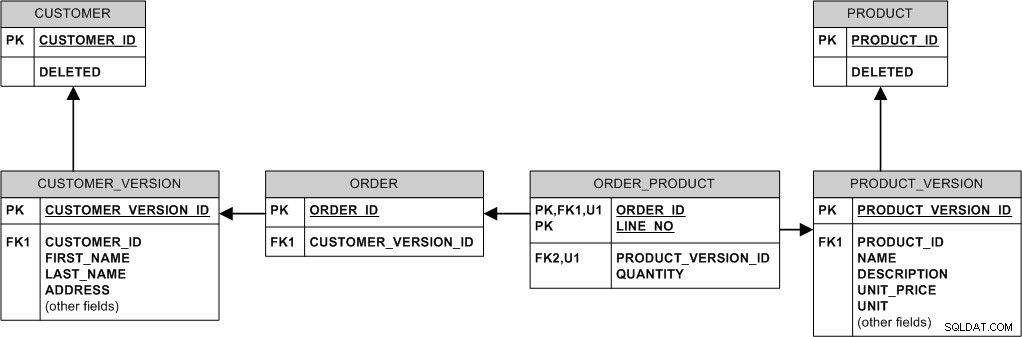
Oto jeden ze sposobów, aby to zrobić:
Zasadniczo nigdy nie modyfikujemy ani nie usuwamy istniejących danych. „Modyfikujemy” go tworząc nową wersję. „Usuwamy” go, ustawiając flagę DELETED.
Na przykład:
- Jeśli produkt zmieni cenę, wstawimy nowy wiersz do PRODUCT_VERSION, podczas gdy stare zamówienia będą nadal połączone ze starą PRODUCT_VERSION i starą ceną.
- Gdy kupujący zmieni adres, po prostu wstawiamy nowy wiersz w CUSTOMER_VERSION i łączymy z nim nowe zamówienia, zachowując stare zamówienia połączone ze starą wersją.
- Jeśli produkt zostanie usunięty, tak naprawdę nie usuwamy go — po prostu ustawiamy flagę PRODUCT.DELETED, aby wszystkie zamówienia złożone w przeszłości dla tego produktu pozostały w bazie danych.
- Jeśli klient zostanie usunięty (np. dlatego, że poprosił o wyrejestrowanie), ustaw flagę CUSTOMER.DELETED.
Zastrzeżenia:
- Jeśli nazwa produktu musi być unikalna, nie można tego wymusić deklaratywnie w powyższym modelu. Musisz albo „promować” nazwę NAME z PRODUCT_VERSION do PRODUCT, uczynić ją tam kluczem i zrezygnować z możliwości „rozwoju” nazwy produktu, albo wymusić unikalność tylko w najnowszym PRODUCT_VER (prawdopodobnie przez wyzwalacze).
- Występuje potencjalny problem z prywatnością klienta. Jeśli klient zostanie usunięty z systemu, może być pożądane fizyczne usunięcie jego danych z bazy danych, a samo ustawienie CUSTOMER.DELETED tego nie zrobi. Jeśli jest to problem, wyczyść dane wrażliwe na prywatność we wszystkich wersjach klienta lub alternatywnie odłącz istniejące zamówienia od rzeczywistego klienta i ponownie połącz je ze specjalnym „anonimowym” klientem, a następnie fizycznie usuń wszystkie wersje klienta.
Ten model wykorzystuje wiele identyfikujących relacji. Prowadzi to do "grubych" kluczy obcych i może być trochę problemem z przechowywaniem, ponieważ MySQL nie obsługuje zaawansowanej kompresji indeksów (w przeciwieństwie, powiedzmy, Oracle), ale z drugiej strony InnoDB zawsze grupuje dane na PK i to klastrowanie może być korzystne dla wydajności. Ponadto JOIN są mniej potrzebne.
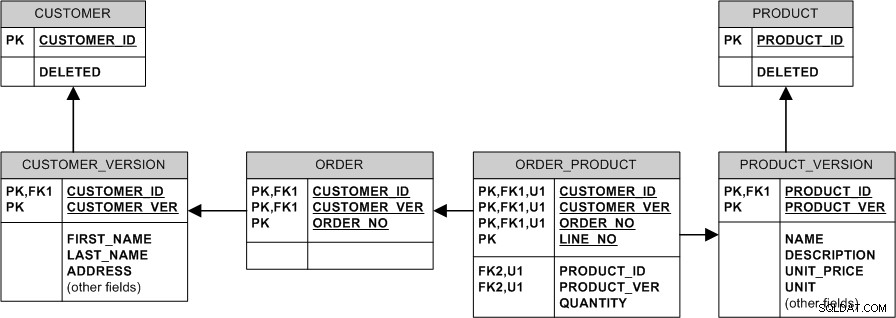
Model ekwiwalentny z nieidentyfikującymi relacjami i kluczami zastępczymi wyglądałby tak: