Jeśli byłeś w świecie kontenerów, wiedziałbyś, że zaadoptowanie pełnej automatyzacji Kubernetes dla klastrowego systemu baz danych, co często zwiększa poziom złożoności opartego na kontenerach architektura dla tych aplikacji stanowych. Właśnie tam Operator Kubernetes może nam pomóc w rozwiązaniu tego problemu. Operator Kubernetes to specjalny typ kontrolera wprowadzony w celu uproszczenia złożonych wdrożeń, który zasadniczo rozszerza Kubernetes API o niestandardowe zasoby. Opiera się na podstawowych koncepcjach zasobów i kontrolerów Kubernetes, ale zawiera wiedzę specyficzną dla domeny lub aplikacji, aby zautomatyzować cały cykl życia oprogramowania, którym zarządza.
Operator klastra Percona XtraDB to sprytny sposób na automatyzację określonych zadań klastra Percona XtraDB, takich jak wdrażanie, skalowanie, tworzenie kopii zapasowych i aktualizacje w ramach Kubernetes, zbudowanego i utrzymywanego przez firmę Percona. Wdraża klaster w StatefulSet z trwałym woluminem, co pozwala nam zachować spójną tożsamość dla każdego poda w klastrze i zachować nasze dane.
W tym poście na blogu zamierzamy przetestować wdrożenie Percona XtraDB Cluster 8.0 w środowisku kontenerowym, koordynowanym przez Percona XtraDB Cluster Kubernetes Operator na Google Cloud Platform.
Tworzenie klastra Kubernetes w Google Cloud
W tym przewodniku użyjemy klastra Kubernetes w Google Cloud, ponieważ uruchomienie Kubernetes jest stosunkowo proste i łatwe. Zaloguj się do panelu Google Cloud Platform -> Compute -> Kubernetes Engine -> Utwórz klaster, a zostanie wyświetlone następujące okno dialogowe:
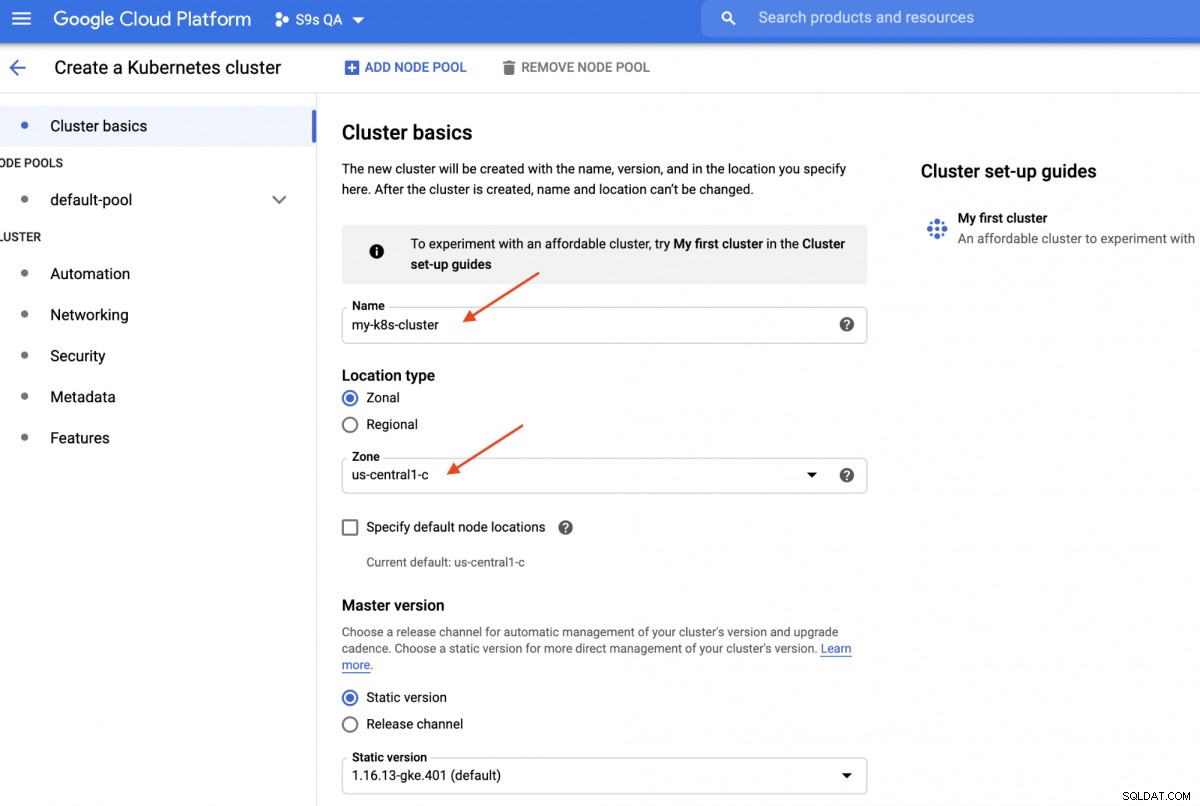
Wystarczy wpisać nazwę klastra Kubernetes, wybrać preferowaną strefę i kliknąć „UTWÓRZ " (na dole strony). Za 5 minut 3-węzłowy klaster Kubernetes będzie gotowy. Teraz na swojej stacji roboczej zainstaluj pakiet SDK gcloud, jak pokazano w tym przewodniku, a następnie przeciągnij konfigurację Kubernetes na swoją stację roboczą:
$ gcloud container clusters get-credentials my-k8s-cluster --zone asia-northeast1-a --project s9s-qa
Fetching cluster endpoint and auth data.
kubeconfig entry generated for my-k8s-cluster.W tym momencie powinno być możliwe połączenie z klastrem Kubernetes. Uruchom następujące polecenie, aby zweryfikować:
