyną realną opcją wysokiej dostępności węzłów SQL w Google Cloud Platform.
Wnioski
Chociaż możliwe jest stworzenie wysoce dostępnego środowiska dla węzłów SQL w GCP, master nie będzie dostępny przez około półtorej minuty. Cały proces (w tym odbudowanie repliki awaryjnej i wykonanie niektórych czynności na replikach do odczytu) trwał kilka minut. W tym czasie nie byliśmy w stanie wywołać dodatkowego przełączania awaryjnego ani nie byliśmy w stanie promować repliki do odczytu.
Czy mamy tam jakichś użytkowników GCP? Jak osiągasz wysoką dostępność?