JPA (Adnotacja dotycząca trwałości Java ) to standardowe rozwiązanie Javy, które wypełnia lukę między obiektowymi modelami domen a relacyjnymi systemami baz danych. Pomysł polega na odwzorowaniu klas Java na tabele relacyjne, a właściwości tych klas na wiersze w tabeli. Zmienia to semantykę ogólnego doświadczenia związanego z kodowaniem Java poprzez bezproblemową współpracę dwóch różnych technologii w ramach tego samego paradygmatu programowania. Ten artykuł zawiera przegląd i wspierającą implementację w Javie.
Przegląd
Relacyjne bazy danych są prawdopodobnie najbardziej stabilną ze wszystkich technologii utrwalania dostępnych w informatyce, a nie wszystkich związanych z tym złożoności. Dzieje się tak, ponieważ dziś, nawet w dobie tak zwanych „big danych”, relacyjne bazy danych „NoSQL” są stale poszukiwane i rozwijają się. Relacyjne bazy danych to stabilna technologia nie przez same słowa, ale przez lata istnienia. NoSQL może być dobry do obsługi dużych ilości ustrukturyzowanych danych w przedsiębiorstwie, ale liczne obciążenia transakcyjne są lepiej obsługiwane przez relacyjne bazy danych. Ponadto istnieje kilka świetnych narzędzi analitycznych związanych z relacyjnymi bazami danych.
Aby komunikować się z relacyjną bazą danych, ANSI ustandaryzowało język o nazwie SQL (Ustrukturyzowany język zapytań ). Oświadczenie napisane w tym języku może służyć zarówno do definiowania danych, jak i do manipulowania nimi. Ale problem SQL w kontaktach z Javą polega na tym, że mają niedopasowaną strukturę składniową i bardzo różnią się w rdzeniu, co oznacza, że SQL jest proceduralny, podczas gdy Java jest zorientowana obiektowo. Poszukuje się więc działającego rozwiązania, aby Java mogła mówić w sposób obiektowy, a relacyjna baza danych nadal byłaby w stanie zrozumieć się nawzajem. JPA jest odpowiedzią na to wezwanie i zapewnia mechanizm do ustanowienia działającego rozwiązania między nimi.
Związek z mapowaniem obiektów
Programy Java współdziałają z relacyjnymi bazami danych za pomocą JDBC (Połączenie z bazą danych Java ) API. Sterownik JDBC jest kluczem do łączności i umożliwia programowi Java manipulowanie tą bazą danych za pomocą interfejsu API JDBC. Po nawiązaniu połączenia program Java uruchamia zapytania SQL w postaci String s do komunikacji tworzenia, wstawiania, aktualizowania i usuwania operacji. Jest to wystarczające do wszystkich praktycznych celów, ale niewygodne z punktu widzenia programisty Java. Co by było, gdyby strukturę tabel relacyjnych można było przemodelować do postaci czystych klas Javy, a następnie można by sobie z nimi poradzić w zwykły sposób obiektowy? Struktura tabeli relacyjnej jest logiczną reprezentacją danych w formie tabelarycznej. Tabele składają się z kolumn opisujących atrybuty encji, a wiersze są zbiorami encji. Na przykład tabela PRACOWNIK może zawierać następujące jednostki wraz z ich atrybutami.
| Emp_number | Nazwa | nr_działu | Wynagrodzenie | Miejsce |
| 112233 | Piotr | 123 | 1200 | LA |
| 112244 | Promień | 234 | 1300 | NY |
| 112255 | Piaskowanie | 123 | 1400 | NJ |
| 112266 | Kalpana | 234 | 1100 | LA |
Wiersze są unikatowe według klucza podstawowego (emp_number) w tabeli; umożliwia to szybkie wyszukiwanie. Tabela może być powiązana z jedną lub kilkoma tabelami za pomocą jakiegoś klucza, takiego jak klucz obcy (dept_no), który odnosi się do równoważnego wiersza w innej tabeli.
Zgodnie ze specyfikacją Java Persistence 2.1, JPA dodaje obsługę generowania schematów, metod konwersji typów, użycia grafu encji w zapytaniach i operacji wyszukiwania, niezsynchronizowanego kontekstu trwałości, wywoływania procedur składowanych i wstrzykiwania do klas nasłuchiwania encji. Zawiera również ulepszenia języka zapytań Java Persistence, Criteria API oraz mapowanie zapytań natywnych.
Krótko mówiąc, robi wszystko, aby stworzyć iluzję, że nie ma części proceduralnej w kontaktach z relacyjnymi bazami danych i wszystko jest zorientowane obiektowo.
