W moim ostatnim poście pokazałem, że przy małych ilościach TVP zoptymalizowany pod kątem pamięci może zapewnić znaczne korzyści w zakresie wydajności typowych wzorców zapytań.
Aby przetestować na nieco większą skalę, wykonałem kopię SalesOrderDetailEnlarged tabeli, którą rozszerzyłem do około 5 000 000 wierszy dzięki temu skryptowi autorstwa Jonathana Kehayiasa (blog | @SQLPoolBoy)).
DROP TABLE dbo.SalesOrderDetailEnlarged; GO SELECT * INTO dbo.SalesOrderDetailEnlarged FROM AdventureWorks2012.Sales.SalesOrderDetailEnlarged; -- 4,973,997 rows CREATE CLUSTERED INDEX PK_SODE ON dbo.SalesOrderDetailEnlarged(SalesOrderID, SalesOrderDetailID);
Stworzyłem również trzy wersje tego stołu w pamięci, z których każda ma inną liczbę wiader (łowienie „sweet spot”) – 16 384, 131 072 i 1 048 576. (Możesz użyć zaokrąglonych liczb, ale i tak zostaną one zaokrąglone do następnej potęgi 2.) Przykład:
CREATE TABLE [dbo].[SalesOrderDetailEnlarged_InMem_16K] -- and _131K and _1MM ( [SalesOrderID] [int] NOT NULL, [SalesOrderDetailID] [int] NOT NULL, [CarrierTrackingNumber] [nvarchar](25) COLLATE SQL_Latin1_General_CP1_CI_AS NULL, [OrderQty] [smallint] NOT NULL, [ProductID] [int] NOT NULL, [SpecialOfferID] [int] NOT NULL, [UnitPrice] [money] NOT NULL, [UnitPriceDiscount] [money] NOT NULL, [LineTotal] [numeric](38, 6) NOT NULL, [rowguid] [uniqueidentifier] NOT NULL, [ModifiedDate] [datetime] NOT NULL PRIMARY KEY NONCLUSTERED HASH ( [SalesOrderID], [SalesOrderDetailID] ) WITH ( BUCKET_COUNT = 16384) -- and 131072 and 1048576 ) WITH ( MEMORY_OPTIMIZED = ON , DURABILITY = SCHEMA_AND_DATA ); GO INSERT dbo.SalesOrderDetailEnlarged_InMem_16K SELECT * FROM dbo.SalesOrderDetailEnlarged; INSERT dbo.SalesOrderDetailEnlarged_InMem_131K SELECT * FROM dbo.SalesOrderDetailEnlarged; INSERT dbo.SalesOrderDetailEnlarged_InMem_1MM SELECT * FROM dbo.SalesOrderDetailEnlarged; GO
Zauważ, że zmieniłem rozmiar wiadra z poprzedniego przykładu (256). Tworząc tabelę, chcesz wybrać „najlepsze miejsce” dla rozmiaru segmentu — chcesz zoptymalizować indeks skrótu dla wyszukiwania punktów, co oznacza, że chcesz mieć jak najwięcej segmentów z jak najmniejszą liczbą wierszy w każdym segmencie. Oczywiście, jeśli utworzysz ~5 milionów wiader (ponieważ w tym przypadku może to niezbyt dobry przykład, istnieje ~5 milionów unikalnych kombinacji wartości), będziesz miał do czynienia z pewnymi kompromisami związanymi z wykorzystaniem pamięci i wyrzucaniem śmieci. Jeśli jednak spróbujesz upchnąć ~5 milionów unikalnych wartości w 256 segmentach, również napotkasz pewne problemy. W każdym razie ta dyskusja wykracza daleko poza zakres moich testów w tym poście.
