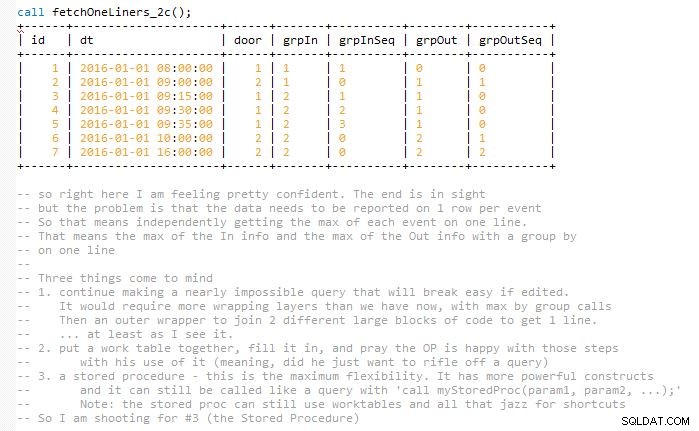
Ma to na celu utrzymanie rozwiązania w łatwości utrzymania bez kończenia ostatniego zapytania za jednym razem, co prawie podwoiłoby jego rozmiar (w moim umyśle). Dzieje się tak, ponieważ wyniki muszą być zgodne i reprezentowane w jednym wierszu z dopasowanymi zdarzeniami wejścia i wyjścia. Więc na koniec używam kilku stołów roboczych. Jest zaimplementowany w procedurze składowanej.
Procedura składowana wykorzystuje kilka zmiennych, które są wprowadzane za pomocą cross join . Pomyśl o łączeniu krzyżowym jako mechanizmie inicjowania zmiennych. Zmienne są utrzymywane bezpiecznie, więc wierzę, że zgodnie z tym dokument
często przywoływane w zapytaniach o zmienne. Ważną częścią odwołania jest bezpieczna obsługa zmiennych w linii, wymuszająca ich ustawienie przed innymi kolumnami, które z nich korzystają. Osiąga się to poprzez greatest() i least() funkcje, które mają wyższy priorytet niż zmienne ustawiane bez użycia tych funkcji. Zauważ też, że coalesce() jest często używany w tym samym celu. Jeśli ich użycie wydaje się dziwne, na przykład wzięcie największej liczby, o której wiadomo, że jest większa niż 0 lub 0, cóż, jest to celowe. Rozważnie wymuś kolejność pierwszeństwa ustawianych zmiennych.
Kolumny w zapytaniu nazywały się takimi jak dummy2 itd. to kolumny, których dane wyjściowe nie były używane, ale zostały użyte do ustawienia zmiennych wewnątrz, powiedzmy, greatest() lub inny. Zostało to wspomniane powyżej. Dane wyjściowe, takie jak 7777, były symbolem zastępczym w trzecim slocie, ponieważ potrzebna była pewna wartość dla if() który był używany. Więc zignoruj to wszystko.
Dołączyłem kilka zrzutów ekranu kodu w miarę postępu warstwa po warstwie, aby pomóc Ci zwizualizować wynik. I jak te iteracje rozwoju są powoli składane w następną fazę, aby rozwinąć poprzednią.
Jestem pewien, że moi rówieśnicy mogliby to poprawić w jednym zapytaniu. Mogłem to zakończyć w ten sposób. Ale wierzę, że spowodowałoby to mylący bałagan, który pękłby po dotknięciu.
