Przede wszystkim „toxi” nie jest pojęciem standardowym. Zawsze określaj swoje warunki! Lub przynajmniej podaj odpowiednie linki.
A teraz do samego pytania...
Nie, będziesz mieć 3 stoły.
Jesteś na dobrej drodze, z wyjątkiem tego, że możesz użyć opartej na zbiorach natury SQL, aby „scalić” wiele z tych kroków. Na przykład oznaczanie elementu 1 tagami:„tag1”, „tag2” i „tag3” można wykonać w ten sposób...
INSERT IGNORE INTO tagmap (item_id, tag_id)
SELECT 1, tag_id FROM tags WHERE tag_text IN ('tag1', 'tag2', 'tag3');
IGNORE pozwala to się udać, nawet jeśli element jest już połączony z niektórymi z tych tagów.
Zakłada się, że wszystkie wymagane tagi są już w tags . Zakładając tag.tag_id jest automatyczne, możesz zrobić coś takiego, aby upewnić się, że:
INSERT IGNORE INTO tags (tag_text) VALUES ('tag1'), ('tag2'), ('tag3');
Nie ma magii. Jeśli „element jest połączony z określonym tagiem” jest fragmentem wiedzy, który chcesz nagrać, to będzie mieć jakąś fizyczną reprezentację w bazie danych.
Masz na myśli ponowne tagowanie elementów (nie modyfikowanie samych tagów)?
Aby usunąć wszystkie tagi, których nie ma na liście, wykonaj coś takiego:
DELETE FROM tagmap
WHERE
item_id = 1
AND tag_id NOT IN (
SELECT tag_id FROM tags
WHERE tag_text IN ('tag1', 'tag3')
);
Spowoduje to odłączenie elementu od wszystkich tagów z wyjątkiem „tag1” i „tag3”. Wykonaj INSERT powyżej i to DELETE jeden po drugim, aby „zakryć” zarówno dodawanie, jak i usuwanie tagów.
Możesz bawić się tym wszystkim w SQL Fiddle .
Prawidłowy. Potomny punkt końcowy FK nie wywoła akcji referencyjnej (takiej jak ON DELETE CASCADE), tylko rodzic to zrobi.
BTW, używasz tego schematu, ponieważ potrzebujesz dodatkowych pól w tags (obok tag_text ), Prawidłowy? Jeśli to zrobisz, nie utrata tych dodatkowych danych tylko dlatego, że zniknęły wszystkie połączenia, jest pożądanym zachowaniem.
Ale jeśli chcesz tylko tag_text , użyj prostszego schematu, w którym usunięcie wszystkich połączeń byłoby tym samym, co usunięcie samego tagu:
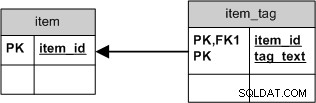
To nie tylko uprościłoby SQL, ale także zapewniłoby lepsze klastrowanie .
Na pierwszy rzut oka „toxi” może wyglądać na oszczędność miejsca, ale w praktyce może tak nie być, ponieważ wymaga dodatkowych tabel i indeksów (a tagi są zwykle krótkie).
Zmierz, zanim zdecydujesz się zrobić coś takiego. Wspomniany powyżej mój SQL Fiddle używa bardzo przemyślanej kolejności pól w tagmap PK, więc dane są zgrupowane w sposób bardzo przyjazny dla tego rodzaju liczenia (pamiętaj:Tabele InnoDB są zgrupowane
). Musisz mieć naprawdę ogromną liczbę przedmiotów (lub wymagać niezwykle wysokiej wydajności), zanim stanie się to problemem.
W każdym razie zmierz na realistycznych ilościach danych!