Aby przetestować tabelę standardową, wykonałem podobne procedury składowane, jak w poprzednich testach:
CREATE PROCEDURE dbo.SODE_InMemory
@InMemory dbo.InMemoryTVP READONLY
AS
BEGIN
SET NOCOUNT ON;
DECLARE @tn NVARCHAR(25);
SELECT @tn = CarrierTrackingNumber
FROM dbo.SalesOrderDetailEnlarged AS sode
WHERE EXISTS (SELECT 1 FROM @InMemory AS t
WHERE sode.SalesOrderID = t.Item);
END
GO
CREATE PROCEDURE dbo.SODE_Classic
@Classic dbo.ClassicTVP READONLY
AS
BEGIN
SET NOCOUNT ON;
DECLARE @tn NVARCHAR(25);
SELECT @tn = CarrierTrackingNumber
FROM dbo.SalesOrderDetailEnlarged AS sode
WHERE EXISTS (SELECT 1 FROM @Classic AS t
WHERE sode.SalesOrderID = t.Item);
END
GO Więc najpierw przyjrzyjmy się planom dla, powiedzmy, 1000 wierszy wstawianych do zmiennych tabeli, a następnie uruchamianiu procedur:
DECLARE @InMemory dbo.InMemoryTVP; INSERT @InMemory SELECT TOP (1000) SalesOrderID FROM dbo.SalesOrderDetailEnlarged GROUP BY SalesOrderID ORDER BY NEWID(); DECLARE @Classic dbo.ClassicTVP; INSERT @Classic SELECT Item FROM @InMemory; EXEC dbo.SODE_Classic @Classic = @Classic; EXEC dbo.SODE_InMemory @InMemory = @InMemory;
Tym razem widzimy, że w obu przypadkach optymalizator wybrał wyszukiwanie indeksu klastrowego względem tabeli bazowej i sprzężenie zagnieżdżonych pętli względem TVP. Niektóre wskaźniki kosztów są różne, ale poza tym plany są dość podobne:
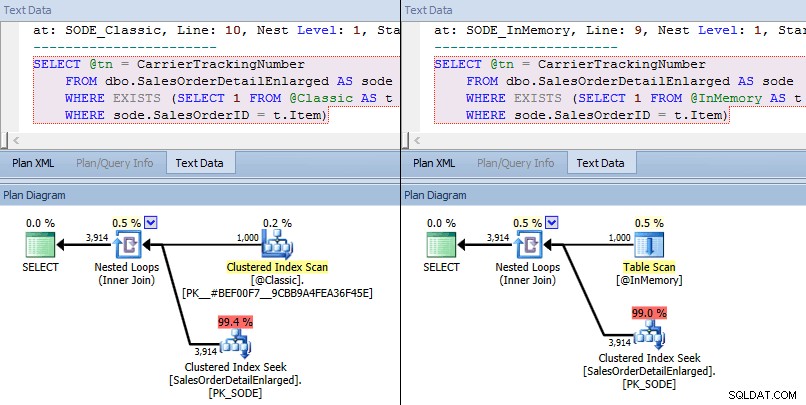 Podobne plany dla TVP w pamięci i klasycznej TVP na większą skalę
Podobne plany dla TVP w pamięci i klasycznej TVP na większą skalę
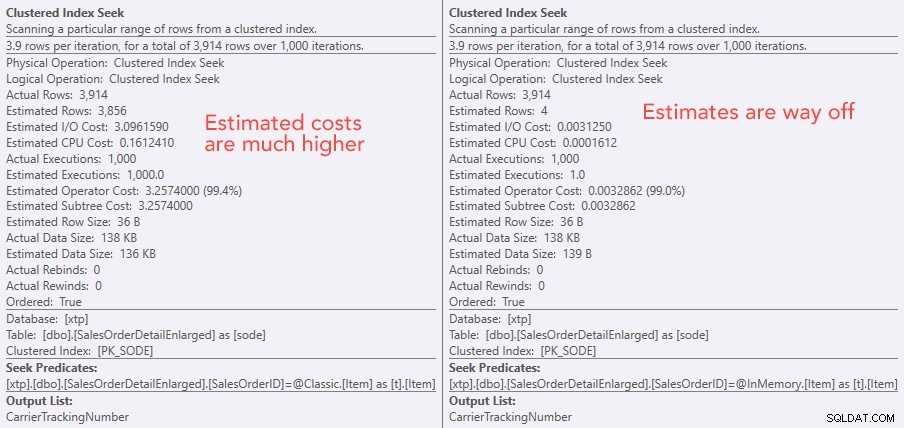 Porównanie kosztów operatora wyszukiwania – po lewej klasyczny, po prawej w pamięci
Porównanie kosztów operatora wyszukiwania – po lewej klasyczny, po prawej w pamięci
Bezwzględna wartość kosztów sprawia, że wydaje się, iż klasyczna TVP byłaby dużo mniej wydajna niż In-Memory TVP. Ale zastanawiałem się, czy byłoby to prawdą w praktyce (zwłaszcza, że szacowana liczba egzekucji po prawej stronie wydawała się podejrzana), więc oczywiście przeprowadziłem kilka testów. Postanowiłem sprawdzić 100, 1000 i 2000 wartości, które mają zostać wysłane do procedury.
