Ostatnio zajmowałem się rozwojem funkcjonalności, która wymagała szybkiego i częstego przenoszenia dużych ilości danych na dysk. Ponadto dane te miały być co jakiś czas odczytywane z dysku. Dlatego moim przeznaczeniem było dowiedzieć się, gdzie, w jaki sposób i jak przechowywać te dane. W tym artykule krótko omówię zadanie, a także zbadam i porównam rozwiązania umożliwiające wykonanie tego zadania.
Kontekst zadania :Pracuję w zespole, który opracowuje narzędzia do relatywnego rozwoju baz danych (SQL Server, MySQL, Oracle). Asortyment narzędzi obejmuje zarówno samodzielne narzędzia, jak i dodatki do MS SSMS.
Zadanie :Przywracanie dokumentów, które zostały otwarte w momencie zamknięcia IDE przy następnym uruchomieniu IDE.
Przypadek użycia :Aby szybko zamknąć IDE przed opuszczeniem biura bez zastanawiania się, które dokumenty zostały zapisane, a które nie. Przy kolejnym uruchomieniu IDE musimy uzyskać to samo środowisko, które było w momencie zamykania i kontynuować pracę. Wszystkie wyniki pracy muszą być zachowane w momencie nieuporządkowanego zamknięcia m.in. podczas awarii programu lub systemu operacyjnego lub podczas wyłączania.
Analiza zadań :Podobna funkcja jest obecna w przeglądarkach internetowych. Jednak przeglądarki przechowują tylko adresy URL składające się z około 100 symboli. W naszym przypadku musimy przechowywać całą zawartość dokumentu. Dlatego potrzebujemy miejsca do zapisywania i przechowywania dokumentów użytkownika. Co więcej, czasami użytkownicy pracują z SQL inaczej niż z innymi językami. Na przykład, jeśli napiszę klasę C# o długości większej niż 1000 wierszy, nie będzie to do zaakceptowania. Podczas gdy we wszechświecie SQL, obok zapytań 10-20 wierszy, istnieją monstrualne zrzuty bazy danych. Takie zrzuty są trudne do edycji, co oznacza, że użytkownicy woleliby, aby ich zmiany były bezpieczne.
Wymagania dotyczące przechowywania:
- Powinno to być lekkie, wbudowane rozwiązanie.
- Powinna mieć dużą szybkość zapisu.
- Powinna mieć możliwość dostępu wieloprocesowego. To wymaganie nie jest krytyczne, ponieważ możemy zapewnić dostęp za pomocą obiektów synchronizacji, ale nadal byłoby miło mieć tę opcję.
Kandydaci
Pierwszy kandydat jest raczej niezdarny, to znaczy przechowywać wszystko w folderze, gdzieś w AppData.
Drugi kandydat jest oczywisty – SQLite, standard wbudowanych baz danych. Bardzo solidny i popularny kandydat.
Trzecim kandydatem jest baza danych LiteDB. Jest to pierwszy wynik zapytania „wbudowana baza danych dla .net” w Google.
Pierwszy widok
System plików. Pliki to pliki, wymagają konserwacji i odpowiedniego nazewnictwa. Oprócz zawartości pliku będziemy musieli przechowywać mały zestaw właściwości (oryginalna ścieżka na dysku, parametry połączenia, wersja IDE, w której został otwarty). Oznacza to, że będziemy musieli albo utworzyć dwa pliki dla jednego dokumentu, albo wymyślić format oddzielający właściwości od treści.
SQLite to klasyczna relacyjna baza danych. Baza danych jest reprezentowana przez jeden plik na dysku. Plik ten jest wiązany ze schematem bazy danych, po czym musimy z nim współdziałać za pomocą środków SQL. Będziemy mogli utworzyć 2 tabele, jedną dla właściwości, a drugą dla treści – na wypadek, gdybyśmy musieli używać właściwości lub treści osobno.
LiteDB to nierelacyjna baza danych. Podobnie jak SQLite, baza danych jest reprezentowana przez pojedynczy plik. Jest w całości napisany w języku С#. Ma urzekającą prostotę użytkowania:wystarczy przekazać obiekt do biblioteki, podczas gdy serializacja zostanie wykonana własnymi środkami.
Test wydajności
Przed dostarczeniem kodu chciałbym wyjaśnić ogólną koncepcję i przedstawić wyniki porównania.
