Zarządzanie wydajnością bazy danych to obszar, w którym firmy często poświęcają więcej czasu niż się spodziewali.
Monitorowanie i reagowanie na problemy z wydajnością produkcyjnej bazy danych jest jednym z najważniejszych zadań w ramach pracy administratora bazy danych. Jest to proces ciągły, wymagający stałej opieki. Aplikacje i podstawowe bazy danych zwykle ewoluują z czasem; rosną rozmiar, liczba użytkowników, obciążenie pracą, zmiany schematu, które pojawiają się wraz ze zmianami w kodzie.
Długotrwałe zapytania rzadko są nieuniknione w bazie danych MySQL. W niektórych okolicznościach długotrwałe zapytanie może być szkodliwym wydarzeniem. Jeśli zależy Ci na swojej bazie danych, optymalizacja wydajności zapytań i wykrywanie długotrwałych zapytań muszą być wykonywane regularnie.
W tym blogu przyjrzymy się dokładniej rzeczywistemu obciążeniu bazy danych, zwłaszcza po stronie uruchomionych zapytań. Sprawdzimy, jak śledzić zapytania, jakie informacje możemy znaleźć w metadanych MySQL, jakich narzędzi użyć do analizy takich zapytań.
Obsługa długotrwałych zapytań
Zacznijmy od sprawdzenia długo działających zapytań. Przede wszystkim musimy znać charakter zapytania, czy ma to być zapytanie długoterminowe, czy krótkotrwałe. Niektóre operacje analityczne i wsadowe mają być zapytaniami długotrwałymi, więc na razie możemy je pominąć. Ponadto, w zależności od rozmiaru tabeli, modyfikowanie struktury tabeli poleceniem ALTER może być długotrwałą operacją (szczególnie w klastrach MySQL Galera).
- Blokada tabeli — tabela jest zablokowana przez globalną lub jawną blokadę tabeli, gdy zapytanie próbuje uzyskać do niej dostęp.
- Nieefektywne zapytanie — używaj nieindeksowanych kolumn podczas wyszukiwania lub łączenia, w ten sposób MySQL potrzebuje więcej czasu na dopasowanie warunku.
- Zakleszczenie — zapytanie czeka na dostęp do tych samych wierszy, które są zablokowane przez inne żądanie.
- Zbiór danych nie mieści się w pamięci RAM - Jeśli dane zestawu roboczego mieszczą się w tej pamięci podręcznej, zapytania SELECT będą zwykle stosunkowo szybkie.
- Nieoptymalne zasoby sprzętowe — mogą to być powolne dyski, odbudowa RAID, przesycenie sieci itp.
Jeśli zauważysz, że wykonanie zapytania trwa dłużej niż zwykle, sprawdź je.
Korzystanie z listy procesów MySQL Show
MYSQL> SHOW PROCESSLIST;Jest to zwykle pierwsza czynność, którą uruchamiasz w przypadku problemów z wydajnością. SHOW PROCESSLIST to wewnętrzne polecenie mysql, które pokazuje, które wątki są uruchomione. Możesz również zobaczyć te informacje z tabeli information_schema.PROCESSLIST lub z polecenia mysqladmin process list. Jeśli masz uprawnienie PROCESS, możesz zobaczyć wszystkie wątki. Możesz zobaczyć informacje, takie jak identyfikator zapytania, czas wykonania, kto je uruchamia, host klienta itp. Informacje są nieco ostrożne w zależności od rodzaju i dystrybucji MySQL (Oracle, MariaDB, Percona)
SHOW PROCESSLIST;
+----+-----------------+-----------+------+---------+------+------------------------+------------------+----------+
| Id | User | Host | db | Command | Time | State | Info | Progress |
+----+-----------------+-----------+------+---------+------+------------------------+------------------+----------+
| 2 | event_scheduler | localhost | NULL | Daemon | 2693 | Waiting on empty queue | NULL | 0.000 |
| 4 | root | localhost | NULL | Query | 0 | Table lock | SHOW PROCESSLIST | 0.000 |
+----+-----------------+-----------+------+---------+------+------------------------+------------------+----------+możemy natychmiast zobaczyć obraźliwe zapytanie bezpośrednio z wyników. W powyższym przykładzie może to być blokada tabeli. Ale jak często przyglądamy się tym procesom? Jest to przydatne tylko wtedy, gdy wiesz o długotrwałej transakcji. W przeciwnym razie nie wiedziałbyś, dopóki coś się nie stanie — na przykład połączenia się nawarstwiają lub serwer działa wolniej niż zwykle.
