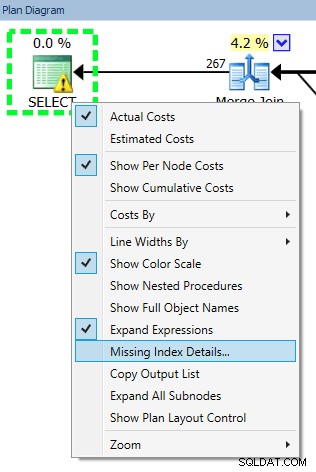
Kevin Kline (@kekline) i ja niedawno przeprowadziliśmy seminarium internetowe dotyczące dostrajania zapytań (właściwie jedno z serii), a jedną z rzeczy, które się pojawiły, jest tendencja ludzi do tworzenia brakujących indeksów, o których SQL Server mówi im, że będą dobra rzecz™ . Mogą dowiedzieć się o tych brakujących indeksach z doradcy dostrajania aparatu bazy danych (DTA), brakujących indeksów DMV lub planu wykonania wyświetlanego w Management Studio lub Plan Explorer (z których wszystkie przekazują informacje z dokładnie tego samego miejsca):
Problem z tworzeniem tego indeksu na ślepo polega na tym, że SQL Server uznał, że jest on przydatny dla konkretnego zapytania (lub kilku zapytań), ale całkowicie i jednostronnie ignoruje resztę obciążenia. Jak wszyscy wiemy, indeksy nie są „darmowe” – płacisz za indeksy zarówno w magazynie surowym, jak i konserwację wymaganą przy operacjach DML. W przypadku dużego obciążenia związanego z zapisem nie ma sensu dodawanie indeksu, który pomaga nieco zwiększyć wydajność pojedynczego zapytania, zwłaszcza jeśli to zapytanie nie jest często uruchamiane. W takich przypadkach bardzo ważne może być zrozumienie ogólnego obciążenia pracą i znalezienie odpowiedniej równowagi między zwiększaniem wydajności zapytań a nie płaceniem za to zbyt wiele w zakresie utrzymania indeksu.
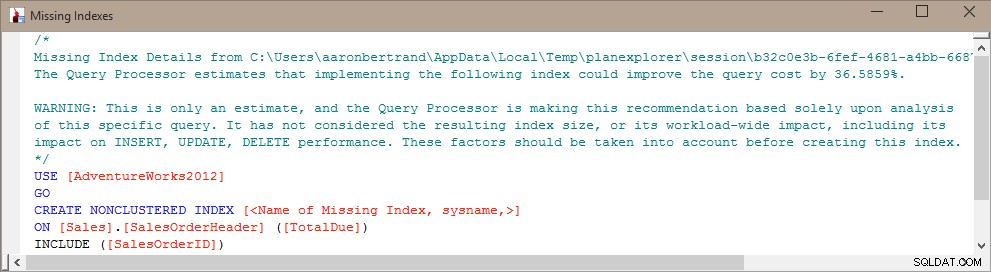
Pomysł, jaki wpadłem, polegał na „zmieszaniu” informacji z brakujących indeksów DMV, statystyk użycia indeksu DMV i informacji o planach zapytań, aby określić, jaki rodzaj salda obecnie istnieje i jak dodanie indeksu może się ogólnie zakończyć.
Brakujące indeksy
Najpierw przyjrzyjmy się brakującym indeksom, które obecnie sugeruje SQL Server:
SELECT d.[object_id], s = OBJECT_SCHEMA_NAME(d.[object_id]), o = OBJECT_NAME(d.[object_id]), d.equality_columns, d.inequality_columns, d.included_columns, s.unique_compiles, s.user_seeks, s.last_user_seek, s.user_scans, s.last_user_scan INTO #candidates FROM sys.dm_db_missing_index_details AS d INNER JOIN sys.dm_db_missing_index_groups AS g ON d.index_handle = g.index_handle INNER JOIN sys.dm_db_missing_index_group_stats AS s ON g.index_group_handle = s.group_handle WHERE d.database_id = DB_ID() AND OBJECTPROPERTY(d.[object_id], 'IsMsShipped') = 0;
Pokazuje tabele i kolumny, które byłyby przydatne w indeksie, ile kompilacji/szukań/skanowań zostałoby użytych i kiedy ostatnie takie zdarzenie miało miejsce dla każdego potencjalnego indeksu. Możesz także uwzględnić kolumny, takie jak s.avg_total_user_cost i s.avg_user_impact jeśli chcesz użyć tych liczb do ustalenia priorytetów.
