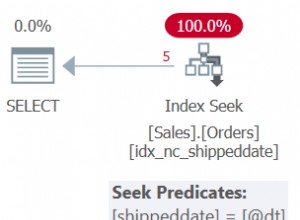
Te pliki mogą być parsowane w PHP za pomocą XMLReader działający na compress.bzip2:// strumień
. Struktura Twojego pliku jest wzorowa (zaglądając do ok. 3000 pierwszych elementów):
\-mediawiki (1)
|-siteinfo (1)
| |-sitename (1)
| |-base (1)
| |-generator (1)
| |-case (1)
| \-namespaces (1)
| \-namespace (40)
\-page (196)
|-title (196)
|-ns (196)
|-id (196)
|-restrictions (2)
|-revision (196)
| |-id (196)
| |-parentid (194)
| |-timestamp (196)
| |-contributor (196)
| | |-username (182)
| | |-id (182)
| | \-ip (14)
| |-comment (183)
| |-text (195)
| |-sha1 (195)
| |-model (195)
| |-format (195)
| \-minor (99)
\-redirect (5)
Sam plik jest nieco większy, więc jego przetworzenie zajmuje trochę czasu. Alternatywnie nie operuj na zrzutach XML, ale po prostu zaimportuj zrzuty SQL przez mysql narzędzie wiersza poleceń. Zrzuty SQL są również dostępne w witrynie, zobacz wszystkie formaty zrzutów dla angielskiego słownika :
Cały plik był nieco większy i zawierał ponad 66 849 000 elementów:
\-mediawiki (1)
|-siteinfo (1)
| |-sitename (1)
| |-base (1)
| |-generator (1)
| |-case (1)
| \-namespaces (1)
| \-namespace (40)
\-page (3993913)
|-title (3993913)
|-ns (3993913)
|-id (3993913)
|-restrictions (552)
|-revision (3993913)
| |-id (3993913)
| |-parentid (3572237)
| |-timestamp (3993913)
| |-contributor (3993913)
| | |-username (3982087)
| | |-id (3982087)
| | \-ip (11824)
| |-comment (3917241)
| |-text (3993913)
| |-sha1 (3993913)
| |-model (3993913)
| |-format (3993913)
| \-minor (3384811)
|-redirect (27340)
\-DiscussionThreading (4698)
|-ThreadSubject (4698)
|-ThreadPage (4698)
|-ThreadID (4698)
|-ThreadAuthor (4698)
|-ThreadEditStatus (4698)
|-ThreadType (4698)
|-ThreadSignature (4698)
|-ThreadParent (3605)
|-ThreadAncestor (3605)
\-ThreadSummaryPage (11)