Schemat:
create table attendance2(Id int, DateTime datetime, Door char(20), Active_door char(20));
INSERT INTO attendance2 VALUES
( 1, '2016-01-01 08:00:00', 'In', ''),
( 2, '2016-01-01 09:00:00', 'Out', ''),
( 3, '2016-01-01 09:15:00', 'In', ''),
( 4, '2016-01-01 09:30:00', 'In', ''),
( 5, '2016-01-01 09:35:00', '', 'On'),
( 6, '2016-01-01 10:00:00', 'Out', ''),
( 7, '2016-01-01 16:00:00', '', 'Off');
drop table if exists oneLinersDetail;
create table oneLinersDetail
( -- architect this depending on multi-user concurrency
id int not null,
dt datetime not null,
door int not null,
grpIn int not null,
grpInSeq int not null,
grpOut int not null,
grpOutSeq int not null
);
drop table if exists oneLinersSummary;
create table oneLinersSummary
( -- architect this depending on multi-user concurrency
id int not null,
grpInSeq int null,
grpOutSeq int null,
checkIn datetime null, -- we are hoping in the end it is not null
checkOut datetime null -- ditto
);
Procedura przechowywana:
DROP PROCEDURE IF EXISTS fetchOneLiners;
DELIMITER $$
CREATE PROCEDURE fetchOneLiners()
BEGIN
truncate table oneLinersDetail; -- architect this depending on multi-user concurrency
insert oneLinersDetail(id,dt,door,grpIn,grpInSeq,grpOut,grpOutSeq)
select id,dt,door,grpIn,grpInSeq,grpOut,grpOutSeq
from
( select id,dt,door,
if(@lastEvt!=door and door=1,
greatest(@grpIn:example@sqldat.com+1,0),
7777) as dummy2, -- this output column we don't care about (we care about the variable being set)
if(@lastEvt!=door and door=2,
greatest(@grpOut:example@sqldat.com+1,0),
7777) as dummy3, -- this output column we don't care about (we care about the variable being set)
if (@lastEvt!=door,greatest(@flip:=1,0),least(@flip:=0,1)) as flip,
if (door=1 and @flip=1,least(@grpOutSeq:=0,1),7777) as dummy4,
if (door=1 and @flip=1,greatest(@grpInSeq:=1,0),7777) as dummy5,
if (door=1 and @flip!=1,greatest(@grpInSeq:example@sqldat.comnSeq+1,0),7777) as dummy6,
if (door=2 and @flip=1,least(@grpInSeq:=0,1),7777) as dummy7,
if (door=2 and @flip=1,greatest(@grpOutSeq:=1,0),7777) as dummy8,
if (door=2 and @flip!=1,greatest(@grpOutSeq:example@sqldat.com+1,0),7777) as dummy9,
@grpIn as grpIn,
@grpInSeq as grpInSeq,
@grpOut as grpOut,
@grpOutSeq as grpOutSeq,
@lastEvt:=door as lastEvt
from
( select id,`datetime` as dt,
CASE
WHEN Door='in' or Active_door='on' THEN 1
ELSE 2
END as door
from attendance2
order by id
) xD1 -- derived table #1
cross join (select @grpIn:=0,@grpInSeq:=0,@grpOut:=0,@grpOutSeq:=0,@lastEvt:=-1,@flip:=0) xParams
order by id
) xD2 -- derived table #2
order by id;
-- select * from oneLinersDetail;
truncate table oneLinersSummary; -- architect this depending on multi-user concurrency
insert oneLinersSummary (id,grpInSeq,grpOutSeq,checkIn,checkOut)
select distinct grpIn,null,null,null,null
from oneLinersDetail
order by grpIn;
-- select * from oneLinersSummary;
update oneLinersSummary ols
join
( select grpIn,max(grpInSeq) m
from oneLinersDetail
where door=1
group by grpIn
) d1
on d1.grpIn=ols.id
set ols.grpInSeq=d1.m;
-- select * from oneLinersSummary;
update oneLinersSummary ols
join
( select grpOut,max(grpOutSeq) m
from oneLinersDetail
where door=2
group by grpOut
) d1
on d1.grpOut=ols.id
set ols.grpOutSeq=d1.m;
-- select * from oneLinersSummary;
update oneLinersSummary ols
join oneLinersDetail old
on old.door=1 and old.grpIn=ols.id and old.grpInSeq=ols.grpInSeq
set ols.checkIn=old.dt;
-- select * from oneLinersSummary;
update oneLinersSummary ols
join oneLinersDetail old
on old.door=2 and old.grpOut=ols.id and old.grpOutSeq=ols.grpOutSeq
set ols.checkOut=old.dt;
-- select * from oneLinersSummary;
-- dump out the results
select id,checkIn,checkOut
from oneLinersSummary
order by id;
-- rows are left in those two tables (oneLinersDetail,oneLinersSummary)
END$$
DELIMITER ;
Test:
call fetchOneLiners();
+----+---------------------+---------------------+
| id | checkIn | checkOut |
+----+---------------------+---------------------+
| 1 | 2016-01-01 08:00:00 | 2016-01-01 09:00:00 |
| 2 | 2016-01-01 09:35:00 | 2016-01-01 16:00:00 |
+----+---------------------+---------------------+
To koniec odpowiedzi. Poniżej przedstawiono dla programisty wizualizację kroków, które doprowadziły do zakończenia procedury składowanej.