DECLARE @values INT = 100; -- 1000, 2000 DECLARE @Classic dbo.ClassicTVP; DECLARE @InMemory dbo.InMemoryTVP; INSERT @Classic(Item) SELECT TOP (@values) SalesOrderID FROM dbo.SalesOrderDetailEnlarged GROUP BY SalesOrderID ORDER BY NEWID(); INSERT @InMemory(Item) SELECT Item FROM @Classic; DECLARE @i INT = 1; SELECT SYSDATETIME(); WHILE @i <= 10000 BEGIN EXEC dbo.SODE_Classic @Classic = @Classic; SET @i += 1; END SELECT SYSDATETIME(); SET @i = 1; WHILE @i <= 10000 BEGIN EXEC dbo.SODE_InMemory @InMemory = @InMemory; SET @i += 1; END SELECT SYSDATETIME();
Wyniki wydajności pokazują, że przy większej liczbie wyszukiwań punktów użycie In-Memory TVP prowadzi do nieco mniejszych zwrotów, za każdym razem nieco wolniej:
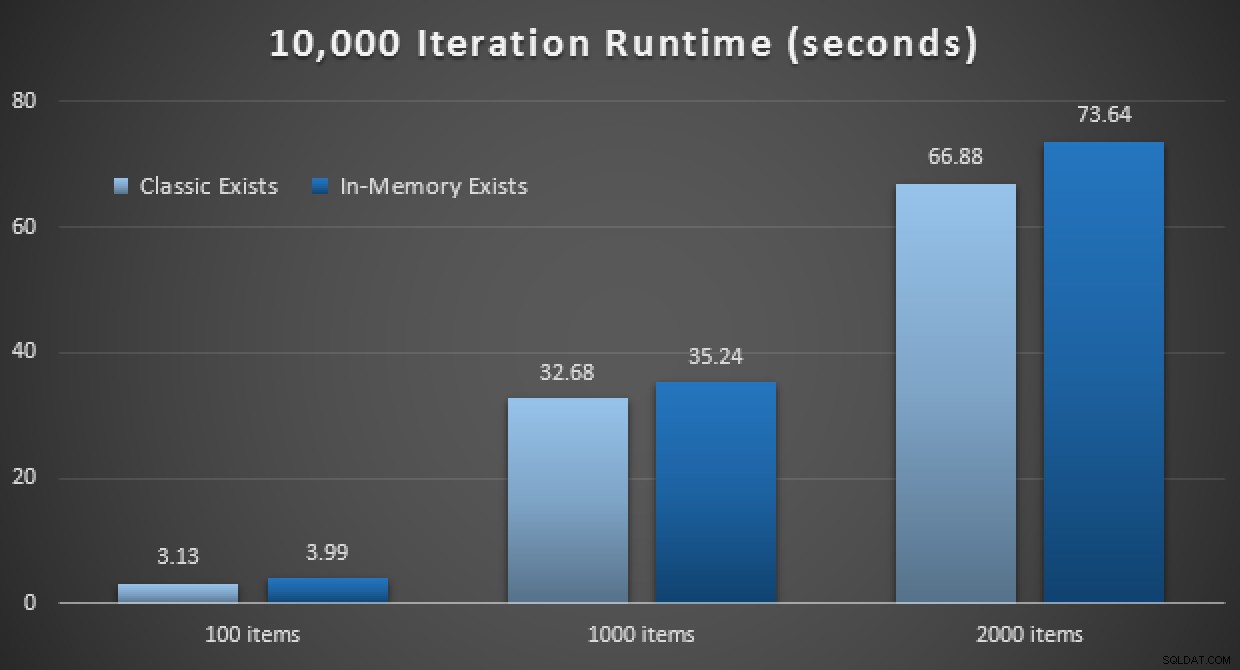
Wyniki 10 000 egzekucji przy użyciu programów TVP klasycznych i zapisanych w pamięci
Tak więc, wbrew wrażeniu, jakie można było odnieść z mojego poprzedniego postu, korzystanie z TVP w pamięci niekoniecznie jest korzystne we wszystkich przypadkach.