Ogólna koncepcja polega na porównaniu szybkości zapisu dużej ilości małych plików do bazy danych, średniej ilości średnich plików i małej ilości dużych plików. Sprawa ze średnimi plikami jest w większości zbliżona do rzeczywistego przypadku, podczas gdy sprawy z małymi i dużymi plikami to przypadki graniczne, co również należy wziąć pod uwagę.
Zapisywałem zawartość do pliku za pomocą FileStream ze standardowym rozmiarem bufora.
W SQLite był jeden niuans, o którym chciałbym wspomnieć. Nie udało nam się umieścić całej zawartości dokumentów (jak wspomniałem powyżej, mogą one być naprawdę duże) w jednej komórce bazy danych. Chodzi o to, że dla celów optymalizacji przechowujemy tekst dokumentu linia po linii. Oznacza to, że aby umieścić tekst w jednej komórce, musimy zmieścić cały dokument w jednym wierszu, co podwoiłoby ilość używanej pamięci operacyjnej. Druga strona problemu ujawniłaby się podczas odczytu danych z bazy danych. Dlatego w SQLite istniała osobna tabela, w której dane były przechowywane wiersz po wierszu, a dane były łączone za pomocą klucza obcego z tabelą zawierającą tylko właściwości pliku. Poza tym udało mi się przyspieszyć bazę danych dzięki wsadowemu wstawianiu danych (kilka tysięcy wierszy na raz) w trybie synchronizacji OFF bez logowania i w ramach jednej transakcji.
LiteDB otrzymał obiekt mający wśród swoich właściwości List i biblioteka samodzielnie zapisała go na dysku.
Podczas tworzenia aplikacji testowej zrozumiałem, że wolę LiteDB. Chodzi o to, że kod testowy dla SQLite zajmuje ponad 120 wierszy, podczas gdy kod, który rozwiązuje ten sam problem w LiteDb, zajmuje tylko 20 wierszy.
Testowe generowanie danych
FileStrings.cs
internal class FileStrings {
private static readonly Random random = new Random();
public List Strings {
get;
set;
} = new List();
public int SomeInfo {
get;
set;
}
public FileStrings() {
}
public FileStrings(int id, int minLines, decimal lineIncrement) {
SomeInfo = id;
int lines = minLines + (int)(id * lineIncrement);
for (int i = 0; i < lines; i++) {
Strings.Add(GetString());
}
}
private string GetString() {
int length = 250;
StringBuilder builder = new StringBuilder(length);
for (int i = 0; i < length; i++) { builder.Append(random.Next((int)'a', (int)'z')); } return builder.ToString(); } } Program.cs List files = Enumerable.Range(1, NUM_FILES + 1) .Select(f => new FileStrings(f, MIN_NUM_LINES, (MAX_NUM_LINES - MIN_NUM_LINES) / (decimal)NUM_FILES))
.ToList();
SQLite
private static void SaveToDb(List files) {
using (var connection = new SQLiteConnection()) {
connection.ConnectionString = @"Data Source=data\database.db;FailIfMissing=False;";
connection.Open();
var command = connection.CreateCommand();
command.CommandText = @"CREATE TABLE files
(
id INTEGER PRIMARY KEY,
file_name TEXT
);
CREATE TABLE strings
(
id INTEGER PRIMARY KEY,
string TEXT,
file_id INTEGER,
line_number INTEGER
);
CREATE UNIQUE INDEX strings_file_id_line_number_uindex ON strings(file_id,line_number);
PRAGMA synchronous = OFF;
PRAGMA journal_mode = OFF";
command.ExecuteNonQuery();
var insertFilecommand = connection.CreateCommand();
insertFilecommand.CommandText = "INSERT INTO files(file_name) VALUES(?); SELECT last_insert_rowid();";
insertFilecommand.Parameters.Add(insertFilecommand.CreateParameter());
insertFilecommand.Prepare();
var insertLineCommand = connection.CreateCommand();
insertLineCommand.CommandText = "INSERT INTO strings(string, file_id, line_number) VALUES(?, ?, ?);";
insertLineCommand.Parameters.Add(insertLineCommand.CreateParameter());
insertLineCommand.Parameters.Add(insertLineCommand.CreateParameter());
insertLineCommand.Parameters.Add(insertLineCommand.CreateParameter());
insertLineCommand.Prepare();
foreach (var item in files) {
using (var tr = connection.BeginTransaction()) {
SaveToDb(item, insertFilecommand, insertLineCommand);
tr.Commit();
}
}
}
}
private static void SaveToDb(FileStrings item, SQLiteCommand insertFileCommand, SQLiteCommand insertLinesCommand) {
string fileName = Path.Combine("data", item.SomeInfo + ".sql");
insertFileCommand.Parameters[0].Value = fileName;
var fileId = insertFileCommand.ExecuteScalar();
int lineIndex = 0;
foreach (var line in item.Strings) {
insertLinesCommand.Parameters[0].Value = line;
insertLinesCommand.Parameters[1].Value = fileId;
insertLinesCommand.Parameters[2].Value = lineIndex++;
insertLinesCommand.ExecuteNonQuery();
}
} LiteDB
private static void SaveToNoSql(List item) {
using (var db = new LiteDatabase("data\\litedb.db")) {
var data = db.GetCollection("files");
data.EnsureIndex(f => f.SomeInfo);
data.Insert(item);
}
}
W poniższej tabeli przedstawiono średnie wyniki dla kilku uruchomień kodu testowego. Podczas modyfikacji odchylenie statystyczne było dość niezauważalne.