$ kubectl get nodes
NAME STATUS ROLES AGE VERSION
gke-my-k8s-cluster-default-pool-b80902cd-gp09 Ready <none> 139m v1.16.13-gke.401
gke-my-k8s-cluster-default-pool-b80902cd-jdc3 Ready <none> 139m v1.16.13-gke.401
gke-my-k8s-cluster-default-pool-b80902cd-rdv8 Ready <none> 139m v1.16.13-gke.401Powyższe dane wyjściowe oznaczają, że jesteśmy w stanie połączyć się z masterem Kubernetes i pobrać węzły klastra Kubernetes. Teraz jesteśmy gotowi do uruchomienia obciążeń Kubernetes.
Wdrażanie klastra Percona XtraDB na Kubernetes
W celu wdrożenia obciążenia będziemy postępować zgodnie z instrukcjami podanymi w dokumentacji operatora klastra Percona XtraDB. Zasadniczo uruchamiamy następujące polecenie na naszej stacji roboczej, aby utworzyć niestandardowe zasoby, przestrzeń nazw, kontrolę dostępu opartą na rolach, a także sam operator Kubernetes:
$ git clone -b v1.6.0 https://github.com/percona/percona-xtradb-cluster-operator
$ cd percona-xtradb-cluster-operator/
$ kubectl apply -f deploy/crd.yaml
$ kubectl create namespace pxc
$ kubectl config set-context $(kubectl config current-context) --namespace=pxc
$ kubectl create clusterrolebinding cluster-admin-binding --clusterrole=cluster-admin --user=$(gcloud config get-value core/account)
$ kubectl apply -f deploy/rbac.yaml
$ kubectl apply -f deploy/operator.yamlNastępnie musimy przygotować nasze hasła (nazywa się to Secrets w terminologii Kubernetes), aktualizując wartości wewnątrz deploy/secrets.yaml w formacie zakodowanym w base64. Możesz użyć narzędzi online, takich jak https://www.base64encode.org/, aby je utworzyć lub użyć narzędzia wiersza poleceń, takiego jak:
$ echo -n 'mypassword' | base64
bXlwYXNzd29yZA==Następnie zaktualizuj deploy/secrets.yaml, jak pokazano poniżej:
apiVersion: v1
kind: Secret
metadata:
name: my-cluster-secrets
type: Opaque
data:
root: bXlwYXNzd29yZA==
xtrabackup: bXlwYXNzd29yZA==
monitor: bXlwYXNzd29yZA==
clustercheck: bXlwYXNzd29yZA==
proxyadmin: bXlwYXNzd29yZA==
pmmserver: bXlwYXNzd29yZA==
operator: bXlwYXNzd29yZA==Powyższe jest super uproszczeniem zarządzania tajemnicami, w którym wszystkie hasła są takie same dla wszystkich użytkowników. W środowisku produkcyjnym należy używać bardziej złożonego hasła i określać inne hasło dla każdego użytkownika.
