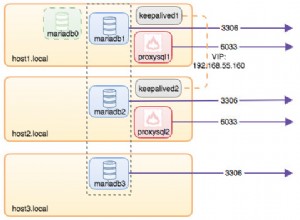
W przypadku implementacji UDF Levenshtein Distance algorytm, który możesz chcieć sprawdzić "codejanitor.com:Levenshtein Distance jako funkcja przechowywana w MySQL ":
CREATE FUNCTION LEVENSHTEIN (s1 VARCHAR(255), s2 VARCHAR(255))
RETURNS INT
DETERMINISTIC
BEGIN
DECLARE s1_len, s2_len, i, j, c, c_temp, cost INT;
DECLARE s1_char CHAR;
DECLARE cv0, cv1 VARBINARY(256);
SET s1_len = CHAR_LENGTH(s1), s2_len = CHAR_LENGTH(s2), cv1 = 0x00, j = 1, i = 1, c = 0;
IF s1 = s2 THEN
RETURN 0;
ELSEIF s1_len = 0 THEN
RETURN s2_len;
ELSEIF s2_len = 0 THEN
RETURN s1_len;
ELSE
WHILE j <= s2_len DO
SET cv1 = CONCAT(cv1, UNHEX(HEX(j))), j = j + 1;
END WHILE;
WHILE i <= s1_len DO
SET s1_char = SUBSTRING(s1, i, 1), c = i, cv0 = UNHEX(HEX(i)), j = 1;
WHILE j <= s2_len DO
SET c = c + 1;
IF s1_char = SUBSTRING(s2, j, 1) THEN SET cost = 0; ELSE SET cost = 1; END IF;
SET c_temp = CONV(HEX(SUBSTRING(cv1, j, 1)), 16, 10) + cost;
IF c > c_temp THEN SET c = c_temp; END IF;
SET c_temp = CONV(HEX(SUBSTRING(cv1, j+1, 1)), 16, 10) + 1;
IF c > c_temp THEN SET c = c_temp; END IF;
SET cv0 = CONCAT(cv0, UNHEX(HEX(c))), j = j + 1;
END WHILE;
SET cv1 = cv0, i = i + 1;
END WHILE;
END IF;
RETURN c;
END
Teraz zbudujmy przypadek testowy, korzystając z danych podanych w pytaniu:
CREATE TABLE table_a (name varchar(20));
CREATE TABLE table_b (name varchar(20));
INSERT INTO table_a VALUES('Olde School');
INSERT INTO table_a VALUES('New School');
INSERT INTO table_a VALUES('Other, C.S. School');
INSERT INTO table_a VALUES('Main School');
INSERT INTO table_a VALUES('Too Cool for School');
INSERT INTO table_b VALUES('Old School');
INSERT INTO table_b VALUES('New ES');
INSERT INTO table_b VALUES('Other School');
INSERT INTO table_b VALUES('Main School');
INSERT INTO table_b VALUES('Hardknocks School');
Następnie:
SELECT *
FROM table_a a
LEFT JOIN table_b b ON (a.name = b.name);
Oczywiście zwraca dopasowanie, w którym nazwy szkół są dokładnie takie same:
+---------------------+-------------+
| name | name |
+---------------------+-------------+
| Olde School | NULL |
| New School | NULL |
| Other, C.S. School | NULL |
| Main School | Main School |
| Too Cool for School | NULL |
+---------------------+-------------+
5 rows in set (0.00 sec)
Teraz możemy spróbować użyć LEVENSHTEIN funkcja zwracająca nazwy szkół, które mają odległość edycji
2 znaki lub mniej:
SELECT *
FROM table_a a
LEFT JOIN table_b b ON (LEVENSHTEIN(a.name, b.name) <= 2);
+---------------------+-------------+
| name | name |
+---------------------+-------------+
| Olde School | Old School |
| New School | NULL |
| Other, C.S. School | NULL |
| Main School | Main School |
| Too Cool for School | NULL |
+---------------------+-------------+
5 rows in set (0.08 sec)
Teraz używam <= 3 jako edycję progu odległości:
SELECT *
FROM table_a a
LEFT JOIN table_b b ON (LEVENSHTEIN(a.name, b.name) <= 3);
Otrzymujemy następujący wynik:
+---------------------+--------------+
| name | name |
+---------------------+--------------+
| Olde School | Old School |
| Olde School | Other School |
| New School | Old School |
| Other, C.S. School | NULL |
| Main School | Main School |
| Too Cool for School | NULL |
+---------------------+--------------+
6 rows in set (0.06 sec)
Zwróć uwagę, jak tym razem Olde School pasował również do Other School i New School dopasowane Olde School także. Są one prawdopodobnie fałszywie pozytywne i pokazują, że zdefiniowanie progu jest bardzo ważne, aby uniknąć błędnych dopasowań.
Jedną z powszechnych technik rozwiązywania tego problemu jest uwzględnienie długości strun podczas stosowania progu. W rzeczywistości witryna, która Cytowałem dla tej implementacji
zapewnia również LEVENSHTEIN_RATIO funkcja, która zwraca stosunek (jako procent) różnicy edycji na podstawie długości ciągów.