Korzystanie z MySQL Pt-query-digest
Jeśli chcesz zobaczyć więcej informacji o konkretnym obciążeniu, użyj pt-query-digest. pt-query-digest to linuksowe narzędzie firmy Percona do analizy zapytań MySQL. Jest to część zestawu narzędzi Percona, który można znaleźć tutaj. Obsługuje najpopularniejsze 64-bitowe dystrybucje Linuksa, takie jak Debian, Ubuntu i Redhat.
Aby go zainstalować, musisz skonfigurować repozytoria Percona, a następnie zainstalować pakiet perona-toolkit.
Zainstaluj Percona Toolkit za pomocą menedżera pakietów:
Debian lub Ubuntu:
sudo apt-get install percona-toolkitRHEL lub CentOS:
sudo yum install percona-toolkitPt-query-digest akceptuje dane z listy procesów, logu ogólnego, logu binarnego, slow log lub tcpdump. Dodatkowo możliwe jest odpytywanie listy procesów MySQL w określonym przedziale czasu - proces które mogą być zasobożerne i dalekie od ideału, ale nadal mogą być używane jako alternatywa.
Najczęstszym źródłem pt-query-digest jest powolny dziennik zapytań. Możesz kontrolować, ile danych trafi tam za pomocą parametru log_slow_verbosity.
Istnieje wiele rzeczy, które mogą spowodować, że wykonanie zapytania zajmie więcej czasu:
- mikroczas — zapytania z dokładnością do mikrosekund.
- query_plan — informacje o planie wykonania zapytania.
- innodb – statystyki InnoDB.
- minimalne — równoważne włączeniu samego mikroczasu.
- standard — odpowiednik włączenia microtime,innodb.
- full — odpowiednik wszystkich innych wartości OR połączonych razem bez opcji profiling i profiling_use_getrusage.
- profilowanie - Włącza profilowanie wszystkich zapytań we wszystkich połączeniach.
- profiling_use_getrusage — Włącza korzystanie z funkcji getrusage.
źródło:dokumentacja Percony
W celu uzyskania kompletności użyj log_slow_verbosity=full, co jest powszechnym przypadkiem.
Dziennik powolnych zapytań
Dziennik powolnych zapytań może być używany do wyszukiwania zapytań, których wykonanie zajmuje dużo czasu i dlatego są kandydatami do optymalizacji. Dziennik powolnych zapytań przechwytuje powolne zapytania (wykonywanie instrukcji SQL trwających dłużej niż long_query_time sekund) lub zapytania, które nie używają indeksów do wyszukiwania (log_queries_not_using_indexes). Ta funkcja nie jest domyślnie włączona i aby ją włączyć, wystarczy ustawić następujące wiersze i ponownie uruchomić serwer MySQL:
[mysqld]
slow_query_log=1
log_queries_not_using_indexes=1
long_query_time=0.1Dziennik powolnych zapytań może być używany do wyszukiwania zapytań, których wykonanie zajmuje dużo czasu i dlatego są kandydatami do optymalizacji. Jednak badanie długiego, wolnego dziennika zapytań może być czasochłonnym zadaniem. Istnieją narzędzia do analizowania plików dziennika powolnych zapytań MySQL i podsumowywania ich zawartości, takie jak mysqldumpslow, pt-query-digest.
Schemat wydajności
Schemat wydajności to doskonałe narzędzie dostępne do monitorowania elementów wewnętrznych MySQL Server i szczegółów wykonania na niższym poziomie. Miał złą reputację we wczesnej wersji (5.6), ponieważ włączenie go często powodowało problemy z wydajnością, jednak najnowsze wersje nie szkodzą wydajności. Poniższe tabele w schemacie wydajności mogą służyć do wyszukiwania wolnych zapytań:
- events_statements_current
- events_statements_history
- events_statements_history_long
- events_statements_summary_by_digest
- events_statements_summary_by_user_by_event_name
- events_statements_summary_by_host_by_event_name
MySQL 5.7.7 i nowsze zawierają schemat sys, zestaw obiektów, który pomaga administratorom baz danych i programistom interpretować dane zebrane przez schemat wydajności w bardziej zrozumiałej formie. Obiekty schematu sys mogą być używane w typowych przypadkach dostrajania i diagnostyki.