Teraz możemy przekazać tajną konfigurację do Kubernetes:
$ kubectl apply -f deploy/secrets.yamlZanim przejdziemy do wdrożenia klastra Percona XtraDB, musimy ponownie odwiedzić domyślną definicję wdrożenia w pliku deploy/cr.yaml dla klastra. Zdefiniowano tutaj wiele obiektów Kubernetes, ale większość z nich została zakomentowana. Dla naszego obciążenia pracą dokonalibyśmy modyfikacji jak poniżej:
$ cat deploy/cr.yaml
apiVersion: pxc.percona.com/v1-6-0
kind: PerconaXtraDBCluster
metadata:
name: cluster1
finalizers:
- delete-pxc-pods-in-order
spec:
crVersion: 1.6.0
secretsName: my-cluster-secrets
vaultSecretName: keyring-secret-vault
sslSecretName: my-cluster-ssl
sslInternalSecretName: my-cluster-ssl-internal
allowUnsafeConfigurations: false
updateStrategy: SmartUpdate
upgradeOptions:
versionServiceEndpoint: https://check.percona.com
apply: recommended
schedule: "0 4 * * *"
pxc:
size: 3
image: percona/percona-xtradb-cluster:8.0.20-11.1
configuration: |
[client]
default-character-set=utf8
[mysql]
default-character-set=utf8
[mysqld]
collation-server = utf8_unicode_ci
character-set-server = utf8
default_authentication_plugin = mysql_native_password
resources:
requests:
memory: 1G
affinity:
antiAffinityTopologyKey: "kubernetes.io/hostname"
podDisruptionBudget:
maxUnavailable: 1
volumeSpec:
persistentVolumeClaim:
resources:
requests:
storage: 6Gi
gracePeriod: 600
haproxy:
enabled: true
size: 3
image: percona/percona-xtradb-cluster-operator:1.6.0-haproxy
resources:
requests:
memory: 1G
affinity:
antiAffinityTopologyKey: "kubernetes.io/hostname"
podDisruptionBudget:
maxUnavailable: 1
gracePeriod: 30
backup:
image: percona/percona-xtradb-cluster-operator:1.6.0-pxc8.0-backup
storages:
fs-pvc:
type: filesystem
volume:
persistentVolumeClaim:
accessModes: [ "ReadWriteOnce" ]
resources:
requests:
storage: 6Gi
schedule:
- name: "daily-backup"
schedule: "0 0 * * *"
keep: 5
storageName: fs-pvcWprowadziliśmy pewne modyfikacje w dostarczonym pliku cr.yaml, aby działał on z naszą aplikacją, jak pokazano powyżej. Przede wszystkim musimy zakomentować (lub usunąć) wszystkie linie związane z procesorem, na przykład [*].resources.requests.cpu:600m, aby upewnić się, że Kubernetes jest w stanie poprawnie zaplanować tworzenie pod na węzłach z ograniczonym procesorem. Następnie musimy dodać kilka opcji zgodności dla Percona XtraDB Cluster 8.0, który jest oparty na MySQL 8.0, aby bezproblemowo współpracować z naszą aplikacją WordPress, którą zamierzamy wdrożyć później, jak pokazano w następującym fragmencie:
Konfiguracja configuration: |
[client]
default-character-set=utf8
[mysql]
default-character-set=utf8
[mysqld]
collation-server = utf8_unicode_ci
character-set-server = utf8
default_authentication_plugin = mysql_native_passwordPowyższe dopasuje domyślny zestaw znaków serwera MySQL do sterownika MySQLi PHP w naszym kontenerze WordPress. Następna sekcja to wdrożenie HAProxy, w którym jest ustawione na „enabled:true”. Istnieje również sekcja ProxySQL z "enabled:false" - zwykle wybiera się jeden z odwróconych serwerów proxy dla każdego klastra. Ostatnia sekcja to konfiguracja kopii zapasowej, w której chcielibyśmy mieć zaplanowaną codzienną kopię zapasową codziennie o godzinie 12:00 i zachować 5 ostatnich kopii zapasowych.
