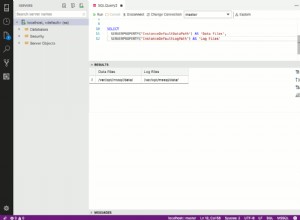
Nie. Możesz włączyć schematy w rekordach json. Źródło JDBC może tworzyć je dla Ciebie na podstawie informacji z tabeli
value.converter=org.apache.kafka...JsonConverter
value.converter.schemas.enable=true
Jeśli chcesz używać Schema Registry, powinieneś używać kafkastore.bootstrap.servers .z adresem Kafki, a nie dozorcy zoo. Więc usuń kafkastore.connection.url
przeczytaj dokumentację objaśnienia wszystkich właściwości
Nie ma znaczenia. Temat schematów jest tworzony przy pierwszym uruchomieniu Rejestru
Tak (ignorując dostępne miejsce na stercie maszyny JVM). Ponownie jest to szczegółowo opisane w dokumentacji Kafka Connect.
Korzystając z trybu samodzielnego, najpierw przekazujesz konfigurację procesu roboczego połączenia, a następnie do N właściwości łącznika w jednym poleceniu
W trybie rozproszonym korzystasz z interfejsu API Kafka Connect REST
https://docs.confluent.io/current/connect/managing/configuring .html
Przede wszystkim dotyczy to Sqlite, a nie Mysql/Postgres. Nie musisz używać plików szybkiego startu, są one dostępne tylko w celach informacyjnych
Ponownie, wszystkie właściwości są dobrze udokumentowane
https://docs.confluent.io /current/connect/kafka-connect-jdbc/index.html#connect-jdbc
Oto więcej informacji na temat debugowania tego
https://www.confluent.io/ blog/kafka-connect-deep-dive-jdbc-source-connector/
Jak wspomniano wcześniej, osobiście sugerowałbym używanie Debezium/CDC tam, gdzie to możliwe
Łącznik Debezium dla RDS Aurora