Operacje planu
Następnie przyjrzyjmy się operacjom użytym we wszystkich planach, które zbuforowaliśmy względem obiektów, które zostały zidentyfikowane przez nasze brakujące indeksy.
CREATE TABLE #planops
(
o INT,
i INT,
h VARBINARY(64),
uc INT,
Scan_Ops INT,
Seek_Ops INT,
Update_Ops INT
);
DECLARE @sql NVARCHAR(MAX) = N'';
SELECT @sql += N'
UNION ALL SELECT o,i,h,uc,Scan_Ops,Seek_Ops,Update_Ops
FROM
(
SELECT o = ' + RTRIM([object_id]) + ',
i = ' + RTRIM(index_id) +',
h = pl.plan_handle,
uc = pl.usecounts,
Scan_Ops = p.query_plan.value(''count(//RelOp[@LogicalOp = ''''Index Scan'''''
+ ' or @LogicalOp = ''''Clustered Index Scan'''']/*/'
+ 'Object[@Index=''''' + QUOTENAME(name) + '''''])'', ''int''),
Seek_Ops = p.query_plan.value(''count(//RelOp[@LogicalOp = ''''Index Seek'''''
+ ' or @LogicalOp = ''''Clustered Index Seek'''']/*/'
+ 'Object[@Index=''''' + QUOTENAME(name) + '''''])'', ''int''),
Update_Ops = p.query_plan.value(''count(//Update/Object[@Index='''''
+ QUOTENAME(name) + '''''])'', ''int'')
FROM sys.dm_exec_cached_plans AS pl
CROSS APPLY sys.dm_exec_query_plan(pl.plan_handle) AS p
WHERE p.dbid = DB_ID()
AND p.query_plan IS NOT NULL
) AS x
WHERE Scan_Ops + Seek_Ops + Update_Ops > 0'
FROM sys.indexes AS i
WHERE i.index_id > 0
AND EXISTS (SELECT 1 FROM #candidates WHERE [object_id] = i.[object_id]);
SET @sql = ';WITH xmlnamespaces (DEFAULT '
+ 'N''https://schemas.microsoft.com/sqlserver/2004/07/showplan'')
' + STUFF(@sql, 1, 16, '');
INSERT #planops EXEC sp_executesql @sql; Przyjaciel na dba.SE, Mikael Eriksson, zasugerował następujące dwa zapytania, które w większym systemie będą działać znacznie lepiej niż zapytanie XML / UNION, które skleiłem powyżej, więc możesz najpierw z nimi poeksperymentować. Jego końcowy komentarz brzmiał, że „nie dziwi fakt, że mniej XML to dobra rzecz dla wydajności. :)” Rzeczywiście.
-- alternative #1
with xmlnamespaces (default 'https://schemas.microsoft.com/sqlserver/2004/07/showplan')
insert #planops
select o,i,h,uc,Scan_Ops,Seek_Ops,Update_Ops
from
(
select o = i.object_id,
i = i.index_id,
h = pl.plan_handle,
uc = pl.usecounts,
Scan_Ops = p.query_plan.value('count(//RelOp[@LogicalOp
= ("Index Scan", "Clustered Index Scan")]/*/Object[@Index = sql:column("i2.name")])', 'int'),
Seek_Ops = p.query_plan.value('count(//RelOp[@LogicalOp
= ("Index Seek", "Clustered Index Seek")]/*/Object[@Index = sql:column("i2.name")])', 'int'),
Update_Ops = p.query_plan.value('count(//Update/Object[@Index = sql:column("i2.name")])', 'int')
from sys.indexes as i
cross apply (select quotename(i.name) as name) as i2
cross apply sys.dm_exec_cached_plans as pl
cross apply sys.dm_exec_query_plan(pl.plan_handle) AS p
where exists (select 1 from #candidates as c where c.[object_id] = i.[object_id])
and p.query_plan.exist('//Object[@Index = sql:column("i2.name")]') = 1
and p.[dbid] = db_id()
and i.index_id > 0
) as T
where Scan_Ops + Seek_Ops + Update_Ops > 0;
-- alternative #2
with xmlnamespaces (default 'https://schemas.microsoft.com/sqlserver/2004/07/showplan')
insert #planops
select o = coalesce(T1.o, T2.o),
i = coalesce(T1.i, T2.i),
h = coalesce(T1.h, T2.h),
uc = coalesce(T1.uc, T2.uc),
Scan_Ops = isnull(T1.Scan_Ops, 0),
Seek_Ops = isnull(T1.Seek_Ops, 0),
Update_Ops = isnull(T2.Update_Ops, 0)
from
(
select o = i.object_id,
i = i.index_id,
h = t.plan_handle,
uc = t.usecounts,