Możemy teraz rozpocząć wdrażanie naszego 3-węzłowego klastra Percona XtraDB:
$ kubectl apply -f deploy/cr.yamlProces tworzenia zajmie trochę czasu. Operator wdroży pody Percona XtraDB Cluster jako Stateful Set, co oznacza utworzenie jednego poda na raz, a każdemu podowi w StatefulSet zostanie przypisana liczba całkowita, od 0 do N-1, która jest unikalna w całym zestawie. Proces kończy się, gdy zarówno operator, jak i kapsuły osiągną stan uruchomiony:
$ kubectl get pods
NAME READY STATUS RESTARTS AGE
cluster1-haproxy-0 2/2 Running 0 71m
cluster1-haproxy-1 2/2 Running 0 70m
cluster1-haproxy-2 2/2 Running 0 70m
cluster1-pxc-0 1/1 Running 0 71m
cluster1-pxc-1 1/1 Running 0 70m
cluster1-pxc-2 1/1 Running 0 69m
percona-xtradb-cluster-operator-79d786dcfb-6clld 1/1 Running 0 121mPonieważ ten operator jest zasobem niestandardowym, możemy manipulować zasobem perconaxtradbcluster tak, aby przypominał standardowy zasób Kubernetes:
$ kubectl get perconaxtradbcluster
NAME ENDPOINT STATUS PXC PROXYSQL HAPROXY AGE
cluster1 cluster1-haproxy.pxc ready 3 3 27hMożesz także użyć krótszej nazwy zasobu „pxc” i spróbować za pomocą następujących poleceń:
$ kubectl describe pxc
$ kubectl edit pxcPrzyglądając się zestawowi obciążenia, możemy stwierdzić, że operator utworzył dwa zestawy StatefulSets:
$ kubectl get statefulsets -o wide
NAME READY AGE CONTAINERS IMAGES
cluster1-haproxy 3/3 26h haproxy,pxc-monit percona/percona-xtradb-cluster-operator:1.6.0-haproxy,percona/percona-xtradb-cluster-operator:1.6.0-haproxy
cluster1-pxc 3/3 26h pxc percona/percona-xtradb-cluster:8.0.20-11.2Operator utworzy również odpowiednie usługi, które będą równoważyć obciążenia do odpowiednich podów:
$ kubectl get service
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
cluster1-haproxy ClusterIP 10.40.9.177 <none> 3306/TCP,3309/TCP,33062/TCP 3h27m
cluster1-haproxy-replicas ClusterIP 10.40.0.236 <none> 3306/TCP 3h27m
cluster1-pxc ClusterIP None <none> 3306/TCP,33062/TCP 3h27m
cluster1-pxc-unready ClusterIP None <none> 3306/TCP,33062/TCP 3h27mPowyższe dane wyjściowe pokazują, że operator utworzył 4 usługi:
- klaster1-haproxy - Usługa dla pojedynczego mastera MySQL z równoważeniem obciążenia (3306), protokołu Proxy (3309) i MySQL Admin (33062) - Nowy port administracyjny wprowadzony w MySQL 8.0.14 i nowszych. Jest to nazwa usługi lub adres IP klastra, z którym aplikacje muszą się łączyć, aby uzyskać połączenie typu single-master z klastrem Galera.
