Krótko wspomniałem, że dane w trybie wsadowym są znormalizowane w moim ostatnim artykule Bitmapy trybu wsadowego w SQL Server. Wszystkie dane w partii są reprezentowane przez ośmiobajtową wartość w tym konkretnym znormalizowanym formacie, niezależnie od bazowego typu danych.
To stwierdzenie bez wątpienia rodzi pewne pytania, nie tylko o to, jak dane o długości znacznie większej niż osiem bajtów mogą być w ten sposób przechowywane. W tym artykule omówiono znormalizowaną reprezentację danych wsadowych, wyjaśniono, dlaczego nie wszystkie ośmiobajtowe typy danych mogą zmieścić się w 64 bitach, i pokazano przykład, jak to wszystko wpływa na wydajność w trybie wsadowym.
Demo
Zacznę od przykładu, który pokazuje format danych wsadowych, który ma istotny wpływ na plan wykonania. Będziesz potrzebować SQL Server 2016 (lub nowszy) i Developer Edition (lub odpowiednik), aby odtworzyć pokazane tutaj wyniki.
Pierwszą rzeczą, której będziemy potrzebować, jest tabela bigint numery od 1 do 102 400 włącznie. Liczby te zostaną wkrótce użyte do zapełnienia tabeli magazynu kolumn (liczba wierszy to minimum potrzebne do uzyskania pojedynczego skompresowanego segmentu).
DROP TABLE IF EXISTS #Numbers;
GO
CREATE TABLE #Numbers (n bigint NOT NULL PRIMARY KEY);
GO
INSERT #Numbers (n)
SELECT
n = ROW_NUMBER() OVER (ORDER BY @@SPID)
FROM master.dbo.spt_values AS SV1
CROSS JOIN master.dbo.spt_values AS SV2
ORDER BY
n
OFFSET 0 ROWS
FETCH FIRST 102400 ROWS ONLY
OPTION (MAXDOP 1); Pomyślne zagregowane pushdown
Poniższy skrypt używa tabeli liczb do utworzenia kolejnej tabeli zawierającej te same liczby przesunięte o określoną wartość. Ta tabela wykorzystuje magazyn kolumn jako swoją główną pamięć masową w celu późniejszego wykonania w trybie wsadowym.
DROP TABLE IF EXISTS #T;
GO
CREATE TABLE #T (c1 bigint NOT NULL);
GO
DECLARE
@Start bigint = CONVERT(bigint, -4611686018427387905);
INSERT #T (c1)
SELECT
c1 = @Start + N.n
FROM #Numbers AS N;
GO
CREATE CLUSTERED COLUMNSTORE INDEX c ON #T
WITH (MAXDOP = 1); Uruchom następujące zapytania testowe w nowej tabeli magazynu kolumn:
SELECT
c = COUNT_BIG(*)
FROM #T AS T
WHERE 1 = (SELECT 1) -- Avoid trivial plan
OPTION (MAXDOP 1);
SELECT
m = MAX(T.c1)
FROM #T AS T
WHERE 1 = (SELECT 1) -- Avoid trivial plan
OPTION (MAXDOP 1);
SELECT
s = SUM(T.c1 + CONVERT(bigint, 4611686018427387904))
FROM #T AS T
WHERE 1 = (SELECT 1) -- Avoid trivial plan
OPTION (MAXDOP 1);
Dodatek wewnątrz SUM jest uniknięcie przepełnienia. Możesz pominąć WHERE klauzule (aby uniknąć trywialnego planu), jeśli używasz SQL Server 2017.
Wszystkie te zapytania korzystają z agregacji pushdown. Suma jest obliczana w Skanowaniu indeksu kolumn zamiast trybu wsadowego Hash Aggregate operator. Plany powykonawcze pokazują zero wierszy emitowanych przez skanowanie. Wszystkie 102 400 wierszy zostało „zagregowanych lokalnie”.
