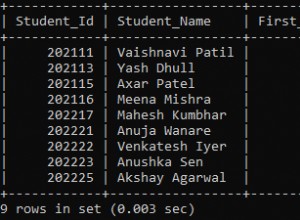
UUID
zwraca uniwersalny unikalny identyfikator
(miejmy nadzieję, że również unikalny, jeśli zostanie zaimportowany do innej bazy danych).
Cytując z dokumentacji MySQL (podkreślenie moje):
Z drugiej strony po prostu INT podstawowy klucz identyfikatora (np. AUTO_INCREMENT ) zwróci unikalną liczbę całkowitą dla konkretnej tabeli DB i DB, ale która nie jest uniwersalnie unikalna (więc jeśli importowane do innej bazy danych są szanse, że wystąpią konflikty kluczy podstawowych).
Pod względem wydajności nie powinno być żadnej zauważalnej różnicy przy użyciu auto-inkrementacji ponad UUID . Większość postów (w tym niektóre autorstwa autorów tej strony) jest tak opisana. Oczywiście UUID może zająć trochę więcej czasu (i miejsca), ale nie jest to wąskie gardło w większości (jeśli nie we wszystkich) przypadkach. Posiadanie kolumny jako Klucz podstawowy powinien sprawić, że oba wybory będą równe wydajności. Zobacz referencje poniżej:
- Do
UUID lub nie do UUID? - Mity,
GUIDvsAutoinkrementacja - Wydajność:
UUIDvsautomatyczne zwiększaniew cakephp-mysql UUIDwydajność w MySQL?- Klucze podstawowe:
IDs kontraGUIDs (kodowanie horroru)
(UUID vs automatyczne zwiększanie wyniki wydajności, zaadaptowane z Mity, GUID vs Autoinkrementacja
)

UUID plusy / minusy (na podstawie Klucze podstawowe:ID s kontra GUID s
)
Uwaga
Przeczytałbym uważnie wspomniane odniesienia i zdecydowałem, czy użyć UUID lub nie w zależności od mojego przypadku użycia. To powiedziawszy, w wielu przypadkach UUID s byłoby rzeczywiście lepsze. Na przykład można wygenerować UUID bez używania/dostępu do bazy danych w ogóle, a nawet bez użycia UUID s, które zostały wstępnie obliczone i/lub przechowywane w innym miejscu. Dodatkowo możesz łatwo uogólnić/zaktualizować schemat bazy danych i/lub schemat klastrowania bez martwienia się o ID łamie i powoduje konflikty.
Jeśli chodzi o możliwe kolizje, na przykład przy użyciu UUIDS v4 (losowo), prawdopodobieństwo znalezienia duplikatu w ciągu 103 bilionów identyfikatorów UUID w wersji 4 jest jeden na miliard.