Naturalnym paradygmatem w teorii przechowywania XBRL w bazie danych byłby OLAP, ponieważ XBRL dotyczy kostek danych. OLAP na górze relacyjnej bazy danych nazywa się ROLAP.
Nie jest to trywialny problem, ponieważ fakty zaczerpnięte z dużej liczby taksonomii mogą tworzyć bardzo dużą i rzadką kostkę (dla zgłoszeń SEC to ponad 10 000 wymiarów), a także dlatego, że stworzenie schematu SQL wymaga znajomości taksonomii przed jakimkolwiek importem. Jeśli pojawią się nowe taksonomie, trzeba wszystko powtórzyć. To nie sprawia, że relacyjne bazy danych są odpowiednie jako ogólne rozwiązanie.
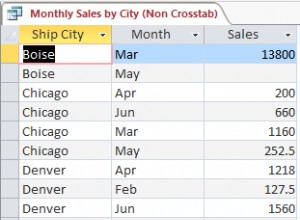
Jeśli zgłoszenia mają tę samą taksonomię, a taksonomia jest bardzo prosta (na przykład:niezbyt wiele wymiarów), możliwe jest wymyślenie mapowania ad-hoc, aby przechowywać wszystkie fakty w jednej tabeli z wieloma wierszami w ROLAP sens (fakty do wierszy, aspekty do kolumn). Niektórzy dostawcy specjalizują się w przechowywaniu niewymiarowych faktów XBRL, w którym to przypadku tradycyjne oferty SQL (lub „post-SQL”, które skalują się z wierszami) działają dobrze.
Niektórzy dostawcy tworzą tabelę dla każdego hipersześcianu XBRL w taksonomii, ze schematem pochodzącym z sieci definicji, ale innym dla każdego hipersześcianu. Może to prowadzić do wielu tabel w bazie danych i wymaga wielu złączeń dla zapytań obejmujących wiele hipersześcianów.
Niektórzy inni dostawcy przyjmują założenia dotyczące podstawowej struktury XBRL lub rodzaju zapytań, które muszą uruchamiać ich użytkownicy. Ograniczenie zakresu problemu pozwala na znalezienie konkretnych architektur lub schematów SQL, które również mogą wykonać zadanie dla tych konkretnych potrzeb.
Wreszcie, aby zaimportować duże ilości plików, możliwe jest tworzenie ogólnych mapowań na bazie magazynów danych NoSQL, a nie relacyjnych baz danych. Duża liczba faktów o różnej liczbie wymiarów mieści się w dużych zbiorach częściowo ustrukturyzowanych dokumentów, a sieci dobrze pasują do formatu hierarchicznego.