SUM plan jest pokazany poniżej jako przykład:

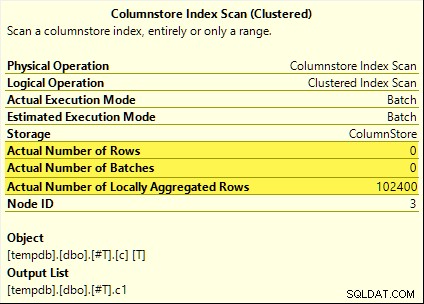
Nieudane zagregowane pushdown
Teraz upuść, a następnie odtwórz tabelę testową magazynu kolumn z przesunięciem zmniejszonym o jeden:
DROP TABLE IF EXISTS #T;
GO
CREATE TABLE #T (c1 bigint NOT NULL);
GO
DECLARE
-- Note this value has decreased by one
@Start bigint = CONVERT(bigint, -4611686018427387906);
INSERT #T (c1)
SELECT
c1 = @Start + N.n
FROM #Numbers AS N;
GO
CREATE CLUSTERED COLUMNSTORE INDEX c ON #T
WITH (MAXDOP = 1); Uruchom dokładnie te same agregujące zapytania testowe pushdown co poprzednio:
SELECT
c = COUNT_BIG(*)
FROM #T AS T
WHERE 1 = (SELECT 1) -- Avoid trivial plan
OPTION (MAXDOP 1);
SELECT
m = MAX(T.c1)
FROM #T AS T
WHERE 1 = (SELECT 1) -- Avoid trivial plan
OPTION (MAXDOP 1);
SELECT
s = SUM(T.c1 + CONVERT(bigint, 4611686018427387904))
FROM #T AS T
WHERE 1 = (SELECT 1) -- Avoid trivial plan
OPTION (MAXDOP 1);
Tym razem tylko COUNT_BIG agregacja osiąga agregację pushdown (tylko SQL Server 2017). MAX i SUM agregaty nie. Oto nowa SUM plan do porównania z tym z pierwszego testu:

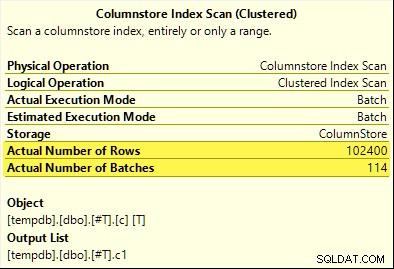
Wszystkie 102 400 wierszy (w 114 partiach) jest emitowanych przez Skanowanie indeksu kolumnowego , przetwarzane przez Compute Scalar i wysłane do Hash Aggregate .
Dlaczego różnica? Wszystko, co zrobiliśmy, to przesunięcie zakresu liczb przechowywanych w tabeli magazynu kolumn o jeden!
Wyjaśnienie
Wspomniałem we wstępie, że nie wszystkie ośmiobajtowe typy danych mieszczą się w 64 bitach. Ten fakt jest ważny ponieważ wiele optymalizacji wydajności magazynu kolumn i trybu wsadowego działa tylko z danymi o rozmiarze 64-bitowym. Jedną z tych rzeczy jest agregacja pushdown. Istnieje wiele innych funkcji wydajności (nie wszystkie udokumentowane), które działają najlepiej (lub w ogóle) tylko wtedy, gdy dane mieszczą się w 64 bitach.
W naszym konkretnym przykładzie zagregowane przesuwanie w dół jest wyłączone dla segmentu magazynu kolumn, gdy zawiera nawet jeden wartość danych, która nie mieści się w 64 bitach. SQL Server może to określić na podstawie metadanych o minimalnej i maksymalnej wartości skojarzonych z każdym segmentem bez sprawdzania wszystkich danych. Każdy segment jest oceniany osobno.
Zagregowane przesuwanie w dół nadal działa dla COUNT_BIG agregat dopiero w drugim teście. Jest to optymalizacja dodana w pewnym momencie w SQL Server 2017 (moje testy były prowadzone na CU16). Logiczne jest, aby nie wyłączać agregacji pushdown, gdy liczymy tylko wiersze i nie robimy nic z określonymi wartościami danych. Nie mogłem znaleźć żadnej dokumentacji dotyczącej tego ulepszenia, ale w dzisiejszych czasach nie jest to takie niezwykłe.
Na marginesie zauważyłem, że SQL Server 2017 CU16 umożliwia agregację pushdown dla wcześniej nieobsługiwanych typów danych real , float , datetimeoffset i numeric z precyzją większą niż 18 — gdy dane mieszczą się w 64 bitach. Jest to również nieudokumentowane w momencie pisania.
OK, ale dlaczego?
Możesz zadać bardzo rozsądne pytanie:Dlaczego jeden zestaw bigint wartości testowe najwyraźniej mieszczą się w 64 bitach, ale inne nie?
Jeśli zgadłeś, że przyczyna była związana z NULL , daj sobie kleszcza. Mimo że kolumna tabeli testowej jest zdefiniowana jako NOT NULL , SQL Server używa tego samego znormalizowanego układu danych dla bigint czy dane dopuszczają wartości null, czy nie. Są ku temu powody, które będę stopniowo rozpakowywać.
Zacznę od kilku obserwacji:
- Każda wartość kolumny w partii jest przechowywana w dokładnie ośmiu bajtach (64 bity), niezależnie od bazowego typu danych. Ten układ o stałym rozmiarze sprawia, że wszystko jest łatwiejsze i szybsze. Wykonanie w trybie wsadowym polega na szybkości.
- Pakiet ma rozmiar 64 KB i zawiera od 64 do 900 wierszy, w zależności od liczby rzutowanych kolumn. Ma to sens, biorąc pod uwagę, że rozmiary danych kolumn są ustalone na 64 bity. Więcej kolumn oznacza, że w każdej partii 64 KB może się zmieścić mniej wierszy.
