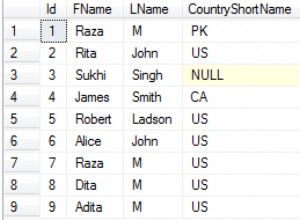
Widok działa jak tabela , ale to nie jest stół. Nigdy nie istnieje; jest to tylko przygotowana instrukcja SQL, która jest uruchamiana podczas odwoływania się do nazwy widoku. IE:
CREATE VIEW foo AS
SELECT * FROM bar
SELECT * FROM foo
...jest równoznaczne z uruchomieniem:
SELECT x.*
FROM (SELECT * FROM bar) x
MySQLDump nigdy nie będzie zawierał wierszy do wstawienia do widoku...
Jest to, niestety, z (choć wątpliwe) zamierzone. Istnieje wiele ograniczeń dla widoków MySQL, które są udokumentowane:https://dev.mysql.com/doc/refman/5.0/en/create-view.html
Więc jeśli jest to tylko wyimaginowana tabela/przygotowana instrukcja, czy oznacza to, że teoretycznie ma taką samą wydajność (lub nawet niższą) jak normalna tabela/zapytanie?
Nie.
Tabela może mieć powiązane indeksy, co może przyspieszyć pobieranie danych (za pewnymi kosztami wstawiania/aktualizacji). Niektóre bazy danych obsługują widoki „zmaterializowane”, czyli widoki, do których można zastosować indeksy – co nie powinno być niespodzianką, że MySQL nie obsługuje biorąc pod uwagę ograniczoną funkcjonalność widoku (która rozpoczęła się dopiero w wersji 5 IIRC, bardzo późno).
Ponieważ widok jest tabelą pochodną, wydajność widoku jest tak dobra, jak zapytanie, na którym jest zbudowany. Jeśli to zapytanie jest do niczego, problem z wydajnością będzie po prostu kulą śniegową... To powiedziawszy, podczas wykonywania zapytania dotyczącego widoku - jeśli odwołanie do kolumny widoku w klauzuli WHERE nie jest opakowane w funkcję (IE:WHERE v.column LIKE ... , nie WHERE LOWER(t.column) LIKE ... ), optymalizator może przesunąć kryteria (nazywane predykatem) do oryginalnego zapytania - przyspieszając je.