Śledzenie sieci
Co zrobić, jeśli nie mamy dostępu do dziennika zapytań lub bezpośrednich dzienników aplikacji. W takim przypadku moglibyśmy użyć kombinacji tcpdump i pt-query digest, które mogłyby pomóc w przechwytywaniu zapytań.
$ tcpdump -s 65535 -x -nn -q -tttt -i any port 3306 > mysql.tcp.txtPo zakończeniu procesu przechwytywania możemy przystąpić do przetwarzania danych:
$ pt-query-digest --limit=100% --type tcpdump mysql.tcp.txt > ptqd_tcp.outMonitor zapytań ClusterControl
ClusterControl Query Monitor to moduł kontroli klastra, który dostarcza połączone informacje o aktywności bazy danych. Może zbierać informacje z wielu źródeł, takich jak pokazywanie listy procesów lub dziennika powolnych zapytań i prezentowanie ich w sposób wstępnie zagregowany.
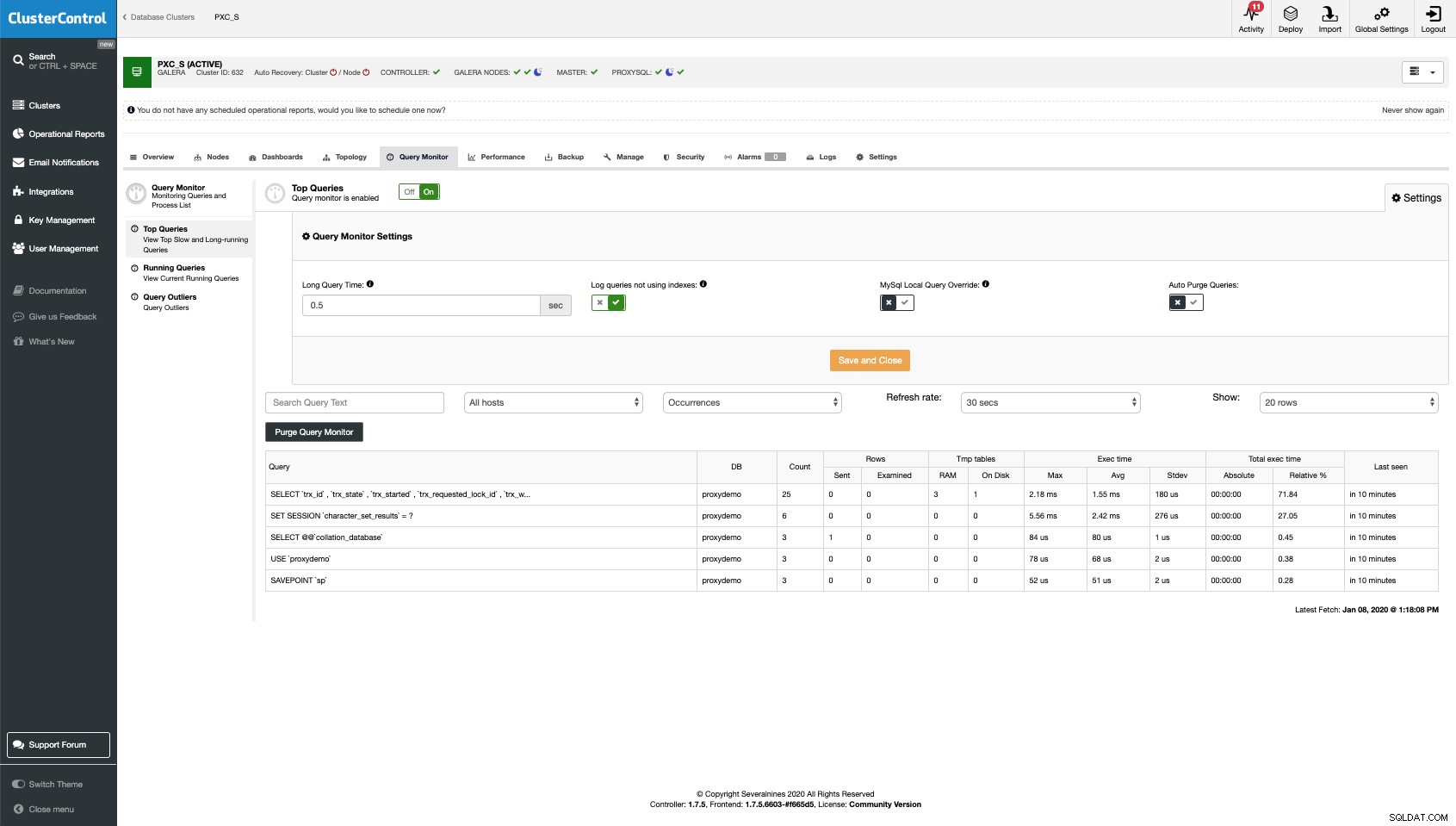
Monitorowanie SQL jest podzielone na trzy sekcje.