Wcześniej przyjrzałem się również natywnie skompilowanym procedurom składowanym i tabelom w pamięci, w połączeniu z programami TVP w pamięci. Czy to może tu coś zmienić? Spoiler:absolutnie nie. Stworzyłem trzy takie procedury:
CREATE PROCEDURE [dbo].[SODE_Native_InMem_16K] -- and _131K and _1MM
@InMemory dbo.InMemoryTVP READONLY
WITH NATIVE_COMPILATION, SCHEMABINDING, EXECUTE AS OWNER
AS
BEGIN ATOMIC WITH (TRANSACTION ISOLATION LEVEL = SNAPSHOT, LANGUAGE = N'us_english');
DECLARE @tn NVARCHAR(25);
SELECT @tn = CarrierTrackingNumber
FROM dbo.SalesOrderDetailEnlarged_InMem_16K AS sode -- and _131K and _1MM
INNER JOIN @InMemory AS t -- no EXISTS allowed here
ON sode.SalesOrderID = t.Item;
END
GO Kolejny spoiler:nie byłem w stanie przeprowadzić tych 9 testów z liczbą iteracji 10 000 – trwało to zdecydowanie za długo. Zamiast tego zapętliłem się i uruchomiłem każdą procedurę 10 razy, wykonałem ten zestaw testów 10 razy i wziąłem średnią. Oto wyniki:
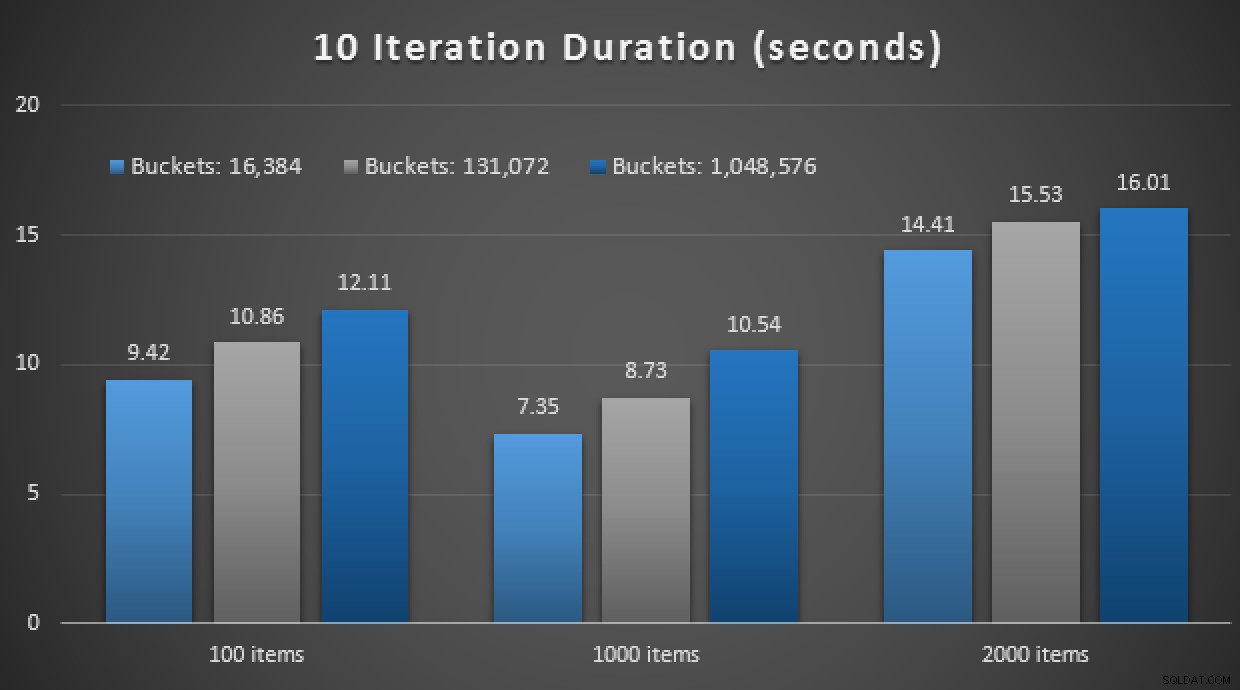
Wyniki 10 wykonań przy użyciu programów TVP w pamięci i natywnie skompilowanych procedury
Ogólnie rzecz biorąc, ten eksperyment był raczej rozczarowujący. Patrząc na samą wielkość różnicy, w przypadku tabeli na dysku, średnie wywołanie procedury składowanej zostało wykonane w ciągu średnio 0,0036 sekundy. Jednak gdy wszystko korzystało z technologii w pamięci, średnie wywołanie procedury składowanej trwało 1,1662 sekundy. Ała . Jest bardzo prawdopodobne, że wybrałem właśnie słaby przypadek użycia do ogólnej demonstracji, ale w tamtym czasie wydawało się to intuicyjną „pierwszą próbą”.
Wniosek
Jest o wiele więcej do przetestowania wokół tego scenariusza i mam więcej wpisów na blogu do śledzenia. Nie zidentyfikowałem jeszcze optymalnego przypadku użycia dla TVP in-memory na większą skalę, ale mam nadzieję, że ten post służy jako przypomnienie, że nawet jeśli rozwiązanie wydaje się optymalne w jednym przypadku, nigdy nie można bezpiecznie założyć, że jest ono równie przydatne do różnych scenariuszy. Dokładnie tak należy podchodzić do OLTP w pamięci:jako rozwiązanie z wąskim zestawem przypadków użycia, które bezwzględnie muszą zostać zweryfikowane przed wdrożeniem w środowisku produkcyjnym.