Klaster Percona XtraDB to bardzo dobrze znane rozwiązanie wysokiej dostępności w świecie MySQL. Opiera się na klastrze Galera i zapewnia wirtualnie synchroniczną replikację w wielu węzłach. Jak w przypadku każdej bazy danych, kluczowe jest śledzenie tego, co dzieje się w systemie, czy wydajność jest na oczekiwanym poziomie, a jeśli nie, jakie jest wąskie gardło. Ma to ogromne znaczenie, aby móc właściwie zareagować w sytuacji, gdy ma to wpływ na wydajność. Oczywiście klaster Percona XtraDB zawiera wiele metryk i nie zawsze jest jasne, które z nich są najważniejsze do śledzenia stanu bazy danych. W tym blogu omówimy kilka kluczowych wskaźników, na które chcesz mieć oko podczas pracy z PXC.
Aby było jasne, skupimy się na metrykach unikalnych dla PXC i Galera, nie będziemy omawiać metryk dla MySQL ani InnoDB. Te dane zostały omówione w naszych poprzednich blogach.
Rzućmy okiem na niektóre z najważniejszych informacji, które przedstawia nam PXC.
Kontrola przepływu
Kontrola przepływu jest w zasadzie najważniejszym wskaźnikiem, jaki można monitorować w dowolnym klastrze Galera, dlatego przyjrzyjmy się trochę tła. Galera to multi-master, praktycznie synchroniczny klaster. Możliwe jest wykonywanie zapisów na dowolnym z węzłów bazy danych, które ją tworzą. Każdy zapis musi być wysłany do wszystkich węzłów w klastrze, aby mógł być zastosowany – proces ten nazywa się certyfikacją. Żadna transakcja nie może zostać zastosowana, zanim wszystkie węzły zgodzą się, że może zostać zatwierdzona. Jeśli któryś z węzłów ma problemy z wydajnością, które uniemożliwiają mu radzenie sobie z ruchem, zacznie wysyłać komunikaty kontroli przepływu, które mają na celu poinformowanie reszty klastra o problemach z wydajnością i poproszenie ich o zmniejszenie obciążenia i pomoc opóźnionym węzeł, aby dogonić resztę klastra.
Możesz śledzić, kiedy węzły musiały wprowadzić sztuczną pauzę, aby ich opóźnione elementy równorzędne mogły nadrobić zaległości za pomocą wskaźnika wstrzymania kontroli przepływu (wsrep_flow_control_paused):

Możesz również śledzić, czy węzeł wysyła lub odbiera komunikaty kontroli przepływu (wsrep_flow_control_recv i wsrep_flow_control_sent).
Te informacje pomogą Ci lepiej zrozumieć, który węzeł nie działa na tym samym na poziomie swoich rówieśników. Następnie możesz skupić się na tym węźle i spróbować zrozumieć, na czym polega problem i jak usunąć wąskie gardło.
Kolejki wysyłania i odbierania
Te metryki są w pewnym sensie powiązane z kontrolą przepływu. Jak już wspomnieliśmy, węzeł może pozostawać w tyle za innymi węzłami w klastrze. Może to być spowodowane nierównomiernym podziałem obciążenia lub innymi przyczynami (jakiś proces działający w tle, kopia zapasowa lub niektóre niestandardowe, ciężkie zapytania). Przed uruchomieniem kontroli przepływu węzły opóźnione będą próbowały przechowywać przychodzące zestawy zapisu w kolejce odbiorczej (wsrep_local_recv_queue), mając nadzieję, że wpływ na wydajność jest przejściowy i będzie w stanie szybko nadrobić zaległości. Dopiero gdy kolejka stanie się zbyt duża (zarządza nią ustawienie gcs.fc_limit), komunikaty kontroli przepływu zaczną być wysyłane przez klaster.

Możesz myśleć o kolejce odbioru jako wczesnym znaczniku, który pokazuje, że istnieje występują problemy z wydajnością i kontrola przepływu może się uruchomić.