Wersje rozwoju, które doprowadziły do końca. Miejmy nadzieję, że pomaga to w wizualizacji, a nie tylko upuszczaniu średniej wielkości mylącego fragmentu kodu.
Krok A
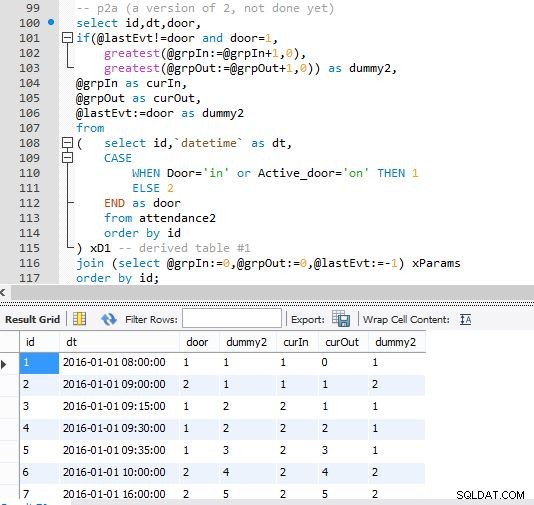
Krok B
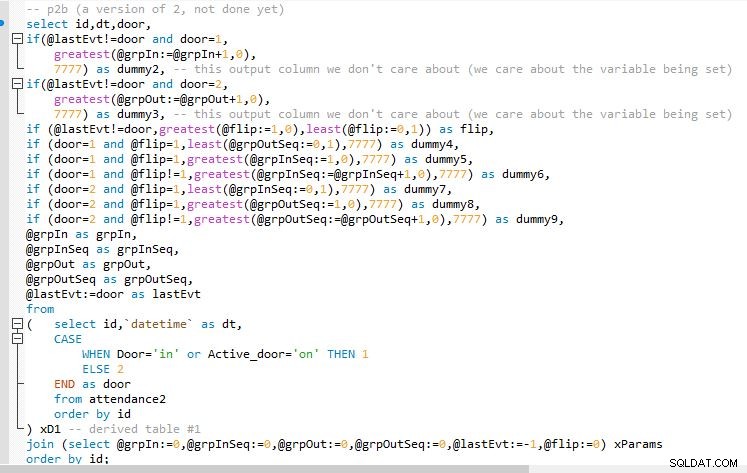
Wyjście kroku B

Krok C
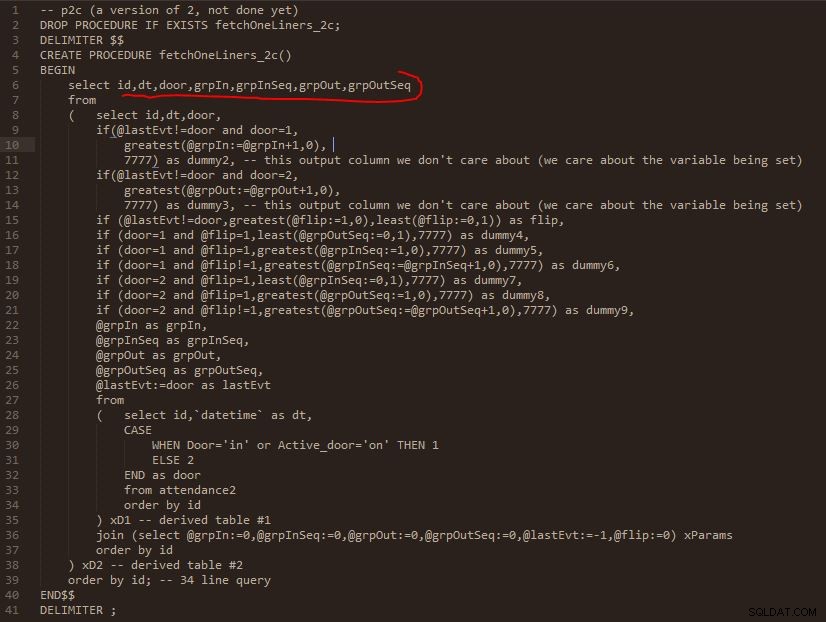
Wyjście kroku C