Wdrożenie JPA
JPA opisuje zarządzanie danymi relacyjnymi w aplikacji Java. Jest to specyfikacja i istnieje wiele jej implementacji. Niektóre popularne implementacje to Hibernate, EclipseLink i Apache OpenJPA. JPA definiuje metadane za pomocą adnotacji w klasach Java lub za pomocą plików konfiguracyjnych XML. Jednak do opisania metadanych możemy użyć zarówno XML, jak i adnotacji. W takim przypadku konfiguracja XML zastępuje adnotacje. Jest to uzasadnione, ponieważ adnotacje są zapisywane w kodzie Java, podczas gdy pliki konfiguracyjne XML są zewnętrzne względem kodu Java. Dlatego później, jeśli w ogóle, należy wprowadzić zmiany w metadanych; w przypadku konfiguracji opartej na adnotacjach wymaga bezpośredniego dostępu do kodu Java. To zawsze może nie być możliwe. W takim przypadku możemy zapisać nową lub zmienioną konfigurację metadanych w pliku XML bez żadnej wskazówki co do zmian w oryginalnym kodzie i nadal przynosić pożądany efekt. To jest zaleta korzystania z konfiguracji XML. Jednak konfiguracja oparta na adnotacjach jest wygodniejsza w użyciu i jest popularnym wyborem wśród programistów.
- Hibernacja jest popularną i najbardziej zaawansowaną spośród wszystkich implementacji JPA dzięki Red Hat. Wykorzystuje własne poprawki i dodatkowe funkcje, które mogą być używane oprócz implementacji JPA. Ma większą społeczność użytkowników i jest dobrze udokumentowany. Niektóre z dodatkowych własnościowych funkcji to obsługa wielu dzierżawców, dołączanie niepowiązanych jednostek w zapytaniach, zarządzanie znacznikami czasu i tak dalej.
- EclipseLink jest oparty na TopLink i jest referencyjną implementacją wersji JPA. Zapewnia standardowe funkcje JPA oprócz kilku interesujących własnościowych funkcji, takich jak obsługa wielu dzierżawców, obsługa zdarzeń zmian w bazie danych i tak dalej.
Korzystanie z JPA w programie Java SE
Aby użyć JPA w programie Java, potrzebujesz dostawcy JPA, takiego jak Hibernate lub EclipseLink, lub dowolnej innej biblioteki. Potrzebny jest również sterownik JDBC, który łączy się z określoną relacyjną bazą danych. Na przykład w poniższym kodzie użyliśmy następujących bibliotek:
- Dostawca: EclipseLink
- Sterownik JDBC: Sterownik JDBC dla MySQL (złącze/J)
Ustalimy relację między dwiema tabelami — Pracownik i Dział — jako jeden do jednego i jeden do wielu, jak pokazano na poniższym diagramie EER (patrz Rysunek 1).
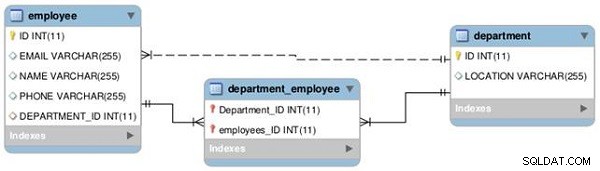
Rysunek 1: Relacje między tabelami
Pracownik tabela jest mapowana na klasę jednostki za pomocą adnotacji w następujący sposób:
package org.mano.jpademoapp;
import javax.persistence.*;
@Entity
@Table(name = "employee")
public class Employee {
@Id
private int id;
private String name;
private String phone;
private String email;
@OneToOne
private Department department;
public Employee() {
super();
}
public Employee(int id, String name, String phone,
String email) {
super();
this.id = id;
this.name = name;
this.phone = phone;
this.email = email;
}
public int getId() {
return id;
}
public void setId(int id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public String getPhone() {
return phone;
}
public void setPhone(String phone) {
this.phone = phone;
}
public String getEmail() {
return email;
}
public void setEmail(String email) {
this.email = email;
}
public Department getDepartment() {
return department;
}
public void setDepartment(Department department) {
this.department = department;
}
}
I departament tabela jest mapowana na klasę encji w następujący sposób:
package org.mano.jpademoapp;
import java.util.*;
import javax.persistence.*;
@Entity
@Table(name = "department")
public class Department {
@Id
private int id;
private String location;
@OneToMany
private List<Employee> employees = new ArrayList<>();
public Department() {
super();
}
public Department(int id, String location) {
super();
this.id = id;
this.location = location;
}
public int getId() {
return id;
}
public void setId(int id) {
this.id = id;
}
public String getLocation() {
return location;
}
public void setLocation(String location) {
this.location = location;
}
public List<Employee> getEmployees() {
return employees;
}
public void setEmployees(List<Employee> employees) {
this.employees = employees;
}
}
Plik konfiguracyjny persistence.xml , jest tworzony w META-INF informator. Ten plik zawiera konfigurację połączenia, taką jak używany sterownik JDBC, nazwa użytkownika i hasło dostępu do bazy danych oraz inne istotne informacje wymagane przez dostawcę JPA do nawiązania połączenia z bazą danych.