Najpopularniejsze zapytania
przedstawia informacje o zapytaniach, które zajmują znaczną część zasobów.
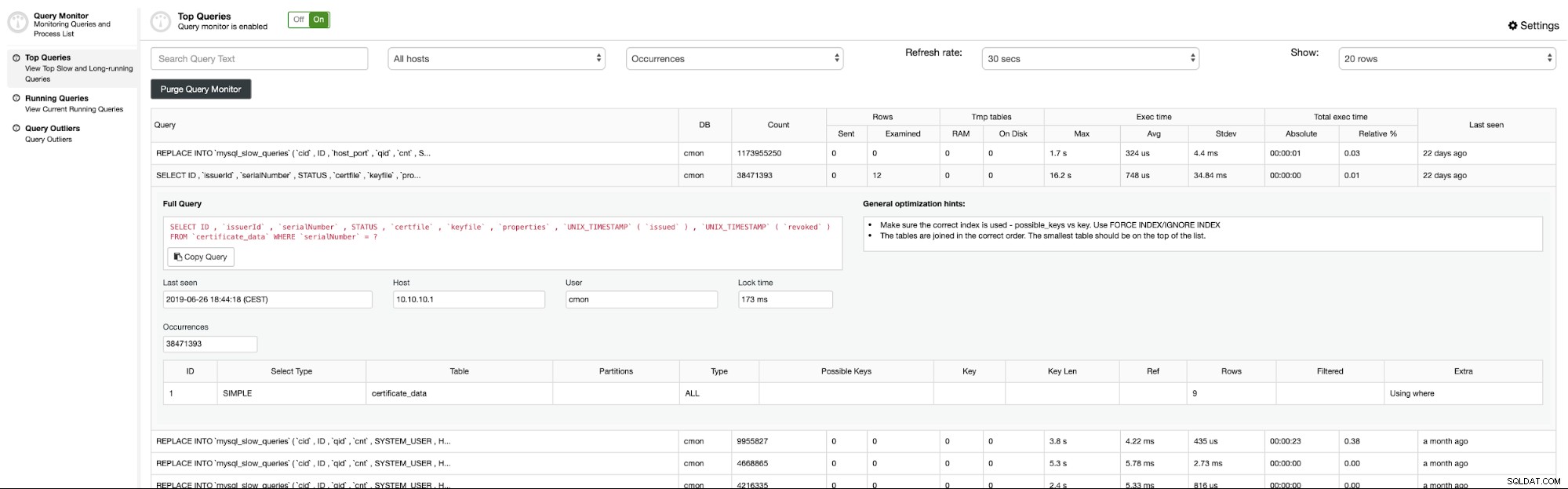
Wykonywanie zapytań
to lista procesów zawierająca informacje ze wszystkich węzłów klastra bazy danych w jednym widoku. Możesz tego użyć do zabijania zapytań, które wpływają na operacje bazy danych.