Scan_Ops = sum(case when t.LogicalOp in ('Index Scan', 'Clustered Index Scan') then 1 else 0 end),
Seek_Ops = sum(case when t.LogicalOp in ('Index Seek', 'Clustered Index Seek') then 1 else 0 end)
from (
select
r.n.value('@LogicalOp', 'varchar(100)') as LogicalOp,
o.n.value('@Index', 'sysname') as IndexName,
pl.plan_handle,
pl.usecounts
from sys.dm_exec_cached_plans as pl
cross apply sys.dm_exec_query_plan(pl.plan_handle) AS p
cross apply p.query_plan.nodes('//RelOp') as r(n)
cross apply r.n.nodes('*/Object') as o(n)
where p.dbid = db_id()
and p.query_plan is not null
) as t
inner join sys.indexes as i
on t.IndexName = quotename(i.name)
where t.LogicalOp in ('Index Scan', 'Clustered Index Scan', 'Index Seek', 'Clustered Index Seek')
and exists (select 1 from #candidates as c where c.object_id = i.object_id)
group by i.object_id,
i.index_id,
t.plan_handle,
t.usecounts
) as T1
full outer join
(
select o = i.object_id,
i = i.index_id,
h = t.plan_handle,
uc = t.usecounts,
Update_Ops = count(*)
from (
select
o.n.value('@Index', 'sysname') as IndexName,
pl.plan_handle,
pl.usecounts
from sys.dm_exec_cached_plans as pl
cross apply sys.dm_exec_query_plan(pl.plan_handle) AS p
cross apply p.query_plan.nodes('//Update') as r(n)
cross apply r.n.nodes('Object') as o(n)
where p.dbid = db_id()
and p.query_plan is not null
) as t
inner join sys.indexes as i
on t.IndexName = quotename(i.name)
where exists
(
select 1 from #candidates as c where c.[object_id] = i.[object_id]
)
and i.index_id > 0
group by i.object_id,
i.index_id,
t.plan_handle,
t.usecounts
) as T2
on T1.o = T2.o and
T1.i = T2.i and
T1.h = T2.h and
T1.uc = T2.uc;
Teraz w #planops tabela masz kilka wartości dla plan_handle abyście mogli przejść i zbadać każdy z indywidualnych planów w grze w odniesieniu do obiektów, które zostały zidentyfikowane jako pozbawione jakiegoś użytecznego indeksu. W tej chwili nie będziemy go do tego używać, ale możesz łatwo odnieść się do tego za pomocą:
SELECT OBJECT_SCHEMA_NAME(po.o), OBJECT_NAME(po.o), po.uc,po.Scan_Ops,po.Seek_Ops,po.Update_Ops, p.query_plan FROM #planops AS po CROSS APPLY sys.dm_exec_query_plan(po.h) AS p;
Teraz możesz kliknąć dowolny z planów wyjściowych, aby zobaczyć, co aktualnie robią w stosunku do twoich obiektów. Zwróć uwagę, że niektóre plany zostaną powtórzone, ponieważ plan może mieć wiele operatorów, które odwołują się do różnych indeksów w tej samej tabeli.
Statystyki wykorzystania indeksu
Następnie przyjrzyjmy się statystykom wykorzystania indeksu, abyśmy mogli zobaczyć, jaka rzeczywista aktywność jest obecnie wykonywana w odniesieniu do naszych tabel kandydatów (a w szczególności aktualizacji).
SELECT [object_id], index_id, user_seeks, user_scans, user_lookups, user_updates INTO #indexusage FROM sys.dm_db_index_usage_stats AS s WHERE database_id = DB_ID() AND EXISTS (SELECT 1 FROM #candidates WHERE [object_id] = s.[object_id]);
Nie przejmuj się, jeśli bardzo niewiele planów w pamięci podręcznej lub żaden z nich nie pokaże aktualizacji dla określonego indeksu, nawet jeśli statystyki wykorzystania indeksu pokazują, że indeksy te zostały zaktualizowane. Oznacza to po prostu, że plany aktualizacji nie znajdują się obecnie w pamięci podręcznej, co może wynikać z różnych powodów – na przykład może to być bardzo duże obciążenie pracą, które są przestarzałe lub wszystkie są pojedyncze- używaj i optimize for ad hoc workloads jest włączony.