<?xml version="1.0" encoding="UTF-8"?>
<persistence version="2.1"
xmlns_xsi="https://www.w3.org/2001/XMLSchema-instance"
xsi_schemaLocation="https://xmlns.jcp.org/xml/ns/persistence
https://xmlns.jcp.org/xml/ns/persistence/persistence_2_1.xsd">
<persistence-unit name="JPADemoProject"
transaction-type="RESOURCE_LOCAL">
<class>org.mano.jpademoapp.Employee</class>
<class>org.mano.jpademoapp.Department</class>
<properties>
<property name="javax.persistence.jdbc.driver"
value="com.mysql.jdbc.Driver" />
<property name="javax.persistence.jdbc.url"
value="jdbc:mysql://localhost:3306/testdb" />
<property name="javax.persistence.jdbc.user"
value="root" />
<property name="javax.persistence.jdbc.password"
value="secret" />
<property name="javax.persistence.schema-generation
.database.action"
value="drop-and-create"/>
<property name="javax.persistence.schema-generation
.scripts.action"
value="drop-and-create"/>
<property name="eclipselink.ddl-generation"
value="drop-and-create-tables"/>
</properties>
</persistence-unit>
</persistence>
Jednostki nie utrzymują się same. Logika musi być zastosowana do manipulowania jednostkami, aby zarządzać ich trwałym cyklem życia. EntityManager Interfejs udostępniany przez JPA pozwala aplikacji zarządzać i wyszukiwać encje w relacyjnej bazie danych. Tworzymy obiekt zapytania za pomocą EntityManager do komunikacji z bazą danych. Aby uzyskać EntityManager dla danej bazy danych użyjemy obiektu, który implementuje EntityManagerFactory berło. Jest statyczny o nazwie createEntityManagerFactory , w sekcji Wytrwałość klasa, która zwraca EntityManagerFactory dla jednostki trwałości określonej jako String argument. W poniższej podstawowej implementacji zaimplementowaliśmy logikę.
package org.mano.jpademoapp;
import javax.persistence.EntityManager;
import javax.persistence.EntityManagerFactory;
import javax.persistence.Persistence;
public enum PersistenceManager {
INSTANCE;
private EntityManagerFactory emf;
private PersistenceManager() {
emf=Persistence.createEntityManagerFactory("JPADemoProject");
}
public EntityManager getEntityManager() {
return emf.createEntityManager();
}
public void close() {
emf.close();
}
}
Teraz jesteśmy gotowi do stworzenia głównego interfejsu aplikacji. Tutaj zaimplementowaliśmy tylko operację wstawiania ze względu na prostotę i ograniczenia przestrzeni.
package org.mano.jpademoapp;
import javax.persistence.EntityManager;
public class Main {
public static void main(String[] args) {
Department d1=new Department(11, "NY");
Department d2=new Department(22, "LA");
Employee e1=new Employee(111, "Peter",
"9876543210", "example@sqldat.com");
Employee e2=new Employee(222, "Ronin",
"993875630", "example@sqldat.com");
Employee e3=new Employee(333, "Kalpana",
"9876927410", "example@sqldat.com");
Employee e4=new Employee(444, "Marc",
"989374510", "example@sqldat.com");
Employee e5=new Employee(555, "Anik",
"987738750", "example@sqldat.com");
d1.getEmployees().add(e1);
d1.getEmployees().add(e3);
d1.getEmployees().add(e4);
d2.getEmployees().add(e2);
d2.getEmployees().add(e5);
EntityManager em=PersistenceManager
.INSTANCE.getEntityManager();
em.getTransaction().begin();
em.persist(e1);
em.persist(e2);
em.persist(e3);
em.persist(e4);
em.persist(e5);
em.persist(d1);
em.persist(d2);
em.getTransaction().commit();
em.close();
PersistenceManager.INSTANCE.close();
}
}
| Uwaga: Zapoznaj się z odpowiednią dokumentacją Java API, aby uzyskać szczegółowe informacje na temat interfejsów API używanych w poprzednim kodzie. |
Wniosek
Jak powinno być oczywiste, podstawowa terminologia kontekstu JPA i Persistence jest obszerniejsza niż wgląd podany tutaj, ale rozpoczęcie od szybkiego przeglądu jest lepsze niż długi, zawiły, brudny kod i jego konceptualne szczegóły. Jeśli masz niewielkie doświadczenie w programowaniu w rdzeniu JDBC, bez wątpienia docenisz, jak JPA może ułatwić Ci życie. Stopniowo zagłębimy się w JPA w miarę rozwoju kolejnych artykułów.