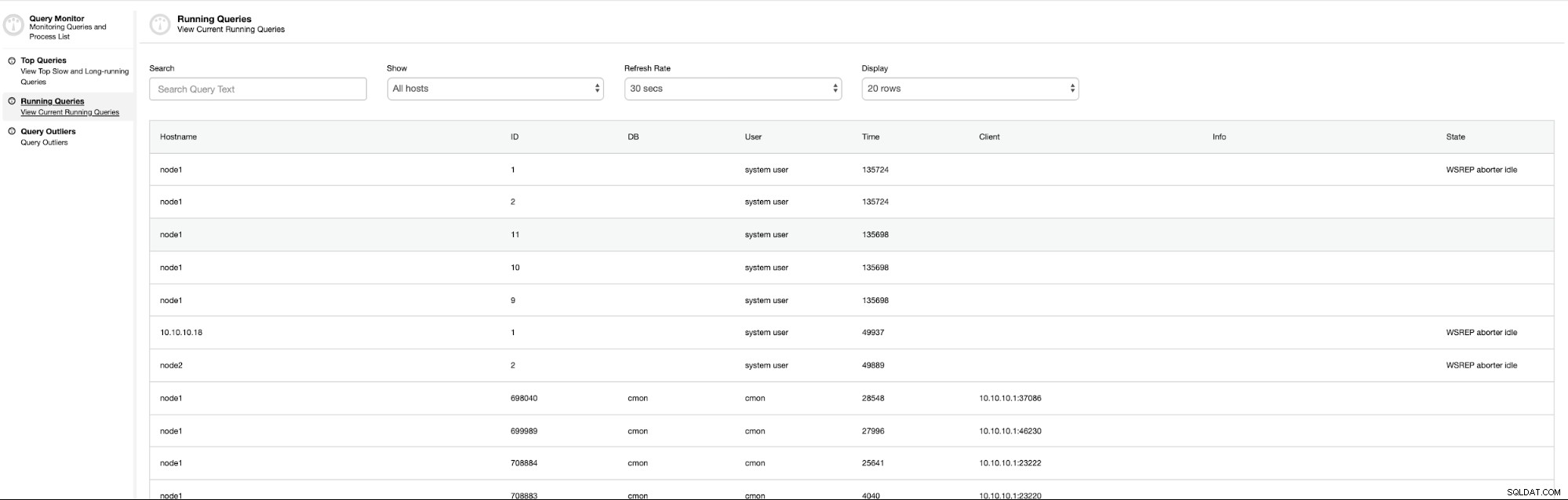
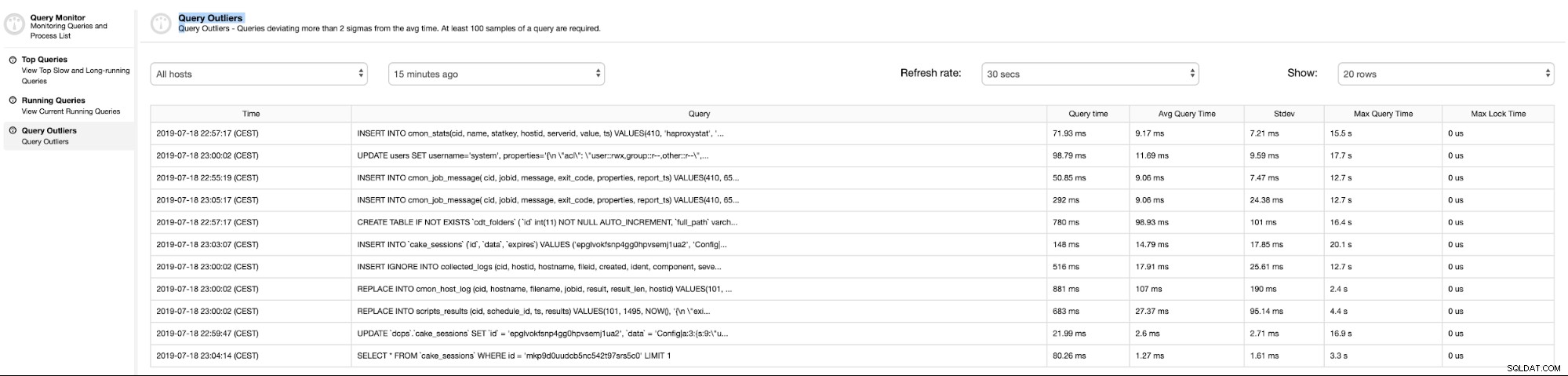
Wyjątki zapytań
przedstaw listę zapytań z czasem wykonania dłuższym niż przeciętny.
Wnioski
To wszystko dla części drugiej. Ten blog nie ma być wyczerpującym przewodnikiem po tym, jak zwiększyć wydajność bazy danych, ale miejmy nadzieję, że daje jaśniejszy obraz tego, co może stać się niezbędne, i niektóre podstawowe parametry, które można skonfigurować. Nie wahaj się dać nam znać, jeśli w komentarzach poniżej pominęliśmy jakieś ważne.