- repliki klastra1-haproxy - Usługa dla multi-mastera MySQL ze zrównoważonym obciążeniem (3306). Jest to nazwa usługi lub adres IP klastra, z którym aplikacje muszą się łączyć, aby uzyskać połączenie z wieloma wzorcami do klastra Galera z algorytmem równoważenia okrężnego.
- cluster1-pxc - Usługa dla podów PXC ze zrównoważonym obciążeniem, z pominięciem HAProxy. Łącząc się bezpośrednio z tą usługą, Kubernetes skieruje połączenie w sposób okrężny do wszystkich podów PXC, podobnie do tego, co zapewnia replikacja klastra-haproxy. Usługa nie ma przypisanego publicznego adresu IP i jest niedostępna poza klastrem.
- klaster1-pxc-niegotowy - Usługa „niegotowy” jest potrzebna do wykrywania adresów podów podczas uruchamiania aplikacji, niezależnie od stanu podów. Pody Proxysql i pxc powinny wiedzieć o sobie, zanim baza danych stanie się w pełni operacyjna. Niegotowa usługa nie ma przypisanego publicznego adresu IP i jest niedostępna poza klastrem.
Aby połączyć się przez klienta MySQL, po prostu uruchom następujące polecenie:
$ kubectl run -i --rm --tty percona-client --image=percona:8.0 --restart=Never -- bash -ilSpowoduje to utworzenie przejściowego poda i natychmiastowe przejście do środowiska kontenera. Następnie uruchom standardowe polecenie klienta mysql z odpowiednimi danymi uwierzytelniającymi:
bash-4.2$ mysql -uroot -pmypassword -h cluster1-haproxy -P3306 -e 'SELECT @@hostname'
mysql: [Warning] Using a password on the command line interface can be insecure.
+----------------+
| @@hostname |
+----------------+
| cluster1-pxc-0 |
+----------------+Gdy przyjrzymy się rozmieszczeniu podów, wszystkie pody Percona XtraDB Cluster znajdują się na innym hoście Kubernetes:
$ kubectl get pods -o wide --selector=app.kubernetes.io/component=pxc
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
cluster1-pxc-0 1/1 Running 0 67m 10.36.2.5 gke-my-k8s-cluster-default-pool-b80902cd-gp09 <none> <none>
cluster1-pxc-1 1/1 Running 0 66m 10.36.1.10 gke-my-k8s-cluster-default-pool-b80902cd-rdv8 <none> <none>
cluster1-pxc-2 1/1 Running 0 65m 10.36.0.11 gke-my-k8s-cluster-default-pool-b80902cd-jdc3 <none> <none>Zdecydowanie poprawi to dostępność usługi na wypadek awarii jednego z hostów Kubernetes.
Aby skalować do 5 podów, musimy wcześniej przygotować kolejne 2 nowe węzły Kubernetes, aby przestrzegać konfiguracji koligacji pod (domyślnie affinity.antiAffinityTopologyKey.topologyKey="kubernetes.io/hostname"). Następnie uruchom następujące polecenie poprawki, aby przeskalować klaster Percona XtraDB do 5 węzłów:
$ kubectl patch pxc cluster1 \
--type='json' -p='[{"op": "replace", "path": "/spec/pxc/size", "value": 5 }]'Monitoruj tworzenie poda za pomocą polecenia kubectl get pods:
$ kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
cluster1-pxc-0 1/1 Running 0 27h 10.36.2.5 gke-my-k8s-cluster-default-pool-b80902cd-gp09 <none> <none>
cluster1-pxc-1 1/1 Running 0 27h 10.36.1.10 gke-my-k8s-cluster-default-pool-b80902cd-rdv8 <none> <none>
cluster1-pxc-2 1/1 Running 0 27h 10.36.0.11 gke-my-k8s-cluster-default-pool-b80902cd-jdc3 <none> <none>
cluster1-pxc-3 1/1 Running 0 30m 10.36.7.2 gke-my-k8s-cluster-pool-1-ab14a45e-h1pf <none> <none>
cluster1-pxc-4 1/1 Running 0 13m 10.36.5.3 gke-my-k8s-cluster-pool-1-ab14a45e-01qn <none> <none>Kolejne 2 nowe pody (cluster1-pxc-3 i cluster1-pxc-4) zostały utworzone na kolejnych 2 nowych węzłach Kubernetes (gke-my-k8s-cluster-pool-1-ab14a45e-h1pf i gke-my-k8s-cluster-pool-1-ab14a45e-01qn). Aby zmniejszyć skalę, po prostu zmień wartość z powrotem na 3 w powyższym poleceniu poprawki. Zwróć uwagę, że klaster Percona XtraDB powinien działać z nieparzystą liczbą węzłów, aby zapobiec rozszczepieniu mózgu.
