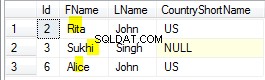
Antywzór?
W powszechnym przypadku druga tabela to antywzór w kontekście projektowania baz danych. Co więcej, ma konkretną nazwę:Entity-Attribute-Value (EAV). W niektórych przypadkach użycie tego wzoru jest uzasadnione, ale są to rzadkie przypadki - i nawet tam można tego uniknąć.
Dlaczego EAV jest zły
Obsługa integralności danych
Pomimo tego, że taka konstrukcja wydaje się być bardziej „elastyczna” lub „zaawansowana”, ta konstrukcja ma słabość.
- Nie można wprowadzić obowiązkowych atrybutów . Nie możesz uczynić niektórych atrybutów obowiązkowymi, ponieważ atrybut jest teraz przechowywany jako wiersz - a jedynym znakiem, że atrybut nie jest ustawiony - jest to, że odpowiadający mu wiersz jest nieobecny w tabeli. SQL nie pozwoli ci na budowanie takiego ograniczenia natywnie - dlatego będziesz musiał to sprawdzić w aplikacji - i tak, za każdym razem pytaj o swoją tabelę
- Mieszanie typów danych . Nie będziesz mógł używać standardowych typów danych SQL. Ponieważ kolumna wartości musi być „supertypem” dla wszystkich przechowywanych w niej wartości. Oznacza to, że ogólnie będziesz musiał przechowywać wszystkie dane jako surowe ciągi . Wtedy zobaczysz, jak bolesna jest praca z datami, tak jak z łańcuchami, za każdym razem rzutowanie typów danych, sprawdzanie integralności danych itp.
- Nie można wymusić integralności referencyjnej . W normalnej sytuacji możesz użyć klucza obcego, aby ograniczyć swoje wartości do tych, które są zdefiniowane w tabeli nadrzędnej. Ale nie w tym przypadku — to dlatego, że integralność referencyjna jest stosowana do każdego wiersza w tabeli, ale nie do wartości wierszy. Tak więc – stracisz tę przewagę – i jest to jedna z podstawowych w relacji DB
- Nie można ustawić nazw atrybutów . Oznacza to, że nie można poprawnie ograniczyć nazwy atrybutu na poziomie bazy danych. Na przykład napiszesz
"customer_name"jako nazwa atrybutu w pierwszym przypadku - inny programista zapomni o tym i użyje"name_of_customer". I... jest ok, DB to przejdzie i skończysz z godzinami spędzonymi na debugowaniu tego przypadku.
Rekonstrukcja wiersza
Ponadto w powszechnym przypadku rekonstrukcja rzędu będzie okropna. Jeśli masz na przykład 5 atrybutów - będzie to 5 samodzielnych tabel JOIN -s. Szkoda dla tak prostego – na pierwszy rzut oka – przypadku. Więc nie chcę nawet wyobrażać sobie, jak utrzymasz 20 atrybutów.
Czy jest to uzasadnione?
Chodzi mi o to - nie. W RDBMS zawsze będzie sposób na uniknięcie tego. To jest straszne. A jeśli EAV ma być używany, najlepszym wyborem może być nierelacja bazy danych.