- Nie wszystkie typy danych programu SQL Server mogą zmieścić się w 64 bitach, nawet co do zasady. Długi ciąg (by wziąć jeden przykład) może nawet nie zmieścić się w całej partii 64 KB (jeśli jest to dozwolone), nie mówiąc już o pojedynczym wpisie 64-bitowym.
SQL Server rozwiązuje ten ostatni problem, przechowując 8-bajtowe odniesienie do danych większych niż 64 bity. „Duża” wartość danych jest przechowywana w innym miejscu pamięci. Możesz nazwać ten układ przechowywaniem „poza rzędem” lub „poza partiami”. Wewnętrznie określa się je jako głębokie dane .
Teraz ośmiobajtowe typy danych nie mogą zmieścić się w 64 bitach, gdy dopuszczają wartość null. Weź bigint NULL na przykład . Zakres danych innych niż null może wymagać pełnych 64 bitów, a my nadal potrzebujemy innego bitu, aby wskazać null lub nie.
Rozwiązywanie problemów
Kreatywnym i skutecznym rozwiązaniem tych wyzwań jest zarezerwowanie najmniejszego znaczącego bitu (LSB) wartości 64-bitowej jako flagi. Flaga wskazuje wsadowo przechowywanie danych, gdy LSB jest czysty (ustawiony na zero). Gdy LSB jest ustawiony (do jednego), może to oznaczać jedną z dwóch rzeczy:
- Wartość jest pusta; lub
- Wartość jest przechowywana poza partiami (to głębokie dane).
Te dwa przypadki różnią się stanem pozostałych 63 bitów. Kiedy są wszystkie zero , wartość to NULL . W przeciwnym razie „wartość” jest wskaźnikiem do głębokich danych przechowywanych gdzie indziej.
Gdy postrzegane jako liczba całkowita, ustawienie LSB oznacza, że wskaźniki do głębokich danych zawsze będą nieparzyste liczby. Nulls są reprezentowane przez (nieparzystą) liczbę 1 (wszystkie pozostałe bity są zerowe). Dane wsadowe są reprezentowane przez parzyste liczb, ponieważ LSB wynosi zero.
To nie oznacza, że SQL Server może przechowywać tylko liczby parzyste w partii! Oznacza to po prostu, że znormalizowana reprezentacja wartości kolumn bazowych zawsze będą miały zerową wartość LSB, gdy są przechowywane „wsadowo”. Za chwilę nabierze to większego sensu.
Wsadowa normalizacja danych
Normalizacja jest wykonywana na różne sposoby, w zależności od bazowego typu danych. Dla bigint proces to:
- Jeśli dane są null , zapisz wartość 1 (tylko zestaw LSB).
- Jeśli wartość może być przedstawiona w 63 bitach , przesuń wszystkie bity o jedno miejsce w lewo i wyzeruj LSB. Patrząc na wartość jako liczbę całkowitą, oznacza to podwojenie wartość. Na przykład
bigintwartość 1 jest znormalizowana do wartości 2. W systemie binarnym jest to siedem całkowicie zerowych bajtów, po których następuje00000010. Wartość zerowa LSB oznacza, że są to dane przechowywane w linii. Kiedy SQL Server potrzebuje oryginalnej wartości, przesuwa w prawo 64-bitową wartość o jedną pozycję (odrzuca flagę LSB). - Jeśli wartość nie może być reprezentowane w 63 bitach, wartość jest przechowywana poza partiami jako dane głębokie . Wskaźnik wsadowy ma ustawioną wartość LSB (co czyni go liczbą nieparzystą).
Proces testowania, czy bigint wartość może zmieścić się w 63 bitach to:
- Przechowuj surowy*
bigintwartość w rejestrze procesora 64-bitowegor8. - Przechowuj podwójną wartość
r8w rejestrzerax. - Przesuń bity
raxjedno miejsce po prawej. - Sprawdź, czy wartości w
raxir8są równe.
* Uwaga:nie można wiarygodnie określić wartości surowej dla wszystkich typów danych przez konwersję T-SQL na typ binarny. Wynik T-SQL może mieć inną kolejność bajtów i może również zawierać metadane, np. time precyzja ułamkowa sekundy.
Jeśli test w kroku 4 zakończy się pomyślnie, wiemy, że wartość można podwoić, a następnie zmniejszyć o połowę w ciągu 64 bitów — zachowując oryginalną wartość.