Wdrażanie aplikacji (WordPress)
W tym przykładzie zamierzamy wdrożyć aplikację WordPress na naszym klastrze Percona XtraDB i HAProxy. Najpierw przygotujmy plik definicji YAML w następujący sposób:
$ cat wordpress-deployment.yaml
apiVersion: v1
kind: Service
metadata:
name: wordpress
labels:
app: wordpress
spec:
ports:
- port: 80
selector:
app: wordpress
tier: frontend
type: LoadBalancer
---
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: wp-pv-claim
labels:
app: wordpress
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 2Gi
---
apiVersion: apps/v1 # for versions before 1.9.0 use apps/v1beta2
kind: Deployment
metadata:
name: wordpress
labels:
app: wordpress
spec:
selector:
matchLabels:
app: wordpress
tier: frontend
strategy:
type: Recreate
template:
metadata:
labels:
app: wordpress
tier: frontend
spec:
containers:
- image: wordpress:4.8-apache
name: wordpress
env:
- name: WORDPRESS_DB_HOST
value: cluster1-haproxy
- name: WORDPRESS_DB_PASSWORD
valueFrom:
secretKeyRef:
name: my-cluster-secrets
key: root
ports:
- containerPort: 80
name: wordpress
volumeMounts:
- name: wordpress-persistent-storage
mountPath: /var/www/html
volumes:
- name: wordpress-persistent-storage
persistentVolumeClaim:
claimName: wp-pv-claimZwróć uwagę na zmienne środowiskowe WORDPRESS_DB_HOST i WORDPRESS_DB_PASSWORD. Pierwsza zmienna, w której zdefiniowaliśmy „cluster1-haproxy” jako host bazy danych, zamiast pojedynczego węzła bazy danych, a dla drugiej określiliśmy hasło roota, nakazując Kubernetesowi odczytanie go z obiektu my-cluster-secrets pod kluczem „root”, co jest równoważne "mypassword" (po zdekodowaniu wartości base64). Pomijamy definiowanie zmiennej środowiskowej WORDPRESS_DB_USER, ponieważ domyślną wartością jest „root”.
Teraz możemy stworzyć naszą aplikację:
$ kubectl apply -f wordpress-deployment.yamlSprawdź usługę:
$ kubectl get service
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
cluster1-haproxy ClusterIP 10.40.9.177 <none> 3306/TCP,3309/TCP,33062/TCP 4h42m
cluster1-haproxy-replicas ClusterIP 10.40.0.236 <none> 3306/TCP 4h42m
cluster1-pxc ClusterIP None <none> 3306/TCP,33062/TCP 4h42m
cluster1-pxc-unready ClusterIP None <none> 3306/TCP,33062/TCP 4h42m
wordpress LoadBalancer 10.40.13.205 35.200.78.195 80:32087/TCP 4h39mW tym momencie możemy połączyć się z naszą aplikacją WordPress pod adresem https://35.200.78.195/ (zewnętrzny adres IP) i rozpocząć konfigurację aplikacji WordPress. W tym momencie nasza aplikacja WordPress jest połączona z jednym z klastrów Percona XtraDB (połączenie jednokierunkowe) za pośrednictwem jednego z modułów HAProxy.
To na razie tyle. Aby uzyskać więcej informacji, zapoznaj się z dokumentacją Percona Kubernetes Operator for Percona XtraDB Cluster. Miłego kontenerowania!