Łączenie wszystkiego w całość
Poniższe zapytanie pokaże, dla każdego sugerowanego brakującego indeksu, liczbę odczytów, które indeks mógł wspomóc, liczbę zapisów i odczytów, które zostały aktualnie przechwycone w stosunku do istniejących indeksów, ich stosunek, liczbę planów powiązanych z ten obiekt i całkowita liczba zastosowań dla tych planów:
;WITH x AS
(
SELECT
c.[object_id],
potential_read_ops = SUM(c.user_seeks + c.user_scans),
[write_ops] = SUM(iu.user_updates),
[read_ops] = SUM(iu.user_scans + iu.user_seeks + iu.user_lookups),
[write:read ratio] = CONVERT(DECIMAL(18,2), SUM(iu.user_updates)*1.0 /
SUM(iu.user_scans + iu.user_seeks + iu.user_lookups)),
current_plan_count = po.h,
current_plan_use_count = po.uc
FROM
#candidates AS c
LEFT OUTER JOIN
#indexusage AS iu
ON c.[object_id] = iu.[object_id]
LEFT OUTER JOIN
(
SELECT o, h = COUNT(h), uc = SUM(uc)
FROM #planops GROUP BY o
) AS po
ON c.[object_id] = po.o
GROUP BY c.[object_id], po.h, po.uc
)
SELECT [object] = QUOTENAME(c.s) + '.' + QUOTENAME(c.o),
c.equality_columns,
c.inequality_columns,
c.included_columns,
x.potential_read_ops,
x.write_ops,
x.read_ops,
x.[write:read ratio],
x.current_plan_count,
x.current_plan_use_count
FROM #candidates AS c
INNER JOIN x
ON c.[object_id] = x.[object_id]
ORDER BY x.[write:read ratio];
Jeśli twój stosunek zapisu:odczytu do tych indeksów jest już> 1 (lub> 10!), myślę, że daje to powód do wstrzymania się przed ślepym utworzeniem indeksu, który mógłby tylko zwiększyć ten stosunek. Liczba potential_read_ops pokazane jednak może to kompensować, gdy liczba staje się większa. Jeśli potential_read_ops liczba jest bardzo mała, prawdopodobnie chcesz całkowicie zignorować zalecenie, zanim jeszcze zadasz sobie trud zbadania innych wskaźników – więc możesz dodać WHERE klauzulę o odfiltrowaniu niektórych z tych zaleceń.
Kilka uwag:
- Są to operacje odczytu i zapisu, a nie indywidualnie mierzone odczyty i zapisy 8K stron.
- Wskaźnik i porównania mają głównie charakter edukacyjny; Równie dobrze mogłoby się zdarzyć, że 10 000 000 operacji zapisu miało wpływ na pojedynczy wiersz, podczas gdy 10 operacji odczytu mogło mieć znacznie większy wpływ. Ma to jedynie charakter orientacyjny i zakłada, że operacje odczytu i zapisu są ważone mniej więcej tak samo.
- Możesz również użyć lekkich odmian niektórych z tych zapytań, aby dowiedzieć się – poza brakującymi indeksami zalecanymi przez SQL Server – ile z Twoich obecnych indeksów jest marnotrawstwem. Istnieje wiele pomysłów na ten temat w Internecie, w tym ten post Paula Randala (@PaulRandal).
Mam nadzieję, że daje to pewne pomysły na uzyskanie lepszego wglądu w zachowanie twojego systemu, zanim zdecydujesz się dodać indeks, który kazał ci utworzyć jakieś narzędzie. Mogłem to stworzyć jako jedno ogromne zapytanie, ale myślę, że poszczególne części dadzą ci kilka króliczych nor do zbadania, jeśli sobie tego życzysz.
Inne notatki
Możesz również rozszerzyć to, aby przechwycić aktualne metryki rozmiaru, szerokość tabeli i liczbę bieżących wierszy (a także wszelkie prognozy dotyczące przyszłego wzrostu); może to dać dobre wyobrażenie o tym, ile miejsca zajmie nowy indeks, co może stanowić problem w zależności od środowiska. Mogę omówić to w przyszłym poście.
Oczywiście musisz pamiętać, że te wskaźniki są tylko tak przydatne, jak dyktuje Twój czas pracy bez przestojów. DMV są usuwane po ponownym uruchomieniu (a czasami w innych, mniej uciążliwych scenariuszach), więc jeśli uważasz, że te informacje będą przydatne przez dłuższy czas, wykonywanie okresowych migawek może być czymś, co warto rozważyć.