Zmniejszony zasięg
Rezultatem tego wszystkiego jest to, że zakres bigint wartości, które mogą być przechowywane w partiach, są zmniejszone o jeden bit (ponieważ LSB nie jest dostępny). Następujące włącznie zakresy bigint wartości będą przechowywane poza partiami jako dane głębokie :
- -4 611 686 018 427 387 905 do -9 223 372 036 854 775 808
- +4 611 686 018 427 387 904 do +9 223 372 036 854 775 807
W zamian za zaakceptowanie, że te bigint ograniczenia zakresu, normalizacja umożliwia SQL Serverowi przechowywanie (większości) bigint wartości, wartości null i głębokie odwołania do danych wsadowo . Jest to o wiele prostsze i bardziej oszczędne pod względem przestrzeni niż posiadanie oddzielnych struktur dla wartości null i głębokich odwołań do danych. Ułatwia to również przetwarzanie danych wsadowych za pomocą instrukcji procesora SIMD.
Normalizacja innych typów danych
SQL Server zawiera normalizację kod dla każdego z typów danych obsługiwanych przez wykonanie w trybie wsadowym. Każda procedura jest zoptymalizowana pod kątem wydajnej obsługi przychodzącego układu binarnego i tworzenia głębokich danych tylko wtedy, gdy jest to konieczne. Normalizacja zawsze skutkuje zarezerwowaniem LSB do wskazywania wartości zerowych lub głębokich danych, ale układ pozostałych 63 bitów różni się w zależności od typu danych.
Zawsze w partii
Znormalizowane dane dla następujących typów danych są zawsze przechowywane zbiorczo ponieważ nigdy nie potrzebują więcej niż 63 bitów:
datetime(n)– przeskalowane wewnętrznie dotime(7)datetime2(n)– przeskalowane wewnętrznie dodatetime2(7)integersmallinttinyintbit– używatinyintwdrożenie.smalldatetimedatetimerealfloatsmallmoney
To zależy
Następujące typy danych mogą być przechowywane dane zbiorcze lub głębokie w zależności od wartości danych:
bigint– jak opisano wcześniej.money– ten sam zakres w partii cobigintale podzielone przez 10 000.numeric/decimal– 18 cyfr dziesiętnych lub mniej w partii niezależnie deklarowanej precyzji. Na przykładdecimal(38,9)wartość -999999999.999999999 może być reprezentowana jako 8-bajtowa liczba całkowita -999999999999999999 (f21f494c589c0001szesnastkowy), który można podwoić do -1999999999999999998 (e43e9298b1380002szesnastkowy) odwracalnie w ciągu 64 bitów. SQL Server wie, dokąd idzie przecinek dziesiętny ze skali typu danych.datetimeoffset(n)– wsadowo, jeśli wartość czasu działania zmieści się wdatetimeoffset(2)niezależnie zadeklarowanej dokładności ułamków sekund.timestamp– format wewnętrzny różni się od wyświetlacza. Na przykładtimestampwyświetlane z T-SQL jako0x000000000099449Ajest reprezentowany wewnętrznie jako9a449900 00000000(w szesnastkach). Ta wartość jest przechowywana jako głębokie dane, ponieważ nie mieści się w 64-bitach po podwojeniu (przesunięcie w lewo o jeden bit).
Zawsze głębokie dane
Następujące dane są zawsze przechowywane jako głębokie dane (z wyjątkiem wartości null) :
uniqueidentifiervarbinary(n)– w tym(max)binarychar/varchar(n)/nchar/nvarchar(n)/sysnamew tym(max)– te typy mogą również korzystać ze słownika (jeśli jest dostępny).text/ntext/image/xml– używavarbinary(n)wdrożenie.
Żeby było jasne, null dla wszystkich Typy danych kompatybilne z trybem wsadowym są przechowywane wsadowo jako specjalna wartość „jeden”.
Ostateczne myśli
Możesz oczekiwać najlepszego wykorzystania dostępnych optymalizacji magazynu kolumn i trybu wsadowego podczas korzystania z typów danych i wartości mieszczących się w 64 bitach. Będziesz mieć również największe szanse na skorzystanie z przyrostowych ulepszeń produktów w czasie, na przykład najnowszych ulepszeń agregacji pushdown odnotowanych w głównym tekście. Nie wszystkie zalety wydajności będą tak widoczne w planach wykonawczych, a nawet udokumentowane. Niemniej jednak różnice mogą być niezwykle znaczące.
Powinienem również wspomnieć, że dane są znormalizowane, gdy operator planu wykonania w trybie wierszowym dostarcza dane do elementu nadrzędnego w trybie wsadowym lub gdy skanowanie niebędące kolumną generuje partie (tryb wsadowy w magazynie wierszy). Istnieje niewidoczny adapter wiersza do partii, który wywołuje odpowiednią procedurę normalizacji dla każdej wartości kolumny przed dodaniem jej do partii. Unikanie typów danych ze skomplikowaną normalizacją i głębokim przechowywaniem danych może również w tym przypadku przynieść korzyści w zakresie wydajności.