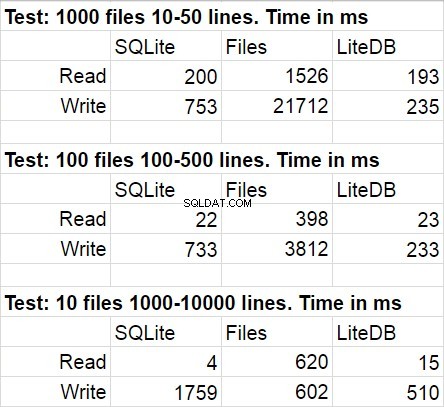
Nie zdziwiłem się, że w tym porównaniu wygrał LiteDB. Byłem jednak zszokowany wygraną LiteDB nad plikami. Po krótkim przestudiowaniu repozytorium biblioteki odkryłem bardzo skrupulatnie zaimplementowany zapis strony na dysk, ale jestem pewien, że jest to tylko jedna z wielu stosowanych tam sztuczek wydajnościowych. Jeszcze jedną rzeczą, na którą chciałbym zwrócić uwagę, jest duża szybkość zmniejszania się dostępu do systemu plików, gdy liczba plików w folderze staje się naprawdę duża.
Wybraliśmy LiteDB do rozwoju naszej funkcji i nie żałowaliśmy tego wyboru. Chodzi o to, że biblioteka jest napisana w języku natywnym dla każdego C#, a jeśli coś nie było do końca jasne, zawsze moglibyśmy odwołać się do kodu źródłowego.
Wady
Poza wyżej wymienionymi zaletami LiteDB w porównaniu z jego konkurentami, zaczęliśmy zauważać wady podczas rozwoju. Większość z tych wad można wytłumaczyć „młodością” biblioteki. Po rozpoczęciu korzystania z biblioteki nieco poza granice „standardowego” scenariusza, odkryliśmy kilka problemów (#419, #420, #483, #496). Autor biblioteki dość szybko odpowiadał na pytania, a większość problemów została szybko rozwiązana. Teraz pozostało tylko jedno zadanie (nie mylić z jego statusem Zamknięte). To jest kwestia konkurencyjnego dostępu. Wygląda na to, że gdzieś głęboko w bibliotece kryją się bardzo paskudne warunki wyścigowe. Pominęliśmy ten błąd w dość oryginalny sposób (zamierzam napisać osobny artykuł na ten temat).
Chciałbym również wspomnieć o braku zgrabnego edytora i przeglądarki. Jest LiteDBShell, ale tylko dla prawdziwych fanów konsol.
Podsumowanie
Zbudowaliśmy dużą i ważną funkcjonalność nad LiteDB, a teraz pracujemy nad kolejną dużą funkcją, w której będziemy również korzystać z tej biblioteki. Osobom poszukującym bazy danych wewnątrzprocesowych sugeruję zwrócenie uwagi na LiteDB i na to, jak sprawdzi się w kontekście Twojego zadania, bo jak wiadomo, gdyby coś się udało do jednego zadania, niekoniecznie musiałoby to poćwicz do innego zadania.