Z drugiej strony kolejka wysyłania (wsrep_local_send_queue) poinformuje Cię, że węzeł nie jest w stanie wysłać zestawów zapisu do innych członków klastra, co może wskazywać na problemy z łącznością sieciową (przekazywanie zestawów zapisu do sieć tak naprawdę nie wymaga dużych zasobów).
Wskaźniki równoległości
Klaster Percona XtraDB można skonfigurować tak, aby używał wielu wątków do stosowania przychodzących zestawów zapisu — pozwala to na lepszą obsługę wielu wątków łączących się z klastrem i jednocześnie dokonujących zapisów. Istnieją dwa główne wskaźniki, na które warto zwrócić uwagę.
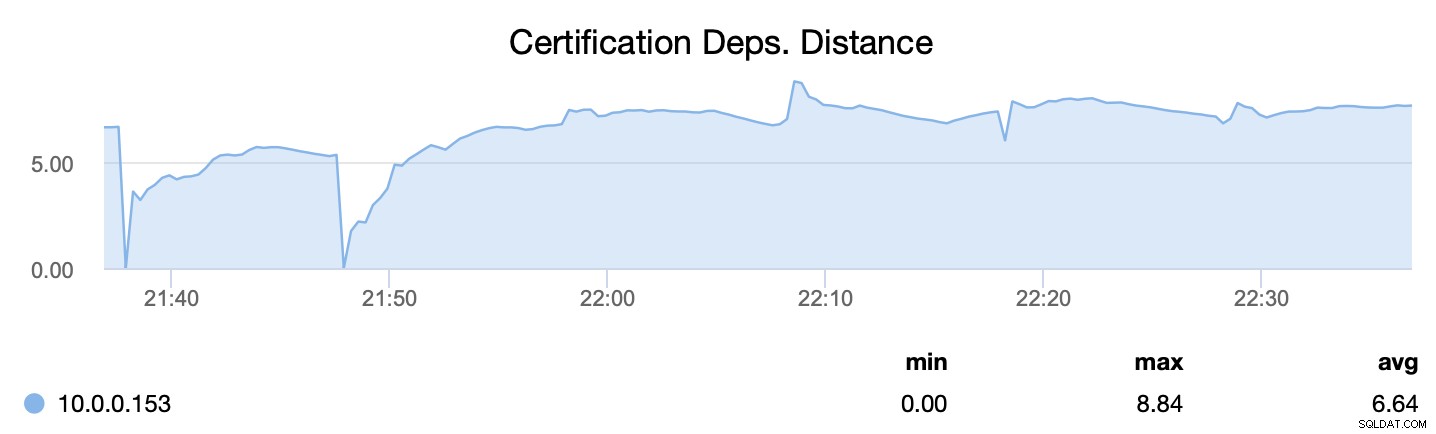
Po pierwsze, wsrep_cert_deps_distance, mówi nam jaki jest potencjał paralelizacji - ile potencjalnie zestawów zapisu można zastosować w tym samym czasie. Na podstawie tej wartości można skonfigurować liczbę równoległych wątków podrzędnych (wsrep_slave_threads), które będą działać przy stosowaniu przychodzących zestawów zapisu. Ogólna zasada jest taka, że nie ma sensu konfigurować większej liczby wątków niż wartość wsrep_cert_deps_distance.
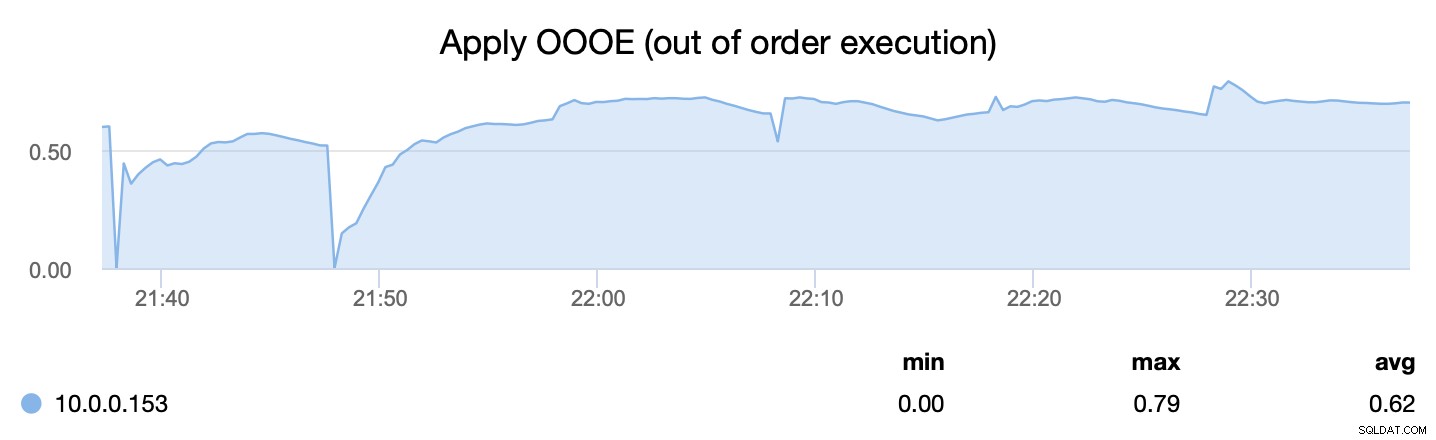
Druga metryka z kolei mówi nam, jak skutecznie byliśmy w stanie zrównoleglić proces stosowania zapisów — wsrep_apply_oooe mówi nam, jak często aplikant zaczął stosować zapisy niewłaściwie (co wskazuje na lepszą równoległość ).
Wnioski
Jak widać, w klastrze Percona XtraDB warto przyjrzeć się kilku metrykom. Oczywiście, jak napisaliśmy na początku tego bloga, są to metryki ściśle związane z PXC i ogólnie klastrem Galera.
Powinieneś także zwracać uwagę na regularne metryki MySQL i InnoDB, aby lepiej zrozumieć stan swojej bazy danych. I pamiętaj, możesz monitorować tę technologię za darmo, korzystając z ClusterControl Community Edition.



